1、链表的定义、创建、插入、查找、删除:
#include<stdio.h>
#include<stdlib.h>
//链表的定义//
struct node{
int data; //数据域
node *next; //指针域,只想下一个元素
};
//链表的创建//
node* creatlist(int arr[],int len){ //建立链表
node*head,*pre,*p;
head=new node; //创造头结点
head->next=NULL;
pre=head; //pre赋值
for(int i=0;i<len;i++){
p=new node;
p->data=arr[i]; //赋值给数据域
p->next=NULL; //最后一个节点的指针域置空
pre->next=p; //新结点连到链表的结尾
pre=p; //pre指向链表的最后一个结点
}
return head;
}
//链表的插入//
void insert(node*head,int pos,int x){ //实现将一个数据插入到链表的指定位置pos处
node*p,*pre;
pre=head;
p=new node; //分配新结点
p->data=x;
while(--pos){ //将pre指针定位到pos位置的前面
pre=pre->next;
}
p->next=pre->next; //先将pre的next赋值给p ,将pre所指结点后面所有的结点连接到p所指的结点
pre->next=p; //将p所指的结点链接到pre所指结点后面。
}
//链表的查找//
int search(node*head,int x){ //实现在链表中查找数据域等于x的结点的个数
int count=0; //计数器,初始化为零
node*p=head->next;
while(p!=NULL){
if(p->data==x){ //找到一个结点,计数器加一
count++;
}
p=p->next; //p往后挪一个位置
}
return count; //返回查找结果
}
//链表的删除//
void del(node*head,int x){ //实现将链表所有数据域等于x的结点删除
node *pre,*p;
pre=head; //pre指针始终指向被删除结点的前置结点
p=pre->next; //p指针为工作指针,用于遍历链表
while(p!=NULL){
if(p->data ==x){ //如果是要被删除的结点
pre->next =p->next;
delete(p); //要记得用过的内存还给操作系统
p=pre->next ; //p指针更新到pre指针的后面
}
else {
pre=p; //如果不是要删除的结点那么两个指针分别后移,这一步该为pre=pre->next;
p=p->next ;
}
}
}
//主函数//
int main()
{
int arr[7]={5,4,7,3,3,9,0}; //这个是例子。
node*L=creatlist(arr,7),*p;
insert(L,2,12);
del(L,3);
p=L->next;
while(p!=NULL){
printf("%d ",p->data);
p=p->next;
}
}2、两个单链表的第一个公共结点。
方法1:粗暴的办法。
从一个链表的第一个结点开始,再另一个链表上查找是否是交点(指向结点的指针一样),这样的话,如果一个链表的长度是m,另一个链表的长度是n,则时间复杂度是O(mn)。
方法2:从后往前遍历
我们知道链表相交,不仅仅只是结点里的data值一样,next指针也是一样的,也就是说,如果两个链表从某一个结点处开始相交,那么之后两个链表一定是相交的。即就是,链表的相交模型不会是X型,而是Y型。所以我们可以从后向前找第一个交点,但是这里是单链表,只能从后向前遍历,所以这里采用数据结构stack,将结点的信息存储在栈中,从栈顶开始比较两个结点,如果不一样,则就说明不相交,如果一样,记住当前结点,将两个栈的栈顶元素出栈,继续比较下一个结点,就这样,直到找到不一样的结点,那么上一个结点就是第一个公共结点。但是这种办法需要两个辅助栈,不是最好的办法
方法3:快慢指针法
求出两个链表的长度,让长的链表先走两个链表长度之差的绝对值步,然后两个链表一起走,直到找到第一个公共结点。这就是所谓的快慢指针法。
方法4:通过环来看
如果两个单链表相交,将链表的尾和其中任何一个链表的头相接,就会构成一个环,求出环的入口就是连个链表的第一个公共结点;如果链表不相交,就不会构成环。判断链表相不相交的办法,就是直接看他们的最后一个结点是否一样。这种办法之后的文章(判断链表是否带环以及环的入口)会实现,这里暂时不实现。
代码实现(包括测试代码):
#include<iostream>
using namespace std;
//链表结点的定义//
struct ListNode
{
int _data;
ListNode* _pNext;
ListNode(int x = 0):_data(x),_pNext(NULL){}
};
//链表的创建//
ListNode* Create(int arr[],int n)
{
ListNode* head = new ListNode(arr[0]);
ListNode* prev = head;
ListNode* cur = prev;
for(int i = 1; i < n; ++i)
{
cur = new ListNode(arr[i]);
prev->_pNext = cur;
prev = cur;
}
return head;
}
//获取链表的长度//
size_t GetLength(ListNode* head)
{
size_t len = 0;
ListNode* cur = head;
while(cur)
{
++len;
cur = cur->_pNext;
}
return len;
}
//获取连个链表的第一的相交点//
