课程来源:吴恩达 深度学习课程 《卷积神经网络》
笔记整理:王小草
时间:2018年6月6日
outline:
本文第1节主要会讲解5个经典的神经网络:
- LeNet-5(1998年)
- AlexNet(2012年ILSVRC第一名)
- z-net(2013年ILSVRC第一名)
- VGG(2014年ILSVRC第二名,但被广泛应用于其他图像任务)
- GoogleNet(2014年ILSVRC第一名)
然后第2节讲解ResNet:
2015年imageNet图像分类分任务第一名。即残差网络,它的特点是非常深,是一个深达152层的神经网络,并且在如何有效训练方面,总结出来一些有趣的想法和窍门。
第3节会讲解一个Inception神经网络的实例分析
了解了以上神经网络网络之后,你就会对如何构建有效的卷积神经网络更有感觉。
1.经典网络
1.1 CNN的演化
下图是截取刘昕博士总结的CNN演化历史图。起点是神经认知机模型,此时已经出现了卷积结构,经典的LeNet诞生于1998年。然而之后CNN的锋芒开始被SVM等手工设计的特征盖过。随着ReLU和dropout的提出,以及GPU和大数据带来的历史机遇,CNN在2012年迎来了历史突破–AlexNet.

1.2 Lenet-5
下图是lenet的结构,与目前不断改进中的CNN一样,也同样具有卷积层,池化层,全链接层。

原论文:Lecun et al.,1998.Gradienct-based learning applied to document recognition
对该论文,建议精读第2段(重点介绍了本节要讲的网络),泛读第3段(一些有趣的实验结果)
输入层
输入层是一张黑白图片,大小是32*32(1个颜色通道)。
卷积层1–C1
输入层的下一层便是第1个卷积层了。这个卷积层有6个卷积核(每个神经元对应一个卷积核),核大小是5*5.即输出的是6个28*28的feature map,每个feature map都提取了一个局部特征。

这一层需要训练的参数个数是(5*5+1)*6 = 156 。加1是因为每一个卷积核线性计算中还有一个bais偏执项参数。
如此一来,C1中的链接数共有156*(28*28) = 122304个。
池化层1–S2
池化层也叫向下采样层,是为了降低网络训练参数及模型的过拟合程度。
C1的输出就是S2的输入,S2的输入大小为6 * 28 * 28.
窗口大小为2*2,步长为2,所以采样之后的S2输出是6 * 14 * 14
卷积层2–C3
C3有16个卷积核(16个神经元),同样也是通过5 * 5的卷积核,得到16个10 * 10 的feature map。
在C1中是有6个卷积核的,现在有16个,每个卷积核都是提取了一个局部的特征。所以16个卷积核其实代表着C1中6中特征的组合。
池化层2–S4
同样,通过对C3的向下采样,输出之后的大小为16 * 5 * 5.
卷积层3–C5
C5有120个卷积核,每个单元与S4的全部16个单元的5*5邻域相连,由于S4层特征图的大小也为5*5(同滤波器一样),故C5特征图的大小为1*1:这构成了S4和C5之间的全连接。之所以仍将C5标示为卷积层而非全相联层,是因为如果LeNet-5的输入变大,而其他的保持不变,那么此时特征图的维数就会比1*1大。C5层有48120个可训练连接。
全链接层1–F6
