原文链接 https://blog.csdn.net/qq_38688564/article/details/79382724 在这里感谢作者
- 感知器和S型神经元简介
1.1感知器
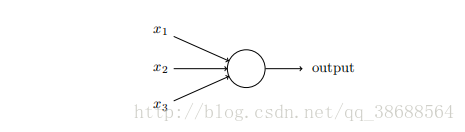
感知器是如何⼯作的呢?⼀个感知器接受⼏个⼆进制输⼊,x1, x2, …,并产⽣⼀个⼆进制输出:
⽰例中的感知器有三个输⼊,x1, x2, x3。通常可以有更多或更少输⼊。Rosenblatt 提议⼀个简单的规则来计算输出。他引⼊权重,w1, w2, …,表⽰相应输⼊对于输出重要性的实数。神经元的输出,0 或者 1,则由分配权重后的总和 ∑j wjxj ⼩于或者⼤于⼀些阈值决定。和权重⼀样,阈值是⼀个实数,⼀个神经元的参数。⽤更精确的代数形式:
这就是⼀个感知器所要做的所有事!
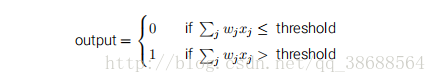
1.2 S型神经元
假设我们有⼀个感知器⽹络,想要⽤它来解决⼀些问题。例如,⽹络的输⼊可以是⼀幅⼿写数字的扫描图像。我们想要⽹络能学习权重和偏置,这样⽹络的输出能正确分类这些数字。为了看清学习是怎样⼯作的,假设我们把⽹络中的权重(或者偏置)做些微⼩的改动。就像我们⻢上会看到的,这⼀属性会让学习变得可能。这⾥简要⽰意我们想要的(很明显这个⽹络对于⼿写识别还是太简单了!): 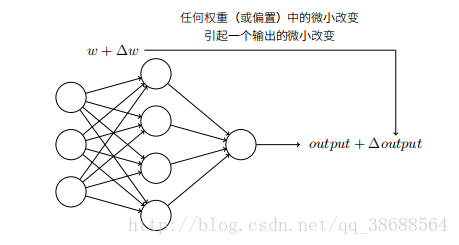
如果对权重(或者偏置)的微⼩的改动真的能够仅仅引起输出的微⼩变化,那我们可以利⽤这⼀事实来修改权重和偏置,让我们的⽹络能够表现得像我们想要的那样。例如,假设⽹络错误地把⼀个“9”的图像分类为“8”。我们能够计算出怎么对权重和偏置做些⼩的改动,这样⽹络能够接近于把图像分类为“9”。然后我们要重复这个⼯作,反复改动权重和偏置来产⽣更好的输出。这时⽹络就在学习。问题在于当我们的⽹络包含感知器时这不会发⽣。实际上,⽹络中单个感知器上⼀个权重或偏置的微⼩改动有时候会引起那个感知器的输出完全翻转,如 0 变到 1。那样的翻转可能接下来引起其余⽹络的⾏为以极其复杂的⽅式完全改变。因此,虽然你的“9”可能被正确分类,⽹络在其它图像上的⾏为很可能以⼀些很难控制的⽅式被完全改变。这使得逐步修改权重和偏置来
让⽹络接近期望⾏为变得困难。也许有其它聪明的⽅式来解决这个问题。但是这不是显⽽易⻅地能让⼀个感知器⽹络去学习。
我们可以引⼊⼀种称为 S 型神经元的新的⼈⼯神经元来克服这个问题。S 型神经元和感知器类似,但是被修改为权重和偏置的微⼩改动只引起输出的微⼩变化。这对于让神经元⽹络学习起来是很关键的。好了 让我来描述下 S 型神经元。我们⽤描绘感知器的相同⽅式来描绘 S 型神经元: 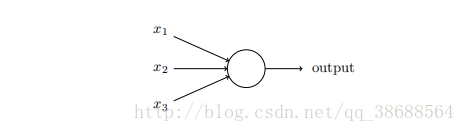
正如⼀个感知器,S 型神经元有多个输⼊,x1, x2, …。但是这些输⼊可以取 0 和 1 中的任意值,⽽不仅仅是 0 或 1。例如,0.638 … 是⼀个 S 型神经元的有效输⼊。同样,S 型神经元对每个输⼊有权重,w1, w2, …,和⼀个总的偏置,b。但是输出不是 0 或 1。相反,它现在是 σ(w · x+b),这⾥ σ 被称为 S 型函数1,定义为: 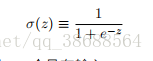
