1 背景
本文描述本地数仓项目即席查询相关内容,主要涉及即席查询工具包括Presto、Druid、Kylin。
本文基于文章《本地数据仓库项目(一) —— 本地数仓搭建详细流程》 和《本地数仓项目(二)——搭建系统业务数仓详细流程》以及《本地数仓项目(三)—— 数据可视化和任务调度》
2 Presto
2.1 Presto概念
Presto是一个开源的分布式SQL查询引擎,数据量支持GB到PB,主要用于处理秒级查询的场景。
2.2 Presto架构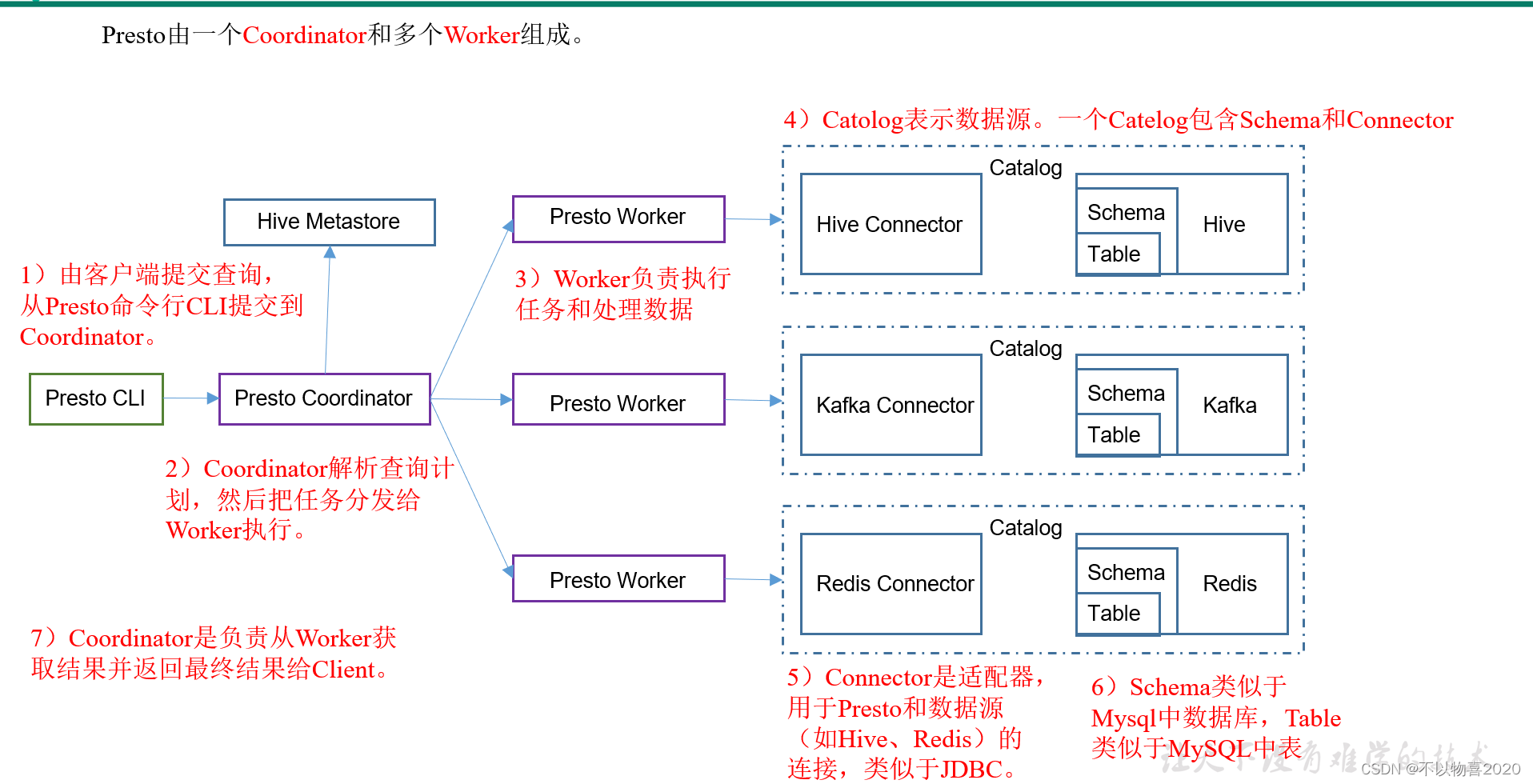
2.3 Presto优缺点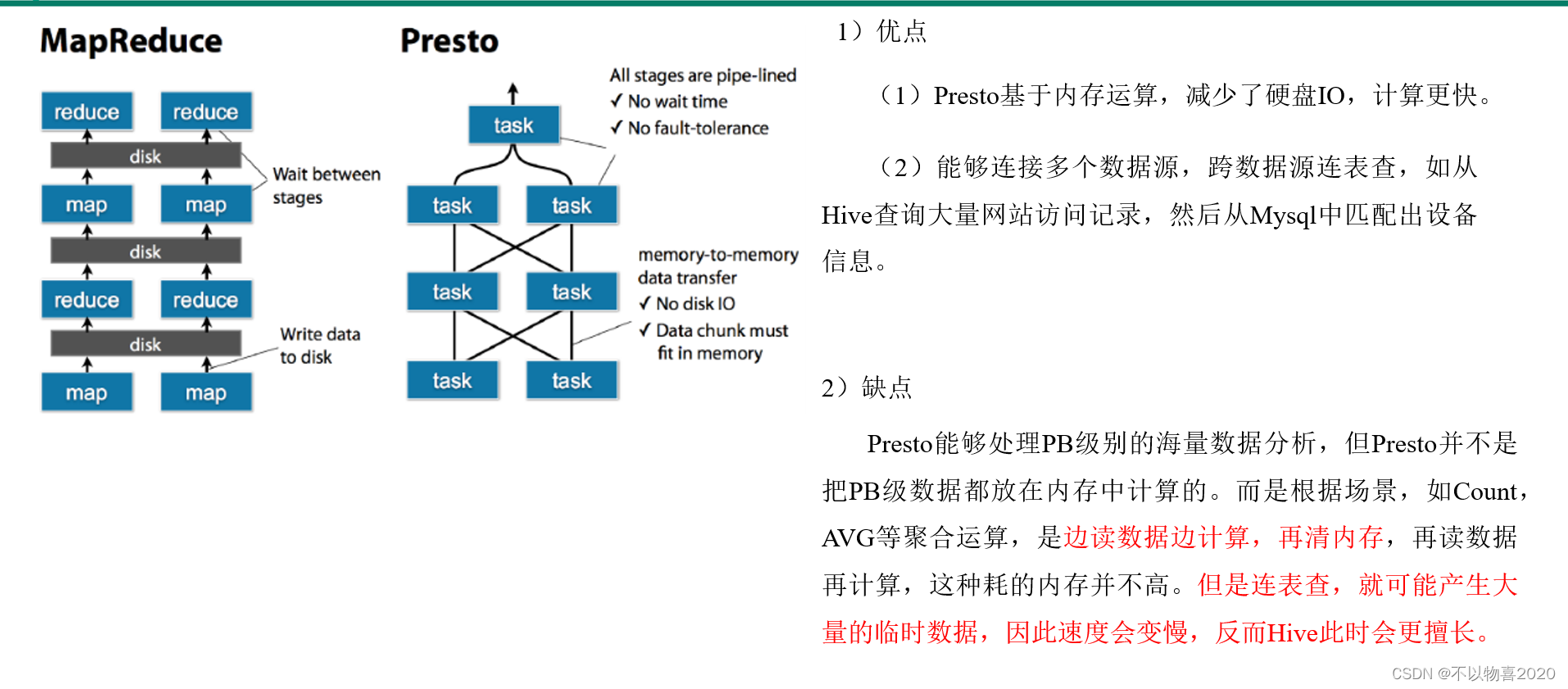
2.4 Presto安装
2.4.1 Presto Server安装
官网地址
https://prestodb.github.io/
下载地址
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/
1) 上传安装包并解压,修改解压后目录名
tar -zxvf presto-server-0.196.tar.gz
mv presto-server-0.196 presto-server
- 创建data和etc目录
[root@wavehouse-1 presto-server]# pwd
/root/soft/presto-server
[root@wavehouse-1 presto-server]# mkdir data
[root@wavehouse-1 presto-server]# mkdir etc
- etc目录下创建jvm.config文件
并添加如下内容:
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
- Presto可以支持多个数据源,在Presto里面叫catalog,这里我们配置支持Hive的数据源,配置一个Hive的catalog
mkdir etc/catalog
vim catalog/hive.properties
hive.properties添加如下内容:
connector.name=hive-hadoop2
hive.metastore.uri=thrift://wavehouse-1:9083
- 分发presto安装包到集群各个节点
- 分发之后在各个节点etc目录下新建node.properties文件
添加如下内容,注:不同节点的node.id设置为不同值,这里用的是十六进制。
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/opt/module/presto/data
- Presto是由一个coordinator节点和多个worker节点组成。在主节点上配置成coordinator,在其他节点上配置为worker
vim etc/config.properties
