目录
一、服务器环境准备
切换至root权限:
sudo su -
准备三台虚拟机,虚拟机配置要求如下:
(1)单台虚拟机:内存4G,硬盘50G
(2)修改克隆虚拟机的静态IP
[root@hadoop102 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33改成
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="ens33"
PREFIX=24
IPADDR=192.168.10.102
GATEWAY=192.168.10.2
DNS1=192.168.10.2
(3)查看Linux虚拟机的虚拟网络编辑器,编辑->虚拟网络编辑器->VMnet8
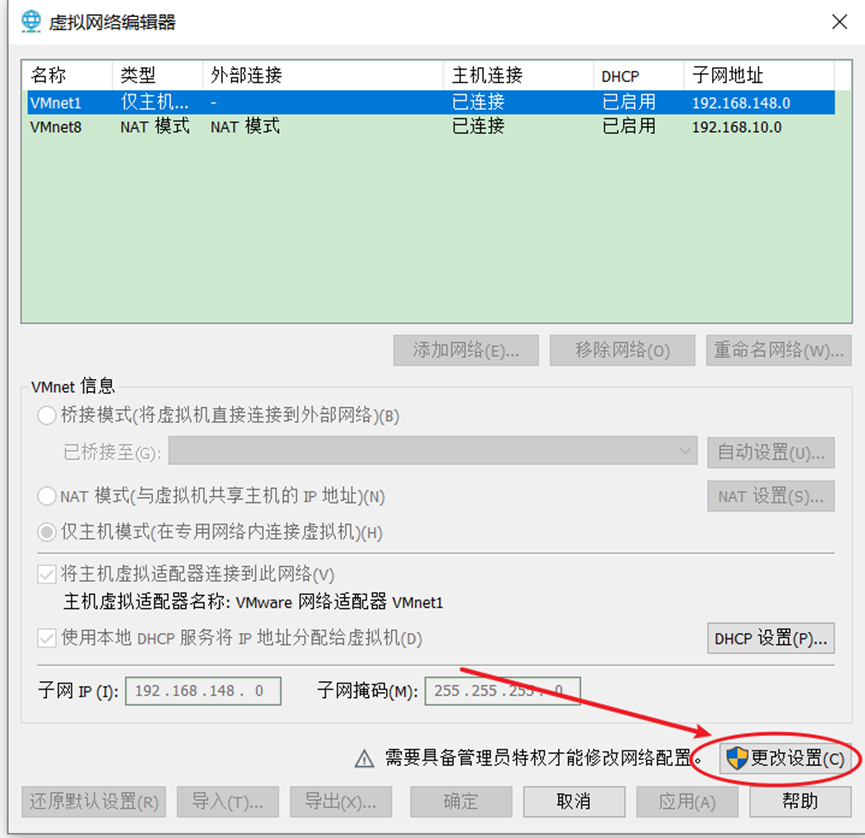


(5)查看Windows系统适配器VMware Network Adapter VMnet8的IP地址
(6)保证Linux文件中IP地址、Linux虚拟网络编辑器地址和Windows系统VM8网络IP地址相同。
2)修改主机名
(1)修改主机名称
[root@hadoop102 ~]# hostnamectl --static set-hostname hadoop102(2)配置主机名称映射,打开/etc/hosts
[root@hadoop102 ~]# vim /etc/hosts添加如下内容
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
(3)修改Windows的主机映射文件(hosts文件)
(a)进入C:\Windows\System32\drivers\etc路径
(b)打开hosts文件并添加如下内容
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
3)关闭并禁用防火墙
[root@hadoop102 ~]# systemctl stop firewalld
[root@hadoop102 ~]# systemctl disable firewalld4)配置普通用户(atguigu)具有root权限
[root@hadoop102 ~]# vim /etc/sudoers修改/etc/sudoers文件,找到下面一行(102行),在%wheel下面添加一行:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
atguigu ALL=(ALL) NOPASSWD: ALL
5)在/opt目录下创建文件夹
(1)在/opt目录下创建module、software文件夹
[root@hadoop102 opt]# mkdir /opt/module /opt/software
(2)修改module、software文件夹的所有者
[root@hadoop102 opt]# chown atguigu:atguigu /opt/module /opt/software
6)重启
[root@hadoop102 module]# reboot
1.2 编写集群分发脚本xsync
1)xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析
① rsync命令原始拷贝:
rsync -av /opt/module root@hadoop103:/opt/
② 期望脚本:
xsync要同步的文件名称
③ 说明:在/home/atguigu/bin这个目录下存放的脚本,atguigu用户可以在系统任何地方直接执行。
(3)脚本实现
① 在用的家目录/home/atguigu下创建bin文件夹
[atguigu@hadoop102 ~]$ mkdir bin
②在/home/atguigu/bin目录下创建xsync文件,以便全局调用
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 bin]$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
