MapReduce深度分析
MapReduce总结构分析
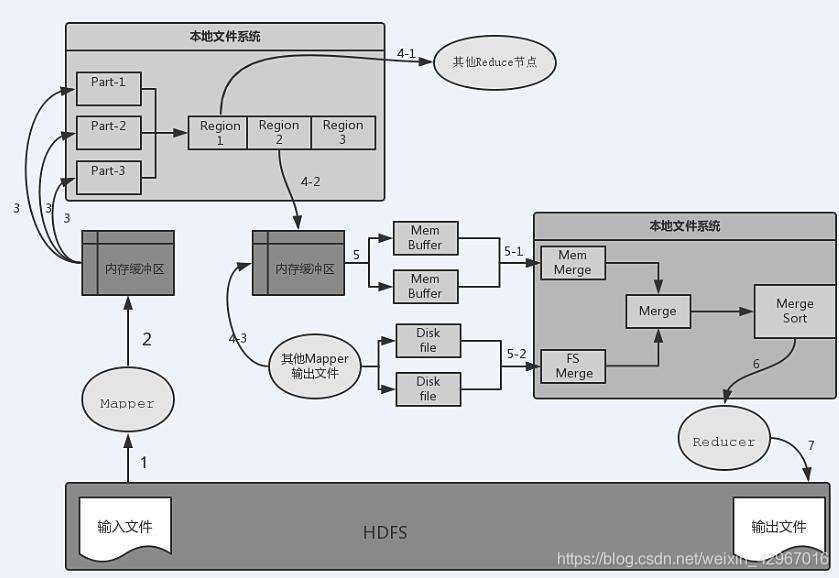
数据流向分析
-
1)从HDFS到Mpper节点输入文件。
-
2)Mapper输出到内存缓冲区。Mapper的输出并不是直接写入本地文件系统,而是先写入内存缓冲区。
-
3)当缓冲区达到一定的阈值时就将缓冲区中的数据以临时文件的形式写入本地磁盘。默认的缓冲区大小是100MB,溢写比例默认是0.8 (可通过spill.percent参数来调节)
当达到阈值时,溢写线程就会启动并锁定这80MB内存执行溢写过程,这一过程称为spill。溢写线程启动的同时还会对这80MB的内存数据依据key的序列化字节做排序。当整个map任务结束后,会对这个map任务产生的所有临时文件进行合并,并产生最终的输出文件。
需要注意:在写入内存缓冲区的同时执行Partition分区。
如果用户作业设置了Combiner,那么在溢写到磁盘之前会对Map输出的键值对调用Combiner归约,这样可以减少溢写到本地磁盘文件的数据量。
-
4)从Mapper端的本地文件系统流入Reduce端,也就是 Reduce中的Shuffle阶段 分三种情况:
- 多个Reduce,需要将Mapper输出中的分区Region文件远程复制到相应的Reduce节点,如4-1
- Mapper节点所在机器有Reduce槽位,则会直接写入本机Reduce缓冲区,如4-2
- 本机的Reduce还会接受其他Mapper输出的分区Region文件,如4-3
-
5)从Reduce端内存缓冲区流向本地磁盘的过程就是Reduce中Merge和Sort阶段。Merge分为内存文件合并和磁盘文件合并,同时还会以key为键排序,最终生成已经对相同key的value进行聚集并排序好的输出文件。
-
6)流向Reduce函数进行归约处理
-
7)写入HDFS中,生成输出文件。
处理过程分析
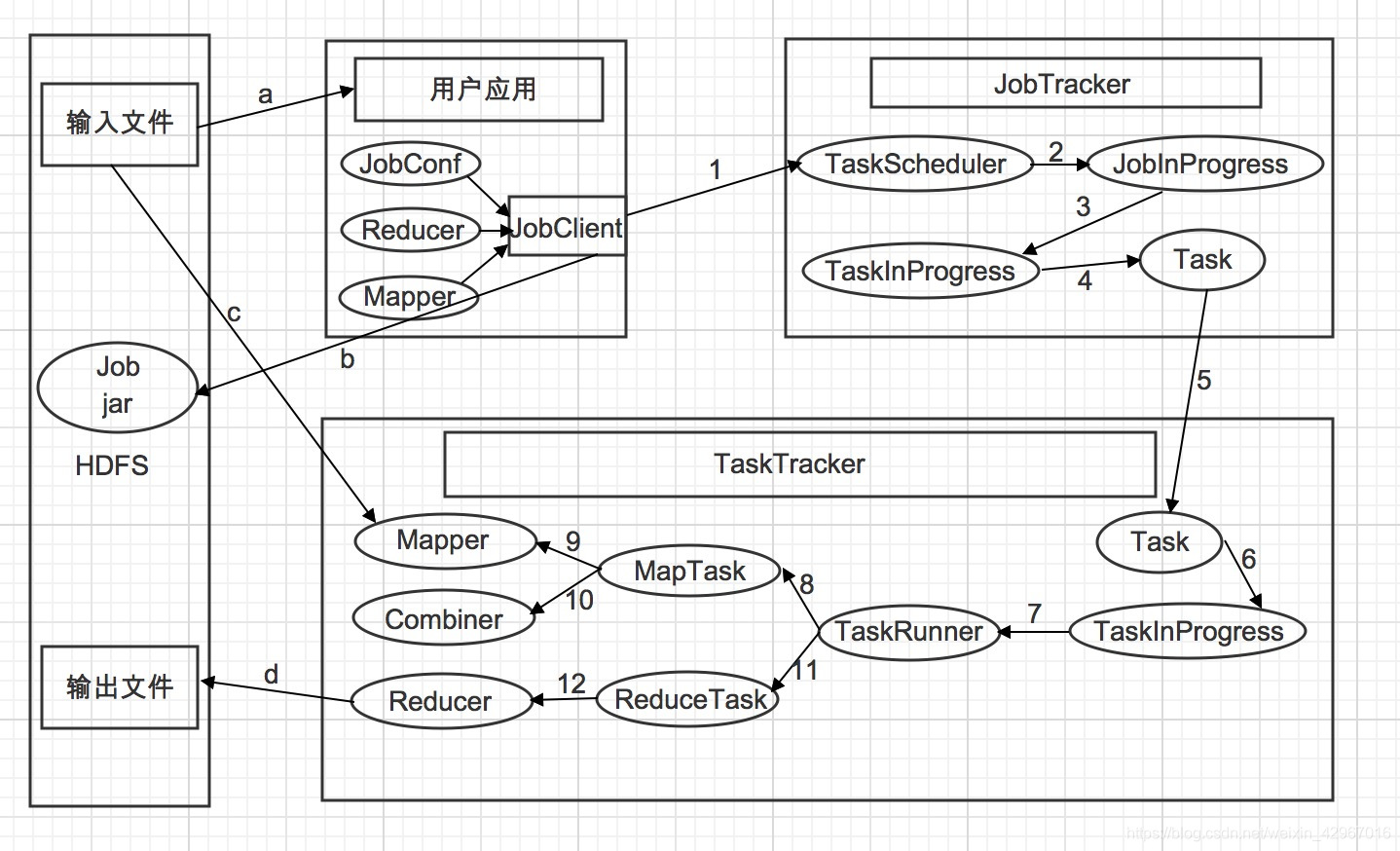
- 1)用户应用通过JobClient类提交到JobTracker,在JobClient会将Mapper类,Reducer类以及配置JobConf打包成一个JAR文件并保存在HDFS中(如b),JobClient在提交作业的同时会把打包的作业JAR文件的路径一起提交到JobTracker的master服务,也就是提交给作业调度器。
- 2)提交Job后,JobTracker会创建一个JobInProgress来跟踪和调度这个作业,并将其添加到调度器的作业队列中。
- 3)JobInProgress根据JAR文件中定义的输入数据集创建相应数量的TaskInProgress用于监控和调度MapTask,同时创建指定数目的TaskInProgress用于监控和调度ReduceTask,默认为一个ReduceTask。
- 4)通过TaskInProgress来启动作业。
- 5)这时会把Task对象(MapTask和ReduceTask)序列化写入相应的TaskTracker服务中。