为了理解和感知器模型的相似性,假设 z ≡ w · x + b 是⼀个很⼤的正数。那么 e^(−z) ≈ 0 ⽽σ(z) ≈ 1。即,当 z = w · x + b 很⼤并且为正,S 型神经元的输出近似为 1,正好和感知器⼀样。相反地,假设 z = w · x + b 是⼀个很⼤的负数。那么 e^(−z) → ∞σ(z) ≈ 0。所以当 z = w · x + b是⼀个很⼤的负数,S 型神经元的⾏为也⾮常近似⼀个感知器。只有在 w · x + b 取中间值时,和
感知器模型有⽐较⼤的偏离。σ 的代数形式⼜是什么?我们怎样去理解它呢?实际上,σ 的精确形式不重要 —— 重要的是这个函数绘制的形状。是这样: 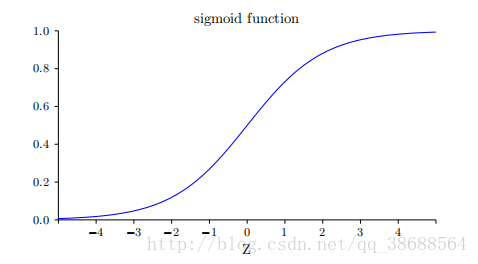
这个形状是阶跃函数平滑后的版本: 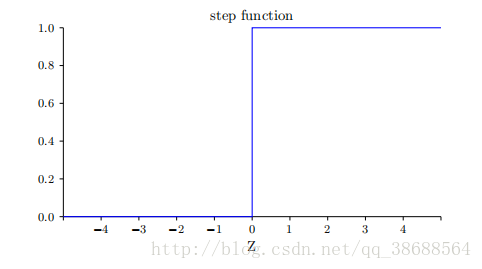
如果 σ 实际是个阶跃函数,既然输出会依赖于 w · x + b 是正数还是负数2,那么 S 型神经元会成为⼀个感知器。利⽤实际的 σ 函数,我们得到⼀个,就像上⾯说明的,平滑的感知器。的确,σ 函数的平滑特性,正是关键因素,⽽不是其细部形式。σ 的平滑意味着权重和偏置的微⼩变化,即 ∆wj 和 ∆b,会从神经元产⽣⼀个微⼩的输出变化 ∆output。实际上,微积分告诉我们∆output 可以很好地近似表⽰为: 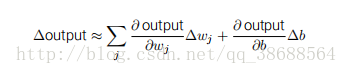
我们应该如何解释⼀个 S 型神经元的输出呢?很明显,感知器和 S 型神经元之间⼀个很⼤的不同是 S 型神经元不仅仅输出 0 或 1。它可以输出 0 和 1 之间的任何实数,所以诸如 0.173 … 和
0.689 … 的值是合理的输出。这是⾮常有⽤的,例如,当我们想要输出来表⽰⼀个神经⽹络的图像像素输⼊的平均强度。但有时候这会是个⿇烦。假设我们希望⽹络的输出表⽰“输⼊图像是
⼀个 9”或“输⼊图像不是⼀个 9”。很明显,如果输出是 0 或 1 是最简单的,就像⽤感知器。但是在实践中,我们可以设定⼀个约定来解决这个问题,例如,约定任何⾄少为 0.5 的输出为表⽰“这是⼀个 9”,⽽其它⼩于 0.5 的输出为表⽰“不是⼀个 9”。当我们正在使⽤这样的约定时,我总会清楚地提出来,这样就不会引起混淆。
1.3 神经网络的架构
前⾯提过,这个⽹络中最左边的称为输⼊层,其中的神经元称为输⼊神经元。最右边的,即输出层包含有输出神经元,在本例中,输出层只有⼀个神经元。中间层,既然这层中的神经元既不是输⼊也不是输出,则被称为隐藏层。“隐藏”这⼀术语也许听上去有些神秘 —— 我第⼀次听到这个词,以为它必然有⼀些深层的哲学或数学涵意 —— 但它实际上仅仅意味着“既⾮输⼊也⾮输出”。上⾯的⽹络仅有⼀个隐藏层,但有些⽹络有多个隐藏层。例如,下⾯的四层⽹络有两个隐藏层:
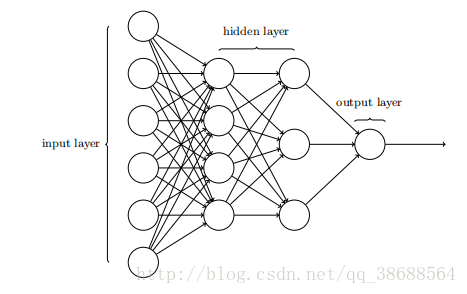
设计⽹络的输⼊输出层通常是⽐较直接的。例如,假设我们尝试确定⼀张⼿写数字的图像上是否写的是“9”。很⾃然地,我们可以将图⽚像素的强度进⾏编码作为输⼊神经元来设计⽹络。如果图像是⼀个 64 × 64 的灰度图像,那么我们会需要 4096 = 64 × 64 个输⼊神经元,每个强度取 0 和 1 之间合适的值。输出层只需要包含⼀个神经元,当输出值⼩于 0.5 时表⽰“输⼊图像不是⼀个 9”,⼤于 0.5 的值表⽰“输⼊图像是⼀个 9”。