主节点添加如下内容
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8881
query.max-memory=50GB
discovery-server.enabled=true
discovery.uri=http://wavehouse-1:8881
其他节点添加如下内容
coordinator=false
http-server.http.port=8881
query.max-memory=50GB
discovery.uri=http://wavehouse-2:8881
8)启动Hive Metastore
nohup bin/hive --service metastore >/dev/null 2>&1 &
9)所有安装presto的节点启动presto
#前台启动
bin/launcher run
或
#后台启动
bin/launcher start
2.4.2 Presto命令行Client安装
下载地址:
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/
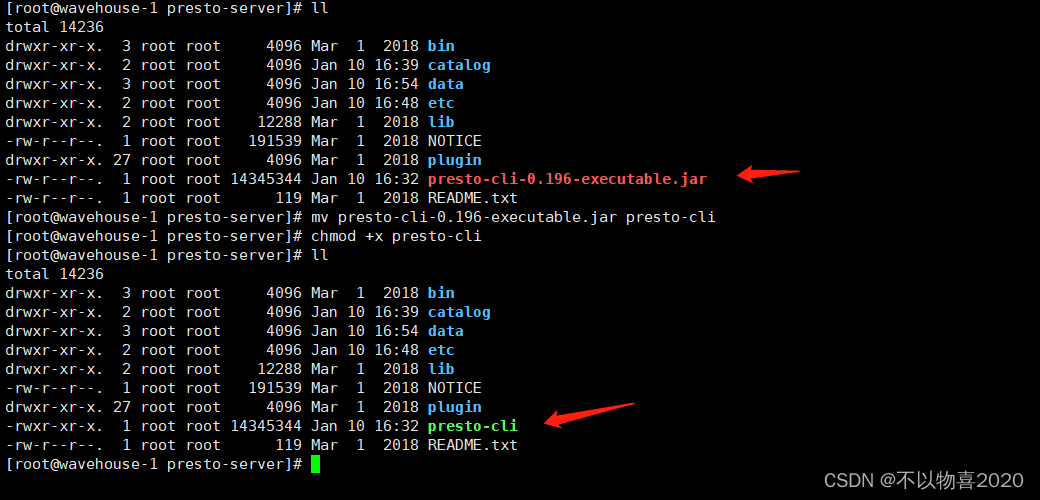
- 将下载的presto-cli-xxxx-executable.jar上传到主节点的安装presto文件夹下
- 修改名字并赋予可执行权限
3)放入支持lzo压缩的jar包
由于数仓数据采用了lzo压缩,Presto去读数据时需要读取lzo格式数据,因此需要将lzo的jar包放入presto
cp /root/soft/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar ./
- 启动
./presto-cli --server wavehouse-1:8881 --catalog hive --schema default
5)Presto命令行操作
Presto的命令行操作,相当于Hive命令行操作。每个表必须要加上schema。
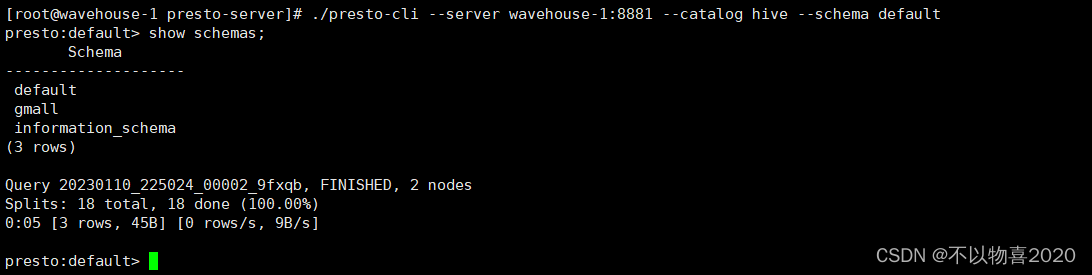
select * from hive.gmall.ads_back_count limit 10;
2.4.3 Presto可视化Client安装
- 上传yanagishima-18.0.zip到soft目录
- 解压缩
unzip yanagishima-18.0.zip
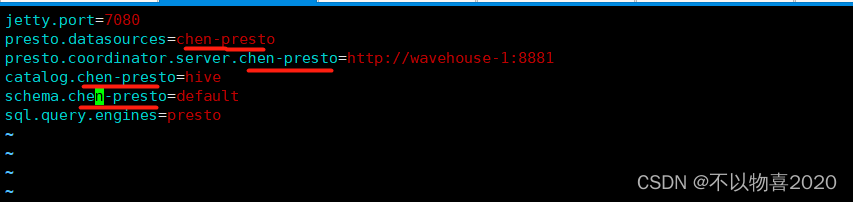
- 进入conf文件夹,编写yanagishima.properties
添加如下内容
jetty.port=7080
presto.datasources=chen-presto
presto.coordinator.server.chen-presto=http://wavehouse-1:8881
