文章:FedCut: A Spectral Analysis Framework for Reliable Detection of Byzantine Colluders
目录
摘要
提出的框架描述了从光谱分析镜头中拜占庭共谋者的模型更新之间的强一致性和时间一致性,并将拜占庭不当行为的检测表述为加权图中的社区检测问题。然后利用改进的归一化图切割来识别攻击者和良性参与者。
研究表明,FedCut的平均MP比最先进的拜占庭弹性方法高出2.1%至16.5%。在最坏情况下模型性能(MP)方面,FedCut比这些方法提高了17.6%至69.5%。
一、引言
大量的研究工作致力于开发许多拜占庭弹性方法,这些方法可以有效地检测和减弱这种错误行为。最近的研究指出,一群攻击者可能会合谋造成比这些拜占庭弹性方法所能处理的更大的破坏。
拜占庭合谋带来了两个主要挑战:
- 首先,共谋者可能合谋一致地不当行为,并引入统计偏差来破坏基于稳健统计(RS)的弹性方法。因此,全局模型的性能可能会显著恶化。
- 其次,Byzantine共谋者可能会密谋违反这样的假设:所有恶意模型更新都会形成一组,而良性模型更新则形成另一组,大多数基于集群的拜占庭弹性方法都总是假设这一点。
通过提交多组这种有害但伪装的模型更新,共谋者因此可以逃避基于聚类的方法,并显著降低全局模型性能。
文章的贡献:
- 提供了拜占庭攻击的光谱分析。
- 提出了FedCut
- 做了很多实验
二、相关工作
解释了两种Byzantine attacks:合谋和非合谋。
解释了基于鲁棒统计的聚合方法,将恶意模型更新视为离良性客户端较远的异常值,并通过稳健统计过滤出异常值。例如,提出了坐标中值和中值的一些变体,如几何中值,以去除异常值。
解释了基于聚类的健壮聚合方法,例如,一些方法将Kmeans应用于良性和拜占庭客户端和satler等人的聚类。
解释了基于服务器的健壮聚合方法,基于服务器的健壮聚合假设服务器有一个额外的训练数据集,用于评估上传的模型更新。这种方法不适用于服务器端数据不可用的情况,如果服务器端数据的分布与客户端训练数据的分布相差很大,可能会导致系统崩溃。
解释了基于历史信息的拜占庭鲁棒方法。利用历史信息(如分布式Momentums)来帮助纠正训练过程中由共谋者带来的统计偏差,从而导致联邦学习的优化收敛。
解释了图中的团体检测,拜占庭共谋的检测被视为一个大加权图中的多个子图或社区的检测。
三、预备知识
3.1 联邦学习
介绍了一下基本概念
3.2 联邦学习中的拜占庭攻击
假设存在恶意威胁模式,其中K个客户机中的未知数量的参与者是拜占庭式的,即他们可能上传任意损坏的更新以降低全局模型性能(MP)。
四、拜占庭共谋导致失败的案例
4.1 联邦学习的加权无向图
假设这里有K个客户,那么就有无向图,其中V代表K个模型的更新,E是一组加权边,表示上传的模型更新对应于V中的客户端之间的相似性。我们假设两个节点
