Tensorflow
一开始呢,让我们先了解一下tensorflow的运行方式。简单来说,我们使用步骤一共有三个:创建图,运行图,保存图。

Tensorflow的计算是在图(graph)里面计算的,因此我们必须按照自己的需求来设计一张图。当然图的意思不是代表图片,而是代表一种结构。当创建好图之后,我们导入数据(也叫喂数据)来运行这张图。运行的过程中我们需要调整自己的参数。假如结果符合我们的要求,我们就保存这张图和里面的数据。
即使看的不明所以也没关系,接下来我们会用最简单的一种结构来解决MNIST数据集。在使用的途中你会对tensorflow更加了解。
MNIST
MNIST数据集是一个手写数字训练集(handwritten digit database)。里面有0到9的手写数字图片,并帮你打上了标签。打上标签的意思它有一个文件写明了图片代表的数字。

MNIST是一个很有用的数据集,在接下来的时间里,我们会针对它不断提高我们神经网络的复杂度进而提高我们的网络的准确率。
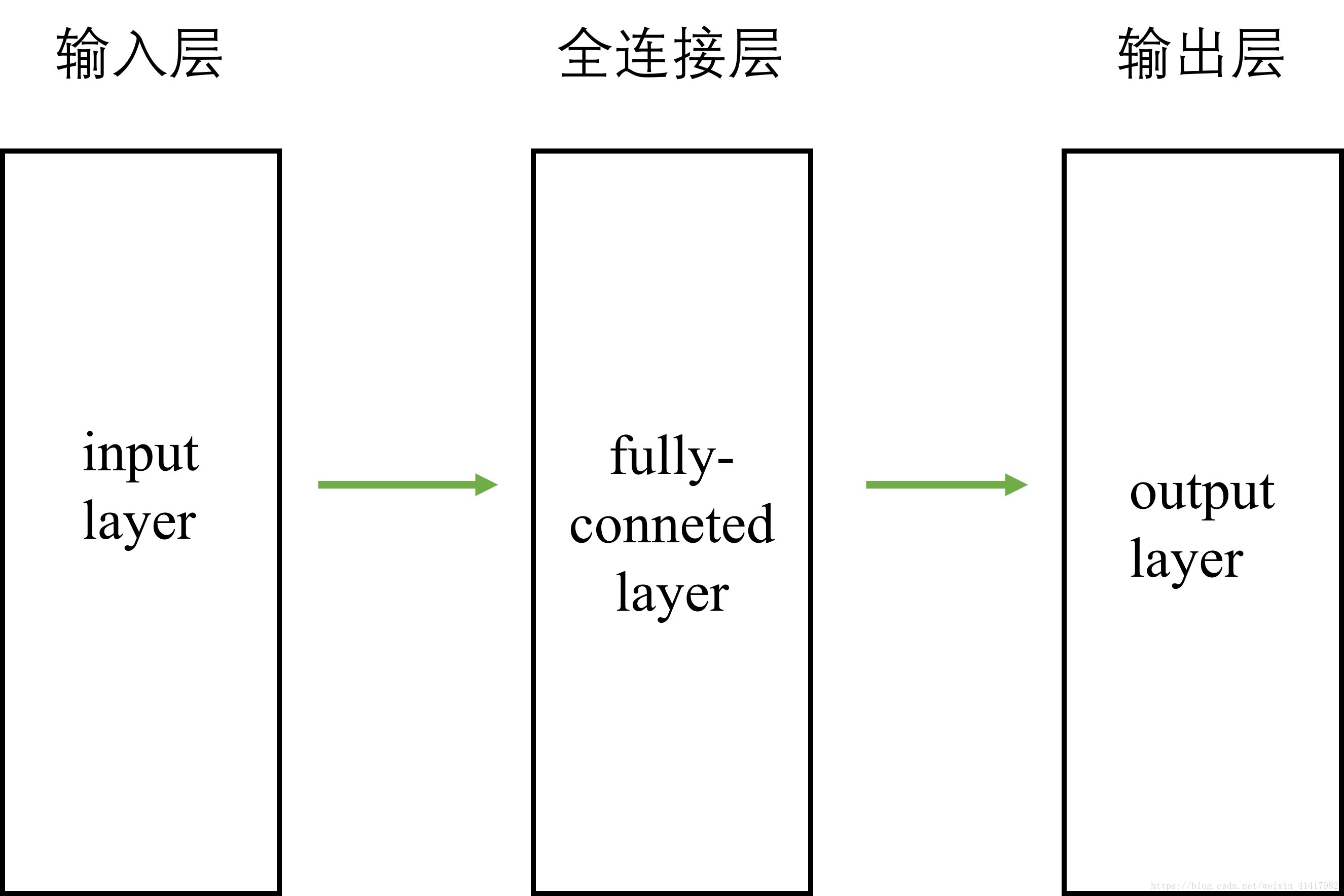
全连接层
全连接层(full-connected layer),顾名思义,是将前面层的节点全部连接然后通过自己之后传入下一层。
前面讲到我们需要创建图,然后喂数据来运行。传入的数据被我们称为输入层。在处理MNIST数据集的时候,我们把每个像素都作为输入的数据,然后分批导入图片。输入层经过网络之后输出的数据作为输出层。本文网络简易结构:
MNIST的每张图片的分辨率都为28*28,那么输入层一共有784个节点(即每个像素都是一个节点)。之所以这样设置,是因为每个像素都包含了图片的信息,它们共同决定了这张图片的数字。
然后我们设置全连接层的形状(shape)为[784,10]。因为我们只有一层全连接层,它接受输入层的784个节点然后输出十个节点(十个分类)。如下图所示,X代表图片的某个像素,经过全连接层层后输出十个值,最大值即是网络的结果。
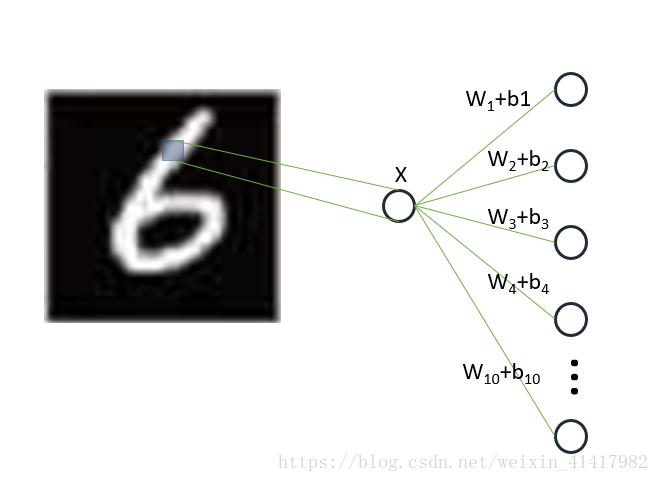
制作图片时候不是很精确,其实 乘以 + 这种形式。
代码解析
导入需要的包
