6. python3.6实现
根据前面的一步步推导获得的结果,我们就可以使用python来实现SVM了
这里我们使用iris数据集进行验证,由于该数据集有4维,不容易在二维平面上表示,我们先使用LDA对其进行降维,又因为该数据集有3类样本,我们编写的SVM是二分类的,所以我们将获取的第二个样本的label设为1,其他两类样本的label设为-1
# -*- coding: gbk -*-
import numpy as np
import matplotlib.pyplot as plt
import math
from sklearn.datasets import load_iris
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
class SVM():
def __init__(self, C, kernel, kernel_arg, e=0.001):
'''
kernel_arg
kernel的类型: 'linear': 1
'poly': d(d>1且为整数)
'gaussian': σ(σ>0)
'lapras': σ(σ>0)
'sigmoid': beta,theta(beta>0,theta<0)
kernel_arg若不符合要求将按照默认参数进行计算
C为目标函数非线性部分的权重
e为误差
'''
self.kernel = kernel
self.kernel_arg = kernel_arg
self.C = C
self.e = e
self.bias = 0
def kernel_function(self, x1, x2):
if self.kernel == 'linear':
return np.dot(x1, x2)
elif self.kernel == 'poly':
if isinstance(self.kernel_arg, int) == False:
self.kernel_arg = 2
return np.dot(x1, x2)**self.kernel_arg
elif self.kernel == 'gaussian':
if isinstance(self.kernel_arg, float) == False:
self.kernel_arg = 0.5
return math.exp(-np.linalg.norm(x1 - x2)**2 / (2 * self.kernel_arg**2))
elif self.kernel == 'lapras':
if isinstance(self.kernel_arg, float) == False:
self.kernel_arg = 0.5
return math.exp(-np.linalg.norm(x1 - x2) / self.kernel_arg)
elif self.kernel == 'sigmoid':
if len(self.kernel_arg) != 2:
self.kernel_arg = [0.5, -0.5]
if self.kernel_arg[0] <= 0:
self.kernel_arg[0] = 0.5
if self.kernel_arg[1] >= 0:
self.kernel_arg[1] = 0.5
return math.tanh(self.kernel_arg[0] * np.dot(x1, x2) + self.kernel_arg[1])
def fit(self, train_x, train_y, max_iter=1000):
self.train_x = np.array(train_x)
self.train_y = np.array(train_y)
self.alpha = np.zeros(train_x.shape[0])
iter = 0
while(iter < max_iter):
print('iter = {}'.format(iter))
index1, index2 = self.SMO_get_alpha()
if index1 == -1:
print('结束迭代, iter = {}'.format(iter))
break
train_result = self.SMO_train(index1, index2)
if train_result == True:
print('结束迭代, iter = {}'.format(iter))
break
iter += 1
def SMO_get_alpha(self):
for i in range(self.alpha.shape[0]):
if 0 < self.alpha[i] < self.C:
if self.train_y[i] * self.f(self.train_x[i]) != 1:
index2 = self.choose_another_alpha(i)
return i, index2
for i in range(self.alpha.shape[0]):
if self.alpha[i] == 0:
if self.train_y[i] * self.f(self.train_x[i]) < 1:
index2 = self.choose_another_alpha(i)
return i, index2
elif self.alpha[i] == self.C:
if self.train_y[i] * self.f(self.train_x[i]) > 1:
index2 = self.choose_another_alpha(i)
return i, index2
return -1, -1
def f(self, x):
result = 0
for i in range(self.alpha.shape[0]):
result += self.alpha[i] * self.train_y[i] * \
self.kernel_function(self.train_x[i], x)
return result + self.bias
def error(self, index):
return self.f(self.train_x[index]) - self.train_y[index]
def choose_another_alpha(self, index):
result_index = 0
temp_diff_error = 0
for i in range(self.alpha.shape[0]):
diff_error = np.abs(self.error(index) - self.error(i))
if diff_error > temp_diff_error:
temp_diff_error = diff_error
result_index = i
return result_index
def SMO_train(self, index1, index2):
old_alpha = self.alpha.copy()
x1 = self.train_x[index1]
y1 = self.train_y[index1]
x2 = self.train_x[index2]
y2 = self.train_y[index2]
eta = self.kernel_function(
x1, x1) + self.kernel_function(x2, x2) - 2 * self.kernel_function(x1, x2)
alpha2 = old_alpha[index2] + y2 * \
