7.1 预备知识
我们描述的算法都将是可以互换的。每个算法都将接收包含一些元素的数组;假设所有的数组位置都包含要排序的数据。我们还假设N是传递到排序程序的元素个数。
除(引用)赋值运算外,这是仅有允许对输入数据进行的操作。在这些条件下的排序叫做基于比较的排序
7.2 插入排序
插入排序由N-1趟组成。对于p=1到N-1趟,插入排序保证从位置0到位置p上的元素为已排序状态。插入排序利用了这样的事实:已知位置0到位置p-1上的元素已经处于排过序的状态。
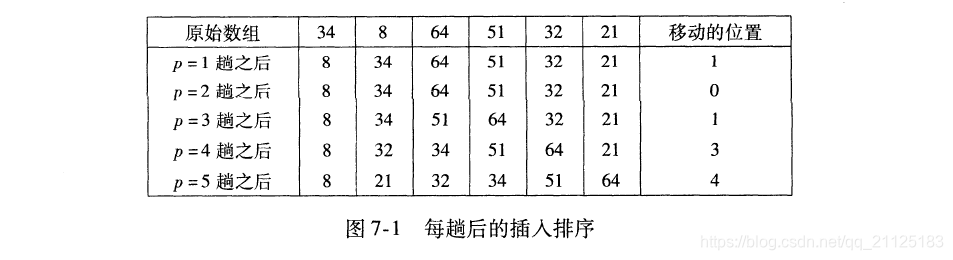 )
)
- 插入排序的最好和最坏的时间复杂度都是O(N^2) 插入排序是一种稳定的排序。
7.3 希尔排序
希尔排序的名称起源于它的发明者Donald Shell。该算法是冲破二次时间屏障的第一批算法之一。正如上节所提到的,它通过比较相距一定间隔的元素来工作;各趟比较所用的距离随着算法的进行而减少,知道只比较相邻元素的最后一趟排序为止。
希尔排序使用一个序列h1,h2,…,hi,叫做增量序列。
- 希尔排序是一个非常不稳定的排序。希尔排序的时间复杂度为O(n^(1.3—2))
7.4 堆排序
优先队列可以用于以O(NlogN)时间的排序。基于该思想的算法叫做堆排序,它给出了我们至今所见到的最佳大O的运行时间。
回忆建立N个元素的二叉堆的基本策略,这个阶段花费O(N)的时间。然后我们执行N次deleteMin操作。按照顺序,最小的元素先离开堆。通过将这些元素记录到第二个数组然后再将数组拷贝回来,得到N个元素的排序。由于每个deleteMin花费的时间开销都是O(logN),因总的运行时间为O(N*logN)
- 堆排序是一个不稳定的排序。它的时间复杂度为O(N*logN)
7.5 归并排序
归并排序以O(N*logN)最坏情形时间运行,而所使用的比较次数几乎是最优的。它是递归算法的一个很好的实例。
归并排序的基本操作是合并两个已排序的表。因为这两个表示已经排序好的,所以若将输出放到第三个表中,则该算法可以通过对输入数据一趟排序来完成。基本的合并算法是取两个输入数组A和B,一个输出数组C,以及三个计数器Actr、Bctr、Cctr,它们初始置于对应数组的开始端。A[ctr]和B[ctr]中的较小者被拷贝到C中的下一个位置,相关的计数器向前推进一步。当两个输入表中有一个用完的时候,则将另一个表中剩余部分都拷贝到C中。
- 归并排序是一种稳定的排序。它的时间复杂度为O(N*logN)
7.6 快速排序
快速排序是实践中的一种快速的排序算法,在C++和Java基本类型中的排序中特别有用。它的平均时间复杂度是O(N*logN)。该算法之所以特别快,主要是由于非常精炼和高度优化的内部循环。它的最坏的情形时间复杂度为O(N^2)
基本思想:随便选取一项,然后形成三个组:小于被选项的一组,等于被选项的一组,大于被选项的一组。递归地对第一和第三组的排序,然后把三组接龙。根据递归地基本原理,结果保证是对原始列表的一个有序排列。
- 归并排序是一种不稳定的排序。它的时间复杂度为O(N*logN)
7.7 线性时间的排序: 桶排序和基数排序
7.7.1 桶排序
任何算法首先始于思想(逻辑),只有思想(逻辑)是对的,才需要考虑优化算法的时间消耗和内存消耗。所谓“桶排序”,即把待排序数列装进一个形如桶的数据结构中,这里的桶中只保存桶中有多少个数据,并不保存实际的数值(其实是保存了的,只是比较巧妙)。上面已经说过,桶排序需要知道一些额外的关于待排序数列的信息,这个信息就是待排序数组的最大值,因为这决定了桶结构的大小。
-
构建桶。待排序数列最大值为M,以数组Bucket[M]作为桶结构,初始化桶结构所有元素为0,即初始时每个桶中保存的数据为0个;
-
扫描待排序数组。依次扫描待排序数组a[N],依次Hash(散列)待排序数组中每个元素到桶结构中,这里的Hash函数是Hash(x) = a[i],一旦某个元素Hash到某一个桶中,则该桶保存的数据个数+1;(仔细体会这个过程,这里Hash的作用时把a[i]与桶结构数组的下标关联)
-
扫描桶结构数组。依次扫描桶结构,如果桶结构中某一元素不等于0,则表示该桶中至少保存有一个待排序数组中的数值,那这个待排序数组中的数值是多少呢?根据第(2)步中的Hash过程,这个数值就是桶结构对应的下标值,即只要桶结构该元素不等于0,就依次打印桶结构对应位置的下标,所得结果就是排序后结果。
如待排序数组时:4,1,2,56,1,20,3,48,50,48 这里共10个数,最大值M=56,根据桶排序思想,桶排序流程如下:
(1)构建桶