F6层有84个单元(之所以选这个数字的原因来自于输出层的设计),与C5层全相连。有10164个可训练参数。如同经典神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置。然后将其传递给sigmoid函数产生单元i的一个状态。
输出层–output
输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,每类一个单元,每个有84个输入。
换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。
现在其实很少用欧式径向基函数作为输出层了,一般都是用softmax层做多分类,比较直观的图:
相比现代版本,这个神经网络有点小,只有约6万个参数,而现在,我们经常看到一千万到一亿个参数的神经网络。
2.3 Alexnet
AlexNet 可以说是具有历史意义的一个网络结构,可以说在AlexNet之前,深度学习已经沉寂了很久。历史的转折在2012年到来,AlexNet 在当年的ImageNet图像分类竞赛中,top-5错误率比上一年的冠军下降了十个百分点,而且远远超过当年的第二名。
AlexNet 之所以能够成功,深度学习之所以能够重回历史舞台,原因在于:
(1)非线性激活函数:ReLU
(2)防止过拟合的方法:Dropout,Data augmentation
(3)大数据训练:百万级ImageNet图像数据
(4)其他:GPU实现,LRN归一化层的使用
(5)Alexnet比LeNet-5要深,其参数数量有600万个
(6)使用了local response normalization(后来学者发现这个并不重要,因此此处不详细讲述)
原论文:[Krizhevsky et al.,2012.ImageNet classification with deep convolutional neaural networks]
2.3.1 结构
Alexnet的结构如下:

还有一张图可能更直观:
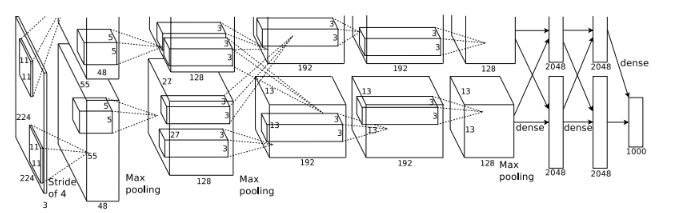
alexnet总共包括8层,其中前5层convolutional(包含pool),后面3层是full-connected,文章里面说的是减少任何一个卷积结果会变得很差,下面我来具体讲讲每一层的构成:
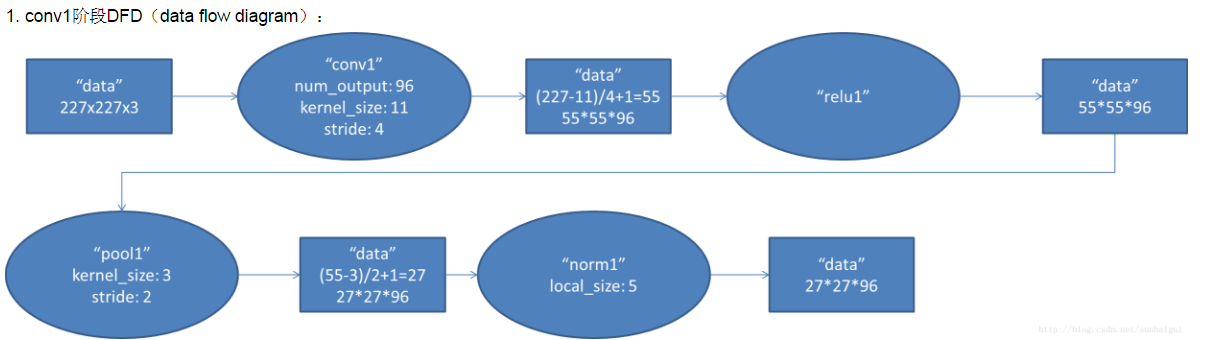
conv1:
第一层卷积层 输入图像为227*227*3(paper上貌似有点问题224*224*3)的图像,使用了96个kernels(96,11,11,3),以4个pixel为一个单位来右移或者下移(步长为4),能够产生96个55*55个卷积后的矩形框值。
pool2:
然后进行response-normalized(其实是Local Response Normalized,后面我会讲下这里)和pooled之后,pool这一层好像caffe里面的alexnet和paper里面不太一样,alexnet里面采样了两个GPU,所以从图上面看第一层卷积层厚度有两部分,池化pool_size=(3,3),滑动步长为2个pixels,得到96个27*27个feature。
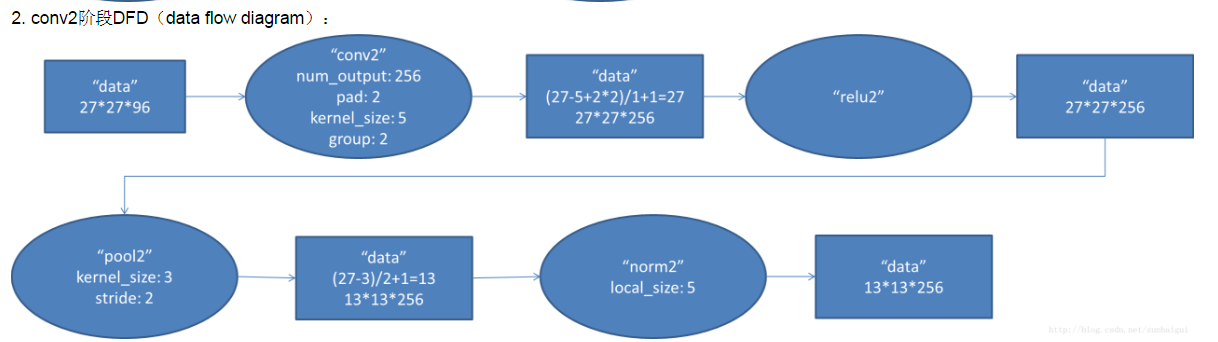
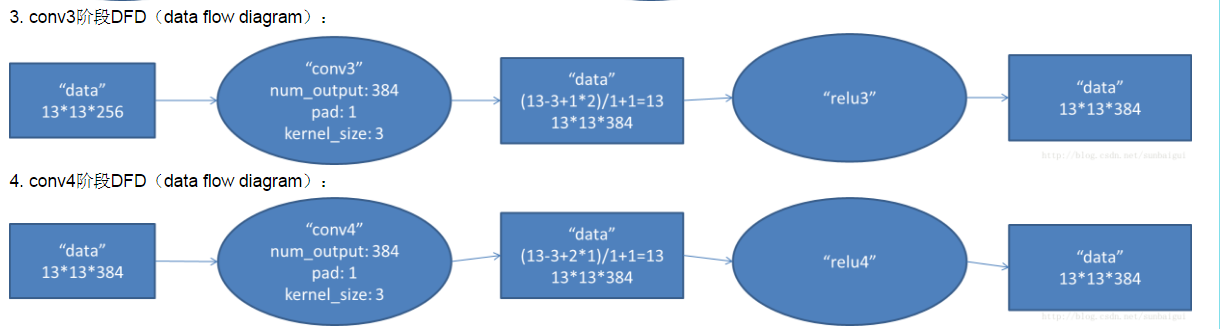
conv3:
第二个卷积层使用256个(同样,分布在两个GPU上,每个128kernels(5*5*48)),做pad_size(2,2)的处理,以1个pixel为单位移动,能够产生256*27*27个卷积后的矩阵框,
pool4:
做LRN处理,然后pooled,池化以3*3矩形框,2个pixel为步长,得到256个13*13个features。
conv5:
使用384个kernels(3*3*384,pad_size=(1,1),得到384*15*15,kernel_size为(3,3),以1个pixel为步长,得到384*13*13)
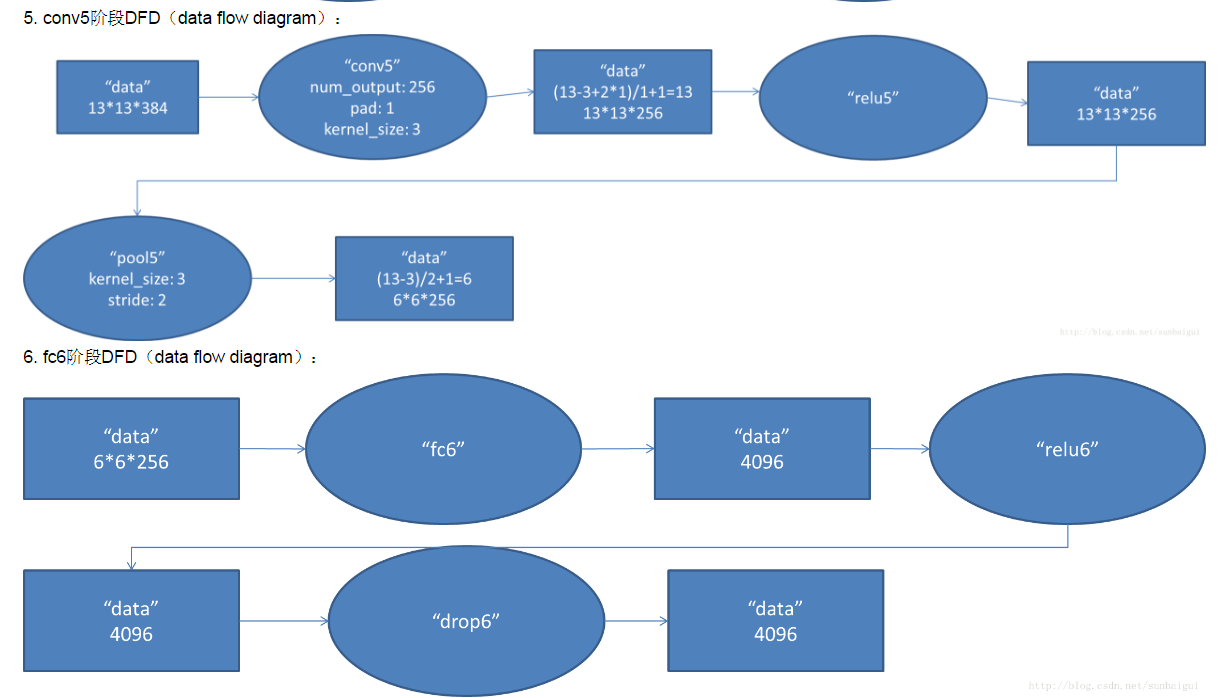
conv6:
使用384个kernels(pad_size(1,1)得到384*15*15,核大小为(3,3)步长为1个pixel,得到384*13*13)
conv7:
使用256个kernels(pad_size(1,1)得到384*15*15,核大小为(3,3)步长为1个pixel,得到256*13*13)
pool7:
经过一个池化层,pool_size=(3,3),步长为2,得到6*6*256
full8:
将6*6*256平铺成9216*1的向量,进入全连接层,该层的神经元个数为4096,即有w权重参数维度4096*9216个。
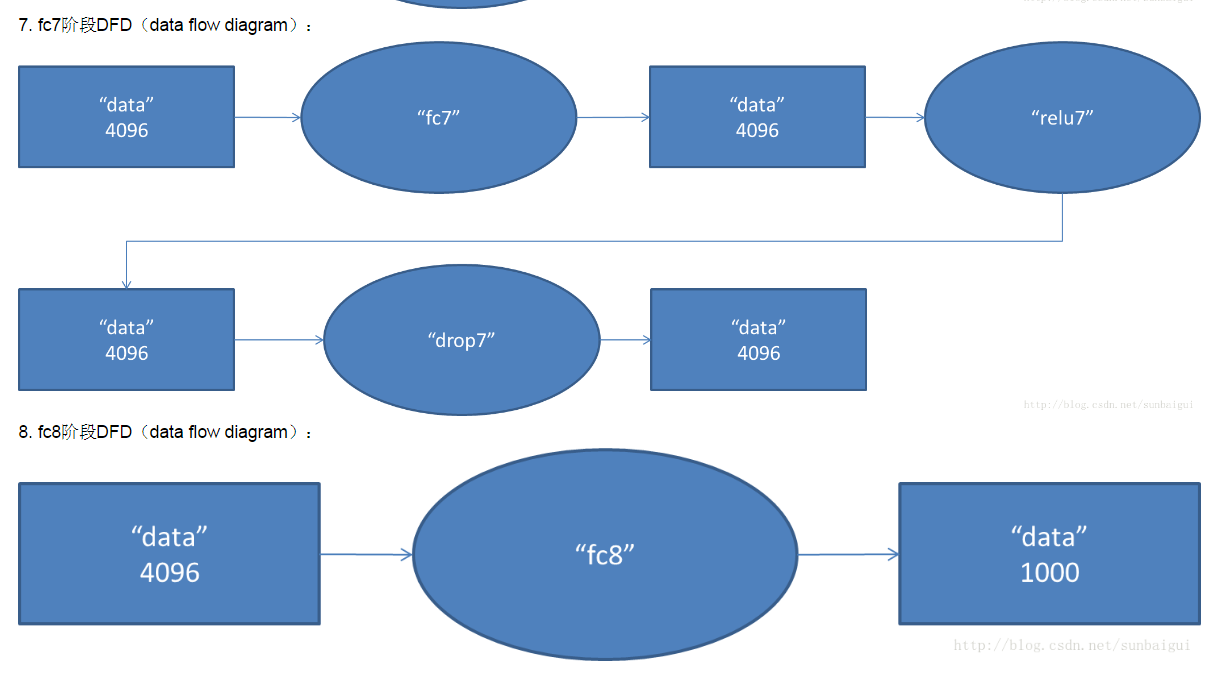
full9:
该层神经元个数仍然是4096个
softmax10:
以上输出,进入softmax层,因为由1000个分类,因此为1000个神经元,每个神经元输出对应类别的概率。注意caffe图中全连接层中有relu、dropout、innerProduct。
Alexnet总共有5个卷积层,具体的数据流如下:

如下有更清晰的数据结构(截图自http://blog.csdn.net/sunbaigui/article/details/39938097)
2.3.2 优点
Data augmentation
有一种观点认为神经网络是靠数据喂出来的,若增加训练数据,则能够提升算法的准确率,因为这样可以避免过拟合,而避免了过拟合你就可以增大你的网络结构了。当训练数据有限的时候,可以通过一些变换来从已有的训练数据集中生成一些新的数据,来扩大训练数据的size。
其中,最简单、通用的图像数据变形的方式:
从原始图像(256,256)中,随机的crop出一些图像(224,224)。【平移变换,crop】
水平翻转图像。【反射变换,flip】
给图像增加一些随机的光照。【光照、彩色变换,color jittering】
AlexNet 训练的时候,在data augmentation上处理的很好:
随机crop。训练时候,对于256*256的图片进行随机crop到224*224,然后允许水平翻转,那么相当与将样本倍增到((256-224)^2)*2=2048。
测试时候,对左上、右上、左下、右下、中间做了5次crop,然后翻转,共10个crop,之后对结果求平均。作者说,不做随机crop,大网络基本都过拟合(under substantial overfitting)。
对RGB空间做PCA,然后对主成分做一个(0, 0.1)的高斯扰动。结果让错误率又下降了1%。
ReLU 激活函数
Sigmoid 是常用的非线性的激活函数,它能够把输入的连续实值“压缩”到0和1之间。特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1.
