1. 问题的提出
若存在一个样本集,其中有两类数据,我们希望将他们分类
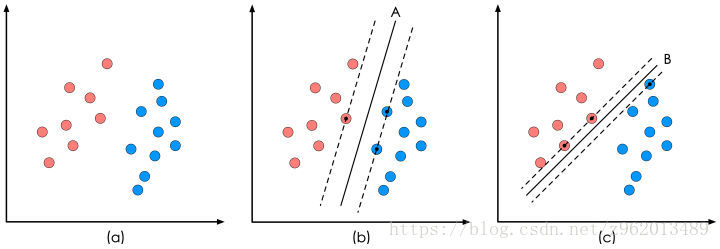
像上图(a)那样的样本集,SVM的目的就是企图获得一个超平面(在这个例子中超平面是一个直线),这个超平面可以完美的分割不同的数据集,我们用下面的线性方程来表示这个超平面:
ωTx+b=0
对于二维空间的超平面,实际上就是:
[w1w2][xy]+b=0
我们再观察图(b)和(c)的两个直线,很明显b中的直线对样本集的划分更好一些,因为,在直线边缘的样本点离直线更远一些,这样就提高了样本划分的鲁棒性,所以我们就有了一个寻找超平面的最开始的理念:找到的这个超平面要离2组样本集尽量的远,即点到超平面的距离尽量大。
这里直接给出点到超平面的距离:
d=∣∣ωTx+b∣∣∥ω∥
我们现在再给出样本的类别标签,红色点为-1,蓝色点为1,则有:
{ωTxi+b>0ωTxi+b<0yi=1yi=−1
如果我们要求再高一些,我们希望这些点到超平面的距离都要大于d,则有:
{(ωTxi+b)/∥ω∥≥d(ωTxi+b)/∥ω∥≤dyi=1yi=−1
不等式两边同时除以d,可以得到:
{ωTdxi+bd≥1ωTdxi+bd≤−1yi=1yi=−1
其中
ωd=ω∥ω∥d,bd=b∥ω∥d
实际上
ωTdxi+bd=0
和
ωTxi+b=0
是同样的超平面,既然如此我们就把
ωd
和
bd
继续叫做
ω
和
b
,那么我们就获得了SVM优化问题的约束条件:
{ωTxi+b≥1ωTxi+b≤−1yi=1yi=−1(1.1)
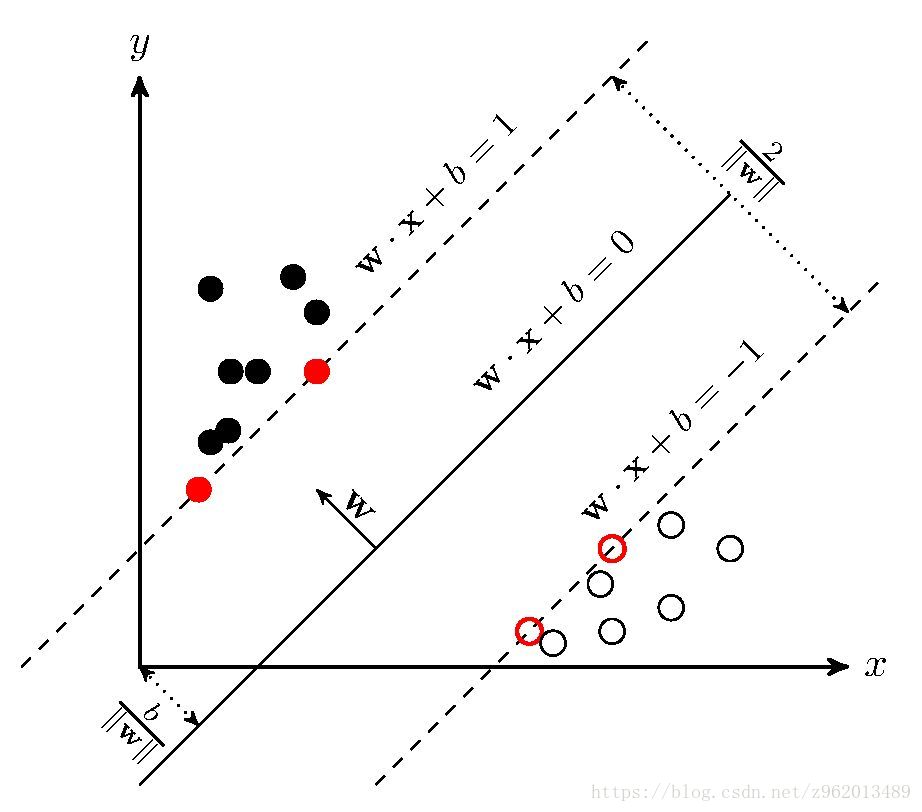
(图片来自https://www.cnblogs.com/freebird92/p/8909546.html)
如上图所示的距离超平面最近的几个训练样本点使(1.1)中的等号成立,这些点我们称为“支持向量”,两个异类支持向量到超平面的距离之和为
2∥ω∥2
,我们希望这个值越大越好,即
12∥ω∥2
越小越好,所以我们的问题就变成了:
min12∥ω∥2s.t. yi(ωTxi+b)≥1,i=1,2,...,m.(1.2)
2. 对偶问题
式(1.2)是一个凸二次规划问题,我们可以使用拉格朗日乘子法获取其对偶问题来求解,引入拉格朗日乘子
αi≥0i=1,2,...,m
,则式(1.2)写为:
L(ω,b,α)=12∥ω∥2+∑i=1mαi(1−yi(ωTxi+b))(2.1)
对
ω
,b求偏导为0可得:
ω=∑i=1mαiyixi0=∑i=1mαiyi(2.2)
将(2.2)带入(2.1)可得:
L(ω,b,α)=12∥ω∥2+∑i=1mαi(1−yi(ωTxi+b))=12ωTω−ωT∑i=1mαiyixi+∑i=1mαi−∑i=1mαiyib=12ωT(ω−2∑i=1mαiyixi)+∑i=1mαi=∑i=1mαi−12∑i=1,j=1mαiαjyiyjxTixj(2.3)