catalog.chen-presto=hive
schema.chen-presto=default
sql.query.engines=presto
4)启动
nohup bin/yanagishima-start.sh >y.log 2>&1 &
- 访问http://wavehouse-1:7080
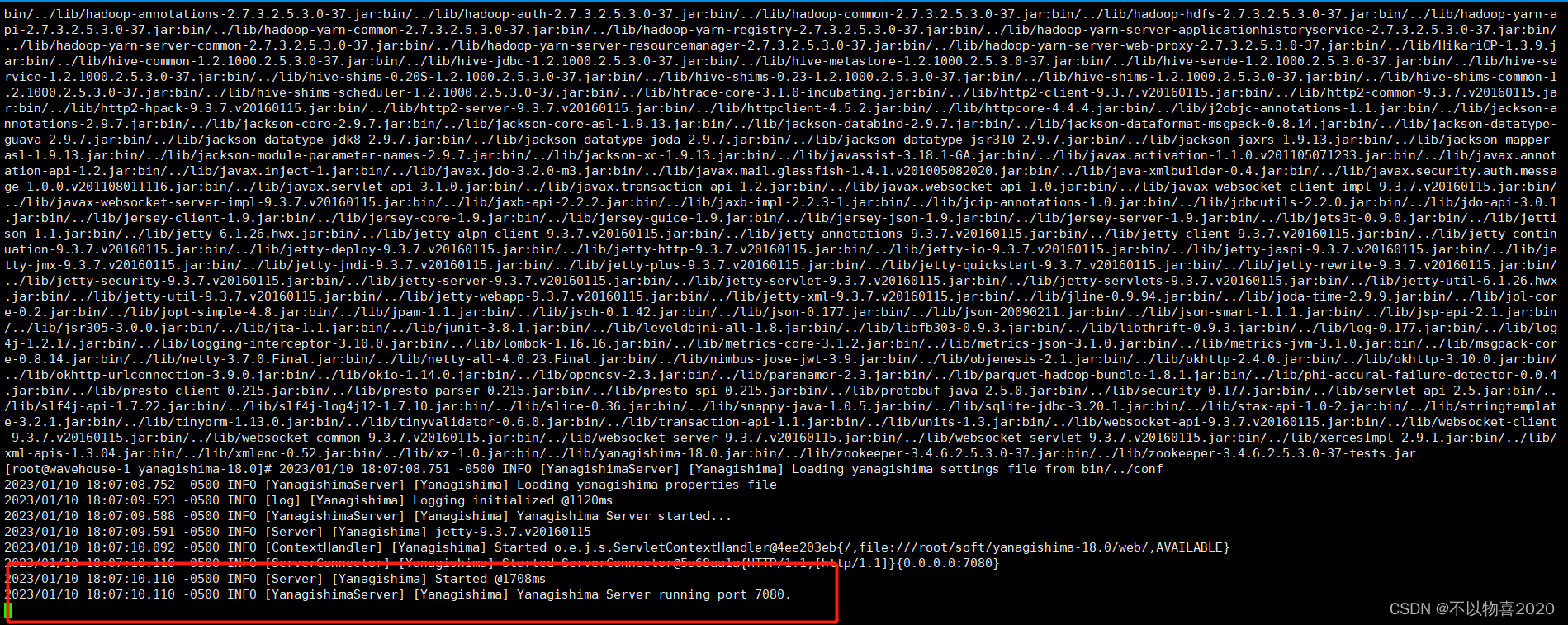
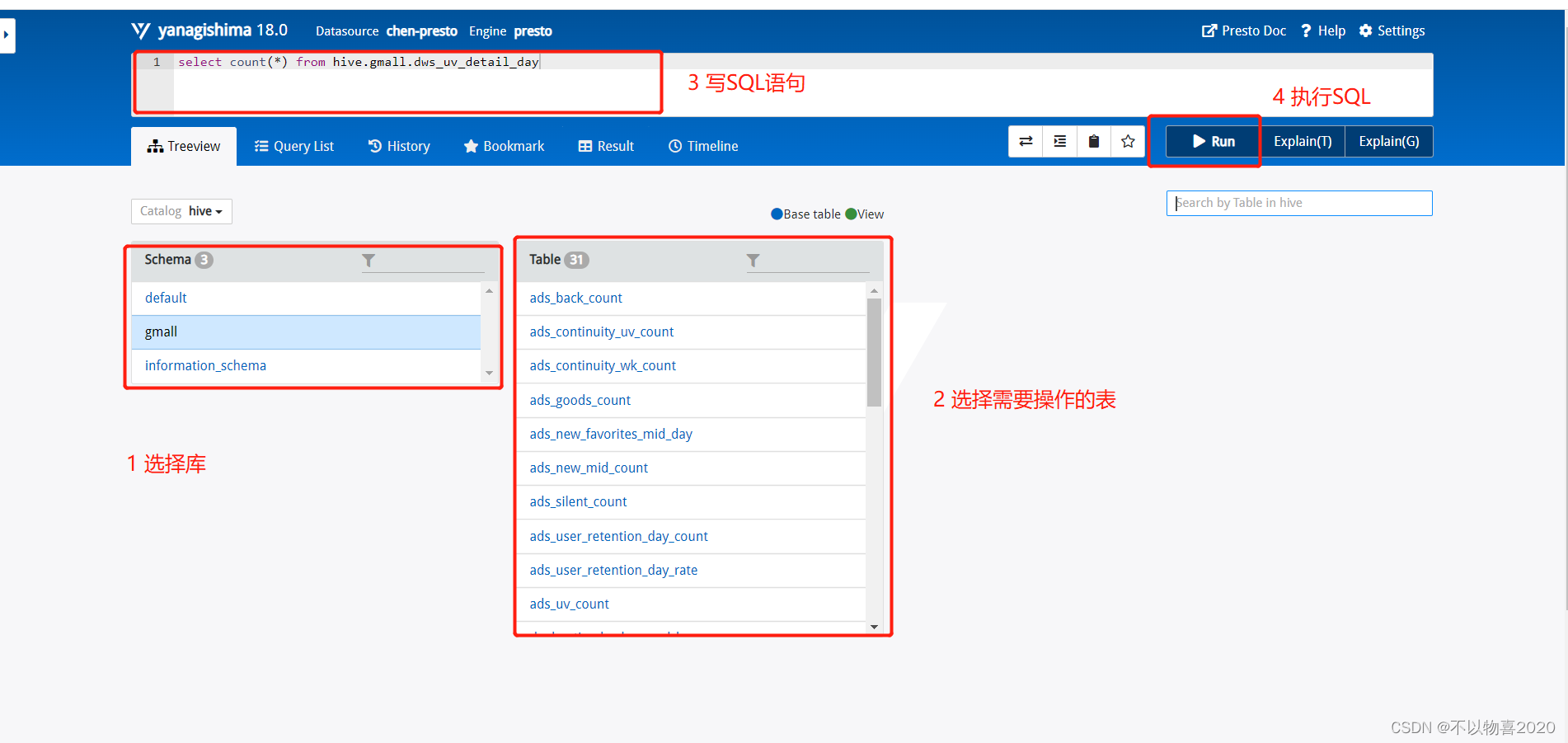
2.4.4 效率对比
执行同样的sql,分别在hive端执行和Presto端执行
2.4.4.1
select count(*) from hive.gmall.dws_uv_detail_day
hive使用TEZ引擎
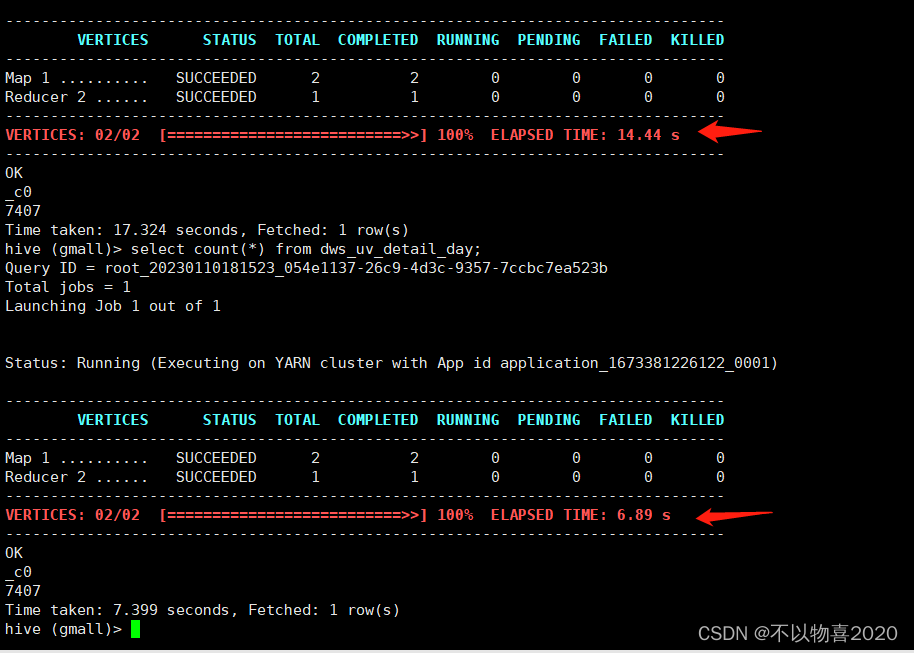
忽略TEZ第一次启动耗时,hive的TEZ查询时间为6.89秒
Presto查询
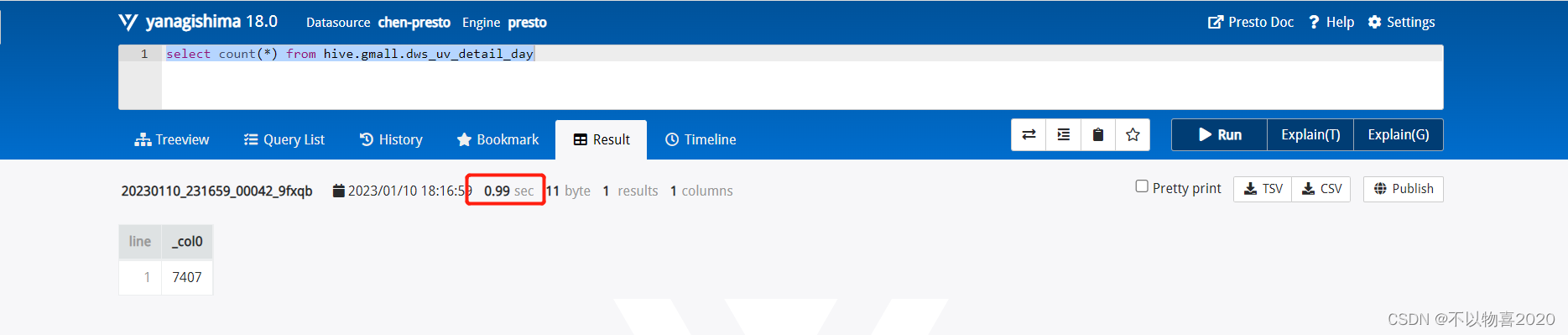
presto耗时0.99秒,性能提升,秒级查询。
2.4.4.2
select max(dt) from hive.gmall.dws_uv_detail_day
hive查询耗时4.65秒
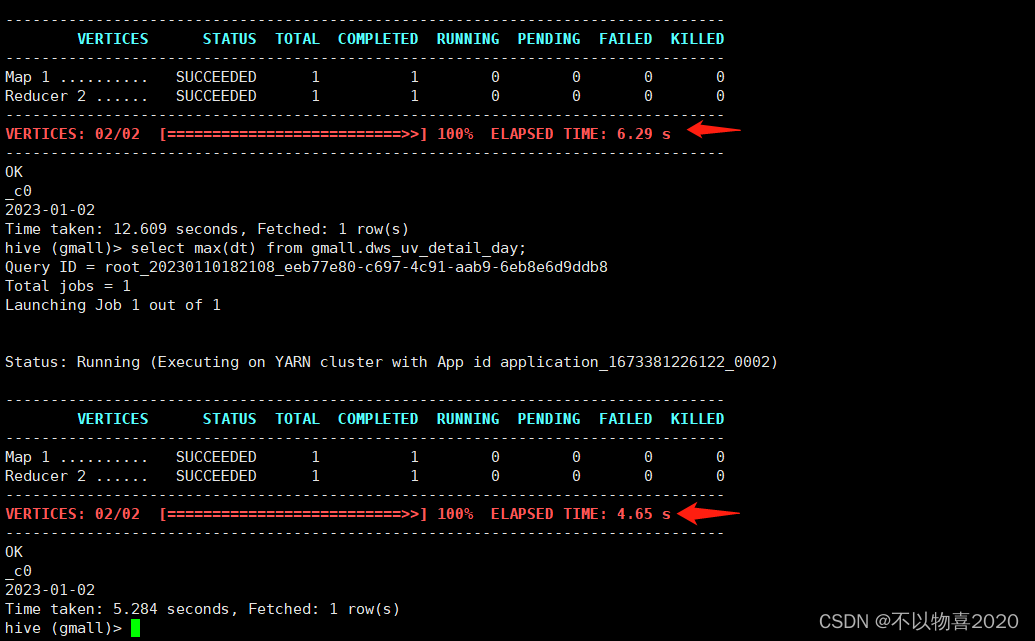
Presto查询
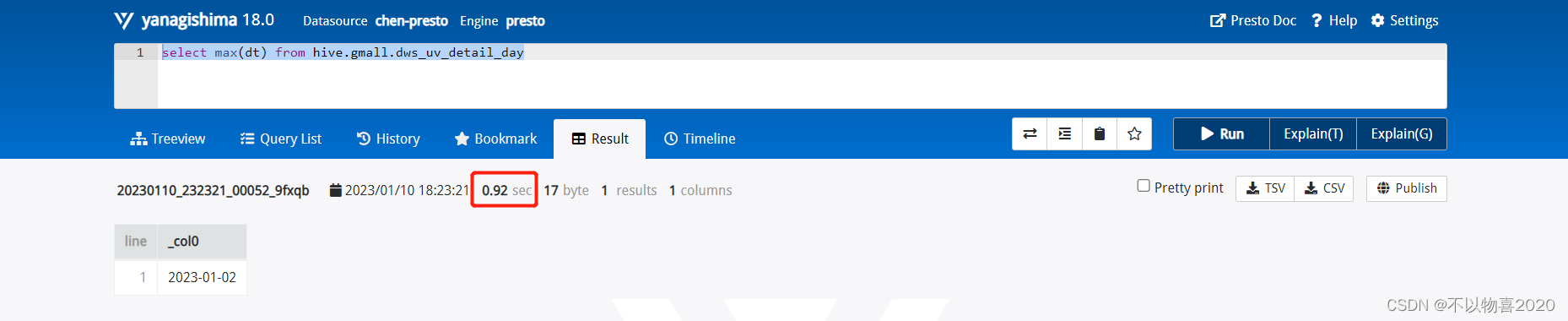
presto耗时0.92秒,性能提升,秒级查询。
注:由于当前本地虚拟机,内存给的是4G,性能有所限制,如果是实际生产环境内存64G+情况下,性能更优!

2.5 Presto优化
2.5.1 合理设置分区
与Hive类似,Presto会根据元数据信息读取分区数据,合理的分区能减少Presto数据读取量,提升查询性能。
2.5.2 使用列式存储
Presto对ORC文件读取做了特定优化,因此在Hive中创建Presto使用的表时,建议采用ORC格式存储。相对于Parquet,Presto对ORC支持更好。
2.5.3 使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于即席查询需要快速解压,建议采用Snappy压缩。
3 Druid
3.1 Druid简介
Druid是一个快速的列式分布式的支持实时分析的数据存储系统。它在处理PB级别数据、毫秒级查询、数据实时处理方面,比传统的OLAP系统又显著性能提升。
3.2 Druid特点和应用场景
① 列式存储
② 可扩展的分布式系统
③ 大规模的并行处理
④ 实时或批量摄取
⑤ 自愈,自平衡,易操作
⑥ 数据进行有效的语句和或预计算
⑦ 数据结果应用Bitmap压缩算法
应用场景:
① 适用于清洗好的记录实时录入,但不需要更新操作
② 适用于支持宽表,不用Join的方式(即就是一张表)
③ 适用于可以总结出基础的统计指标,用一个字段表示