- 6)TaskTracker收到后创建对应的TaskInProgress(不是JobTracker中的,但作用是类似的)用于监控和调度运行该Task。
- 7)启动具体的Task进程,TaskTracker通过TaskRunner对象来运行具体的Task。
- 8)TaskRunner自动装载用户作业JAR文件,并设置好环境变量后启动一个独立的java进程来执行Task,TaskRunner会首先调用MapTask。
- 9)MapTask先调用Mapper,根据用户作业JAR中定义的输入数据集<key1,value1>键值对读入,处理完成生成临时的<key2,value2>键值对。
- 10)如果用户定义了Combiner,那么MapTask会在Mapper完成后调用Combiner,并将相同key值做归约处理,以减少Map输出的键值对集合。
- 11)在MapTask任务完成后,TaskRunner紧接着调用ReduceTask进程来启动Reducer。需要注意的是MapTask和ReduceTask 不一定运行在同一个TaskTracker节点中。
- 12)ReduceTask调用Reducer类处理Mapper的输出结果。Reducer生成最终结果<key3,value3>键值对,并根据用户指定的输出类型写入HDFS中。
各阶段分析
MapTask
MapTask的总逻辑流程,包括以下几个阶段:
- 1)Read阶段
通过RecordReader对象,对HDFS上的文件进行split切分,输出<key,value>键值对。 - 2)Map阶段
对输入的键值对调用用户编写的Map函数进行处理,输出<key,value>键值对 - 3)Collector和Partitioner阶段
收集Mapper输出,在OutputCollector函数内部对键值对进行Partitioner分区,以便确定相应的Reducer处理,这个阶段将最终的键值对集合输出到内存缓冲区。 - 4)Spill阶段
包含Sort和Combiner阶段,当内存缓冲区达到阈值后写入本地磁盘,在这个阶段会对Mapper的输出键值对进行排序,如果设置了Combiner会执行Combiner函数。 - 5)Merge阶段
对Spill阶段在本地磁盘生成的小文件进行多次合并,最终生成一个大文件。
(3),(4),(5)也称Map端的Shuffle
Read阶段
//创建InputFormat 对象
InputFormat<INKEY, INVALUE> inputFormat = (InputFormat)ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
//得到用户指定的InputFormatClass,创建InputFormat对象实例
//InputFormat对象会提供getSplit()方法,通过该方法将输入文件切分成多个逻辑InputSplit实例并返回
//---------------------------------------
//重建InputSplit对象