③ 修改脚本xsync具有执行权限
[atguigu@hadoop102 bin]$ chmod +x xsync
④ 测试脚本
[atguigu@hadoop102 bin]$ xsync xsync
1.3 SSH无密登录配置
说明:这里面只配置了hadoop102、hadoop103到其他主机的无密登录;因为hadoop102未外配置的是NameNode,hadoop103配置的是ResourceManager,都要求对其他节点无密访问。
(1)hadoop102上生成公钥和私钥:
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(2)将hadoop102公钥拷贝到要免密登录的目标机器上
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
(3)hadoop103上生成公钥和私钥:
[atguigu@hadoop103 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(4)将hadoop103公钥拷贝到要免密登录的目标机器上
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop104
1.4 JDK准备
1)卸载现有JDK(3台节点)
[atguigu@hadoop102 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
[atguigu@hadoop103 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
[atguigu@hadoop104 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
(1)rpm -qa:表示查询所有已经安装的软件包
(2)grep -i:表示过滤时不区分大小写
(3)xargs -n1:表示一次获取上次执行结果的一个值
(4)rpm -e --nodeps:表示卸载软件
2)用Xftp工具将JDK导入到hadoop102的/opt/software文件夹下面
点击图标打开Xftp

左侧窗口对应windows文件系统,右侧窗口对应Linux文件系统,找到对应目录,将JDK拖动到右侧窗口即可完成上传。
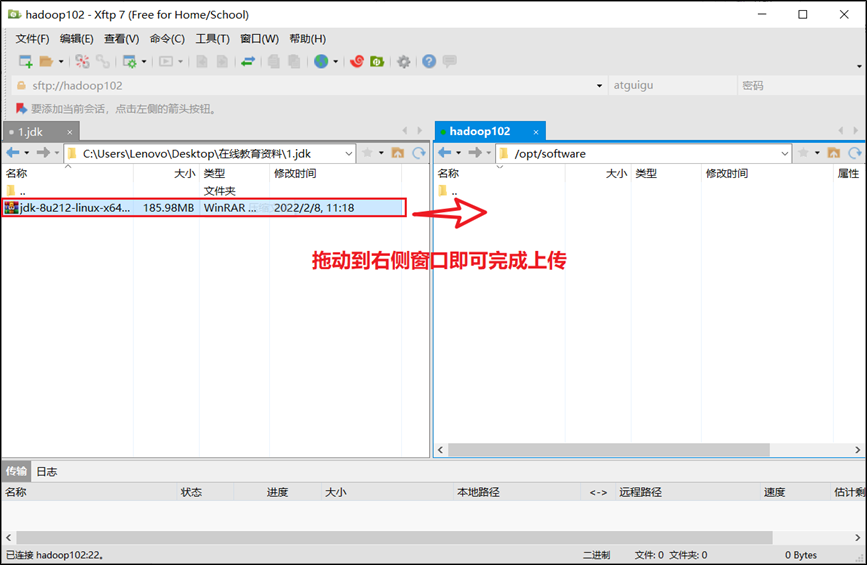
3)在Linux系统下的opt目录中查看软件包是否导入成功
[atguigu@hadoop102 software]# ls /opt/software/
看到如下结果:
jdk-8u212-linux-x64.tar.gz
4)解压JDK到/opt/module目录下
[atguigu@hadoop102 software]# tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
5)配置JDK环境变量
(1)新建/etc/profile.d/my_env.sh文件
[atguigu@hadoop102 module]# sudo vim /etc/profile.d/my_env.sh
添加如下内容,然后保存(:wq)退出
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
(2)让环境变量生效
[atguigu@hadoop102 software]$ source /etc/profile.d/my_env.sh
6)测试JDK是否安装成功
[atguigu@hadoop102 module]# java -version
如果能看到以下结果、则Java正常安装
java version "1.8.0_212"
7)分发JDK
[atguigu@hadoop102 module]$ xsync /opt/module/jdk1.8.0_212/