的权值都是非负的,比如:
其中,是上传梯度的第
个客户端和
是高斯比例因子。设
和
分别表示G的两个子图,分别表示良性客户端和拜占庭客户端。
拜占庭问题可以看作是:为G寻找一个最优的图切,以区分拜占庭和良性模型更新。由于来自共谋者的模型更新形成了特定的模式,因此上述图切割可以推广到所谓的社区检测问题,其中多个紧密连接的节点子集需要相互分离。
4.2 拜占庭攻击者的谱图分析
这章说明了代表拜占庭攻击的光谱分析,特别是那些由共谋者发起的攻击。例如,图2显示了邻接矩阵,其中的元素表示IID设置下70个良性客户端和30个攻击者之间的成对相似性。
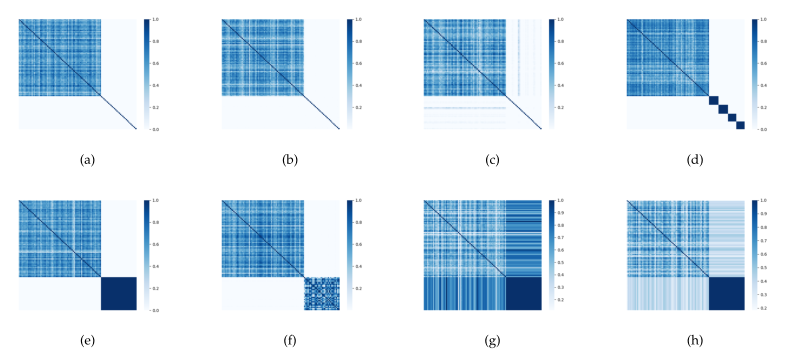
图为,在IID设置下,第1000次迭代时,包含30个攻击者的100个客户端,8种攻击类型的邻接矩阵。在每个子图中,良性客户端形成一个单独的相干集群,位于相邻矩阵的左上块,而攻击者位于相邻矩阵的右下部分。采用尺度因子 = 10,对MNIST数据集进行逻辑回归。从左到右,从上到下,攻击方法分别为:
- (a)高斯攻击
- (b)标签翻转
- (c)符号反转
- (d)多共谋攻击
- (e)同值攻击
- (f)Fang-v1(设计为修建平均值)
- (g)Mimic攻击
- (h)Lie攻击
很明显,在每个子图中,良性客户端形成一个单独的相干集群,位于相邻矩阵的左上块,而攻击者位于相邻矩阵的右下部分。我们观察到与良性模型更新和拜占庭模型更新有关的以下特征:
首先,良性模型更新形成一个单独的组,这由假设1正式说明:

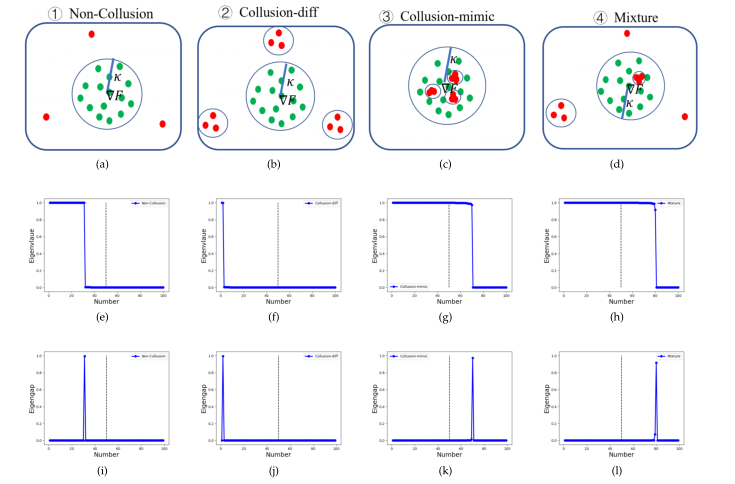
其次,拜占庭模型更新可以分为四种类型,如上图所示:
- 非共谋:
,而恶意更新
彼此相距很远,比如a、b、c。
- 差异共谋:
- 模仿共谋:
,不同攻击者的
),它表示具有强关联的对手形成一个或多个集群(簇内距离小),他们的行为与少数被选中的良性客户非常相似,但与其他良性客户不同。比如g、h。
- 混合:对手可以任意组合非共谋、差异共谋和模仿共谋来获得混合攻击。
这里说的频谱分析就是指,特征值和相邻特征值差(在线性代数中,线性算子的特征值是两个连续特征值之间的差,其中特征值按升序排序)。
我们用一个具体的例子来说明图3中四种攻击类型的不同频谱,其中每一列代表一种攻击类型。我们观察到以下特性:(所有的例子都包括70个良性客户端和30个攻击者)
- 对于非共谋攻击,我们使用高斯攻击在
之后上传大量不同的随机更新。从图3(e)和(i)可以看出,邻接矩阵L的特征值在索引30和31之间急剧下降,即最大的特征值位于索引31。
- 对于差异共谋攻击,我们使用同值攻击来上传由所有一个元素组成的更新,图3(f)和(j)说明最大的相邻特征差在于2,说明良性客户端组成一组,强连接的勾结者组成另一组。