④ 适用于实时性要求高
3.3 Druid框架
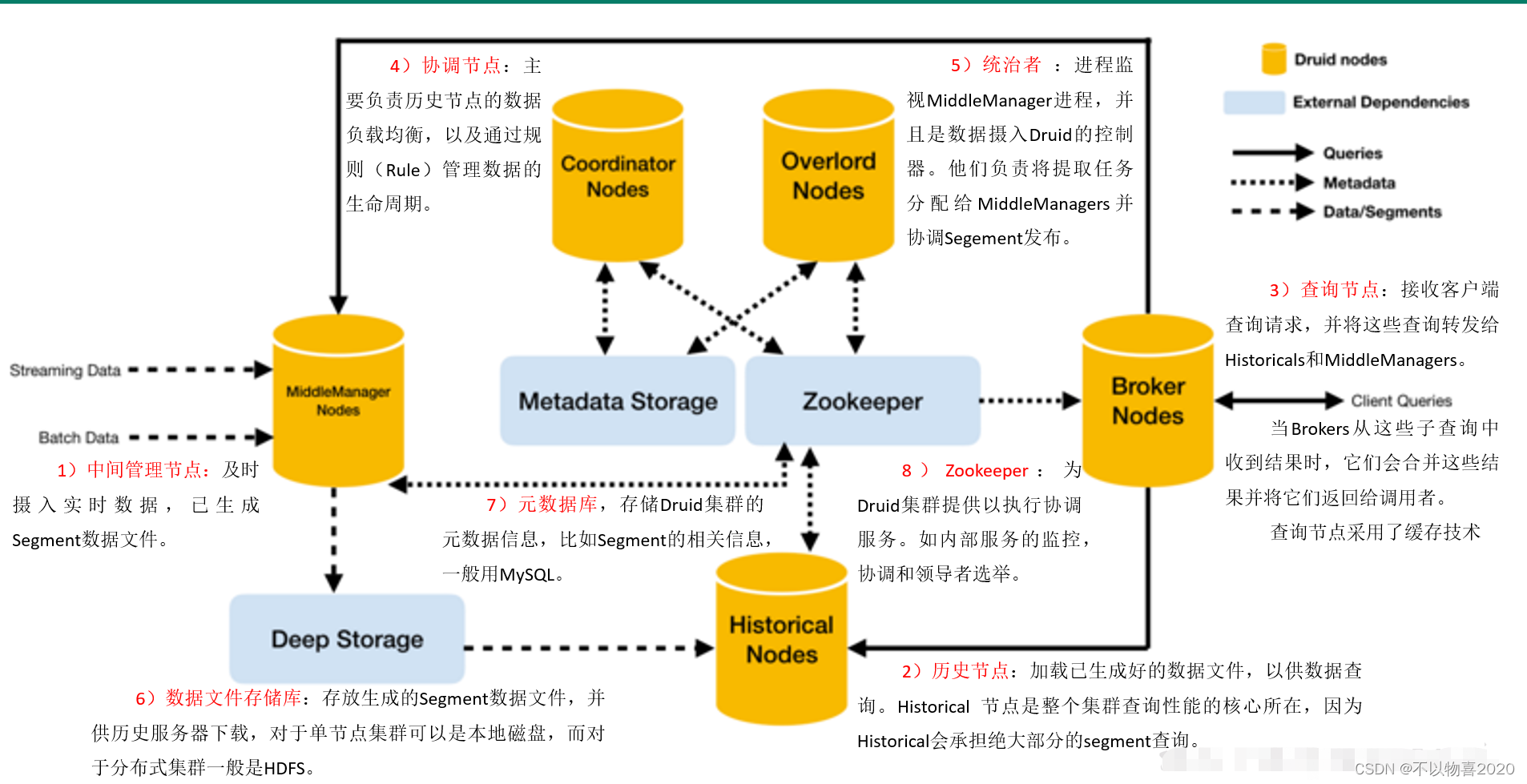
3.4 Druid数据结构
与Druid架构相辅相成的是其基于DataSource与Segment的数据结构,它们共同成就了Druid的高性能优势。

3.5 Druid安装
3.5.1 安装包下载
从https://imply.io/get-started 下载最新版本安装包
3.5.2 安装部署
1)将imply-2.7.10.tar.gz上传到hadoop102的/opt/software目录下,并解压
tar -zxvf imply-2.7.10.tar.gz
2)修改imply-2.7.10名称为imply
3)修改配置文件
(1)修改Druid的ZK配置
vim imply/conf/druid/_common/common.runtime.properties
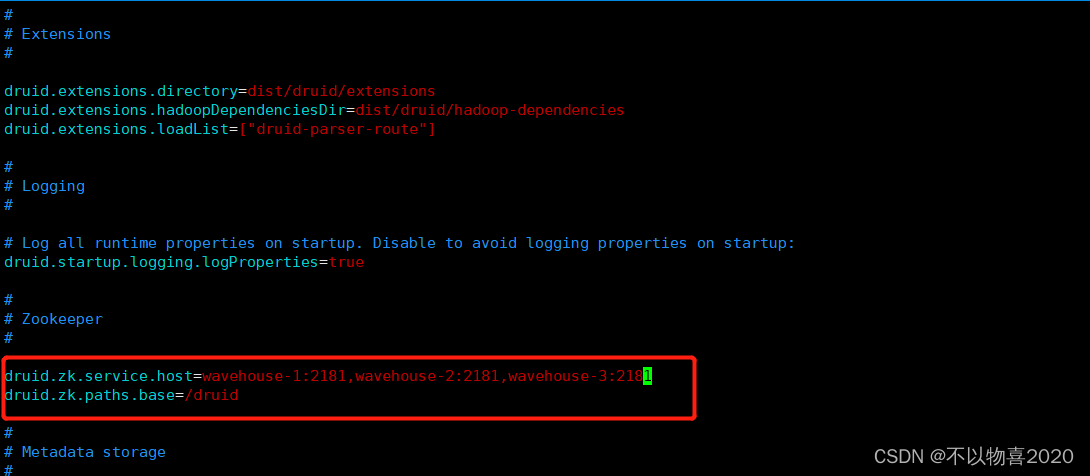
(2)修改启动命令参数,使其不校验不启动内置ZK
vim imply/conf/supervise/quickstart.conf
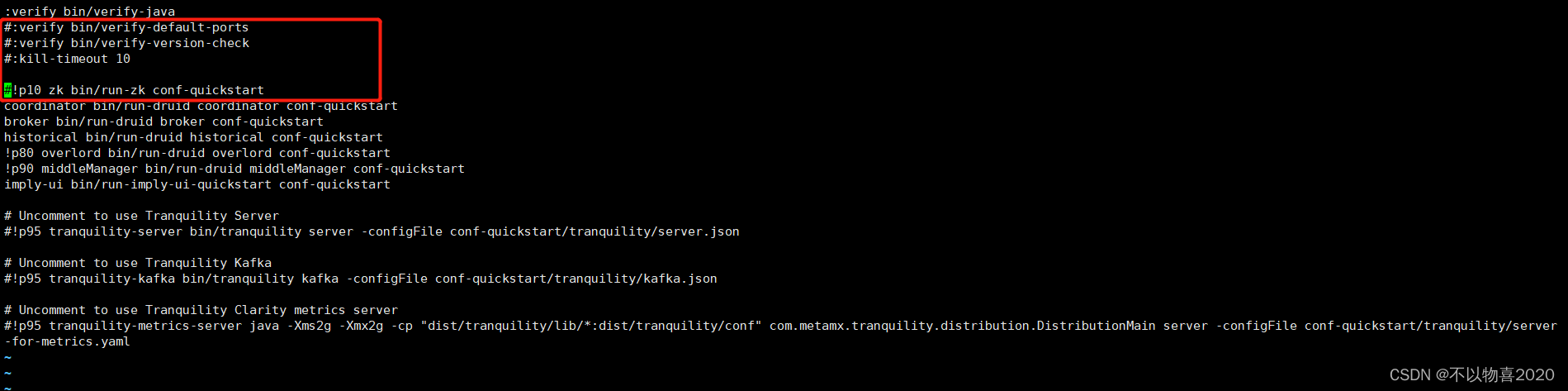
4)启动
(1)启动Zookeeper
./zkServer.sh statrt
(2)启动imply
bin/supervise -c conf/supervise/quickstart.conf
3.5.3 Web页面使用
1)登录wavehouse-1:9095查看

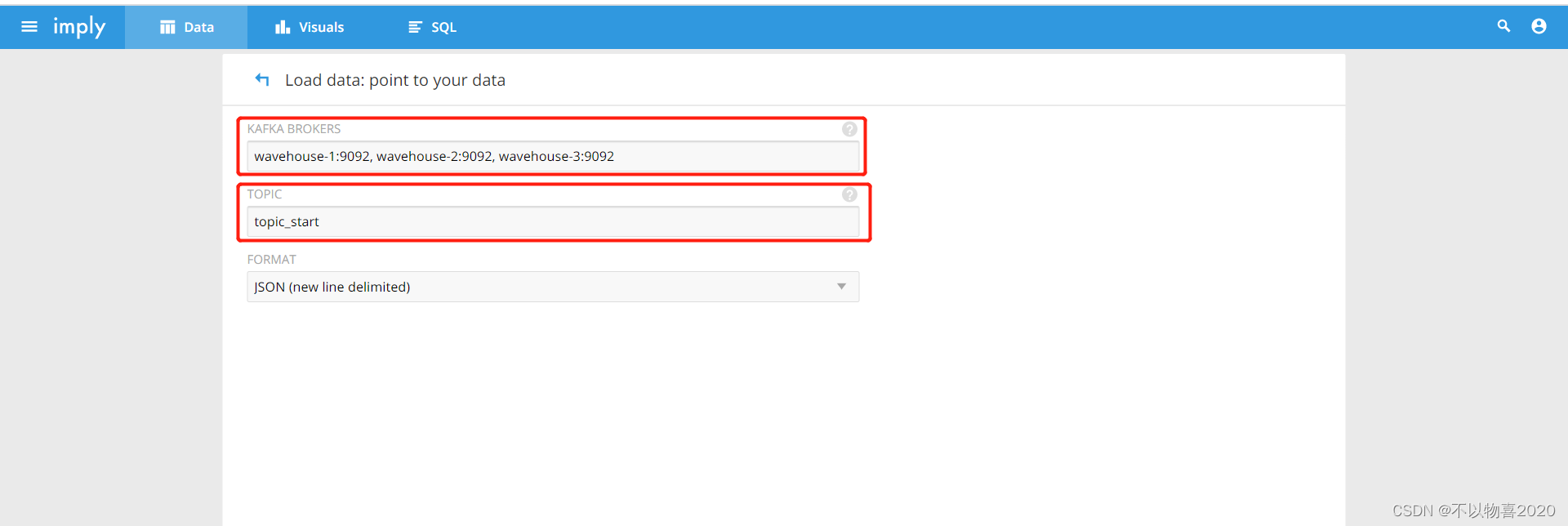
2)点击Load data->点击Apache Kafka
设置kafka集群和主题
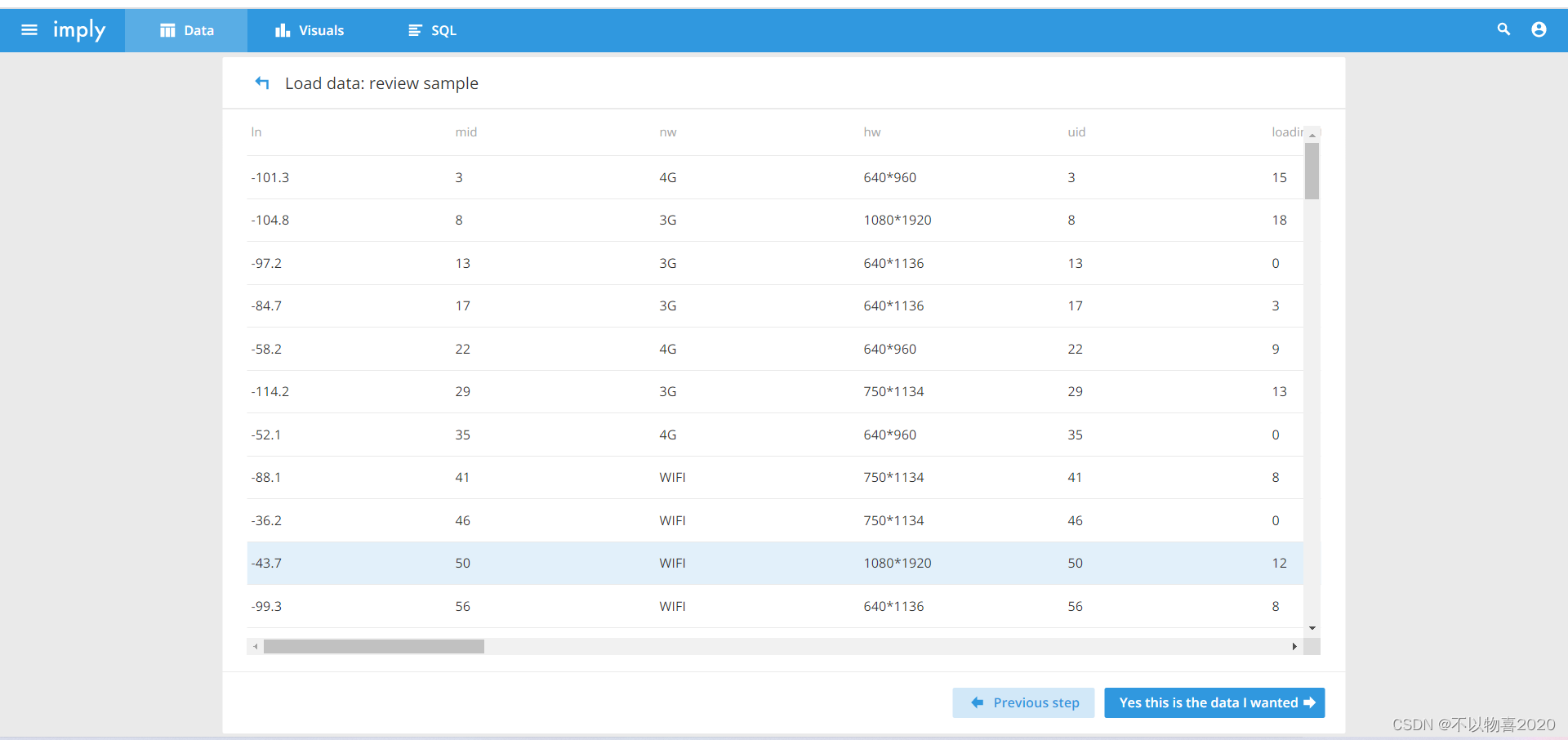
3)确认数据样本格式
4) 加载数据,必须要有时间字段
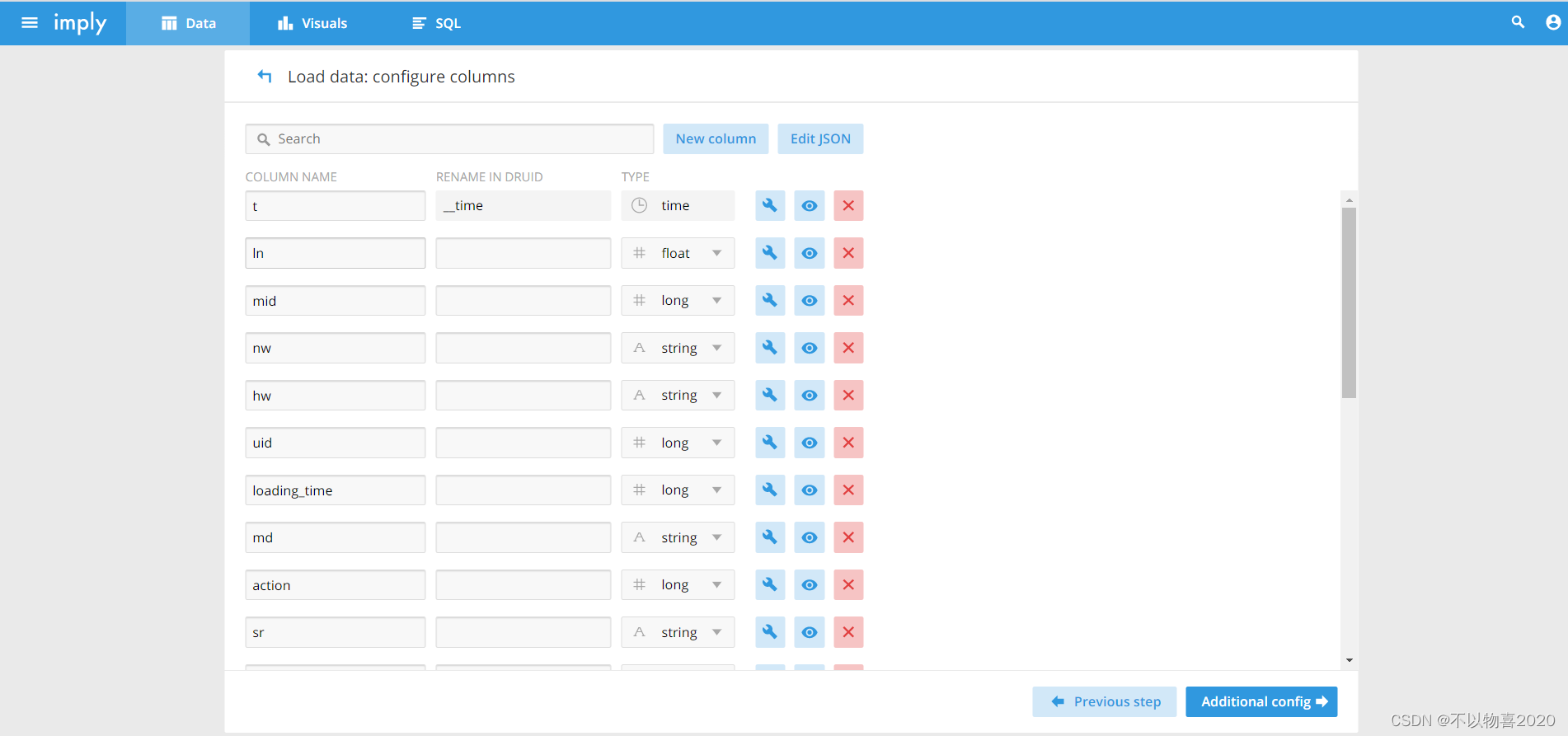
5)选择需要加载的项
6)创建数据库表名
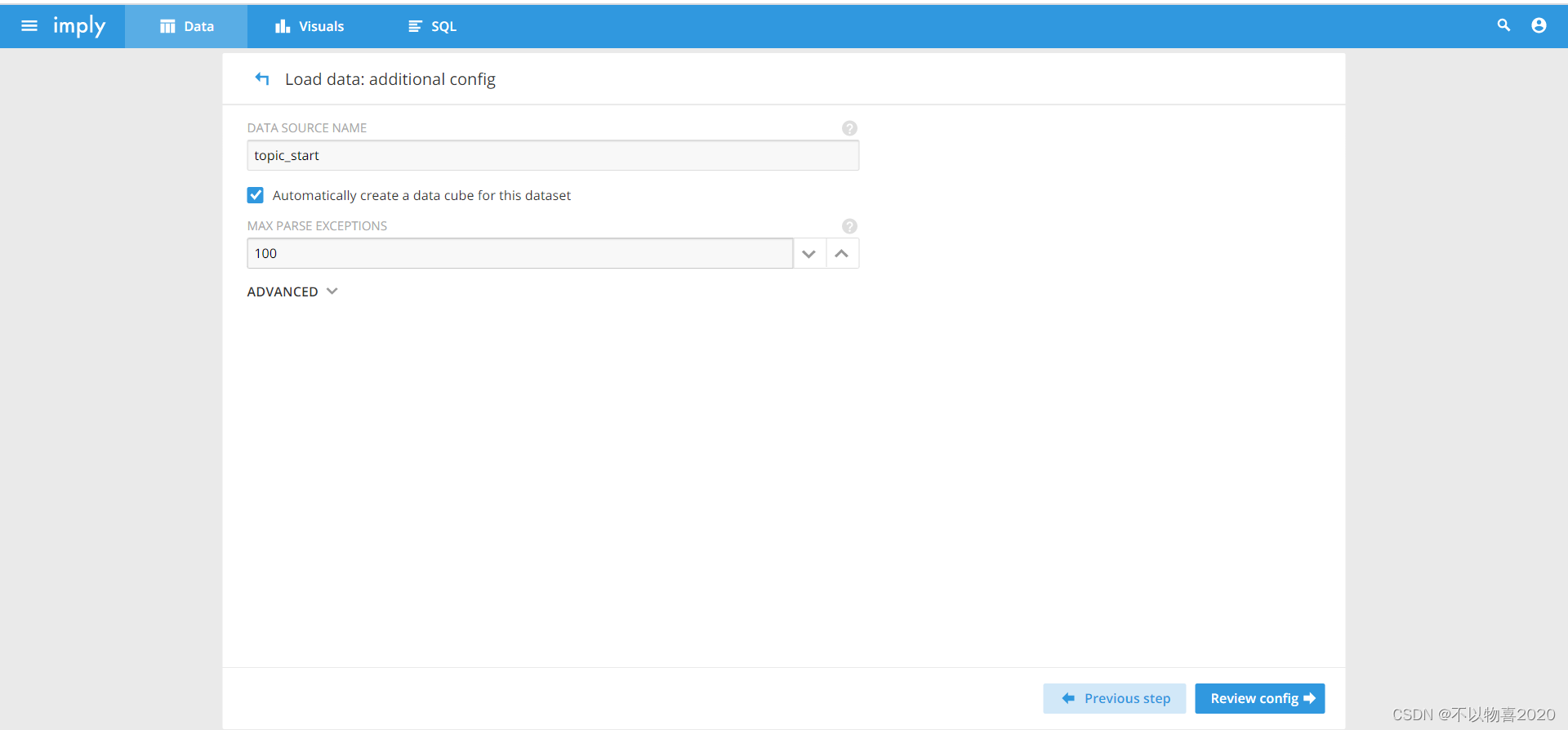
7) 确认一下配置
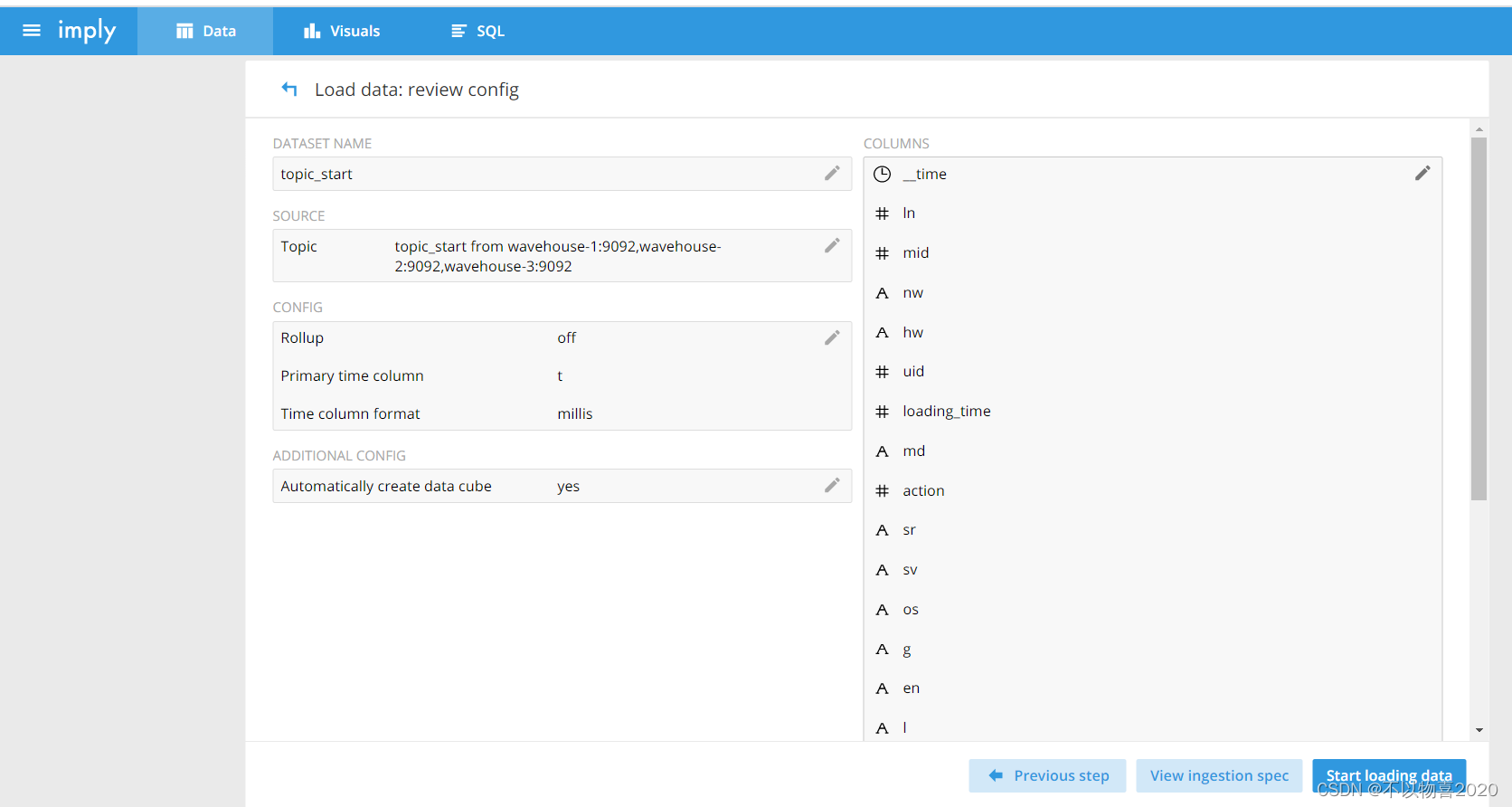
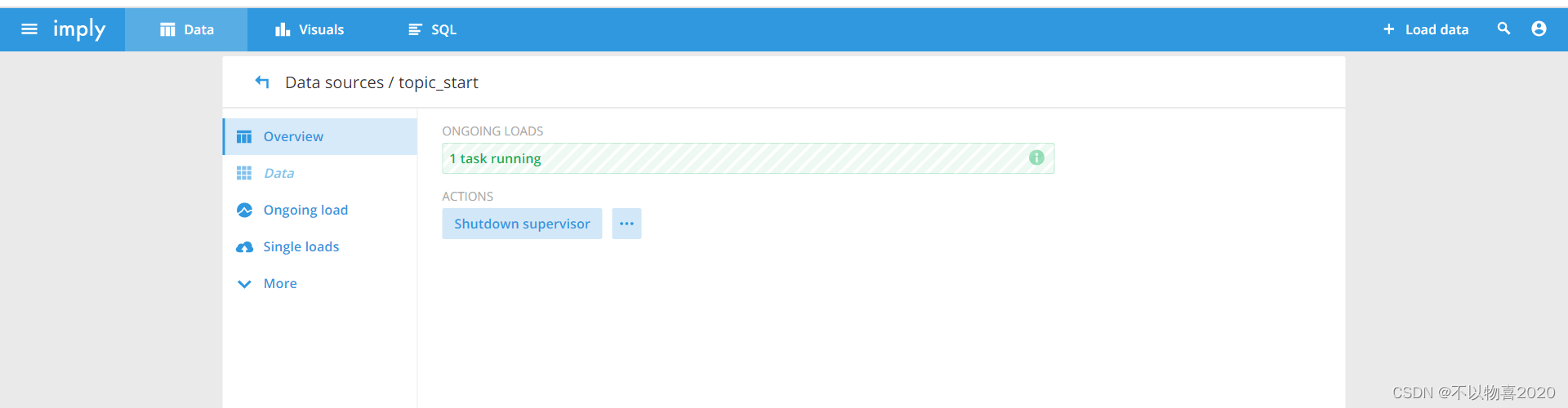
8)连接Kafka的topic_start
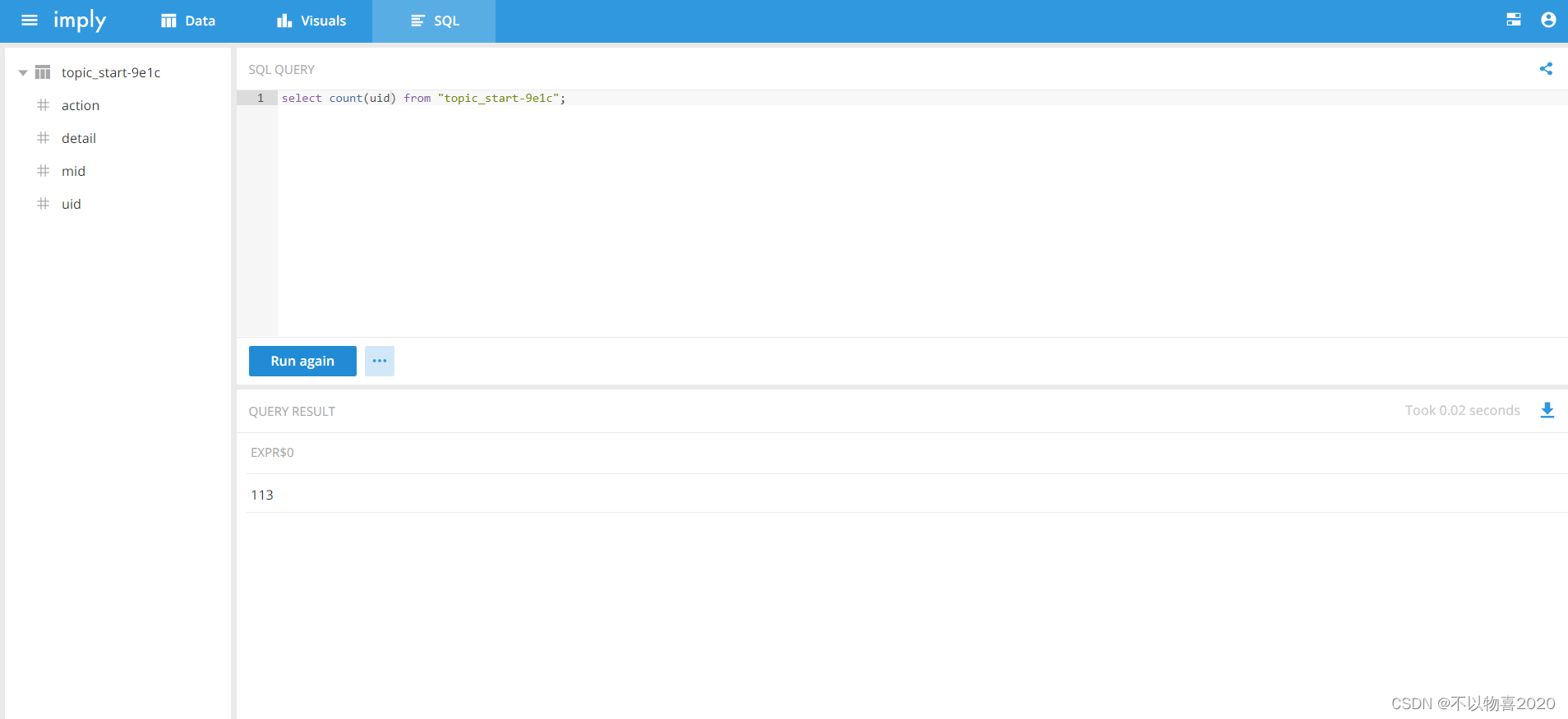
9) 选择SQL,查询指标
select sum(uid) from "topic_start"
4 Kylin
4.1 Kylin介绍
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
4.2 Kylin架构
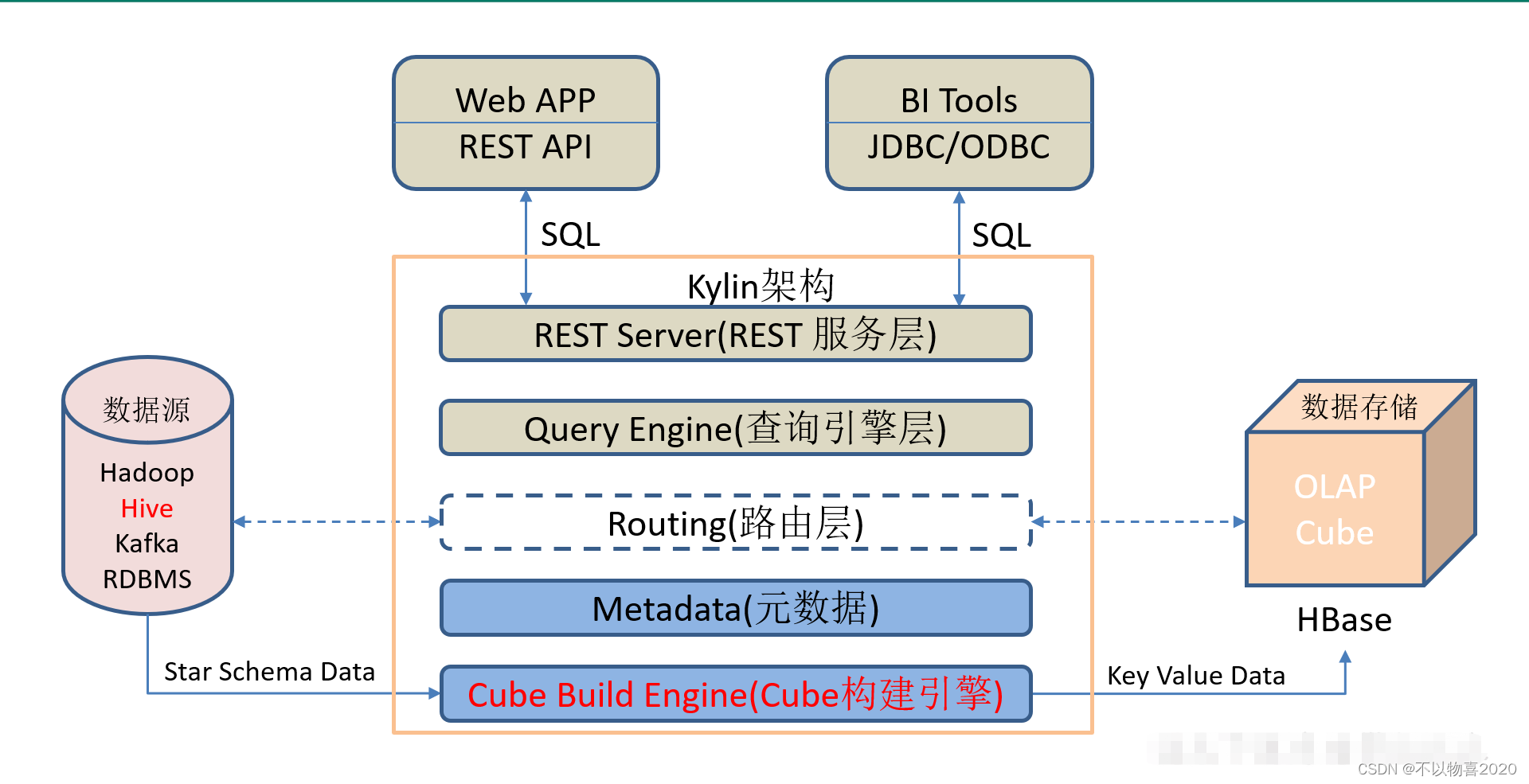