但是它有一些致命的 缺点:
Sigmoids saturate and kill gradients. sigmoid 有一个非常致命的缺点,当输入非常大或者非常小的时候,会有饱和现象,这些神经元的梯度是接近于0的。如果你的初始值很大的话,梯度在反向传播的时候因为需要乘上一个sigmoid 的导数,所以会使得梯度越来越小,这会导致网络变的很难学习。
Sigmoid 的 output 不是0均值. 这是不可取的,因为这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。
产生的一个结果就是:如果数据进入神经元的时候是正的(e.g. x>0 elementwise in f=wTx+b),那么 w 计算出的梯度也会始终都是正的。
当然了,如果你是按batch去训练,那么那个batch可能得到不同的信号,所以这个问题还是可以缓解一下的。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的 kill gradients 问题相比还是要好很多的。
Alex用ReLU代替了Sigmoid,发现使用 ReLU 得到的SGD的收敛速度会比 sigmoid/tanh 快很多。
主要是因为它是linear,而且 non-saturating(因为ReLU的导数始终是1),相比于 sigmoid/tanh,ReLU 只需要一个阈值就可以得到激活值,而不用去算一大堆复杂的运算。
Dropout
结合预先训练好的许多不同模型,来进行预测是一种非常成功的减少测试误差的方式(Ensemble)。但因为每个模型的训练都需要花了好几天时间,因此这种做法对于大型神经网络来说太过昂贵。
然而,AlexNet 提出了一个非常有效的模型组合版本,它在训练中只需要花费两倍于单模型的时间。这种技术叫做Dropout,它做的就是以0.5的概率,将每个隐层神经元的输出设置为零。以这种方式“dropped out”的神经元既不参与前向传播,也不参与反向传播。
所以每次输入一个样本,就相当于该神经网络就尝试了一个新的结构,但是所有这些结构之间共享权重。因为神经元不能依赖于其他特定神经元而存在,所以这种技术降低了神经元复杂的互适应关系。
正因如此,网络需要被迫学习更为鲁棒的特征,这些特征在结合其他神经元的一些不同随机子集时有用。在测试时,我们将所有神经元的输出都仅仅只乘以0.5,对于获取指数级dropout网络产生的预测分布的几何平均值,这是一个合理的近似方法。
多GPU训练
单个GTX 580 GPU只有3GB内存,这限制了在其上训练的网络的最大规模。因此他们将网络分布在两个GPU上。
目前的GPU特别适合跨GPU并行化,因为它们能够直接从另一个GPU的内存中读出和写入,不需要通过主机内存。
他们采用的并行方案是:在每个GPU中放置一半核(或神经元),还有一个额外的技巧:GPU间的通讯只在某些层进行。
例如,第3层的核需要从第2层中所有核映射输入。然而,第4层的核只需要从第3层中位于同一GPU的那些核映射输入。
Local Responce Normalization
一句话概括:本质上,这个层也是为了防止激活函数的饱和的。
2.3.3 AlexNet On Tensorflow
代码位置:
http://www.cs.toronto.edu/~guerzhoy/tf_alexnet/
tflearn里面有一个alexnet来分类Oxford的例子,好开心,在基于tflearn对一些日常layer的封装,代码量只有不到50行,看了下内部layer的实现,挺不错的,写代码的时候可以多参考参考,代码地址https://github.com/tflearn/tflearn/blob/master/examples/images/alexnet.py.
from __future__ import division, print_function, absolute_import
import tflearn
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.normalization import local_response_normalization
from tflearn.layers.estimator import regression
import tflearn.datasets.oxflower17 as oxflower17
X, Y = oxflower17.load_data(one_hot=True, resize_pics=(227, 227))
# Building 'AlexNet'
network = input_data(shape=[None, 227, 227, 3])
network = conv_2d(network, 96, 11, strides=4, activation='relu')
network = max_pool_2d(network, 3, strides=2)
network = local_response_normalization(network)
network = conv_2d(network, 256, 5, activation='relu')
network = max_pool_2d(network, 3, strides=2)
network = local_response_normalization(network)
network = conv_2d(network, 384, 3, activation='relu')
network = conv_2d(network, 384, 3, activation='relu')
network = conv_2d(network, 256, 3, activation='relu')
network = max_pool_2d(network, 3, strides=2)
network = local_response_normalization(network)
network = fully_connected(network, 4096, activation='tanh')
network = dropout(network, 0.5)
network = fully_connected(network, 4096, activation='tanh')
network = dropout(network, 0.5)
network = fully_connected(network, 17, activation='softmax')
network = regression(network, optimizer='momentum',
loss='categorical_crossentropy',
learning_rate=0.001)
# Training
model = tflearn.DNN(network, checkpoint_path='model_alexnet',
max_checkpoints=1, tensorboard_verbose=2)
model.fit(X, Y, n_epoch=1000, validation_set=0.1, shuffle=True,
show_metric=True, batch_size=64, snapshot_step=200,
snapshot_epoch=False, run_id='alexnet_oxflowers17')2.4 ZFNet
首先来简单地介绍一下ZFNet这个CNN模型。它是2013年ILSVRC比赛的冠军。它是在Alexnet的基础上做一点点的改进和变换。结构如下:
ZFNet与Alexnet有两点差别
1.在卷积层1中,VGG的卷积核是11*11大小,并且步长为4;在ZFNet中,卷积核大小改为了7 * 7, 步长改为了2.
2.在卷积层3,4,5中,神经元的个数分别由VGG的384,384,256变成了512,1024,512.
其余结构与AlexNet完全一致。
ZFNet将top5的错误率从15.4%下降到了14.8%,提升并没有特别惊人。
2.5 VGG
原论文:[Simonyan&Zisserman 2015. Very deep conblutional networks for large-scale iamge recognition]
2.5.1 结构
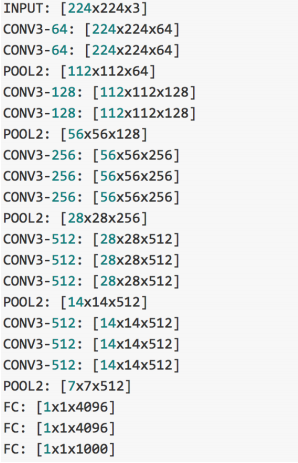
VGGnet是Oxford的Visual Geometry Group的team,在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能,如下图,文章通过逐步增加网络深度来提高性能,虽然看起来有一点小暴力,没有特别多取巧的,但是确实有效,很多pretrained的方法就是使用VGG的model(主要是16和19),VGG相对其他的方法,参数空间很大,最终的model有500多m,alnext只有200m,googlenet更少,所以train一个vgg模型通常要花费更长的时间,所幸有公开的pretrained model让我们很方便的使用。paper中的几种模型如下:
论文的作者试验了多种深度与结构的CNN, 在16层的时候达到了最好。所以我们现在一般都使用VGG-16,VGG-19.