ListNode* GetFirstCommonNode(ListNode* head1,ListNode* head2)
{
size_t len1 = GetLength(head1);
size_t len2 = GetLength(head2);
ListNode* pLong = head1;
ListNode* pShort = head2;
int diff = len1 - len2;
if(diff < 0)//第一个链表比第二个链表短
{
pLong = head2;
pShort = head1;
diff = len2 - len1;
}
//让长的链表先走diff步
for(int i = 0; i < diff; ++i)
{
pLong = pLong->_pNext;
}
//两个链表一起向后走找第一个交点
while(pLong != NULL && pShort != NULL && pLong != pShort)
{
pLong = pLong->_pNext;
pShort = pShort->_pNext;
}
if(pLong && pShort == 0)//没有找到公共结点
return NULL;
else
return pShort;
}
//链表的销毁//
void Destroy(ListNode* head)
{
ListNode* cur = head;
ListNode* del = NULL;
while(cur)
{
del = cur;
cur = cur->_pNext;
delete del;
}
}
//链表的查找//
ListNode* FindNode(ListNode* head,int data)
{
ListNode* cur = head;
while(cur)
{
if(cur->_data == data)
return cur;
cur = cur->_pNext;
}
return NULL;
}
//主函数//
int main()
{
int arr1[] = {3,4,5,6,7,8};
int arr2[] = {8,7};
//创建链表
ListNode* head1 = Create(arr1,sizeof(arr1)/sizeof(arr1[0]));
ListNode* head2 = Create(arr2,sizeof(arr2)/sizeof(arr2[0]));
//创造交点
ListNode* Node1 = FindNode(head1,6);
ListNode* Node2 = FindNode(head2,7);
Node2->_pNext = Node1;
ListNode* ret = GetFirstCommonNode(head1,head2);
if(ret)
cout<<"交点的值是:"<<ret->_data <<endl;
else
cout<<"没有交点"<<endl;
Destroy(head1);
Node2->_pNext = NULL;
Destroy(head2);
system("pause");
return 0;
}
3、一个单链表的环入口
struct Node
{
int _data;
Node* _pNext;
Node(int x=0):_data(x),_pNext(NULL){}
};
Node *getLoopEntrance(Node *head)
{
Node *slow = head, *fast = head;
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next; //走两步
if (slow == fast)
{
break;
}
}
if (fast == NULL || fast->next == NULL)
{
return NULL;
}
fast = head; //从头开始走了
while (slow != fast)
{
slow = slow->next;
fast = fast->next; //走一步
}
return fast;
} 解法如下:设定fast和slow两个指针,初始都指向head。然后让fast每次走2步,slow每次走一步,如果发现fast和slow重合,则确定单向链表有环路了。接下来,让fast回到链表的头部,重新走,每次步长不是走2步了,而是走1步,那么当fast和slow再次相遇的结点,就是环路的入口位置了。
证明:当fast和slow第一次相遇的时候,slow肯定没有遍历完一次链表或刚好遍历完一次链表,而fast已经在环内循环了n圈(n>=1)。这时,假设slow走了i个结点,则fast走了2i个结点,再假设环长为C,则
2i = i + nC => i = nC
设链表长度为L,链表起点距环入口的距离为j,环入口距相遇点的距离为k,则
j + k = i = nC
j + k = (n - 1)C + C = (n - 1)C + (L - j)
j = (n - 1)C + (L - j - k)
(L - j - k)同k一样,同样为环入口点距相遇点的距离。也就是说,从链表起点到环入口点的距离等于(n - 1)环长+相遇点到入口点的距离。于是,从链表起点、相遇点分别设一指针,每次各走一步,则两指针必定相遇,且第一个相遇点即为环入口点。


4、单链表的反转
迭代是从前往后依次处理,直到循环到链尾;而递归恰恰相反,首先一直迭代到链尾也就是递归基判断的准则,然后再逐层返回处理到开头。总结来说,链表翻转操作的顺序对于迭代来说是从链头往链尾,而对于递归是从链尾往链头。
非递归(迭代)方式
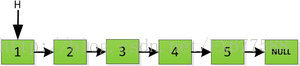
迭代的方式是从链头开始处理,如下图给定一个存放5个数的链表。
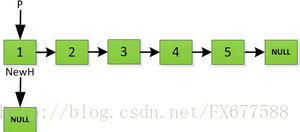