1)REST Server
REST Server是一套面向应用程序开发的入口点,旨在实现针对Kylin平台的应用开发工作。 此类应用程序可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等等。另外可以通过Restful接口实现SQL查询。
2)查询引擎(Query Engine)
当cube准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。
3)路由器(Routing)
在最初设计时曾考虑过将Kylin不能执行的查询引导去Hive中继续执行,但在实践后发现Hive与Kylin的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。最后这个路由功能在发行版中默认关闭。
4)元数据管理工具(Metadata)
Kylin是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存在Kylin当中的所有元数据进行管理,其中包括最为重要的cube元数据。其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin的元数据存储在hbase中。
5)任务引擎(Cube Build Engine)
这套引擎的设计目的在于处理所有离线任务,其中包括shell脚本、Java API以及Map Reduce任务等等。任务引擎对Kylin当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。
4.3 Kyllin特点
Kylin的主要特点包括支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等。
1)标准SQL接口:Kylin是以标准的SQL作为对外服务的接口。
2)支持超大数据集:Kylin对于大数据的支撑能力可能是目前所有技术中最为领先的。早在2015年eBay的生产环境中就能支持百亿记录的秒级查询,之后在移动的应用场景中又有了千亿记录秒级查询的案例。
3)亚秒级响应:Kylin拥有优异的查询响应速度,这点得益于预计算,很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需的计算量,提高了响应速度。
4)可伸缩性和高吞吐率:单节点Kylin可实现每秒70个查询,还可以搭建Kylin的集群。
5)BI工具集成
Kylin可以与现有的BI工具集成,具体包括如下内容。
ODBC:与Tableau、Excel、PowerBI等工具集成
JDBC:与Saiku、BIRT等Java工具集成
RestAPI:与JavaScript、Web网页集成
Kylin开发团队还贡献了Zepplin的插件,也可以使用Zepplin来访问Kylin服务
4.4 Kylin安装