(self.error(index1) - self.error(index2)) / eta
if y1 != y2:
L = max(0, old_alpha[index2] - old_alpha[index1])
H = min(self.C, self.C + old_alpha[index2] - old_alpha[index1])
else:
L = max(0, old_alpha[index1] + old_alpha[index2] - self.C)
H = min(self.C, old_alpha[index1] + old_alpha[index2])
if alpha2 > H:
alpha2 = H
elif alpha2 < L:
alpha2 = L
alpha1 = old_alpha[index1] + y1 * y2 * (old_alpha[index2] - alpha2)
self.alpha[index1] = alpha1
self.alpha[index2] = alpha2
b1 = -self.error(index1) \
- y1 * self.kernel_function(x1, x1) * (alpha1 - old_alpha[index1]) \
- y2 * self.kernel_function(x1, x2) * (alpha2 - old_alpha[index2]) \
+ self.bias
b2 = -self.error(index2) \
- y1 * self.kernel_function(x1, x2) * (alpha1 - old_alpha[index1]) \
- y2 * self.kernel_function(x2, x2) * (alpha2 - old_alpha[index2]) \
+ self.bias
if 0 < alpha1 < self.C:
self.bias = b1
elif 0 < alpha2 < self.C:
self.bias = b2
else:
self.bias = (b1 + b2) / 2
print('E = {}'.format(np.linalg.norm(old_alpha - self.alpha)))
if np.linalg.norm(old_alpha - self.alpha) < self.e:
return True
else:
return False
def predict_one(self, x):
if self.f(x) > 0:
return 1
else:
return -1
def predict(self, x_group):
return np.array([self.predict_one(x) for x in x_group])
if __name__ == '__main__':
iris = load_iris()
X = iris.data
y = iris.target
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X, y)
X = lda.transform(X)
train_data = X[0::2, :]
train_label = y[0::2]
for i in range(train_label.shape[0]):
if train_label[i] != 1:
train_label[i] = -1
else:
train_label[i] = 1
test_data = X[1::2, :]
test_label = y[1::2]
for i in range(test_label.shape[0]):
if test_label[i] != 1:
test_label[i] = -1
else:
test_label[i] = 1
svm = SVM(5, 'gaussian', 0.5, 0.001)
svm.fit(train_data, train_label)
predict_label = svm.predict(test_data)
a = predict_label - test_label
print(a)
# print(svm.alpha)
count = 0
for i in range(a.shape[0]):
if a[i] == 0:
count += 1
print(count / test_label.shape[0])
points = []
for i in np.linspace(-10.0, 10.0, num=400):#获取超平面上的点为了作图
for j in np.linspace(-5.0, 5.0, num=200):
x_ij = np.array([i, j])
if -0.05 < svm.f(x_ij) < 0.05:
tmp = [i, j]
points.append(tmp)
points = np.array(points)
print(points)
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.scatter(points[:, 0], points[:, 1], marker='o')
plt.show()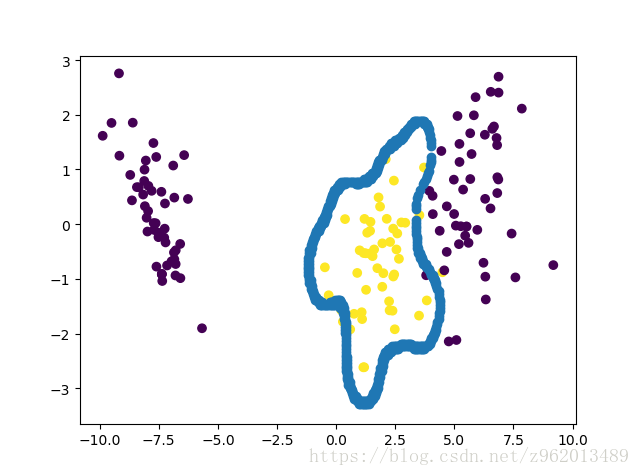
我们用了高斯核获取样本和划分曲线,由于不知道怎么画出超平面,我只好取巧不断将点代入方程,判断结果是否与0很接近,然后把和0接近的点画出来,另外我发现在用高斯核的时候e设0.01就好了,但是在用poly核的时候需要设的小很多,不然得到的结果很差。
- C越大,拟合非线性的能力越强,但是更容易过拟合
- 高斯核的参数 越大,函数越平滑,拟合非线性的能力越差,对噪声越不敏感
- 若使用核函数,一定要对Feature做Feature Scaling(Normalization)(我这里没做。。。)
- 若训练集m太小,但Feature数量n很大,则训练数据不足以拟合复杂的非线性模型,这种情况下只能用linear-kernel,不能用高斯核
- 时样本点在最大间隔以外,计算模型时不做考虑, 时样本在超平面上, 时样本位于最大间隔之间
传送门
支持向量机(SVM)和python实现(一)https://blog.csdn.net/z962013489/article/details/82499063
支持向量机(SVM)和python实现(二)https://blog.csdn.net/z962013489/article/details/82559626
参考:
《机器学习》周志华
https://zhuanlan.zhihu.com/p/24638007
https://blog.csdn.net/u011734144/article/details/81233553
https://blog.csdn.net/zouxy09/article/details/17292011
https://blog.csdn.net/zouxy09/article/details/17291805
https://blog.csdn.net/wisedoge/article/details/57077614
https://blog.csdn.net/timruning/article/details/49779767
https://blog.csdn.net/ybdesire/article/details/53915093