相⽐于神经⽹络中输⼊输出层的直观设计,隐藏层的设计则堪称⼀⻔艺术。特别是通过⼀些简单的经验法则来总结隐藏层的设计流程是不可⾏的。相反,神经⽹络的研究⼈员已经为隐藏层开发了许多设计最优法则,这有助于⽹络的⾏为能符合⼈们期望的那样。例如,这些法则可以⽤于帮助权衡隐藏层数量和训练⽹络所需的时间开销。在本书后⾯我们会碰到⼏个这样的设计最优法则。
⽬前为⽌,我们讨论的神经⽹络,都是以上⼀层的输出作为下⼀层的输⼊。这种⽹络被称为前馈神经⽹络。这意味着⽹络中是没有回路的 —— 信息总是向前传播,从不反向回馈。如果确实有回路,我们最终会有这样的情况:σ 函数的输⼊依赖于输出。这将难于理解,所以我们不允许这样的环路。
然⽽,也有⼀些⼈⼯神经⽹络的模型,其中反馈环路是可⾏的。这些模型被称为递归神经⽹络。这种模型的设计思想,是具有休眠前会在⼀段有限的时间内保持激活状态的神经元。这种
激活状态可以刺激其它神经元,使其随后被激活并同样保持⼀段有限的时间。这样会导致更多的神经元被激活,随着时间的推移,我们得到⼀个级联的神经元激活系统。因为⼀个神经元的
输出只在⼀段时间后⽽不是即刻影响它的输⼊,在这个模型中回路并不会引起问题。
递归神经⽹络⽐前馈⽹络影响⼒⼩得多,部分原因是递归⽹络的学习算法(⾄少⽬前为⽌)不够强⼤。但是递归⽹络仍然很有吸引⼒。它们原理上⽐前馈⽹络更接近我们⼤脑的实际⼯作。并且递归⽹络能解决⼀些重要的问题,这些问题如果仅仅⽤前馈⽹络来解决,则更加困难。然⽽为了篇幅,这里将专注于使⽤更⼴泛的前馈⽹络。
1.4 使用梯度下降算法学习
我们将⽤符号 x 来表⽰⼀个训练输⼊。为了⽅便,把每个训练输⼊ x 看作⼀个 28 × 28 = 784维的向量。每个向量中的项⽬代表图像中单个像素的灰度值。我们⽤ y = y(x) 表⽰对应的期望输出,这⾥ y 是⼀个 10 维的向量。例如,如果有⼀个特定的画成 6 的训练图像,x,那么y(x) = (0, 0, 0, 0, 0, 0, 1, 0, 0, 0)T 则是⽹络的期望输出。注意这⾥ T 是转置操作,把⼀个⾏向量转换成⼀个列向量。我们希望有⼀个算法,能让我们找到权重和偏置,以⾄于⽹络的输出 y(x) 能够拟合所有的训练输⼊ x。为了量化我们如何实现这个⽬标我们定义⼀个代价函数: 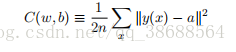
这⾥ w 表⽰所有的⽹络中权重的集合,b 是所有的偏置,n 是训练输⼊数据的个数,a 是表⽰当输⼊为 x 时输出的向量,求和则是在总的训练输⼊ x 上进⾏的。当然,输出 a 取决于 x, w和 b,但是为了保持符号的简洁性,我没有明确地指出这种依赖关系。符号 ∥v∥ 是指向量 v 的模。我们把 C 称为⼆次代价函数;有时也称被称为均⽅误差或者 MSE。观察⼆次代价函数的形式我们可以看到 C(w, b) 是⾮负的,因为求和公式中的每⼀项都是⾮负的。此外,代价函数 C(w, b)的值相当⼩,即 C(w, b) ≈ 0,精确地说,是当对于所有的训练输⼊ x,y(x) 接近于输出 a 时。因此如果我们的学习算法能找到合适的权重和偏置,使得 C(w, b) ≈ 0,它就能很好地⼯作。相反,当 C(w, b) 很⼤时就不怎么好了,那意味着对于⼤量地输⼊,y(x) 与输出 a 相差很⼤。因此我们的训练算法的⽬的,是最⼩化权重和偏置的代价函数 C(w, b)。换句话说,我们想要找到⼀系列能让代价尽可能⼩的权重和偏置。我们将采⽤称为梯度下降的算法来达到这个⽬的。