8)分发环境变量配置文件
[atguigu@hadoop102 module]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
9)分别在hadoop103、hadoop104上执行source
[atguigu@hadoop103 module]$ source /etc/profile.d/my_env.sh
[atguigu@hadoop104 module]$ source /etc/profile.d/my_env.sh
1.5 环境变量配置说明
Linux的环境变量可在多个文件中配置,如/etc/profile,/etc/profile.d/*.sh,~/.bashrc,~/.bash_profile等,下面说明上述几个文件之间的关系和区别。
bash的运行模式可分为login shell和non-login shell。
例如,我们通过终端,输入用户名、密码,登录系统之后,得到就是一个login shell。而当我们执行以下命令ssh hadoop103 command,在hadoop103执行command的就是一个non-login shell。
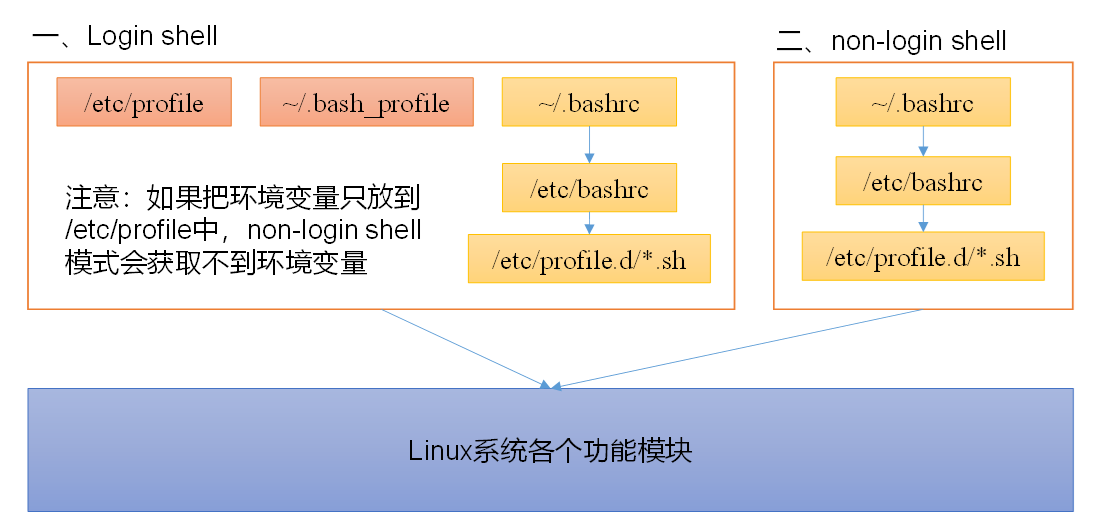
这两种shell的主要区别在于,它们启动时会加载不同的配置文件,login shell启动时会加载/etc/profile,~/.bash_profile,~/.bashrc。non-login shell启动时会加载~/.bashrc。
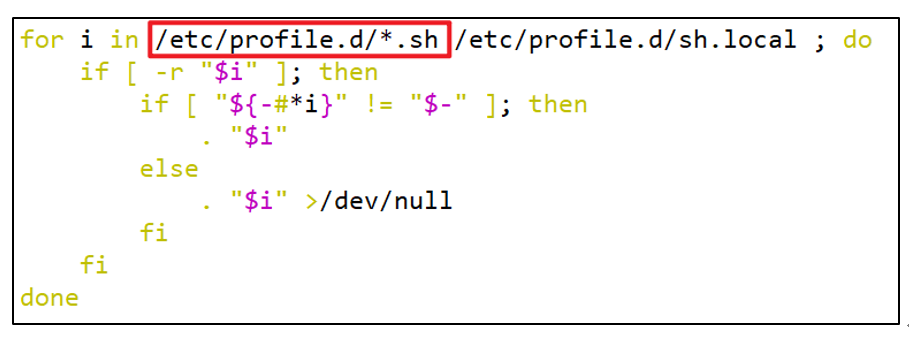
而在加载~/.bashrc(实际是~/.bashrc中加载的/etc/bashrc)或/etc/profile时,都会执行如下代码片段,因此不管是login shell还是non-login shell,启动时都会加载/etc/profile.d/*.sh中的环境变量。
二、集群所有进程查看脚本
1)在/home/atguigu/bin目录下创建脚本xcall.sh
[atguigu@hadoop102 bin]$ vim xcall.sh
2)在脚本中编写如下内容
#! /bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo --------- $i ----------
ssh $i "$*"
done3)修改脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 xcall.sh
4)启动脚本
[atguigu@hadoop102 bin]$ xcall.sh jps
三、Zookeeper安装
3.1 分布式安装部署
1)集群规划
在hadoop102、hadoop103和hadoop104三个节点上部署Zookeeper。
| 服务器hadoop102 |
服务器hadoop103 |
服务器hadoop104 |
|
| Zookeeper |
Zookeeper |
Zookeeper |
Zookeeper |
2)解压安装
(1)解压Zookeeper安装包到/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module/
(2)修改/opt/module/apache-zookeeper-3.7.1-bin名称为zookeeper
[atguigu@hadoop102 module]$ mv apache-zookeeper-3.7.1-bin/ zookeeper
3)配置服务器编号
(1)在/opt/module/zookeeper/目录下创建zkData
[atguigu@hadoop102 zookeeper]$ mkdir zkData
(2)在/opt/module/zookeeper/zkData目录下创建一个myid的文件
[atguigu@hadoop102 zkData]$ vim myid