以下是VGG每一层的数据维度
以下是计算VGG每一层需要的显存,是可以通过参数的数量进行估算的。要运行一个VGG,一张图片需要给它93M,而且这只是前向计算的,如果还药后向计算,那么要93*2.
2.5.2 VGG on tensorflow
import tflearn
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.estimator import regression
# Data loading and preprocessing
import tflearn.datasets.oxflower17 as oxflower17
X, Y = oxflower17.load_data(one_hot=True)
# Building 'VGG Network'
network = input_data(shape=[None, 224, 224, 3])
network = conv_2d(network, 64, 3, activation='relu')
network = conv_2d(network, 64, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = conv_2d(network, 128, 3, activation='relu')
network = conv_2d(network, 128, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = conv_2d(network, 256, 3, activation='relu')
network = conv_2d(network, 256, 3, activation='relu')
network = conv_2d(network, 256, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = conv_2d(network, 512, 3, activation='relu')
network = max_pool_2d(network, 2, strides=2)
network = fully_connected(network, 4096, activation='relu')
network = dropout(network, 0.5)
network = fully_connected(network, 4096, activation='relu')
network = dropout(network, 0.5)
network = fully_connected(network, 17, activation='softmax')
network = regression(network, optimizer='rmsprop',
loss='categorical_crossentropy',
learning_rate=0.001)
# Training
model = tflearn.DNN(network, checkpoint_path='model_vgg',
max_checkpoints=1, tensorboard_verbose=0)
model.fit(X, Y, n_epoch=500, shuffle=True,
show_metric=True, batch_size=32, snapshot_step=500,
snapshot_epoch=False, run_id='vgg_oxflowers17')2.残差网络
2.1 残差网络介绍
原论文链接:https://arxiv.org/abs/1512.03385
当神经网络深度很深的时候,残差做后向计算求导时会变得非常非常小,所以训练起来非常困难。但是往往神经网络越深它的效果也越好。
所以,得想一个办法得让神经网络又深又好训练。于是微软亚洲研究院提出ResNet,在2015年的ILSVRC比赛中获得了冠军,比VGG还要深8倍。(152层)
深层的CNN训练困难在于梯度衰减,即使使用bantch normalization,几十层的CNN也非常难训练。
离输入层越远,残差传回来的信号也就非常弱了,从而导致了失真。
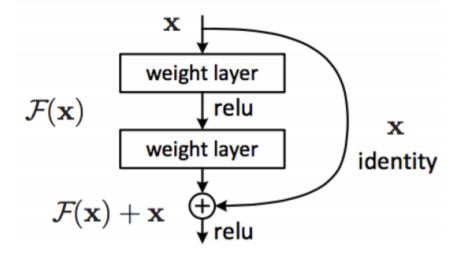
于是ResNet设计了这样一个结构:residual block
F(x)是一个残差的隐射,将它加上从根部传过来的原始的信息x再去经过激励函数relu往下走。
从而,原来的每层计算如下:
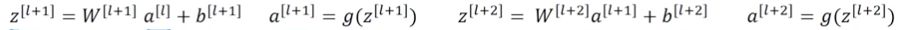
现在a[l+2]中增添了a[l]的信息:
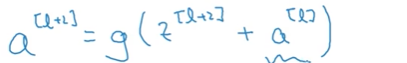
这个传残差的的过程叫做“shot cut”,有时也叫做“skip connection”
整个ResNet的结构可以如下图:
使用resNet的效果对比:
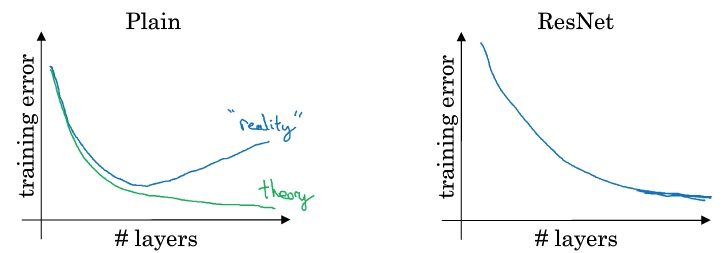
普通神经网络,随着深度的增加,训练的误差会增大,而使用残差网络,则无论深度如何增加,训练的误差都是逐渐下降的。
2.2 Deep Residual Network tflearn实现
from __future__ import division, print_function, absolute_import
import tflearn
# Residual blocks
# 32 layers: n=5, 56 layers: n=9, 110 layers: n=18
n = 5
# Data loading
from tflearn.datasets import cifar10
(X, Y), (testX, testY) = cifar10.load_data()
Y = tflearn.data_utils.to_categorical(Y, 10)
testY = tflearn.data_utils.to_categorical(testY, 10)
# Real-time data preprocessing
img_prep = tflearn.ImagePreprocessing()
img_prep.add_featurewise_zero_center(per_channel=True)
# Real-time data augmentation
img_aug = tflearn.ImageAugmentation()
img_aug.add_random_flip_leftright()
img_aug.add_random_crop([32, 32], padding=4)
# Building Residual Network
net = tflearn.input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug)
net = tflearn.conv_2d(net, 16, 3, regularizer='L2', weight_decay=0.0001)
net = tflearn.residual_block(net, n, 16)
net = tflearn.residual_block(net, 1, 32, downsample=True)
net = tflearn.residual_block(net, n-1, 32)
net = tflearn.residual_block(net, 1, 64, downsample=True)
net = tflearn.residual_block(net, n-1, 64)
net = tflearn.batch_normalization(net)
net = tflearn.activation(net, 'relu')
net = tflearn.global_avg_pool(net)
# Regression
net = tflearn.fully_connected(net, 10, activation='softmax')
mom = tflearn.Momentum(0.1, lr_decay=0.1, decay_step=32000, staircase=True)
net = tflearn.regression(net, optimizer=mom,
loss='categorical_crossentropy')
# Training
model = tflearn.DNN(net, checkpoint_path='model_resnet_cifar10',
max_checkpoints=10, tensorboard_verbose=0,
clip_gradients=0.)