安装Kylin前需先部署好Hadoop、Hive、Zookeeper、HBase,并且需要在/etc/profile中配置以下环境变量HADOOP_HOME,HIVE_HOME,HBASE_HOME,记得source使其生效。
HBASE安装详细见这篇文章
1)下载Kylin安装包
下载地址:http://kylin.apache.org/cn/download/
2)解压apache-kylin-2.5.1-bin-hbase1x.tar.gz
3)启动
(1)启动Kylin之前,需先启动Hadoop(hdfs,yarn,jobhistoryserver)、Zookeeper、Hbase
(2)启动Kylin
bin/kylin.sh start
看到如下页面说明kylin启动成功
4) 访问URL
在http://wavehouse-1:7070/kylin查看Web页面
用户名为:ADMIN,密码为:KYLIN(系统已填)
4.5 Kylin使用
以gmall数据仓库中的dwd_payment_info作为事实表,dwd_order_info_his、dwd_user_info作为维度表,构建星型模型,并演示如何使用Kylin进行OLAP分析。
4.5.1 创建工程
- 选择‘+’按钮
- 填写项目名称描述信息
4.5.2 获取数据源
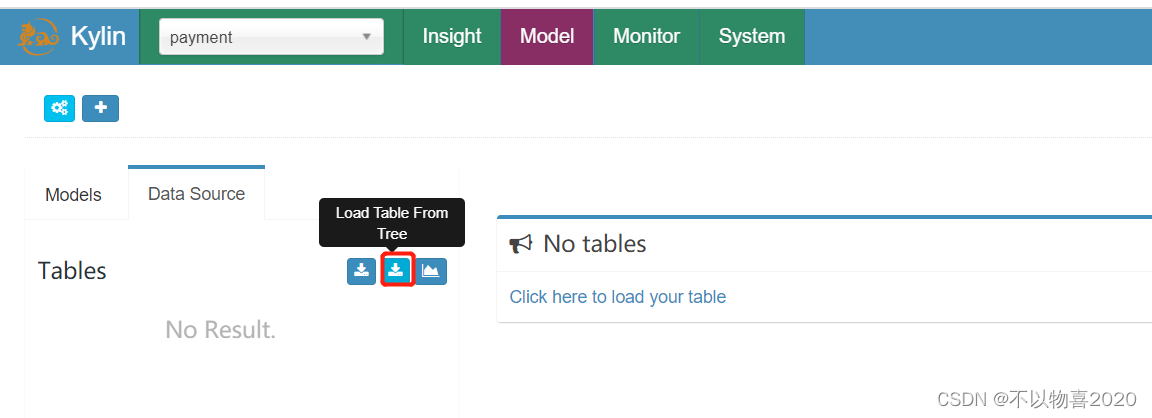
- 选择datasource
2) 选择导入表
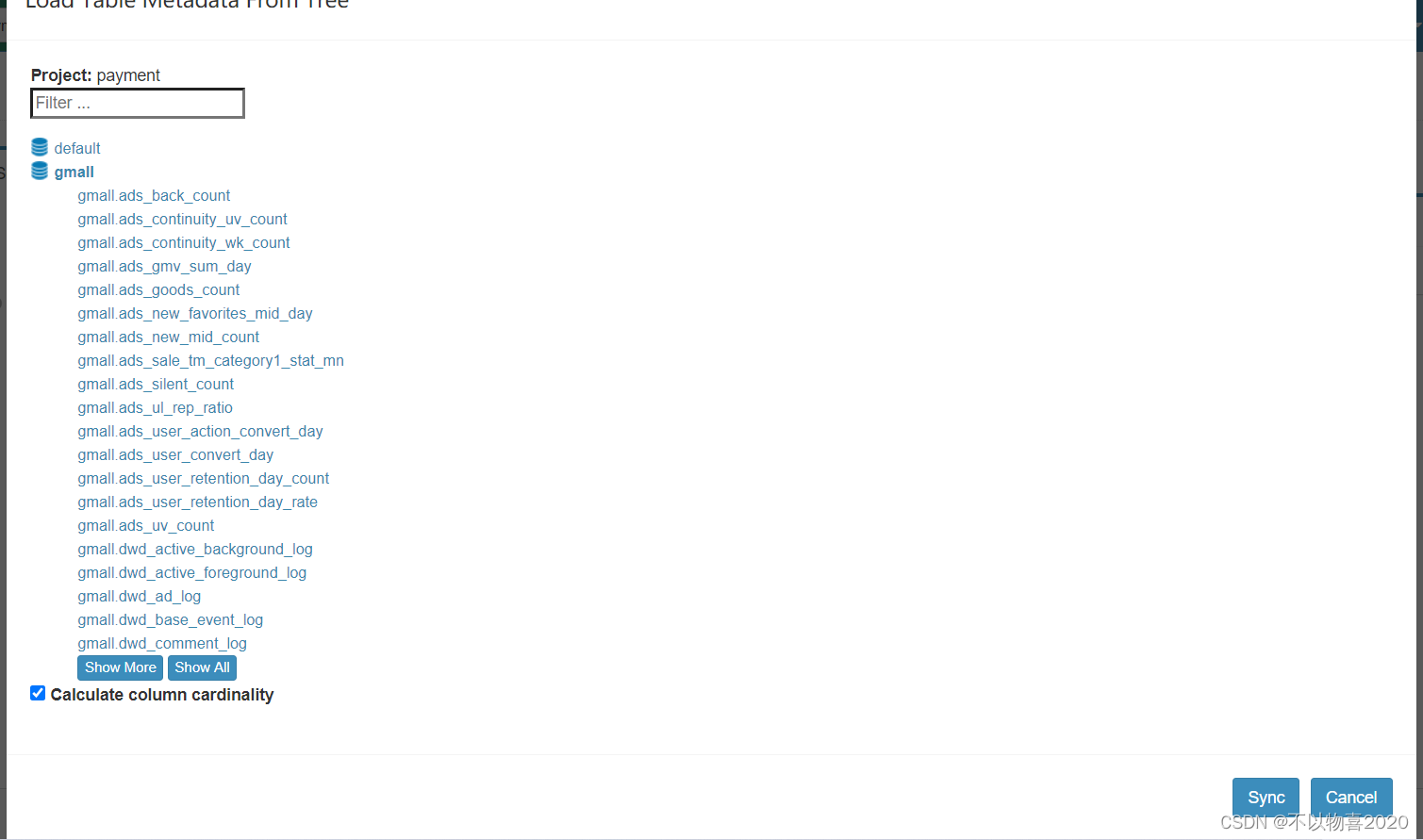
- 选择所需数据表,并点击Sync按钮
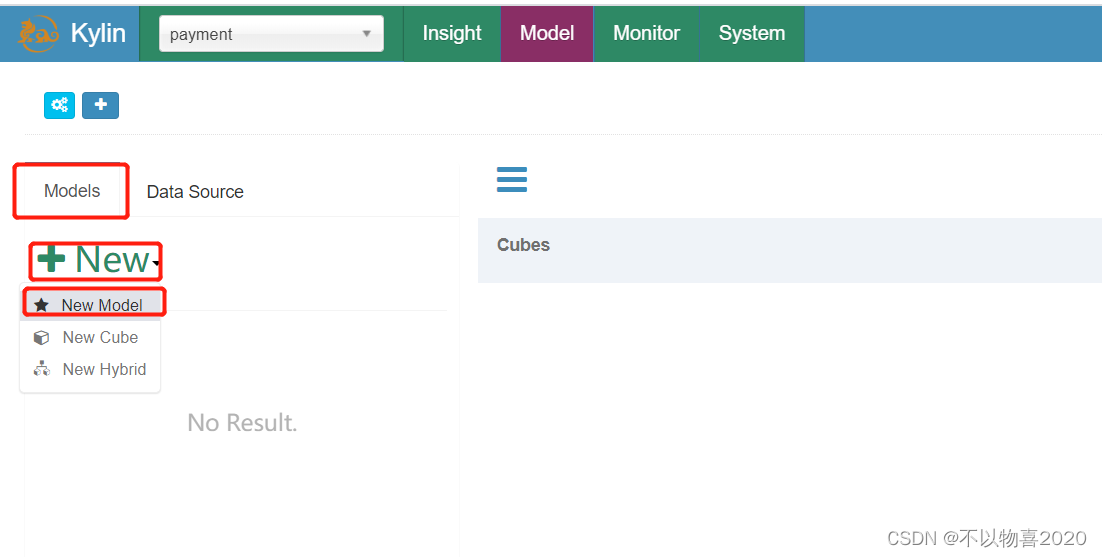
4.5.3 创建model
1)点击Models,点击"+New"按钮,点击"★New Model"按钮。
2)填写Model信息,点击Next
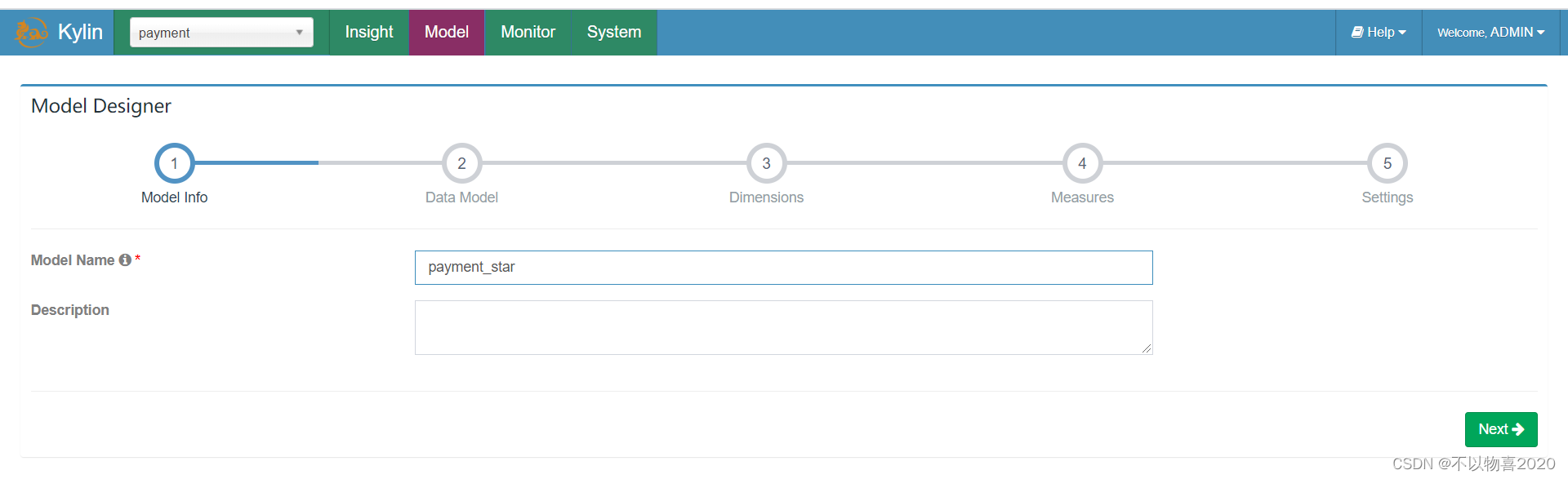
3)指定事实表
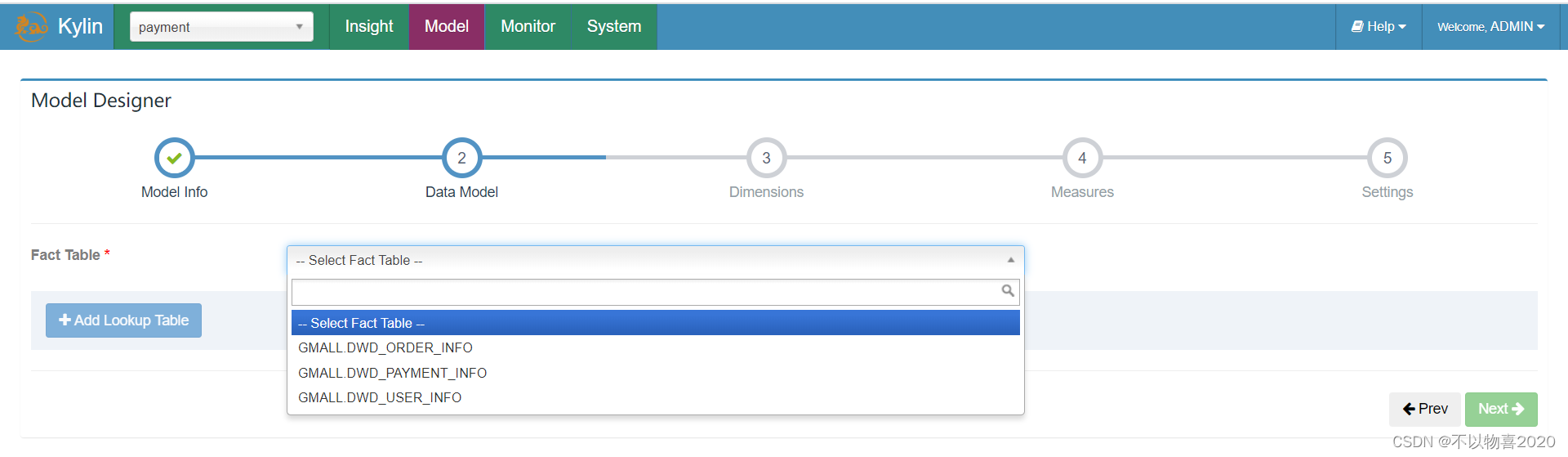
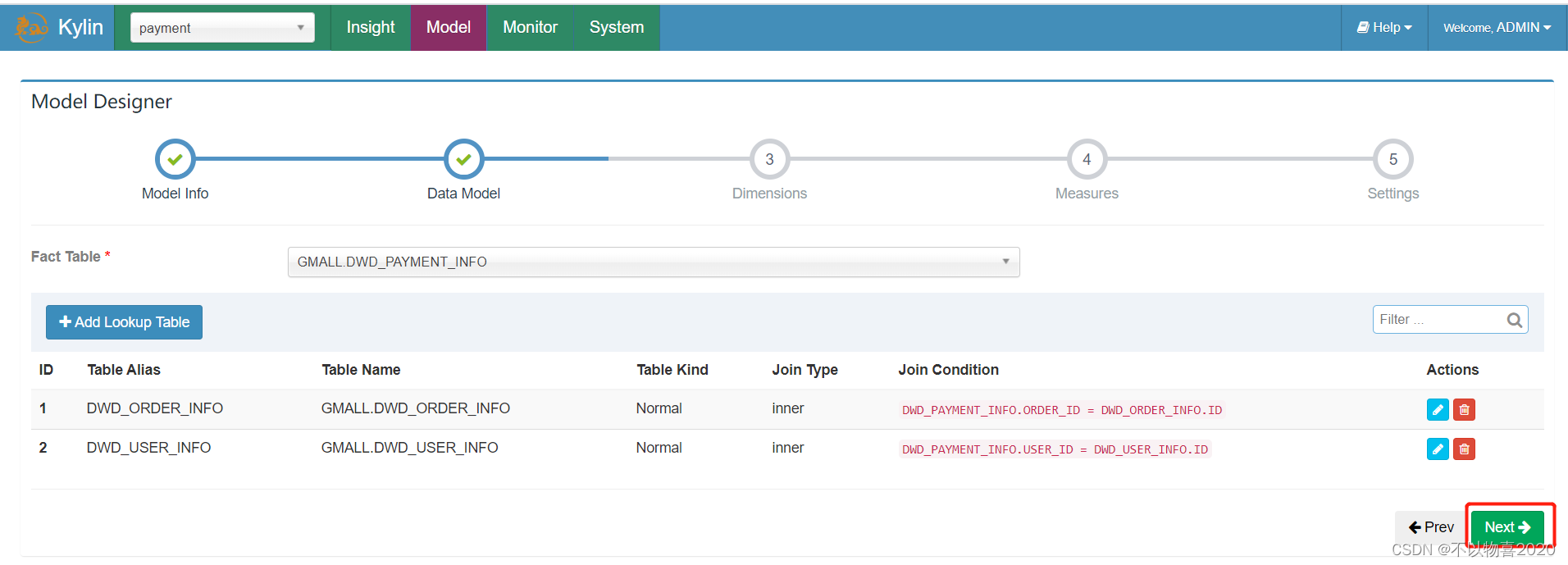
4)选择维度表,并指定事实表和维度表的关联条件,点击Ok

维度表添加完毕之后,点击Next
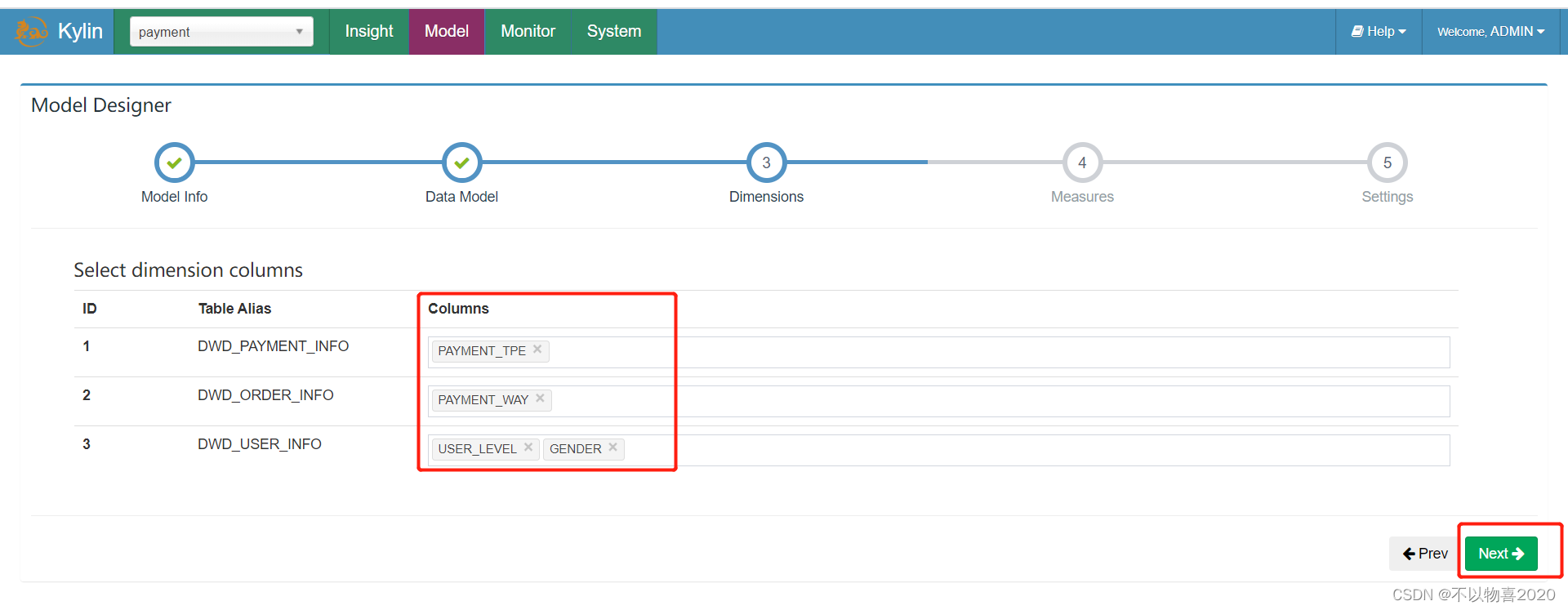
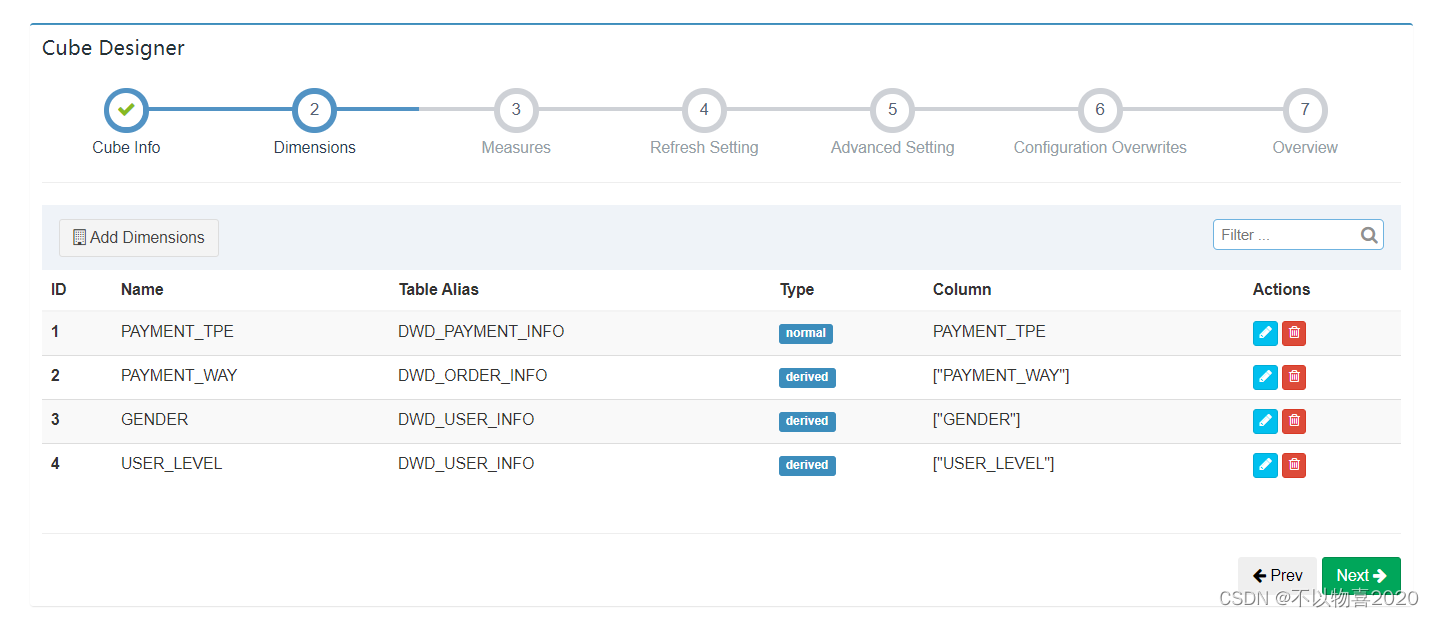
5)指定维度字段,并点击Next
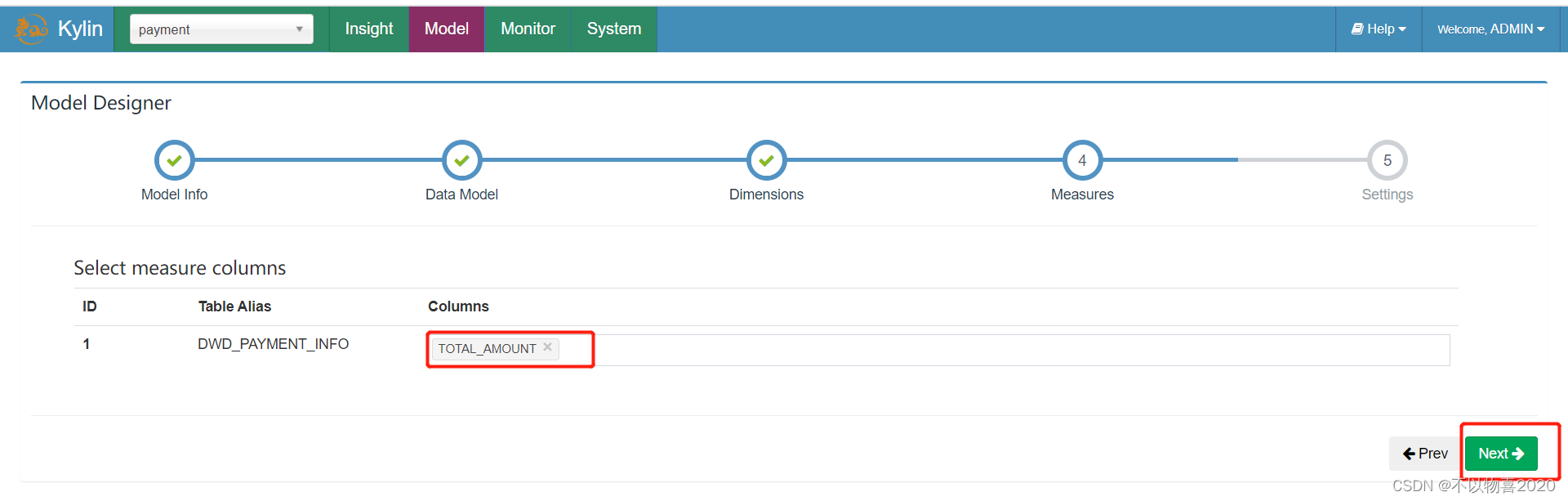
6)指定度量字段,并点击Next
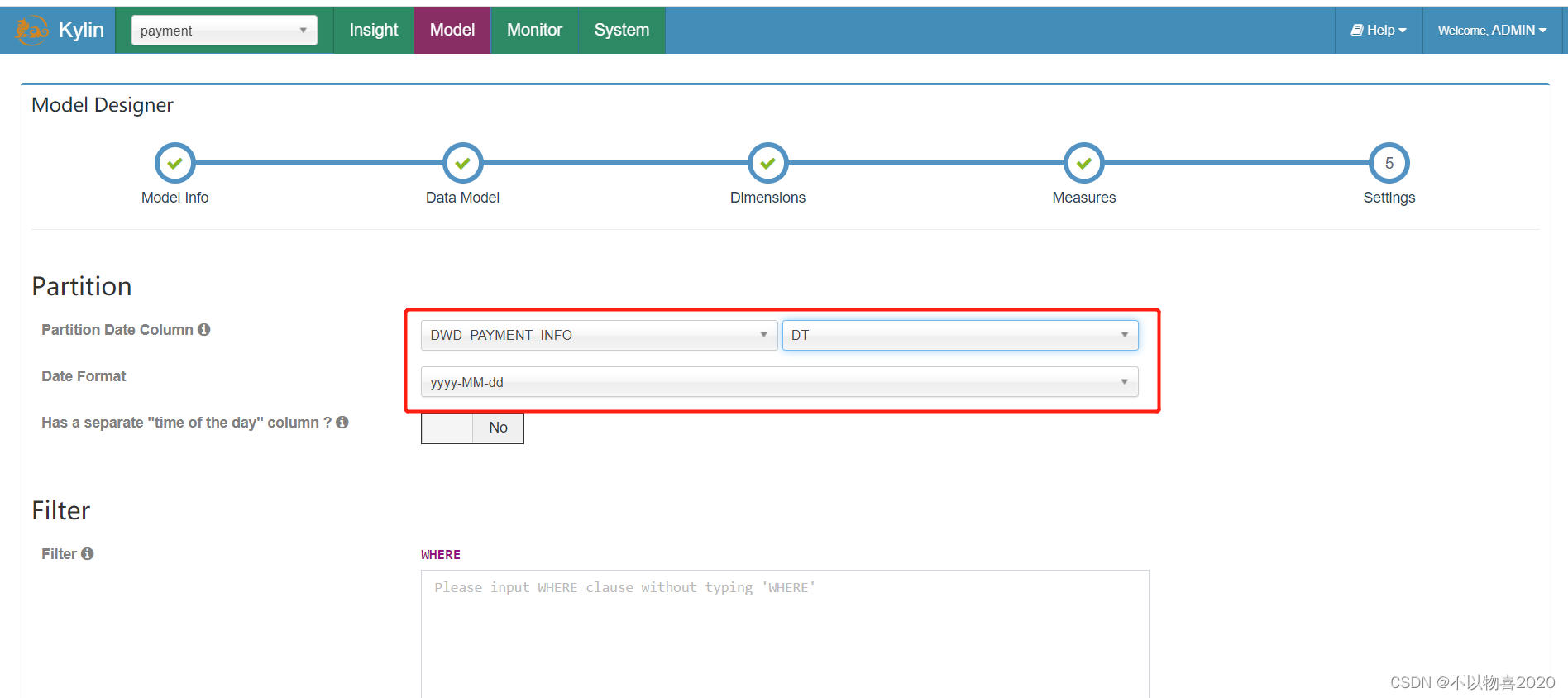
7)指定事实表分区字段(仅支持时间分区),点击Save按钮,model创建完毕
4.5.4 构建cube
1)点击new, 并点击new cube
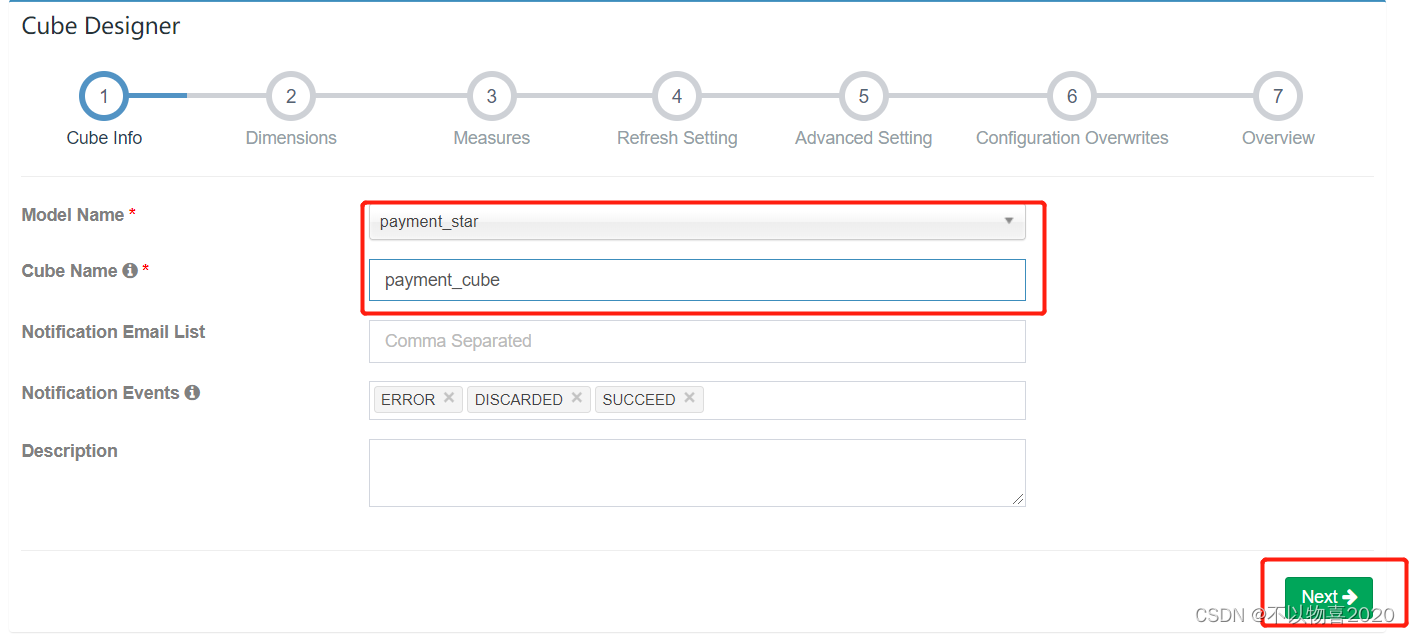