最后的对偶问题为:
max.∑i=1mαi−12∑i=1,j=1mαiαjyiyjxTixjs.t. αi≥0∑i=1mαiyi(2.4)
解出
α
后求出
ω
和b就可以得到模型:
f(x)=ωTx+b=∑i=1mαiyixix+b(2.5)
因为式(1.2)含有不等式约束,因此对偶问题应满足KKT条件,这里稍微说一下KKT条件怎么获得的。
KKT条件

(图来自https://zhuanlan.zhihu.com/p/24638007)
不等式约束
g(x)≤0
即为图中的可行解区域,最优解
x∗
的位置有两种情况:在可行区域边界上或者在可行区域内部。
在边界上:这种情况下
g(x)=0
,目标函数
f(x)
在可行解区域边缘更大,可行解区域其他地方更小,而
g(x)
在可行解区域内小于0,外部大于0,意味着
f(x)
的梯度方向与约束条件函数
g(x)
的梯度方向相反,则在最优解处满足下式:
∇f(x∗)+λ∇g(x∗)=0
根据上式可以推出当最优解在边界上时
λ>0
在区域内:这种情况相当于约束条件不存在,因此拉格朗日乘子
λ=0
,
g(x)<0
这样就得出了KKT条件
⎧⎩⎨⎪⎪g(x)≤0λ≥0λg(x)=0
其中第一个式子是约束本身,第二个式子是对拉格朗日乘子的描述,第三个式子是综合上述2种情况后获得的表达。
现在我们再回到之前的对偶问题中,(2.4)需要满足的KKT条件为:
⎧⎩⎨⎪⎪αi≥0yif(xi)−1≥0αi(yif(xi)−1)=0
于是,对于任意训练样本,总有
αi=0
或
yif(xi)=1
,当
αi=0
时,该样本不会对目标函数产生影响,若
αi>0
,则必有
yif(xi)=1
,此时对应样本位于最大间隔边界上,是一个支持向量。
3. 核函数
前面我们举的例子都是线性可分的,如果找不到一条直线将两个数据集分离的时候该怎么办呢?
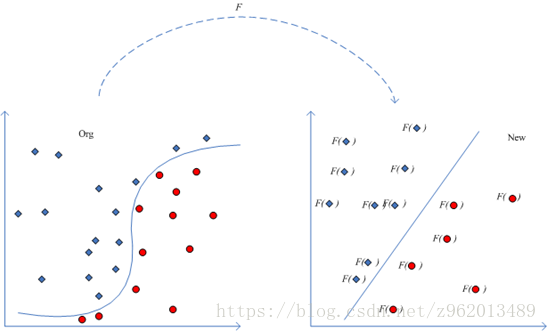
(图片来自http://www.360doc.com/content/14/0526/16/10724725_381159791.shtml)
对于这样的问题,我们可以通过将样本点从原始空间映射到一个更高维的特征空间,使在这个新的特征空间内,样本点变得线性可分,就像上图描述的那样,我们用
φ(x)
来表示将x映射后的特征向量,于是我们就可以将模型写为:
f(x)=ωTφ(x)+b=∑i=1mαiyiφ(x)Tφ(xi)+b(3.1)
对偶问题也描述为:
max.∑i=1mαi−12∑i=1,j=1mαiαjyiyjφ(xi)Tφ(xj)s.t. αi≥0∑i=1mαiyi(3.2)
求解(3.2)涉及到计算
φ(xi)Tφ(xj)
考虑到样本x映射到特征空间后维数可能很高,因此直接计算
φ(xi)Tφ(xj)
是很困难的,为了避免这种情况,我们引入下面这样的函数:
κ(xi,xj)=<φ(xi)φ(xj)>=φ(xi)Tφ(xj)
未完待续。。。