model.fit(X, Y, n_epoch=200, validation_set=(testX, testY),
snapshot_epoch=False, snapshot_step=500,
show_metric=True, batch_size=128, shuffle=True,
run_id='resnet_cifar10')3.3 1*1卷积
1*1的卷积有什么用,听上去好搞笑哦。实际上它很有用。
如下网络,输入时6*6*32的图片,经过1*1*32的卷积核,再经过relu会得到6*6*Filter_num的矩阵
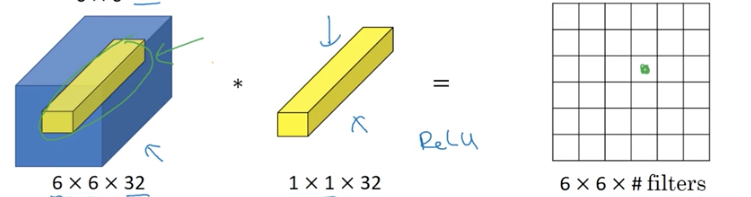
这个过程称为1*1卷积,或者网络中的网络
什么时候使用1*1卷积呢?当channel数目非常多的时候。
我们知道pool layer可以压缩hight和width的大小,但是channel的大小却无法压缩。而使用1*1卷积就可以解决这个问题。若设置n个1*1的卷积核,则最后的输出矩阵的channel数目就是n
来个例子:
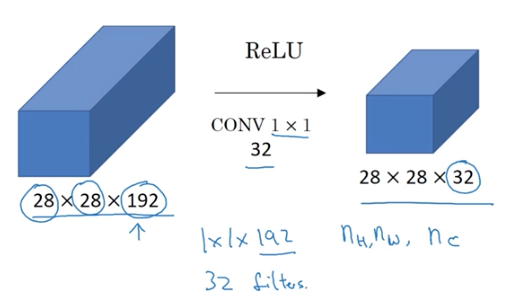
输入的维度是28*28*192,192的channel树忒大了,想要缩小,就是用32个1*1*192的卷积核进行卷积,最终输出维度是28*28*32.同理,你也可以用这种方式来增加channel数目。
(后面你会发现1*1卷积对侯建Inception网络很有帮助)
4. 谷歌Inception网络
在构建神经网络的时候,我们需要去设计需要多少卷积核呀,卷积核大小是多少呀,需要多少卷积层与池化层呀等等。而Inception网络实在是帮助你去决定这些东东,虽然因此网络结构复杂了很多,但是网络表现却非常好。
4.1 Inception结构
假设有一个28*28*192的输入

不知道要用多少大小的卷积核去卷积,因此先用64个1*1卷积核,得到28*28*64的输出
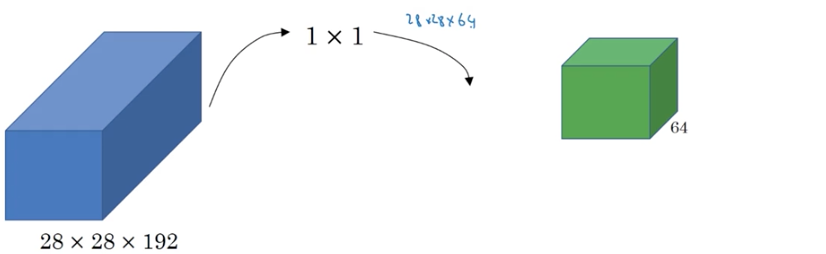
接着在用128个3*3的卷积核,得到28*28*128的输出,将这个输出叠加在已有的输出上
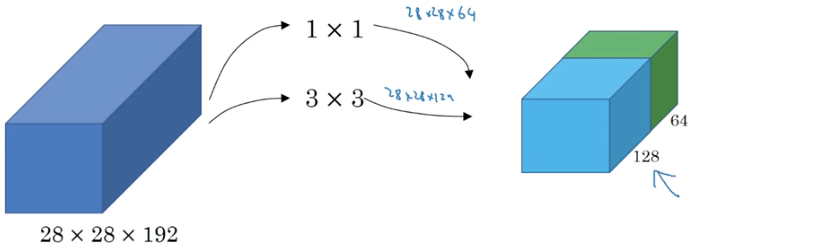
再接着用32个5*5的卷积核,得到28*28*32的输出,再叠加到已有输出上

再来一个池化层,32个1*1,步长为1,则得到输出为28*28*32,将这个输出也堆叠在已有的输出上
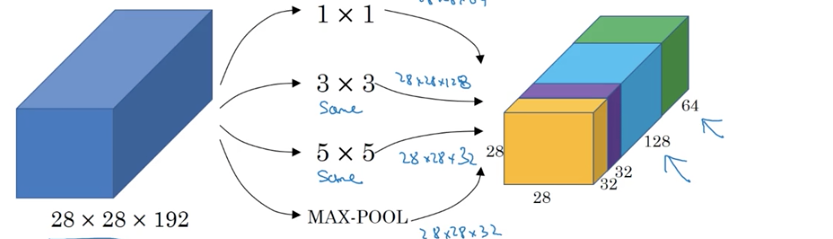
综上所有输出叠加得到维度为28*28*256,而以上过程就是Inception的核心了,来自论文[Szegedy et al.2014.Going Deeper with Convolutions]
基于以上,我们有3类卷积,1类池化,无需人为去选择到底要哪个卷积,或要不要池化和卷积,在训练的过程中,模型自动会去学习参数,并决定选用哪个类型。但这样,也加大了计算量
4.2 Inception的问题-计算量大
以5*5的卷积核为例来看看它的计算量。
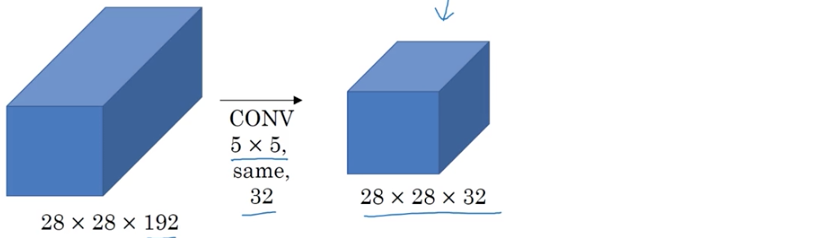
输入是28*28*192,卷积核大小是5*5,有32个,因此总的计算量是28*28*32*5*5*192 = 1.2亿。吓人。
解决办法,是上一节提到的1*1卷积,假设用16个1*1的卷积核进行卷积,则原来28*28*192的维度就会缩减到28*28*16,再在上面做5*5的卷积,则计算量大大缩减.