2)填写cube信息,选择cube所依赖的model,并点击next
3)选择所需的维度,如下图所示
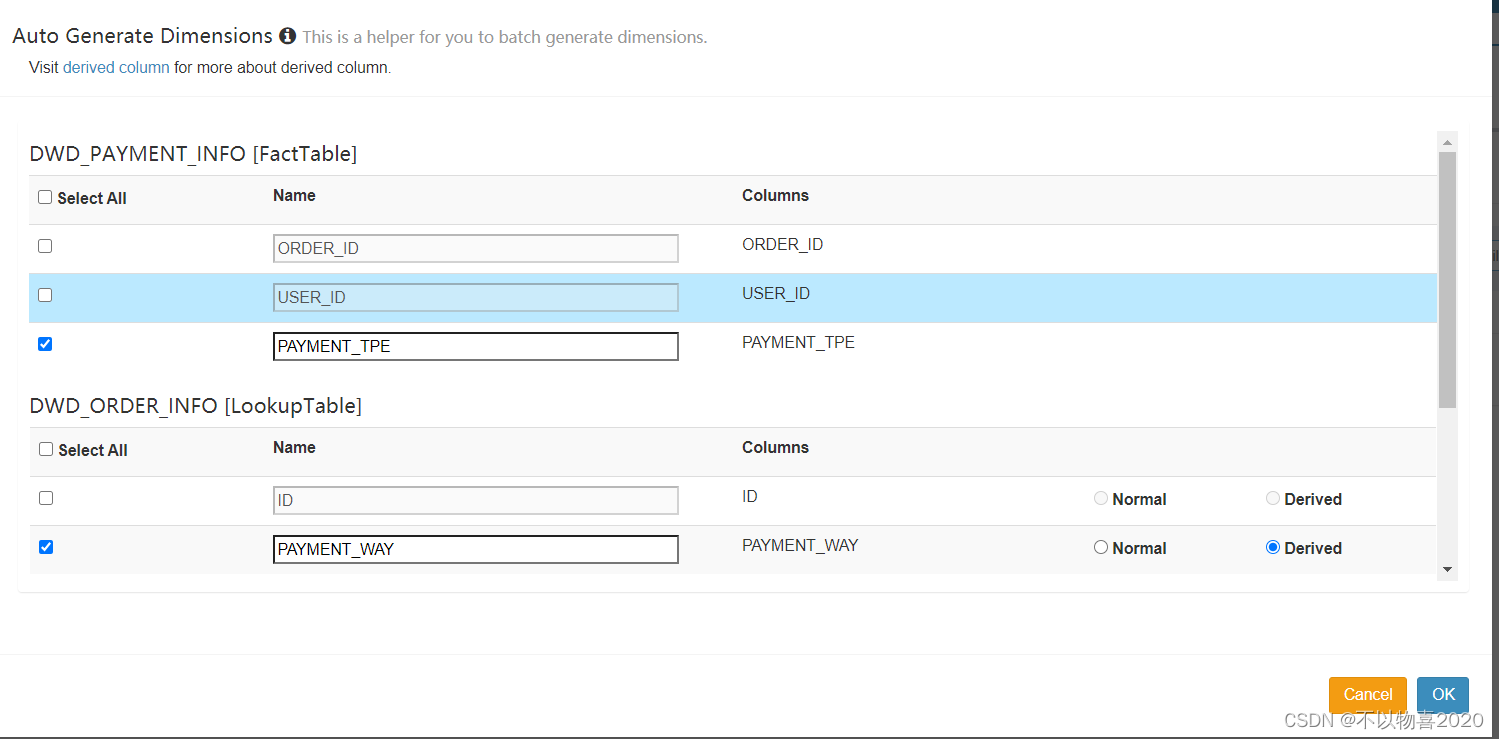
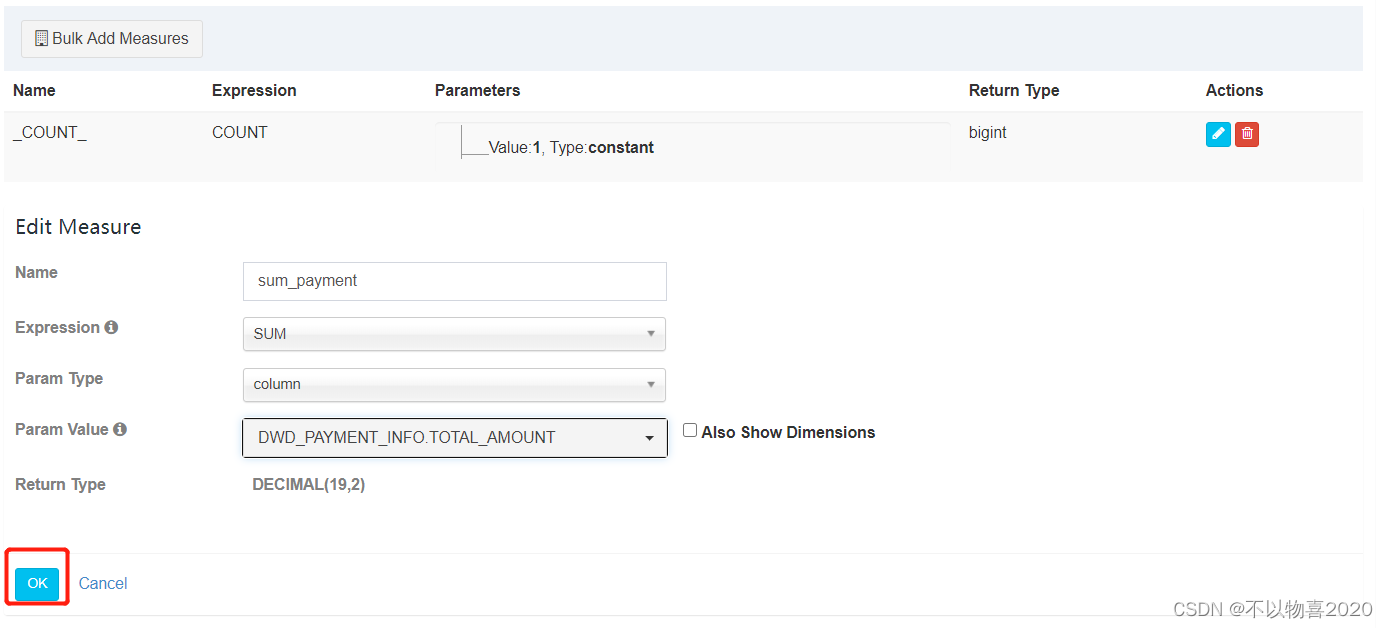
4)选择所需度量值,如下图所示
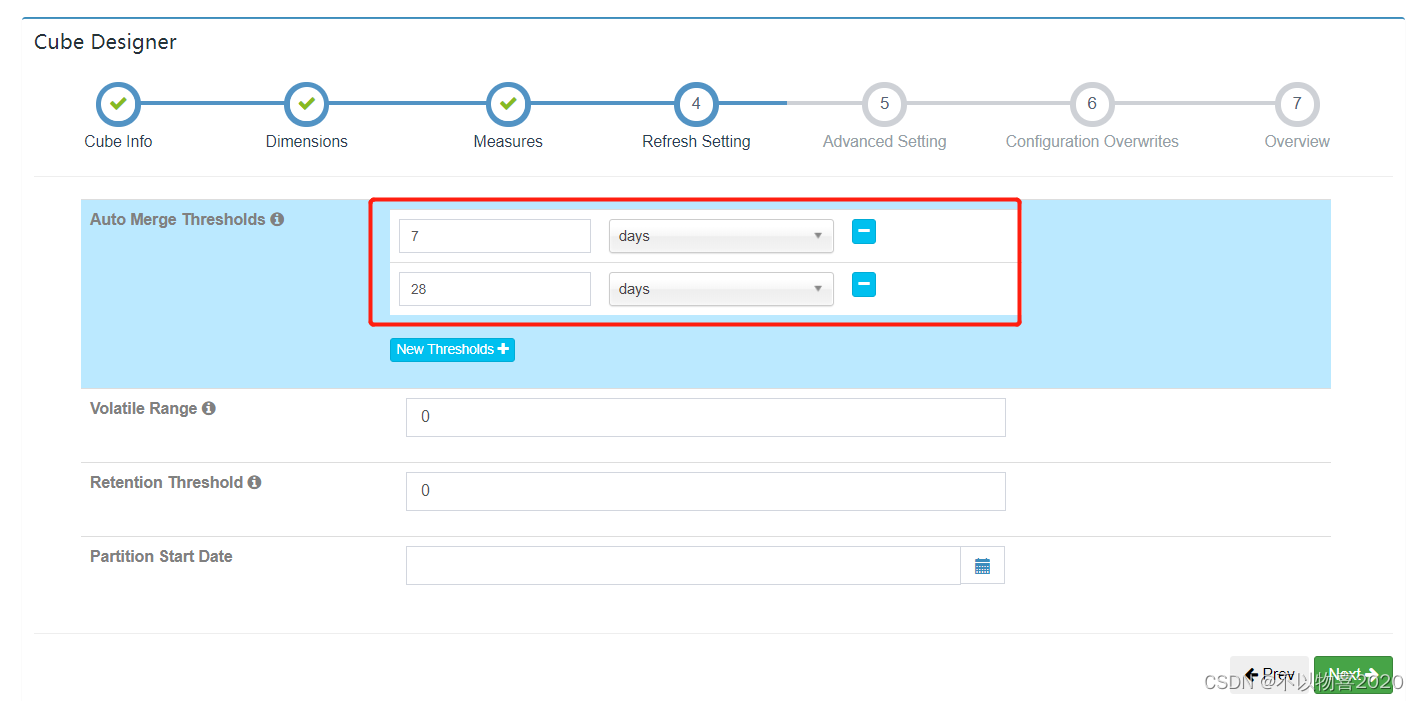
5)cube自动合并设置,cube需按照日期分区字段每天进行构建,每次构建的结果会保存在
Hbase中的一张表内,为提高查询效率,需将每日的cube进行合并,此处可设置合并周期。
6)Kylin高级配置(优化相关,暂时跳过)
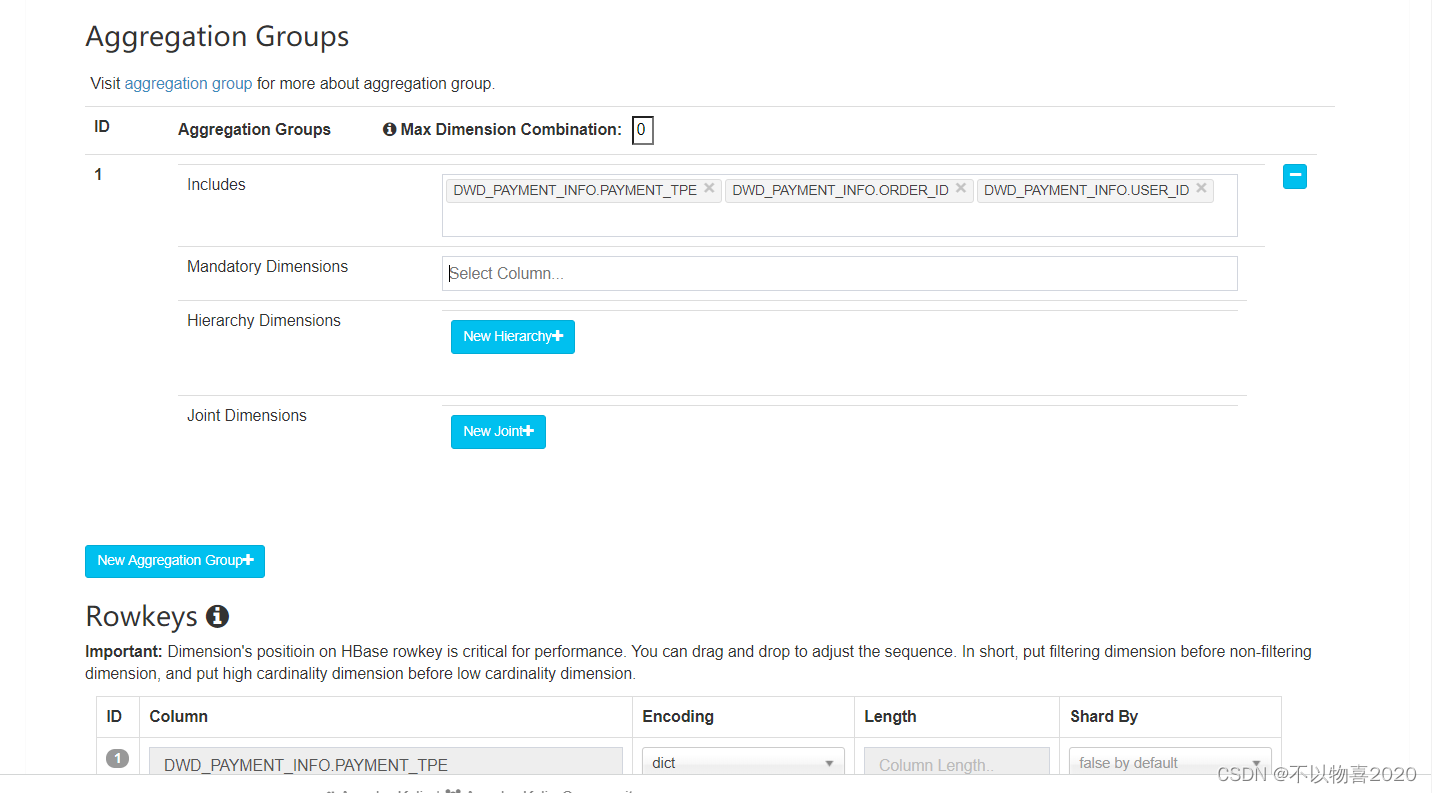
7)Kylin相关属性配置覆盖
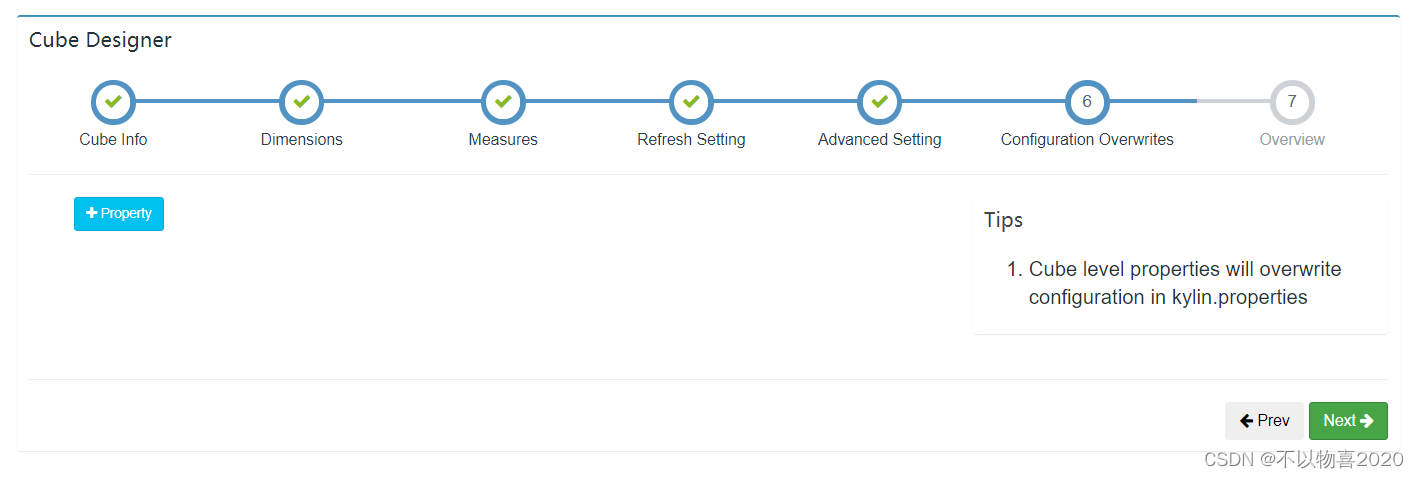
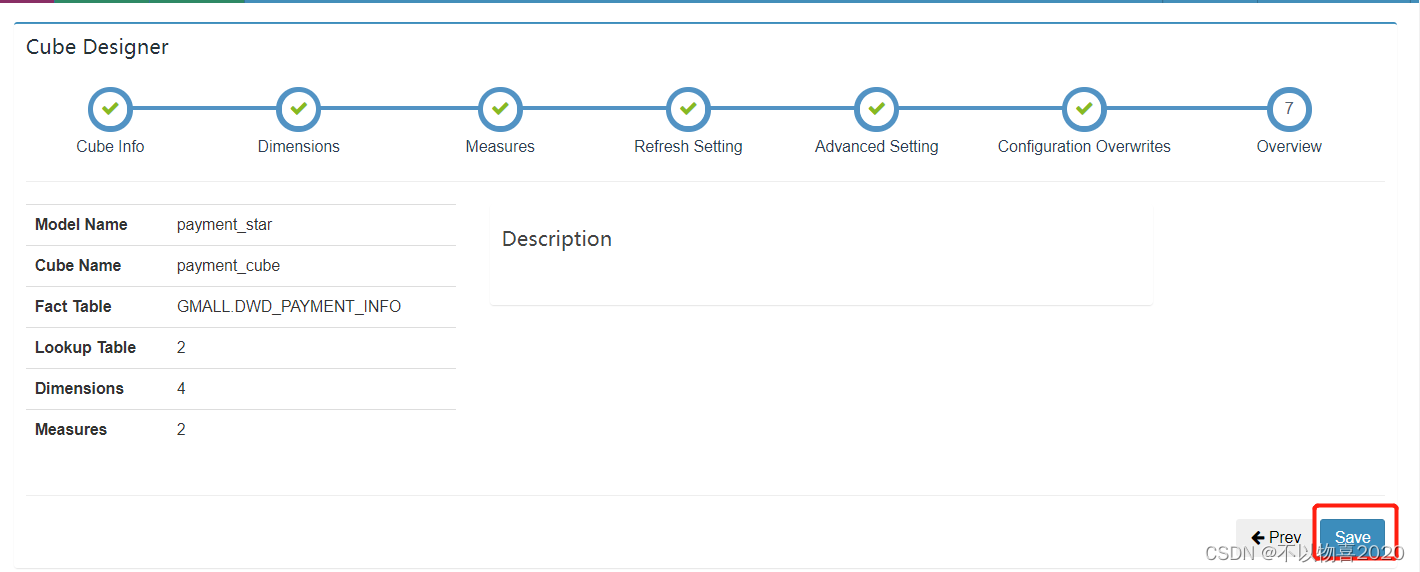
8)Cube信息总览,点击Save,Cube创建完成
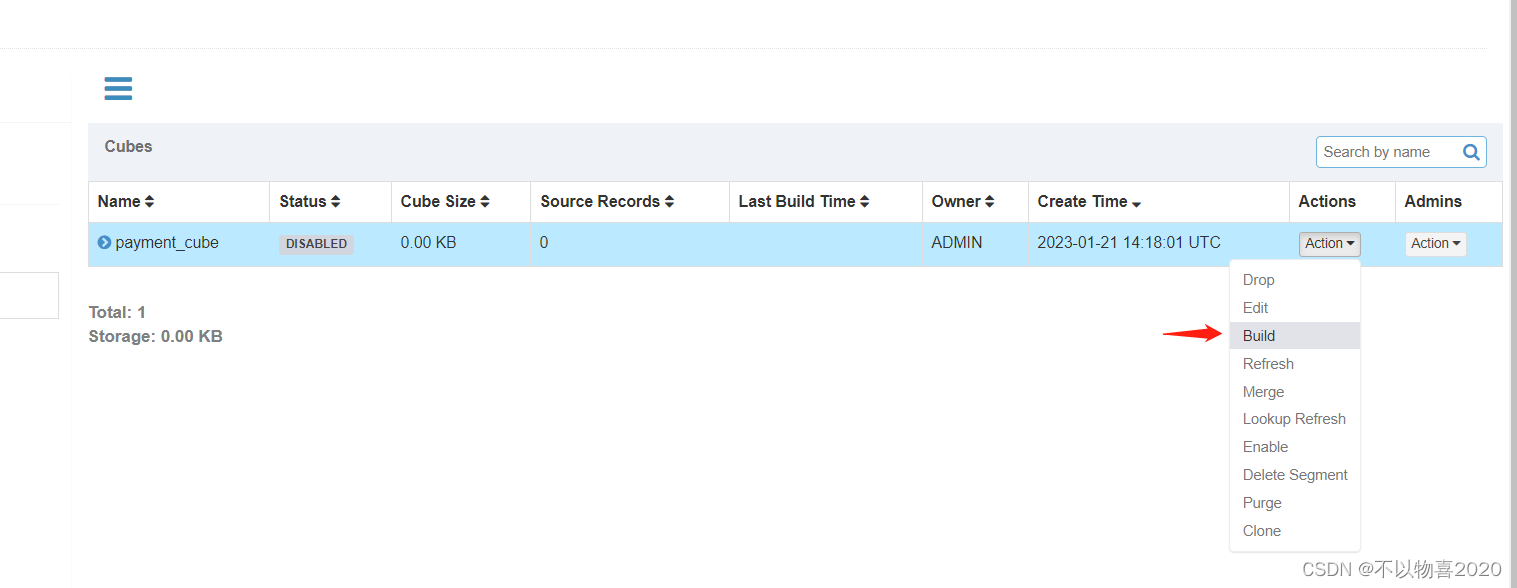
9)构建Cube(计算),点击对应Cube的action按钮,选择build
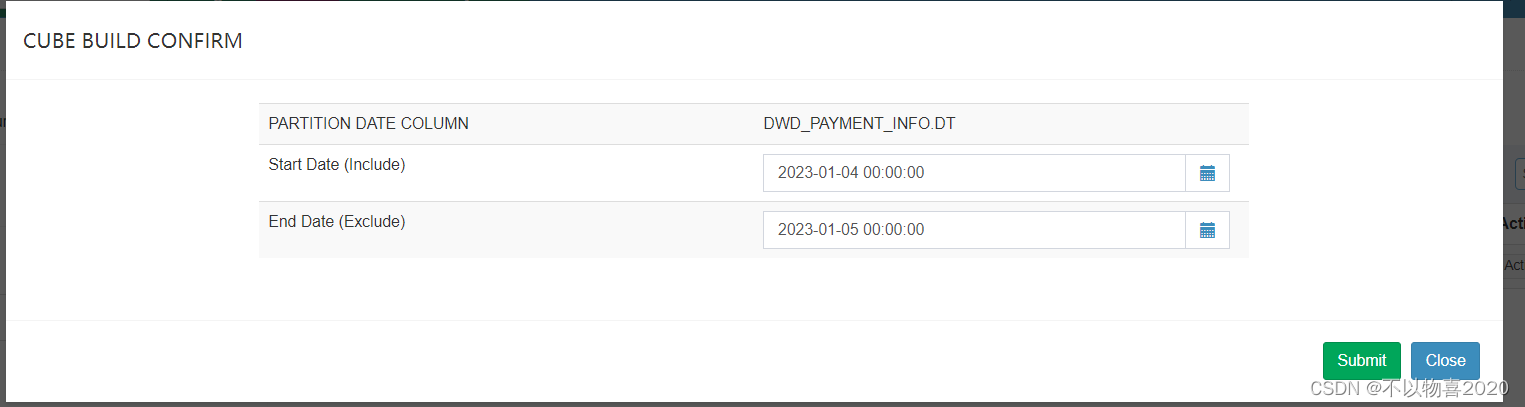
10)选择要构建的时间区间,点击Submit
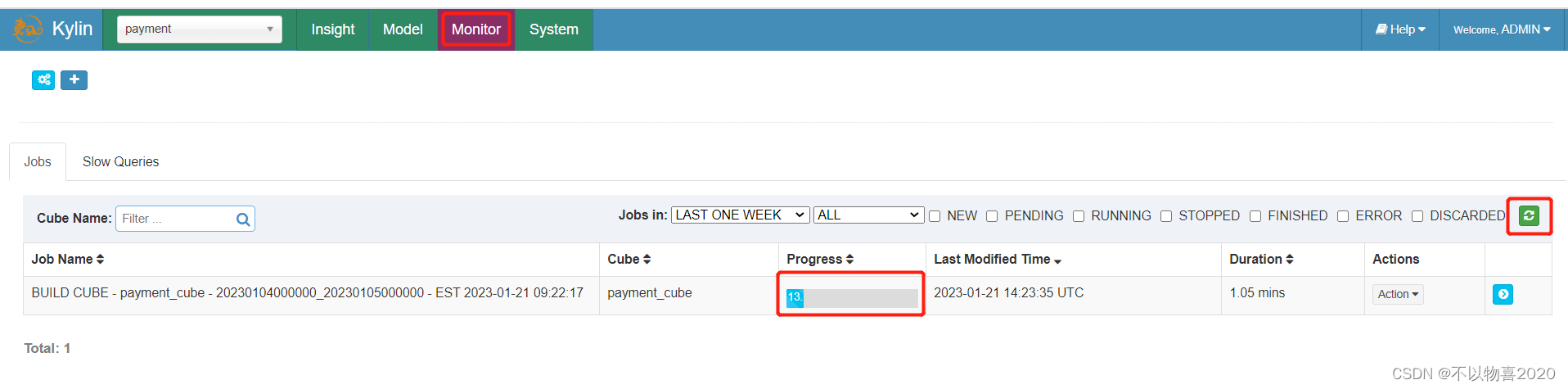
11)点击Monitor查看构建进度
4.5.6 使用进阶
执行上述流程之后,发现报错如下:
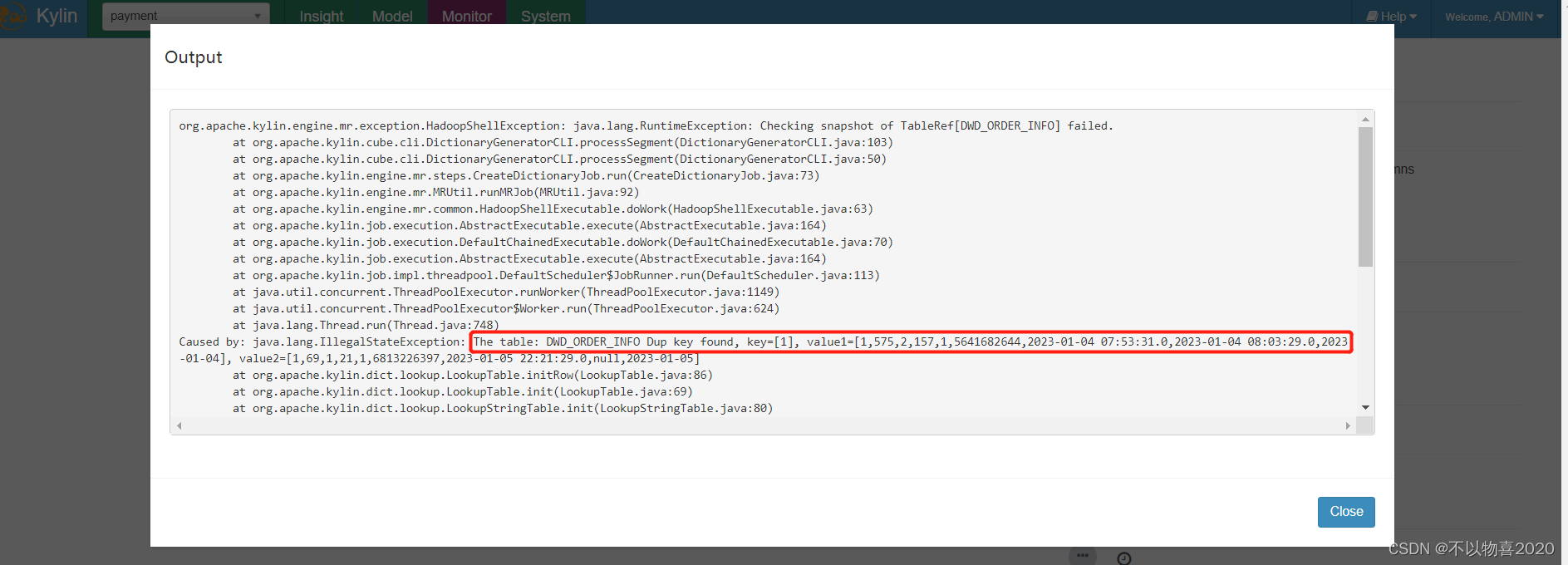
错误原因:上述错误原因是由于model中的维度表dwd_order_info_his为拉链表,dwd_user_info为每日全量表,故使用整张表作为维度表,必然会出现同同一个order_id或user_id对应多条数据的问题.又两种解决方案:
方案一:在hive中创建维度表的临时表,该临时表中只存放维度表最新的一份完整的数据,在kylin中创建模型时选择该临时表作为维度表。
方案二:与方案一思路相同,但不使用物理临时表,而选用视图(view)实现相同的功能。
4.5.7 采用方案二
(1)创建维度表视图
CREATE VIEW dwd_user_info_view as select * from dwd_user_info
WHERE dt='2023-01-04';
CREATE VIEW dwd_order_info_view as select * from dwd_order_info
WHERE dt='2023-01-04';
(2)在DataSource中导入新创建的视图,之前的维度表,可选择性删除。
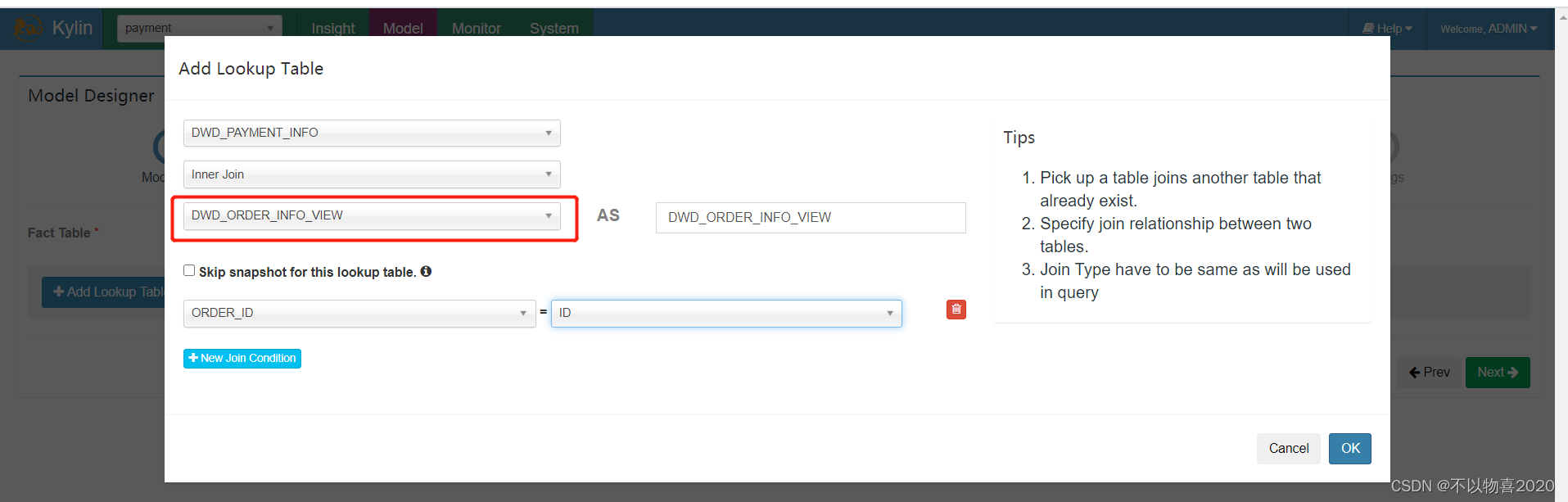
修改后:
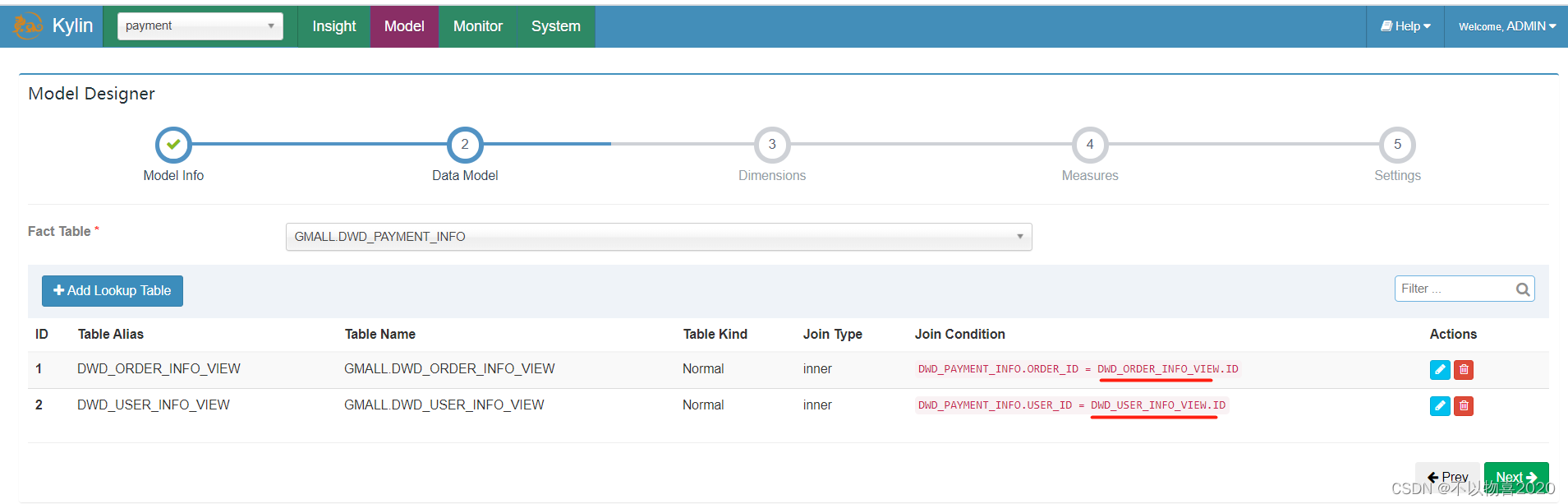
