无监督
无监督聚类这里使用了Kmeans的聚类方式,适用于凸数据集,当然如果有更好的聚类方式也可以替换的。
输入一系列数据,输出的就是这一系列数据的标签。
看代码
# 导入包
import numpy as np
from sklearn.cluster import KMeans
from yellowbrick.cluster.elbow import kelbow_visualizer
import matplotlib.pyplot as plt
from sklearn import manifold
# 无监督聚类出具labels
def y_knn(X):
data_X = np.array(X)
# 变形状
if len(data_X.shape) == 1:
data_X = data_X.reshape(-1, 1)
# 找出最合适的K
oz = kelbow_visualizer(KMeans(random_state=1, n_init='auto'), data_X, k=(2,20))
k = oz.elbow_value_
# 再进行KMeans聚类
kmeans = KMeans(n_clusters=k, random_state=1, n_init='auto')
kmeans.fit(data_X)
# 获取每个点的类别信息
labels = kmeans.predict(data_X)
return labels
# 原始数据如果是一维的这样画
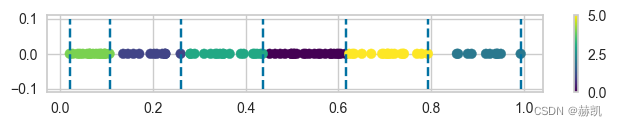
def draw1w(X, labels):
X = np.array(X)
min_arr = []
max_arr = []
for l in range(len(set(labels))):
x = X.reshape(-1)[np.where(labels==l)]
z_min = min(x)
z_max = max(x)
print(z_min, z_max)
min_arr.append(z_min)
max_arr.append(z_max)
print(sorted(min_arr), sorted(max_arr))
li_arr = [sorted(min_arr)[0]] + sorted(max_arr)
print(li_arr)
# L_ARR[i] = li_arr
# 获取簇中心
# centers = kmeans.cluster_centers_
# print(labels, centers)
plt.figure(figsize=(8, 1))
for i_x in li_arr:
# 画两条虚线
plt.plot([i_x, i_x], [-0.1, 0.1], c='b', linestyle='--')
# 可视化聚类结果和分界线
plt.scatter(X.reshape(-1, 1)[:, 0], [0]*len(X.reshape(-1, 1)[:, 0]), c=labels, cmap="viridis")
plt.colorbar()
plt.show()
# 原始数据是多维度的,这样画
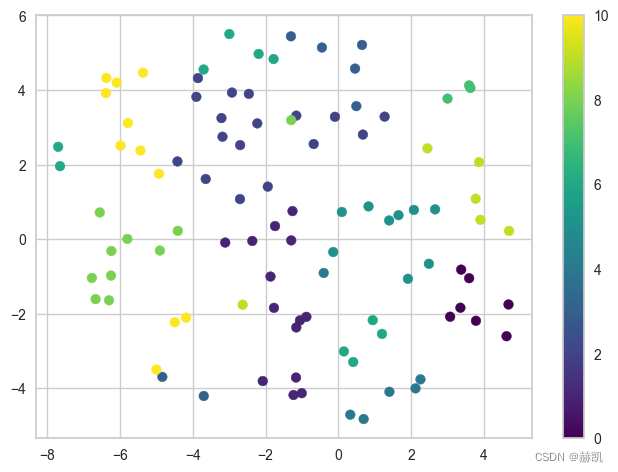
def draw2w(X, labels):
# 将数据降维,降维出来就是X_tsne
tSNE = manifold.TSNE(n_components=2, init='pca', random_state=0)
X_tsne = tSNE.fit_transform(X)
# 画一下
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=labels, cmap="viridis")
plt.colorbar()
plt.show()
看效果
一维数据
X = np.random.random(100)
labels = y_knn(X)
draw1w(X, labels)
多维数据
X = np.random.random((100, 5))
labels = y_knn(X)
draw2w(X, labels)