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data相信掌握python的人对于”import … as …”的用法不会陌生。Tensorflow可以通过第三句导入MNIST数据集,命名为input_data。
处理训练集
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
定义批次
batch_size = 100
n_batch = mnist.train.num_examples // batch_size前面说到要将MNIST分批次处理,在这里我们定义了batch_size=100。即每次将传入100张照片进行处理,batch的数量为全部的照片的数量对batch_size取余。在这里的mnist.train.num_examples是tensorflow为我们准备好的语句了。
需要注意的是,one_hot是一种格式。根据MNIST数据集,我们一共有十个分类。假如一张图片分类为‘0’,那么它的标签格式为:
可以看的出来,此时下标为0的值为1,而其他全为0。
Tips:假如IDE提示网络连接失败,那就需要你自己上网找MNIST数据集,一共有四个gz文件。假如下载在当前目录,那么需要新建一个’MNIST_data’文件夹放置这四个文件。
构建tensorflow的图
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
create a simple neutral network
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))这里就在构建一个图了。tf.placehoder是创建一个占位符,用来接受输入的数据。在这里我们创建x,y来分别接受传入的图片和对应的标签。tf.float32是tensorflow里面的float类型,而后面的[None, 784]代表了占位符的形状。前文提到,我们将784个像素作为输入,但我们一次性输入100张图片,所以输入会是一个[100, 784]的矩阵。用None表示数量可以产生变化!