为什么要介绍⼆次代价呢?毕竟我们最初感兴趣的内容不是能正确分类的图像数量吗?为什么不试着直接最⼤化这个数量,⽽是去最⼩化⼀个类似⼆次代价的间接评量呢?这么做是因为在神经⽹络中,被正确分类的图像数量所关于权重和偏置的函数并不是⼀个平滑的函数。⼤多数情况下,对权重和偏置做出的微⼩变动完全不会影响被正确分类的图像的数量。这会导致我们很难去解决如何改变权重和偏置来取得改进的性能。⽽⽤⼀个类似⼆次代价的平滑代价函数则能更好地去解决如何⽤权重和偏置中的微⼩的改变来取得更好的效果。这就是为什么我们⾸先专注于最⼩化⼆次代价,只有这样,我们之后才能测试分类精度。
重复⼀下,我们训练神经⽹络的⽬的是找到能最⼩化⼆次代价函数 C(w, b) 的权重和偏置。这是⼀个适定问题,但是现在它有很多让我们分散精⼒的结构 —— 对权重 w 和偏置 b 的解释,晦涩不清的 σ 函数,神经⽹络结构的选择,MNIST 等等。事实证明我们可以忽略结构中⼤部分,把精⼒集中在最⼩化⽅⾯来理解它。现在我们打算忘掉所有关于代价函数的具体形式、神经⽹络的连接等等。现在让我们想象只要最⼩化⼀个给定的多元函数。我们打算使⽤⼀种被称为梯度下降的技术来解决这样的最⼩化问题。然后我们回到在神经⽹络中要最⼩化的特定函数上来。
好了,假设我们要最⼩化某些函数,C(v)。它可以是任意的多元实值函数,v = v1, v2, …。注意我们⽤ v 代替了 w 和 b 以强调它可能是任意的函数 —— 我们现在先不局限于神经⽹络的环境。为了最⼩化 C(v),想象 C 是⼀个只有两个变量 v1 和 v2 的函数: 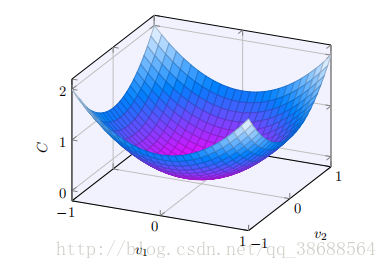
我们想要的是找到 C 的全局最⼩值。当然,对于上图的函数,我们⼀眼就能找到最⼩值。那只意味着,也许我展⽰的函数过于简单了!通常函数 C 可能是⼀个复杂的多元函数,看⼀下就能找到最⼩值可是不可能的。
⼀种解决这个问题的⽅式是⽤微积分来解析最⼩值。我们可以计算导数去寻找 C 的极值点。运⽓好的话,C 是⼀个只有⼀个或少数⼏个变量的函数。但是变量过多的话那就是噩梦。⽽且神经⽹络中我们经常需要⼤量的变量——最⼤的神经⽹络有依赖数亿权重和偏置的代价函数,极其复杂。⽤微积分来计算最⼩值已经不可⾏了。
好吧,微积分是不能⽤了。幸运的是,有⼀个漂亮的推导法暗⽰有⼀种算法能得到很好的效果。⾸先把我们的函数想象成⼀个⼭⾕。只要瞄⼀眼上⾯的绘图就不难理解。我们想象有⼀个⼩球从⼭⾕的斜坡滚落下来。我们的⽇常经验告诉我们这个球最终会滚到⾕底。也许我们可以⽤这⼀想法来找到函数的最⼩值?我们会为⼀个(假想的)球体随机选择⼀个起始位置,然后模拟球体滚落到⾕底的运动。我们可以通过计算 C 的导数(或者⼆阶导数)来简单模拟——这些导数会告诉我们⼭⾕中局部“形状”的⼀切,由此知道我们的球将怎样滚动。
为了更精确地描述这个问题,让我们思考⼀下,当我们在 v1 和 v2 ⽅向分别将球体移动⼀个很⼩的量,即 ∆v1 和 ∆v2 时,球体将会发⽣什么情况。微积分告诉我们 C 将会有如下变化: 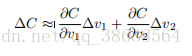