第一步计算量为28*28*16*192=2.4m
第二部计算量为28*28*32*5*5*16=10.0m
与上文的120m下降了很多。
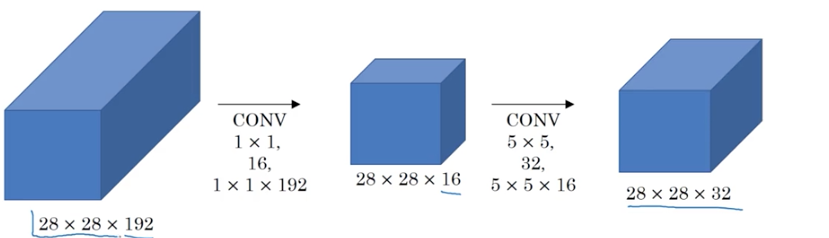
中间的这个28*28*16的输出层,有时我们称之为瓶颈层(bottleneck layer)
4.3 构建完整的Inception网络
回顾一下Inception模块
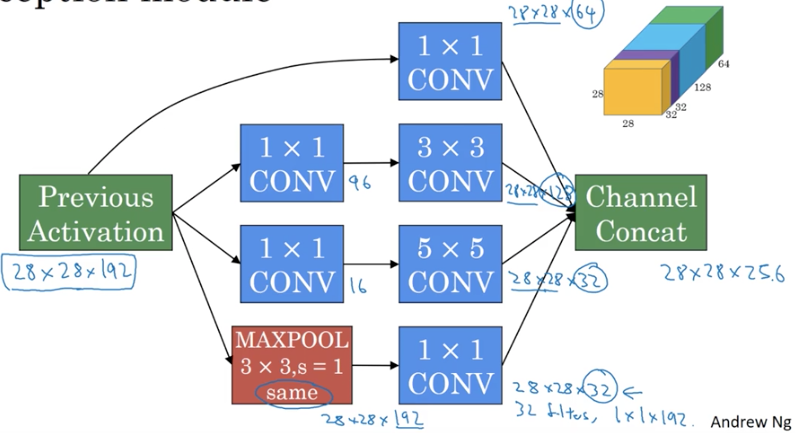
输入时前一层的激活函数的输出,大小有28*28*192
中间过程做4个类型的堆叠:
(1)直接进行1*1卷积,输出28*28*64
(2)进行3*3卷积,但是为了减小计算量,前面先放了一个1*1卷积,使channel层数目由192下降到了96,最终输出28*28*128
(3)进行5*5卷积,同样为了减小计算量,前面先放了一个1*1卷积,使channel层数目由192下降到了16,最终输出28*28*32
(4)池化,输出28*28*192,然后用1*1卷积将192下降到了32
最终左右结果堆叠在一起输出28*28*256
完整的Inception网络结构图:
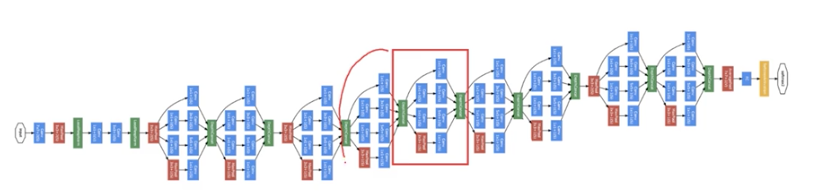
看上去复杂得密集恐惧症,其实其是由一个一个上文那样的Inception模块组合起来的,中间穿插一些max pool layer来减小hight和wighth.
论文中的完整网络其实还有一小块细节,就是在中间的隐藏层,也会额外接上全连接层与softmax层做分类,从而避免过拟合。
为什么要取名为Inception呢?看过电影《Inception(盗梦空间)》的不解释。
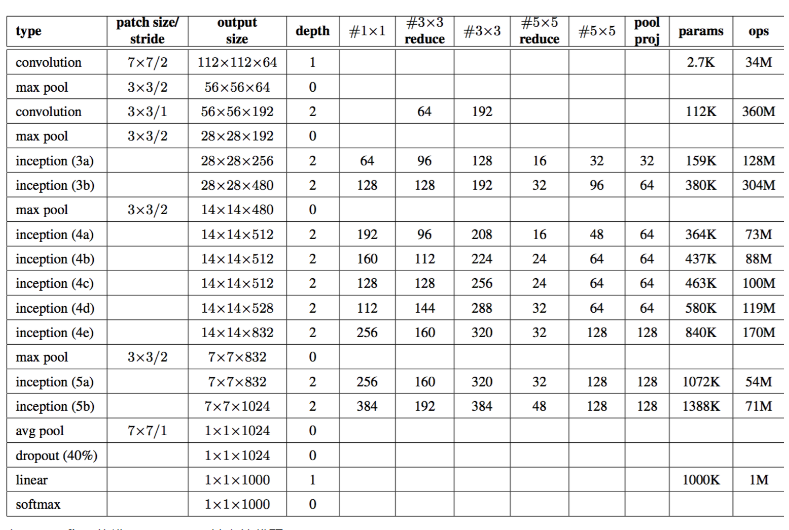
4.4 GoogLeNet
参考博客“http://hacker.duanshishi.com/?p=1678
GoogLeNet是ILSVRC 2014的冠军,主要是致敬经典的LeNet-5算法,主要是Google的team成员完成,paper见Going Deeper with Convolutions.相关工作主要包括LeNet-5、Gabor filters、Network-in-Network.Network-in-Network改进了传统的CNN网络,采用少量的参数就轻松地击败了AlexNet网络,使用Network-in-Network的模型最后大小约为29MNetwork-in-Network caffe model.GoogLeNet借鉴了Network-in-Network的思想
总体结构:
1.包括Inception模块的所有卷积,都用了修正线性单元(ReLU);
2.网络的感受野大小是224x224,采用RGB彩色通道,且减去均值;
3.#3x3 reduce和#5x5 reduce分别表示3x3和5x5的卷积前缩减层中1x1滤波器的个数;pool proj表示嵌入的max-pooling之后的投影层中1x1滤波器的个数;缩减层和投影层都要用ReLU;
4.网络包含22个带参数的层(如果考虑pooling层就是27层),独立成块的层总共有约有100个;
5.网络中间的层次生成的特征会非常有区分性,给这些层增加一些辅助分类器。这些分类器以小卷积网络的形式放在Inception(4a)和Inception(4b)的输出上。在训练过程中,损失会根据折扣后的权重(折扣权重为0.3)叠加到总损失中。
辅助分类器的具体细节:
1.均值pooling层滤波器大小为5x5,步长为3,(4a)的输出为4x4x512,(4d)的输出为4x4x528;
2.1x1的卷积有用于降维的128个滤波器和修正线性激活;
3.全连接层有1024个单元和修正线性激活;
4.dropout层的dropped的输出比率为70%;
5.线性层将softmax损失作为分类器(和主分类器一样预测1000个类,但在inference时移除)。
5.使用开源的实现方案
上文我们学习了优秀的经典网络,现在来讲一讲如何使用它们。
看了论文,理解作者的思路之后,此时就应该去将论文中的方法复现一遍,而自己去实现一遍费时费力也不一定能达到作者的效果,因为构建神经网络中药涉及的细节忒多,作者在论文中也不可能全部罗列,因此我们需要去寻找作者开源出来的代码(如果有的话)。
找开源代码,直接在Github上搜索对应的相关词,找到适合的代码,就将工程下载到本地即可。(关于如何使用github下载源码请百度哦)
6.迁移学习(transfer learning)
从头构建一个神经网络,初始化参数进行训练,往往费时费力不讨好,而若直接使用别人已经训练好的优秀模型来做预训练,则可能事半攻倍。
如何进行迁移学习?