org.apache.hadoop.mapreduce.InputSplit split = null;
//创建一个InputSplit对象,用于对文件进行数据块的逻辑切分
split = (org.apache.hadoop.mapreduce.InputSplit)this.getSplitDetails(new Path(splitIndex.getSplitLocation()), splitIndex.getStartOffset());
//每一个InputSplit实例就由对应的一个Mapper来处理
//--------------------------------------
//创建RecordReader对象
LOG.info("Processing split: " + split);
org.apache.hadoop.mapreduce.RecordReader<INKEY, INVALUE> input = new MapTask.NewTrackingRecordReader(split, inputFormat, reporter, taskContext);
//RecordReader对象会把InputSplit提供的输入文件转化为Mapper所需要的keys/values键值对集合形式
Map阶段
- Mapper类中有setup(),map(),cleanup(),run()四个重要方法
一般默认map()是需要用户重写的函数。
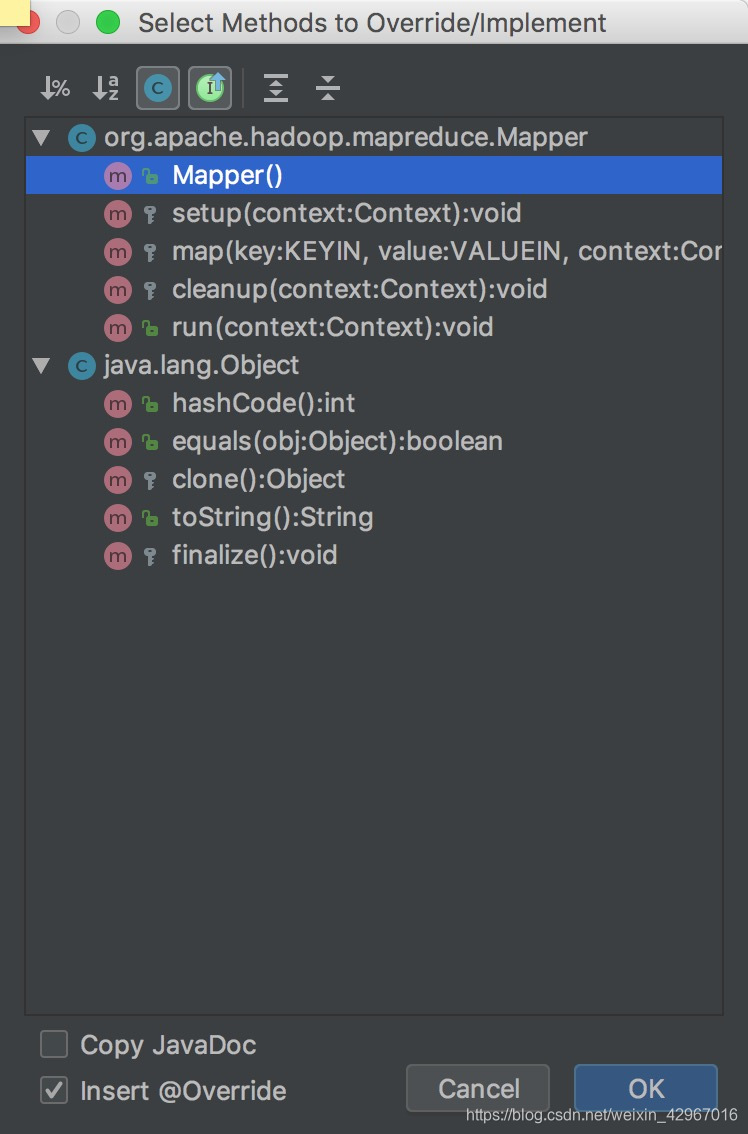
- 下面是run()方法的源代码
public void run(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
//传入Context对象,然后依次执行setup()->map()->cleanup()
this.setup(context);
try {
while(context.nextKeyValue()) {
this.map(context.getCurrentKey(), context.getCurrentValue(), context);
//得到<key,value>键值对,根据用户的Map操作逻辑进行处理,并调用write()输出
}
} finally {
this.cleanup(context);
}
}
Collector和Partitioner阶段
-
map()函数处理完成先写入缓冲区,被Collector对象收集。
context.write(K,V) -> Partitioner<K,V>()-> collector.collect(K,V,partition)
partition是对应的Reduce分区号,是Partitioner的返回值,也就是应该传输到哪个Reduce节点处理的。
这里,以Reduce数目大于0的情况为例分析。
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext, JobConf