我们要寻找⼀种选择 ∆v1 和 ∆v2 的⽅法使得 ∆C 为负;即,我们选择它们是为了让球体滚落。为了弄明⽩如何选择,需要定义 ∆v 为 v 变化的向量,∆v ≡ (∆v1, ∆v2)^T,T 是转置符号。
我们也定义 C 的梯度为偏导数的向量,(∂C/∂v1,∂C/∂v2)^T。我们⽤ ∇C 来表⽰梯度向量,即: 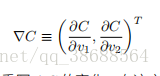
有了这些定义,∆C 的表达式 (7) 可以被重写为: 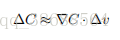
这个表达式解释了为什么 ∇C 被称为梯度向量:∇C 把 v 的变化关联为 C 的变化,正如我们期望的⽤梯度来表⽰。但是这个⽅程真正让我们兴奋的是它让我们看到了如何选取 ∆v 才能让∆C 为负数。假设我们选取: 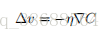
这⾥的 η 是个很⼩的正数(称为学习速率)。
⽅程∆C ≈ ∇C · ∆v (9) 告诉我们 ∆C ≈ −η∇C·∇C = −η∥∇C∥^2。由于 ∥∇C∥^2 ≥ 0,这保证了 ∆C ≤ 0,即,如果我们按照⽅程 ∆v = −η∇C(10)的规则去改变 v,那么 C 会⼀直减⼩,不会增加。(当然,要在⽅程 ∆C ≈ ∇C · ∆v 的近似约束下)。这正是我们想要的特性!因此我们把⽅程 (10) ⽤于定义球体在梯度下降算法下的“运动定律”。也就是说,我们⽤⽅程 (10) 计算∆v,来移动球体的位置 v:v → v′ = v − η∇C
然后我们⽤它再次更新规则来计算下⼀次移动。如果我们反复持续这样做,我们将持续减⼩C 直到 —— 正如我们希望的 —— 获得⼀个全局的最⼩值。
总结⼀下,梯度下降算法⼯作的⽅式就是重复计算梯度 ∇C,然后沿着相反的⽅向移动,沿着⼭⾕“滚落”。我们可以想象它像这样: 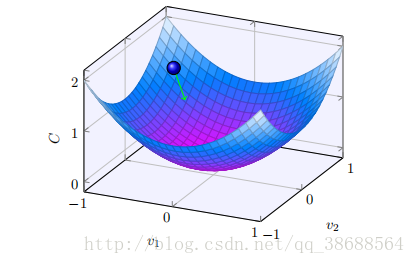
为了使梯度下降能够正确地运⾏,我们需要选择⾜够⼩的学习速率 η 使得⽅程 (9) 能得到很好的近似。如果不这样,我们会以 ∆C > 0 结束,这显然不好。同时,我们也不想 η 太⼩,因为这会使 ∆v 的变化极⼩,梯度下降算法就会运⾏得⾮常缓慢。在真正的实现中,η 通常是变化的,以⾄⽅程 (9) 能保持很好的近似度,但算法⼜不会太慢。我们后⾯会看这是如何⼯作的。
我已经解释了具有两个变量的函数 C 的梯度下降。但事实上,即使 C 是⼀个具有更多变量的函数也能很好地⼯作。我们假设 C 是⼀个有 m 个变量 v1, … , vm 的多元函数。那么对 C 中⾃变量的变化 ∆v = (∆v1, … , ∆vm)^T,∆C 将会变为:∆C ≈ ∇C · ∆v(12),
这⾥的梯度 ∇C 是向量∇C ≡(∂C/∂v1, … ,∂C/∂vm)^T,正如两个变量的情况,我们可以选取 ∆v = −η∇C,
⽽且 ∆C 的(近似)表达式 (12) 保证是负数。这给了我们⼀种⽅式从梯度中去取得最⼩值,即使 C 是任意的多元函数,我们也能重复运⽤更新规则 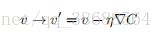
你可以把这个更新规则看做定义梯度下降算法。这给我们提供了⼀种⽅式去通过重复改变 v来找到函数 C 的最⼩值。这个规则并不总是有效的 —— 有⼏件事能导致错误,让我们⽆法从梯度下降来求得函数 C 的全局最⼩值,这个观点我们会在后⾯的章节中去探讨。但在实践中,梯度下降算法通常⼯作地⾮常好,在神经⽹络中这是⼀种⾮常有效的⽅式去求代价函数的最⼩值,进⽽促进⽹络⾃⾝的学习。