(3)重新创建model、cube
(4)等待重新构建
(5)查询结果
例1:
select user_level,sum(TOTAL_AMOUNT) from DWD_PAYMENT_INFO t1 join DWD_USER_INFO_VIEW t2 on t1.USER_ID = t2.ID
group by user_level
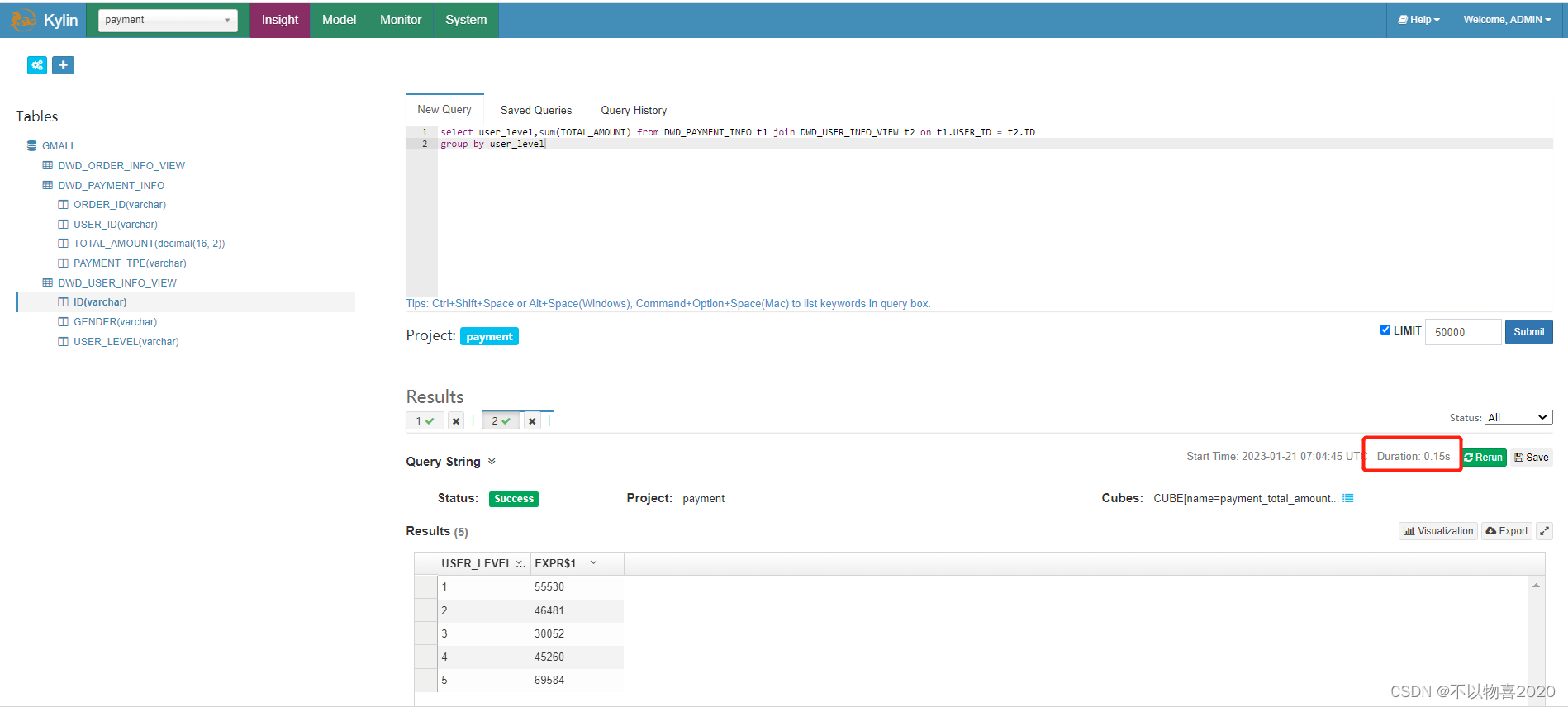
可发现当前耗时0.15秒,可以在在亚秒级别返回。
例2:增加一个性别维度查询
select user_level,gender,sum(TOTAL_AMOUNT) from DWD_PAYMENT_INFO t1 join DWD_USER_INFO_VIEW t2 on t1.USER_ID = t2.ID
group by user_level,gender
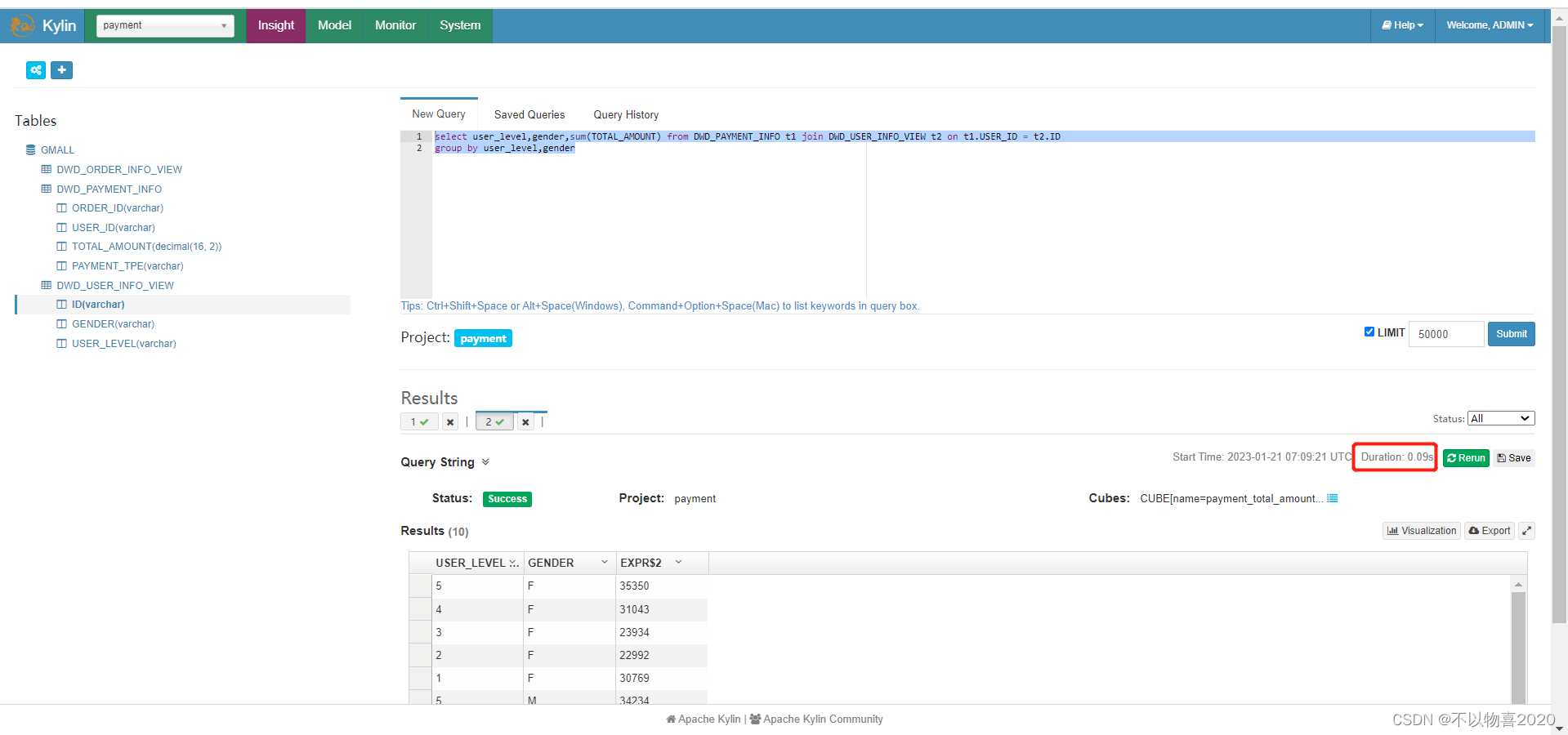
只需要0.09秒,可以在在亚秒级别返回。
4.5.8 Kylin BI工具
4.5.8.1JDBC
项目中导入maven依赖,即可开发,这里不再赘述
<dependencies>
<dependency>
<groupId>org.apache.kylin</groupId>
<artifactId>kylin-jdbc</artifactId>
<version>2.5.1</version>
</dependency>
</dependencies>
4.5.8.2 Zepplin
1)Zepplin安装与启动
(1)将zeppelin-0.8.0-bin-all.tgz上传至Linux
(2)解压zeppelin-0.8.0-bin-all.tgz
(3)修改名称
(4)启动
bin/zeppelin-daemon.sh start

可登录网页查看,web默认端口号为8080
http://wavehouse-1:8080
2)配置Zepplin支持Kylin
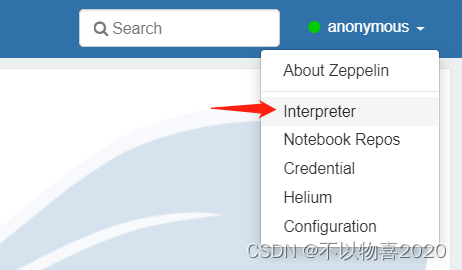
(1)点击右上角anonymous选择Interpreter
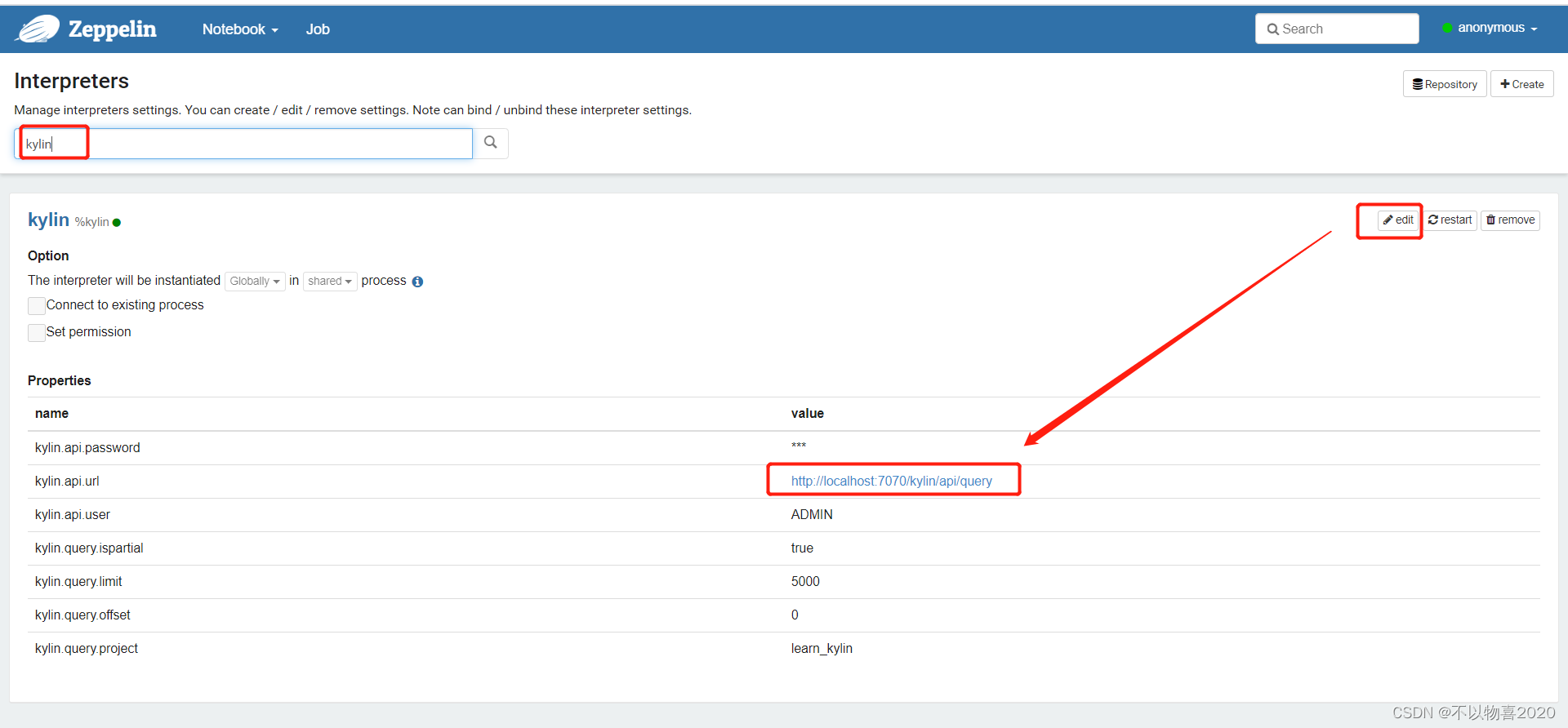
(2)搜索Kylin插件并修改相应的配置
(3)修改完成点击Save完成
3) 创建新的note
(2)填写Note Name点击Create
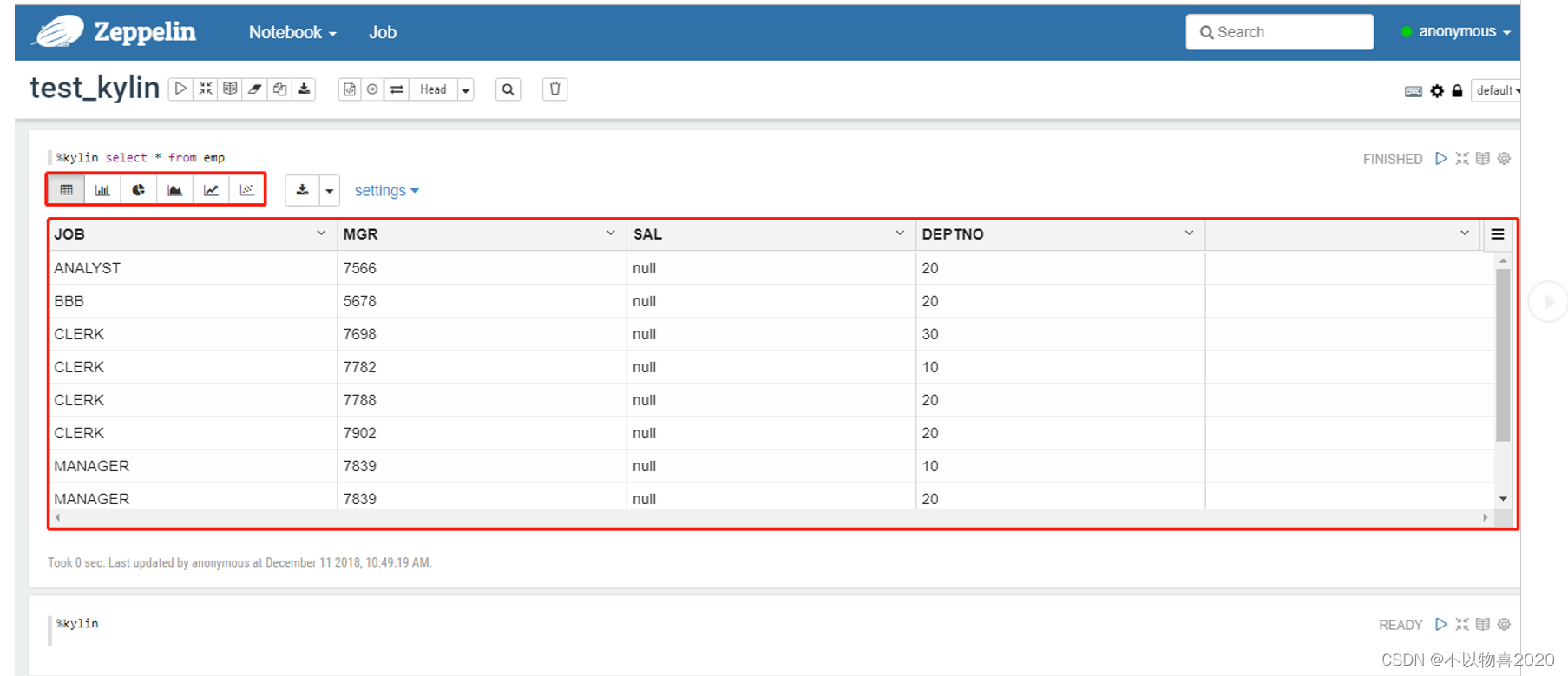
(3) 输入SQL进行查询

(4 )查看查询结果
5 总结
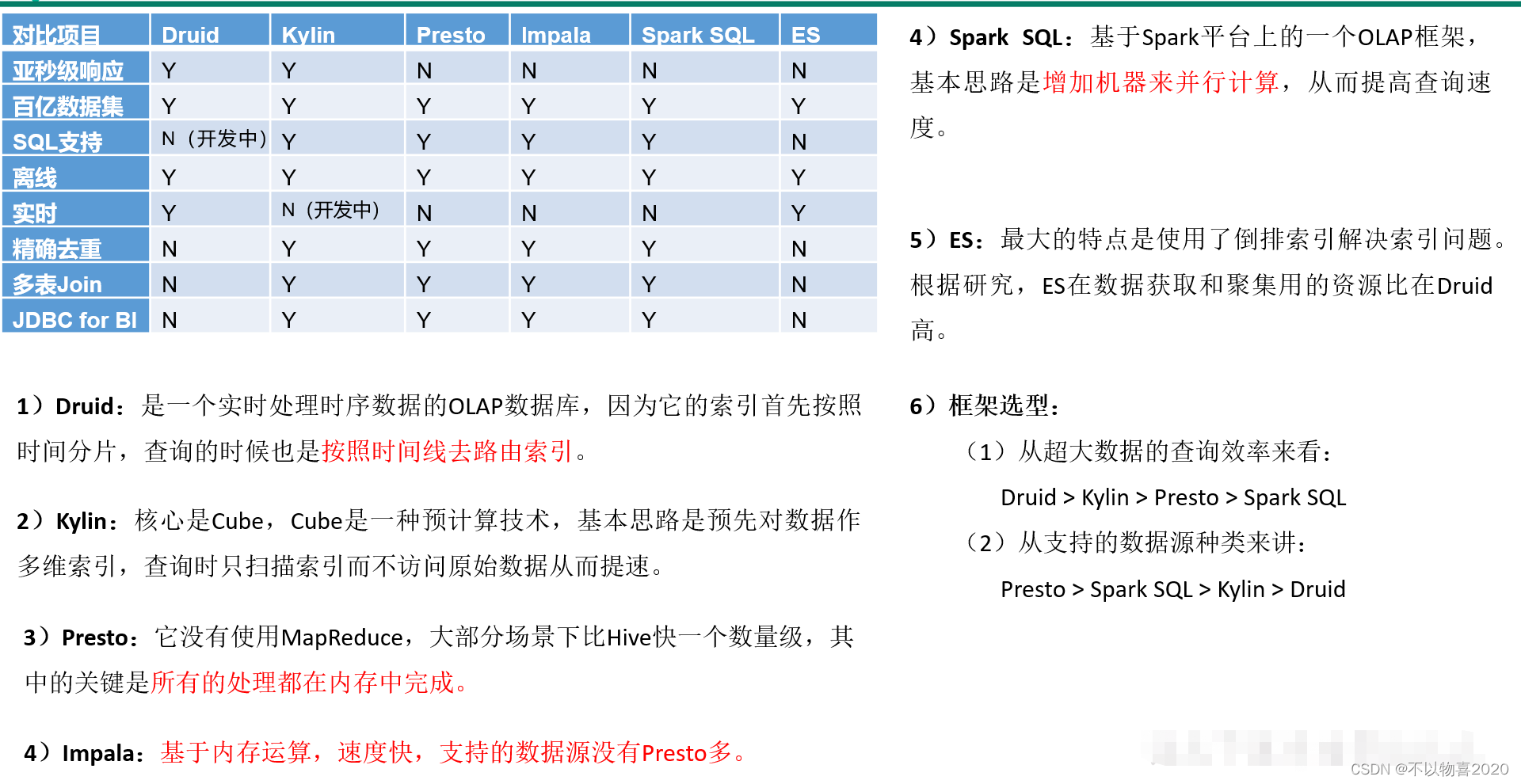
5.1 即席查询对比
Druid/Impala/Presto/Es/Kylin/Spark SQL对比
后面是基于CDH搭建数仓项目,详见《CDH数仓项目(一) —— CDH安装部署搭建详细流程》