job, TaskUmbilicalProtocol umbilical, TaskReport report
) throws IOException, ClassCastException{
colector = new MapTask.MapOutputBuffer<K,V>(umbilical,job,reporter);
//写入内存缓冲区
partitions = jobContext.getNumReduceTasks();
//得到Reduce数目
if (partition > 0){
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
//默认的Partitioner是HashPartitioner ReflectionUtils.newInstance(jobContext.getPartitionerClass(),job);
//通过反射得到具体的Partitioner实例对象
} else {
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition (K key, V value, int numPartitions){
return -1;
}
}
}
}
在得到键值对的Reduce分区号后,通过调用NewOutputCollector收集器类的write()方法进行collect操作。
public void write (K key, V value) throws IOException, InterruptedException {
collector.collect(key, value, partitioner.getPartition(key, value, partitions));
}
Spill阶段
-
Spill阶段有两个重要的逻辑,Sort和Combiner(如果用户设置了Combiner)。
-
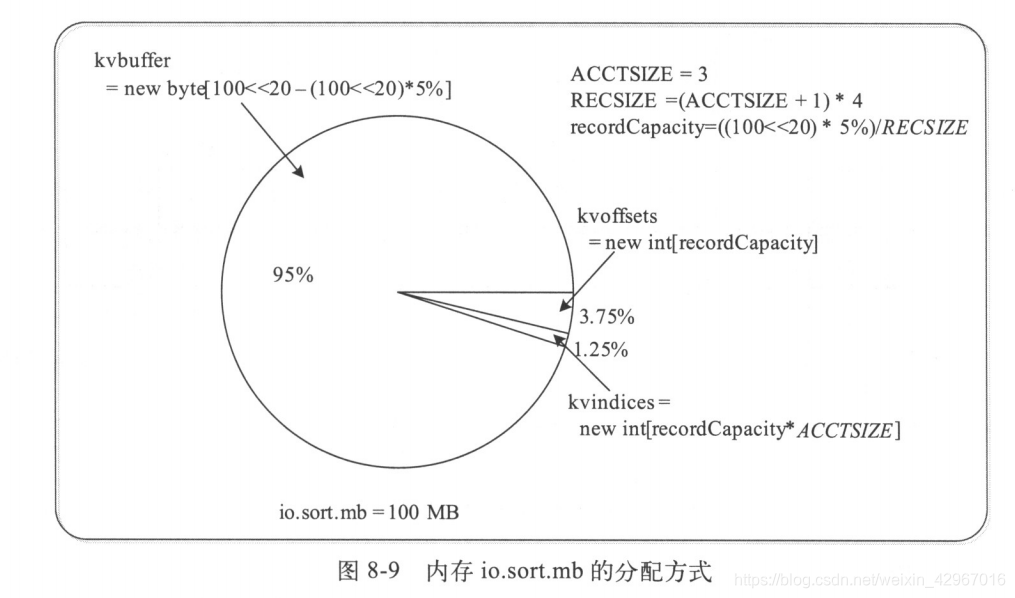
首先介绍一个缓冲区。如图所示,真正在内存中的是一个环形缓冲区。
| kvoffsets | int[]类型 | <key,value>偏移量数组,就是其在kvindices中的偏移量 |
|---|---|---|
| kvindices | int[]类型 | <key,value>键值对索引,就是键值对在kvbuffer中的起始位置 |
| kvbuffer | byte[]类型 | 记录存储数组,真正存储<key,value>键值对的内存缓冲区 |
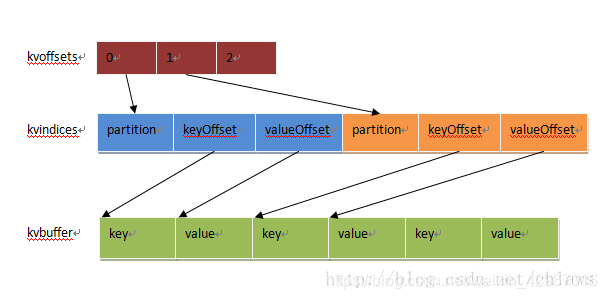
(keyOffset代表key的偏移量,valueOffset代表value的偏移量)
- 具体sortAndSpill过程如下:
-
先创建Spill文件
-
根据partition分区号对<key,value>键值对进行排序,也就是Map端的sort阶段。具体使用的是快速排序算法。
-