1.5 随机梯度下降
⼈们已经研究出很多梯度下降的变化形式,包括⼀些更接近真实模拟球体物理运动的变化形式。这些模拟球体的变化形式有很多优点,但是也有⼀个主要的缺点:它最终必需去计算 C 的⼆阶偏导,这代价可是⾮常⼤的。为了理解为什么这种做法代价⾼,假设我们想求所有的⼆阶偏导 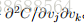
我们怎么在神经⽹络中⽤梯度下降算法去学习呢?其思想就是利⽤梯度下降算法去寻找能使得⽅程 
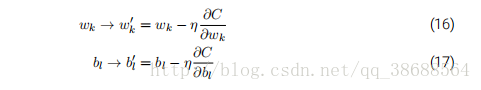
通过重复应⽤这⼀更新规则我们就能“让球体滚下⼭”,并且有望能找到代价函数的最⼩值。换句话说,这是⼀个能让神经⽹络学习的规则。
应⽤梯度下降规则有很多挑战。我们将在下⼀章深⼊讨论。但是现在只提及⼀个问题。为了理解问题是什么,我们先回顾(6) 中的⼆次代价。注意这个代价函数有着这样的形式 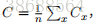
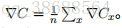
有种叫做随机梯度下降的算法能够加速学习。其思想就是通过随机选取⼩量训练输⼊样本来计算 ∇Cx,进⽽估算梯度 ∇C。通过计算少量样本的平均值我们可以快速得到⼀个对于实际梯度 ∇C 的很好的估算,这有助于加速梯度下降,进⽽加速学习过程。
更准确地说,随机梯度下降通过随机选取⼩量的 m 个训练输⼊来⼯作。我们将这些随机的训练输⼊标记为 X1, X2, … , Xm,并把它们称为⼀个⼩批量数据(mini-batch)。假设样本数量
m ⾜够⼤,我们期望 ∇CXj 的平均值⼤致相等于整个 ∇Cx 的平均值,即, 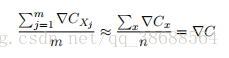
这⾥的第⼆个求和符号是在整个训练数据上进⾏的。交换两边我们得到: 
证实了我们可以通过仅仅计算随机选取的⼩批量数据的梯度来估算整体的梯度。
为了将其明确地和神经⽹络的学习联系起来,假设 wk 和 bl 表⽰我们神经⽹络中权重和偏置。随即梯度下降通过随机地选取并训练输⼊的⼩批量数据来⼯作, 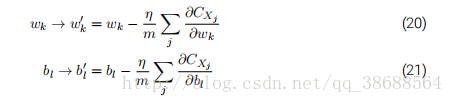
其中两个求和符号是在当前⼩批量数据中的所有训练样本 Xj 上进⾏的。然后我们再挑选另⼀随机选定的⼩批量数据去训练。直到我们⽤完了所有的训练输⼊,这被称为完成了⼀个训练迭代期(epoch)。然后我们就会开始⼀个新的训练迭代期。
另外值得提⼀下,对于改变代价函数⼤⼩的参数,和⽤于计算权重和偏置的⼩批量数据的更新规则,会有不同的约定。在⽅程 (6) 中,我们通过因⼦ 1/n 来改变整个代价函数的⼤⼩。⼈们有
时候忽略 1/n,直接取单个训练样本的代价总和,⽽不是取平均值。这对我们不能提前知道训练数据数量的情况下特别有效。例如,这可能发⽣在有更多的训练数据是实时产⽣的情况下。同
样,⼩批量数据的更新规则 (20) 和 (21) 有时也会舍弃前⾯的 1
m。从概念上这会有⼀点区别,因为它等价于改变了学习速率 η 的⼤⼩。但在对不同⼯作进⾏详细对⽐时,需要对它警惕。