(1)在数据集A上训练一个神经网络(比如训练了猫狗分类的)
(2)将以上训练好的神经网络用在B数据集上训练(比如X光照片分类)
- 若B数据集size小,则可只重新训练最后一层的参数
- 若B数据集size大,则可重新训练后面几层的参数(数据集越大,重新训练的层数可以越多)
- 若B数据集size非常大,则可重新训练整个神经网络的所有参数(将原训练好的神经网络的参数作为初始参数,即通过A数据集进行预训练初始参数pre-train the weight of NN)
以上过程叫做fine-tuning
而数据集A训练的神经网络我们往往会去拿一些开源的优秀的神经网络框架(注意在github下载源码的同事也把权重下载下来)
为什么进行迁移学习?
在原数据集上学到的边缘特征,有助于在新数据集中有更好的算法表现(比如结构信息,图像形状信息等其中有些信息可能会有用)
什么时候进行迁移学习?
(1)taskA,B必须有相同的input,比如都是image或者都是音频
(2)当对于你想要解决的问题数据集很小的时候,则先用大量数据做预训练,然后用少量的目标数据做迁移学习。
(3)A数据的low level特征对学习B数据有帮助的时候
7.数据增强(data augmentation)
训练神经网络往往需要大量的数据,而现实中数据的获取总是难之又难,因此需要用到data augmentation来应用一些技术扩大以后的数据集。
对于图像有以下几种数据增强的方式:
常用的方式
(1)Mirroring镜像翻转

(2)Random Cropping随机裁剪
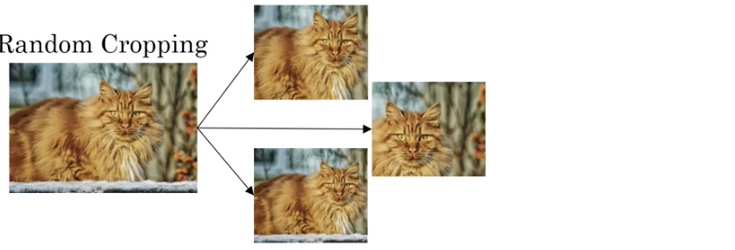
这并不是一个完美的数据增强方式,因为你随机裁剪的部分可能里面并没有目标图像,从而误导模型学习。但对于大量数据而言,这点噪音还可以接受。
(3)Rotation旋转
(4)Shearing扭曲
(5)local warping局部弯曲
color shifting
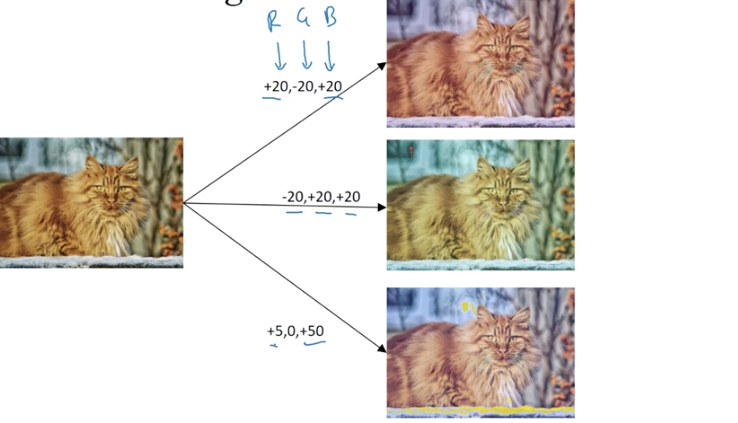
RGB的采样方式:PCA(主成分分析法/PCA颜色增强)
8.论文与比赛中表现好的小技巧
如果在基准数据上有好的表现,则往往很容易发论文,所以学者们都常常致力于在基准数据上下功夫,构建模型,但是这些东东在业务实践上有时并不可观。为了在基准数据上表现良好,或者竞赛中表现优异,有以下tips:
(1)集成模型:独立训练多个模型,然后平均他们的结果进行集成(多个模型计算量太大,不适合于生产)
(2)Multi-crop:让同一个模型跑在不同版本的测试集上(比如数据增强后的不同形式的数据),然后平均结果。
常用的有10-crop,将图片以中心点折起来,分别从左上角开始截取图片,比如如下,总共会得到10张图片:

要做的是,让分类器对这10张图片都做预测,然后选取平均值。(但同样增大了计算量)
(3)使用开源框架:
- 文献中发表的神经网络框架
- 已被实现的开源代码
- 使用与训练好的模型,在你的数据集上fine-tuning