添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码
在文件中添加与server对应的编号:
2
4)配置zoo.cfg文件
(1)重命名/opt/module/zookeeper/conf目录下的zoo_sample.cfg为zoo.cfg
[atguigu@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
(2)打开zoo.cfg文件
[atguigu@hadoop102 conf]$ vim zoo.cfg
修改数据存储路径配置
dataDir=/opt/module/zookeeper/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
(3)同步/opt/module/zookeeper目录内容到hadoop103、hadoop104
[atguigu@hadoop102 module]$ xsync zookeeper/
(4)分别修改hadoop103、hadoop104上的myid文件中内容为3、4
(5)zoo.cfg配置参数解读
server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的地址;
C是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
5)集群操作
(1)分别启动Zookeeper
[atguigu@hadoop102 zookeeper]$ bin/zkServer.sh start
[atguigu@hadoop103 zookeeper]$ bin/zkServer.sh start
[atguigu@hadoop104 zookeeper]$ bin/zkServer.sh start
(2)查看状态
[atguigu@hadoop102 zookeeper]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[atguigu@hadoop103 zookeeper]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[atguigu@hadoop104 zookeeper]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg
Mode: follower3.2 ZK集群启动停止脚本
1)在hadoop102的/home/atguigu/bin目录下创建脚本
[atguigu@hadoop102 bin]$ vim zk.sh
在脚本中编写如下内容。
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper/bin/zkServer.sh status"
done
};;
esac2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 zk.sh
3)Zookeeper集群启动脚本
[atguigu@hadoop102 module]$ zk.sh start
4)Zookeeper集群停止脚本
[atguigu@hadoop102 module]$ zk.sh stop
3.3 客户端命令行操作
| 命令基本语法 |
功能描述 |
| help |
显示所有操作命令 |
| ls path |
使用 ls 命令来查看当前znode的子节点 -w 监听子节点变化 -s 附加次级信息 |
| create |
普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
| get path |
获得节点的值 -w 监听节点内容变化 -s 附加次级信息 |
| set |
设置节点的具体值 |
| stat |
查看节点状态 |
| delete |
删除节点 |
| deleteall |
递归删除节点 |
1)启动客户端