我们可以把随机梯度下降想象成⼀次⺠意调查:在⼀个⼩批量数据上采样⽐对⼀个完整数据集进⾏梯度下降分析要容易得多,正如进⾏⼀次⺠意调查⽐举⾏⼀次全⺠选举要更容易。例如,
如果我们有⼀个规模为 n = 60, 000 的训练集,就像 MNIST,并选取⼩批量数据 ⼤⼩为 m = 10,这意味着在估算梯度过程中加速了 6, 000 倍!当然,这个估算并不是完美的 —— 存在统计波
动 —— 但是没必要完美:我们实际关⼼的是在某个⽅向上移动来减少 C,⽽这意味着我们不需要梯度的精确计算。在实践中,随机梯度下降是在神经⽹络的学习中被⼴泛使⽤、⼗分有效的
技术,它也是本书中展开的⼤多数学习技术的基础。
1.6 实现我们的网络来分类数字
https://github.com/mnielsen/neural-networks-and-deep-learning.git
# %load network.py
"""
network.py
~~~~~~~~~~
IT WORKS
A module to implement the stochastic gradient descent learning
algorithm for a feedforward neural network. Gradients are calculated
using backpropagation. Note that I have focused on making the code
simple, easily readable, and easily modifiable. It is not optimized,
and omits many desirable features.
"""
#### Libraries
# Standard library
import random
# Third-party libraries
import numpy as np
class Network(object):
def __init__(self, sizes):
"""The list ``sizes`` contains the number of neurons in the
respective layers of the network. For example, if the list
was [2, 3, 1] then it would be a three-layer network, with the
first layer containing 2 neurons, the second layer 3 neurons,
and the third layer 1 neuron. The biases and weights for the
network are initialized randomly, using a Gaussian
distribution with mean 0, and variance 1. Note that the first
layer is assumed to be an input layer, and by convention we
won't set any biases for those neurons, since biases are only
ever used in computing the outputs from later layers."""