(2)扫描待排序数组,进行Hash操作

(3)扫描桶结构数组,依次打印下标结果为:1,1,2,3,4,20,48,48,50,56。 排序完成,具体代码如下:
void BucketSort(int *a, const int N, const int M)
{
//构建桶
int *bucket = new int[M];
for(int i=0;i<M;i++)
bucket[i] = 0;
//依次扫描待排序数组,Hash操作
for(int i=0;i<N;i++)
bucket[ a[i] ] += 1;
//依次扫描桶结构,打印下标
for(int i=0;i<M;i++)
{
while(bucket[i] != 0)
{
cout << i << " ";
--bucket[i];
}
}
7.7.2 基数排序
了解了桶排序,有没有什么想法?首先它的时间复杂度是多少?O(M+N),主要体现在扫描桶结构的过程中,那么它的空间复杂度又是多少呢?是O(M)。回过头来想一想,你排序10个元素,用了56个内存空间,那要是还是刚刚那个数列,只是最大值变了,变为999,那么你的空间复杂度变为1000,也就是说对10个数进行排序,用了1000个额外空间,这未免也太奢侈了吧,为了解决这个问题,就有了基数排序(其实基数排序的原理在很久以前就有了)。
怎么解决呢?那就是用多趟桶排序,每趟只排序所有数列中数值中的某一位,如个位、十位、百位等,同理,基数排序也需要知道待排序数列的额外信息,但不是最大值本身,只是最大值的位数P,P就是桶排序的趟数。
如何进行多趟排序呢?如果从最低位(个位)开始,每进行一趟桶排序,完成之后需要先收集这一趟的排序结果,作为下一趟排序的输入,所以整个基数排序是一个分配和收集循环的过程。这并没有比桶排序多出多少工作量,只有两个方面:(1)基数排序需要多趟桶排序;(2)每一趟桶排序之后需要收集当前的排序结果,作为下一趟排序的输入。对于第一点,可以用用for循环跟踪P实现多趟排序控制,对于第二点,难点在于怎么收集当前排序结果?用什么结构来收集?答案是用二维数组收集,为什么是二维数组,看看下面的例子:
如果待排序数组为:64, 8, 216, 512, 27, 729, 0, 1, 342, 125,最大数有3位,则需要3趟桶排序,则第一趟(按个位数值排序)排序结果为:
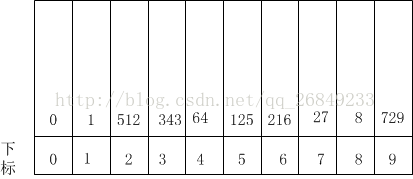
收集第一趟排序结果为:0,1,512,343,64,125,216,27,8,729,收集原则为从下到上,依次收集每个桶中的元素;
第二趟排序(按十位数值排序)结果为:
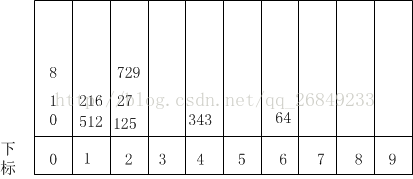
根据收集原则,第二次桶排序结果为:0,1,8,512,216,125,27,729,343,64,以该数列为基础,进行第三趟桶排序(按百位数值排序),结果如下:

再收集桶排序结果为:0,1,8,27,64,125,216,343,512,729.由于这是最后一趟桶排序,则所得结果即为最后排序结果。
7.8 外部排序
岂止为今,我们讲解的所有算法都需要将输入数据装入内存。然而,存在一些应用程序它们的输入量太大装入不进内存。所以接下来我们讲解的就是外部排序,它就是设计用来处理数据量很大的输入数据。
7.8.1 为什么需要外部排序
大部分内存排序算法都用到内存可直接寻址的事实。希尔排序用一个时间单位比较a[i]和a[i-hk]。堆排序用一个时间单位比较元素a[i]和a[i*2+1]。使用三数中值分割法的快速排序以常数个时间单位比较a[left]、a[center]、a[right]。如果输入数据在磁盘上,由于转动磁盘和移动磁盘所需要的延迟,仍然存在实际上的效率损失。