然后依次将旧链表上每一项添加在新链表的后面,然后新链表的头指针NewH移向新的链表头,如下图所示。此处需要注意,不可以上来立即将上图中P->next直接指向NewH,这样存放2的地址就会被丢弃,后续链表保存的数据也随之无法访问。而是应该设置一个临时指针tmp,先暂时指向P->next指向的地址空间,保存原链表后续数据。然后再让P->next指向NewH,最后P=tmp就可以取回原链表的数据了,所有循环访问也可以继续展开下去。
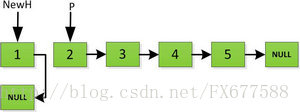
指针继续向后移动,直到P指针指向NULL停止迭代。
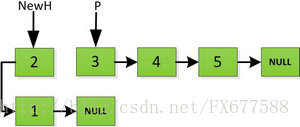
最后一步:
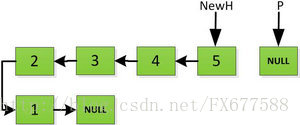
node* reverseList(node* H)
{
if (H == NULL || H->next == NULL) //链表为空或者仅1个数直接返回
return H;
node* p = H, *newH = NULL;
while (p != NULL) //一直迭代到链尾
{
node* tmp = p->next; //暂存p下一个地址,防止变化指针指向后找不到后续的数
p->next = newH; //p->next指向前一个空间
newH = p; //新链表的头移动到p,扩长一步链表
p = tmp; //p指向原始链表p指向的下一个空间
}
return递归方式
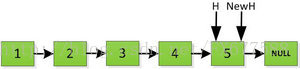
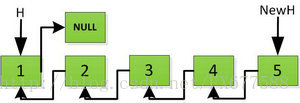
我们再来看看递归实现链表翻转的实现,前面非递归方式是从前面数1开始往后依次处理,而递归方式则恰恰相反,它先循环找到最后面指向的数5,然后从5开始处理依次翻转整个链表。
首先指针H迭代到底如下图所示,并且设置一个新的指针作为翻转后的链表的头。由于整个链表翻转之后的头就是最后一个数,所以整个过程NewH指针一直指向存放5的地址空间。
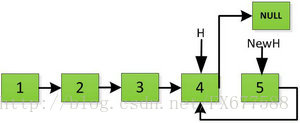
然后H指针逐层返回的时候依次做下图的处理,将H指向的地址赋值给H->next->next指针,并且一定要记得让H->next =NULL,也就是断开现在指针的链接,否则新的链表形成了环,下一层H->next->next赋值的时候会覆盖后续的值。
继续返回操作:
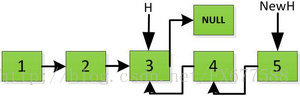
上图第一次如果没有将存放4空间的next指针赋值指向NULL,第二次H->next->next=H,就会将存放5的地址空间覆盖为3,这样链表一切都大乱了。接着逐层返回下去,直到对存放1的地址空间处理。
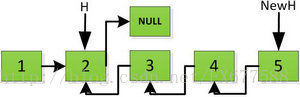
返回到头:
迭代实现的程序
node* In_reverseList(node* H)
{
if (H == NULL || H->next == NULL) //链表为空直接返回,而H->next为空是递归基
return H;
node* newHead = In_reverseList(H->next); //一直循环到链尾
H->next->next = H; //翻转链表的指向
H->next = NULL; //记得赋值NULL,防止链表错乱
return newHead; //新链表头永远指向的是原链表的链尾
完整程序
#include<iostream>
using namespace std;
struct node{
int val;
struct node* next;
node(int x) :val(x){}
};
/***非递归方式***/
node* reverseList(node* H)
{
if (H == NULL || H->next == NULL) //链表为空或者仅1个数直接返回
return H;
node* p = H, *newH = NULL;
while (p != NULL) //一直迭代到链尾
{
node* tmp = p->next; //暂存p下一个地址,防止变化指针指向后找不到后续的数
p->next = newH; //p->next指向前一个空间
newH = p; //新链表的头移动到p,扩长一步链表
p = tmp; //p指向原始链表p指向的下一个空间
}
return newH;
}
/***递归方式***/
node* In_reverseList(node* H)
{
if (H == NULL || H->next == NULL) //链表为空直接返回,而H->next为空是递归基
return H;
node* newHead = In_reverseList(H->next); //一直循环到链尾
H->next->next = H; //翻转链表的指向
H->next = NULL; //记得赋值NULL,防止链表错乱
return newHead; //新链表头永远指向的是原链表的链尾
}
int main()
{
node* first = new node(1);
node* second = new node(2);
node* third = new node(3);
node* forth = new node(4);
node* fifth = new node(5);
first->next = second;
second->next = third;
third->next = forth;
forth->next = fifth;
fifth->next = NULL;
//非递归实现
node* H1 = first;
H1 = reverseList(H1); //翻转
//递归实现
node* H2 = H1; //请在此设置断点查看H1变化,否则H2再翻转,H1已经发生变化
H2 = In_reverseList(H2); //再翻转
return 0;
}