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
def feedforward(self, a):
"""Return the output of the network if ``a`` is input."""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a
def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):
"""Train the neural network using mini-batch stochastic
gradient descent. The ``training_data`` is a list of tuples
``(x, y)`` representing the training inputs and the desired
outputs. The other non-optional parameters are
self-explanatory. If ``test_data`` is provided then the
network will be evaluated against the test data after each
epoch, and partial progress printed out. This is useful for
tracking progress, but slows things down substantially."""
training_data = list(training_data)
n = len(training_data)
if test_data:
test_data = list(test_data)
n_test = len(test_data)
for j in range(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size]
for k in range(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
if test_data:
print("Epoch {} : {} / {}".format(j,self.evaluate(test_data),n_test))
else:
print("Epoch {} complete".format(j))
def update_mini_batch(self, mini_batch, eta):
"""Update the network's weights and biases by applying
gradient descent using backpropagation to a single mini batch.
The ``mini_batch`` is a list of tuples ``(x, y)``, and ``eta``
is the learning rate."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
def backprop(self, x, y):
"""Return a tuple ``(nabla_b, nabla_w)`` representing the
gradient for the cost function C_x. ``nabla_b`` and
``nabla_w`` are layer-by-layer lists of numpy arrays, similar
to ``self.biases`` and ``self.weights``."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# Note that the variable l in the loop below is used a little
# differently to the notation in Chapter 2 of the book. Here,
# l = 1 means the last layer of neurons, l = 2 is the
# second-last layer, and so on. It's a renumbering of the
# scheme in the book, used here to take advantage of the fact
# that Python can use negative indices in lists.
for l in range(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
def evaluate(self, test_data):
"""Return the number of test inputs for which the neural
network outputs the correct result. Note that the neural
network's output is assumed to be the index of whichever
neuron in the final layer has the highest activation."""
test_results = [(np.argmax(self.feedforward(x)), y)
for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y):
"""Return the vector of partial derivatives \partial C_x /
\partial a for the output activations."""
return (output_activations-y)
#### Miscellaneous functions
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""Derivative of the sigmoid function."""
return sigmoid(z)*(1-sigmoid(z))
测试代码:
import mnist_loader
import network
training_data, validation_data, test_data = mnist_loader.load_data_wrapper()
training_data = list(training_data)
net = network.Network([784, 30, 10])
net.SGD(training_data, 30, 10, 3.0, test_data=test_data)结果:
Epoch 0 : 9098 / 10000
Epoch 1 : 9227 / 10000
Epoch 2 : 9325 / 10000
Epoch 3 : 9337 / 10000
Epoch 4 : 9391 / 10000
Epoch 5 : 9404 / 10000
Epoch 6 : 9429 / 10000
Epoch 7 : 9425 / 10000
Epoch 8 : 9446 / 10000
Epoch 9 : 9472 / 10000
Epoch 10 : 9496 / 10000
Epoch 11 : 9503 / 10000
Epoch 12 : 9481 / 10000
Epoch 13 : 9523 / 10000
Epoch 14 : 9502 / 10000
Epoch 15 : 9510 / 10000
Epoch 16 : 9514 / 10000
Epoch 17 : 9504 / 10000
Epoch 18 : 9500 / 10000
Epoch 19 : 9500 / 10000
Epoch 20 : 9519 / 10000
Epoch 21 : 9509 / 10000
Epoch 22 : 9535 / 10000
Epoch 23 : 9538 / 10000
Epoch 24 : 9528 / 10000
Epoch 25 : 9530 / 10000
Epoch 26 : 9517 / 10000
Epoch 27 : 9528 / 10000
Epoch 28 : 9543 / 10000
Epoch 29 : 9522 / 10000更确切地说,经过训练的⽹络给出的识别率约为 95% —— 在峰值时为 95.42%(“Epoch 28”)!作为第⼀次尝试,这是⾮常令⼈⿎舞的。然⽽我应该提醒你,如果你运⾏代码然后得到的结果和我的不完全⼀样,那是因为我们使⽤了(不同的)随机权重和偏置来初始化我们的⽹络。
让我们重新运⾏上⾯的实验,将隐藏神经元数量改到 100。
net = network.Network([784, 100, 10])
net.SGD(training_data, 30, 10, 3.0, test_data=test_data)果然,它将结果提升⾄ 96.59%。⾄少在这种情况下,使⽤更多的隐藏神经元帮助我们得到了更好的结果。这里还可以更改学习率 η 来提高准确度,这会在接下来博客中介绍如何调优参数。