- 对于共谋模仿攻击,我们使用模仿攻击来上传模仿一个良性更新的更新,最大的相邻特征差为70,因为拜占庭共谋者和模仿的良性客户端组成一个组,而其余69个良性客户端分别组成69个组,如图3(g)和(k)所示。这是因为模拟共谋者之间的联系比良性客户之间的联系要强得多。
- 对于混合攻击,我们将高斯攻击(5个攻击者)、同值攻击(5个攻击者)和模拟攻击(20个攻击者)组合在一起。从图3(h)和(l)可以看出,最大的eigengap为80,其中模拟共谋者和一个模拟良性客户构成一组。相反,69个良性客户端和10个攻击者分别组成79个组。这个例子展示了模仿攻击主导了混合攻击的光谱特征。因此,对于本文提出的方法,首先检测并消除了模仿共谋类型的攻击,然后检测其他两种类型的攻击。
4.3 失败案例分析
评估了两种典型的拜占庭弹性方法(稳健统计和基于聚类的聚合方法)和提出的FedCut方法(5.2节),以测试4.2节中提到的四种拜占庭攻击。为了方便描述,我们定义拜占庭容忍率(BTR):具体来说,我们假设10次良性模型更新遵循一维高斯分布,并看到四种类型的拜占庭攻击(S1-S4)如表所示。

接下来,我们提供了上面提到的四种拜占庭攻击类型的一个典型示例,以说明现有的拜占庭弹性方法的失败案例。为了在四种场景下评估不同的拜占庭-弹性方法,我们定义了拜占庭容忍率,表示拜占庭容忍案例在重复攻击运行中的比例:
- 拜占庭容忍率:假设服务器收到
个正确的梯度,集合表示为
;同时服务器收到
个拜占庭梯度,集合表示为
。一个拜占庭鲁棒方法
可以被称作对一个特定拜占庭攻击具有拜占庭容忍性,当且仅当:
- 此外,
下表总结了上述四种拜占庭攻击下不同拜占庭弹性方法的示例结果。
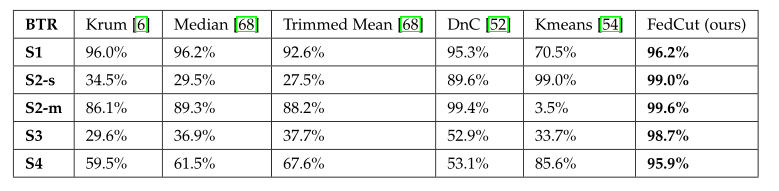
我们可以得出以下结论:
- 首先,对于非合谋攻击(S1),除Kmeans外,其他拜占庭弹性方法都表现良好(即BTR大于90%),说明非合谋攻击易于防御。
- 其次,对于差异合谋攻击(S2),基于鲁棒统计的方法如Krum,Median, Mean和DnC容易受到S2-s攻击。这种失败主要是由于样本均值或中位数的错误估计被共谋者的有偏差的模型更新所误导。此外,基于聚类的Kmeans方法在S2-m中失败,BTR低至3.5%。这是因为基于聚类的方法依赖于只有一组串谋者存在的假设,但在S2-m中有两组或更多的串谋者被基于错误假设的朴素聚类方法错误分类。
- 第三,对于模仿合谋攻击(S3),基于稳健统计的方法和基于聚类的方法都失败,BTR低于52.9%。主要原因是共谋者会对良性更新引入统计偏差,共谋者的类似行为很难被发现。
-
最后,提出的FedCut方法能够防御所有高BTR(超过95%)的攻击,使用时空框架和频谱启发式,如第5节所示。