tf.Variable就是创建一个变量。权重的参数都应该设置为变量,因为它在训练的时候需要被更新,在测试的时候又能需要不产生变化。这里有W和b,tf.zeros把他们初始化成形状为[784, 10]和[10]但值全为0的矩阵。
定义需要的变量
prediction = tf.nn.softmax(tf.matmul(x, W)+b)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
loss = tf.reduce_mean(tf.square(y-prediction))
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
init = tf.global_variables_initializer()prediction是预测值。我们网络最后会导出一个[batch_size, 10]的张量出来,利用softmax我们可以得到分类预测。softmax是激活函数的一种,一方面它可以将我们所创建的线性模型转化成非线性,第二方面是它对变化比较敏感。
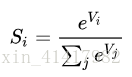
其中,V的第i个值经过softmax的值,等于e的Vi次方除以e的所有V的值次方之和。例子:
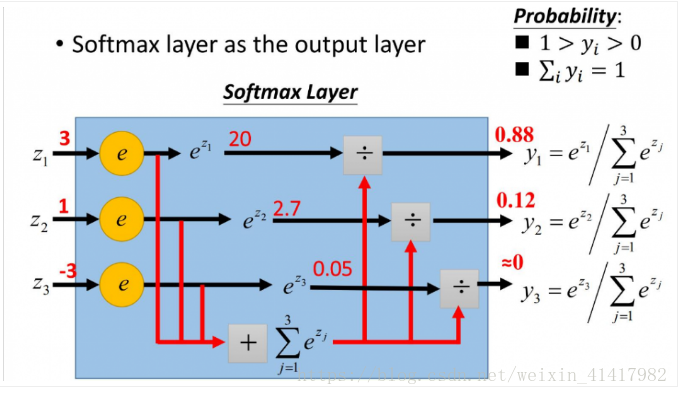
我们可以看出来,经过Softmax之后原本的值的对比会更加明显(从3:1变成0.88:0.12, 三倍变成7.3倍)。即对的更对,错的更错。
tf.argmax可以取张量里面某一维的最大值的下标。那么取出每一张图片标签和预测值里面的分类,再判断是否相等就可以得到准确与否(correct_prediction)。
tf.reduce_mean把准确率平均就能求出平均准确率。tf.cast使得准确率转化成浮点数,因此求平均的时候不会省略小数部分。
loss是损失值。由于神经网络得到的分类并不一定正确,所以不正确的估计我们会传递回去作为一个损失激励权重更新。而如何确定loss的大小就是用损失函数来决定。这里的损失函数是将y减去网络的预测值然后平方取平均。
举个例子,加入我们输入一张’6‘的图片(数据是虚构的):

train_step节点代表利用梯度下降法来降低loss值。换句话说,它告诉我们需要求loss对权重的梯度来更新权重。这方面涉及到权重的更新方法,会在后面详细介绍。
init代表初始化所有变量的操作。这又要重新提一下,我们到这里也只是画好了一个图。我们在图里面放了很多节点,但到这里它都没产生任何值!
图的结构
运行构建好的图
with tf.Session() as sess:
sess.run(init)
for epoch in range(21):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={x: batch_xs, y: batch_ys})
acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
print('Iter' + str(epoch) + ",Testing Accuracy" + str(acc))with tf.Session() as sess代表之后我们开始运行。首先我们都会开始sess.run(init)来运行init这个操作,即现在才开始初始化变量的操作。epoch代表迭代的次数。迭代代表跑完一整个数据集。
mnist.train.next_batch是内置的函数,表示下一批(batch_size)的数据。sess.run(train_step)好像只是运行train_step这个节点,但实际上为了运行它,我们将跟它相关联的节点都跑完了,也就是跑完了一整张图。
feed_dict是代表你喂的数据的字典。将batch_xs, batch_ys都放置在对应的占位符x, y上,此时每次运行x, y都是我们得到的新的批次的数据。接着是运行准确率的节点,调用的是测试集的图片。
我们会得到这样的数据:
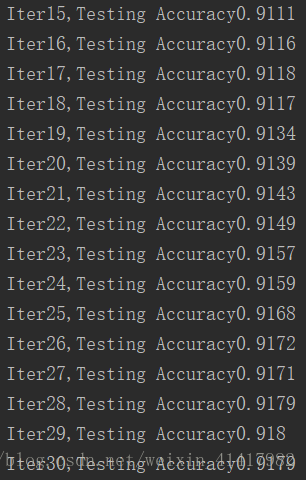
你会发现准确率到一定的值就上升不了了,这是因为我们的网络过于简陋。在接下来的课程我们会加入卷积层,池化层,正则化等部分来改善识别的能力。
但是下一篇文章我们会继续深入这个网络来讲权重更新的细节。