循环依次将每一个partition写入磁盘文件
1)如果有combiner,则先combine对同一partition中输出的<key,value>简直对进行归约操作,写入磁盘文件
2)如果没有combiner,则直接写入磁盘。
这一过程会把Spill的数据保存在spill.out格式文件中。
-
生成索引文件,格式为spill.out.index 。内容实质就是kvindices的内容。
-
Merge阶段
- MapTask最终将Spill阶段后生成的临时文件经过多次合并成一个大的输出文件。
(spill.out和spill.out.index文件)
ReduceTask
ReduceTask的总逻辑流程,包括以下几个阶段:
- 1)Shuffle阶段
这个阶段就是Reduce中的Copy阶段,运行Reducer的TaskTracker需要从各个Mapper节点远程复制属于自己处理的一段数据。 - 2)Merge阶段
由于执行Shuffle阶段时会从各个Mapper节点复制很多同一partition段的数据,因此需要进行多次合并,以防止ReduceTask节点上内存使用过多或小文件过多。 - 3)Sort阶段
虽然每个Mapper的输出是按照key排序好的,但是经过Shuffle和Merge阶段后并不是统一有序的,因此还需要在Reduce端进行多轮归并排序。 - 4)Reduce阶段
Reduce的输入要求是按照key排序的,因此只有在Sort阶段执行完成之后才可以对数据调用用户编写的Reduce类进行归约处理。
shuffle阶段
又称copy阶段。Reduce任务拥有多个复制线程,可以并行获得Map输出。Map任务可能会在不同时间内完成,只要其中一个任务完成了,ReduceTask任务就开始复制它的输出。
Merge阶段
分为基于内存的合并和基于磁盘的合并。
Sort阶段
由于每个Mapper复制的输出数据是局部排序的,因此Merge的同时还会经过多次归并排序最终生成整体按照key有序的结果数据。
实质上,Shuffle,Merge,Sort阶段基本是同时执行的
Reduce阶段
- Reducer类中有setup(),reduce(),cleanup(),run()的四个核心方法,其中setup()和cleanup()与Mapper的类似。
默认reduce()函数是需要用户重写的方法。
- run()方法的实现如下:
public void run (Context context) throws IOException, InterruptedException {
//传入context对象,依次执行setup(),reduce(),cleanup()函数
setup(context);
while(context.nextKey()){
reduce(context.getCurrentKey(), context.getValues (), context);
//获得key和value, 然后对相同key下的所有value依照用户的reduce()函数逻辑进行归约处理,调用write()进行输出。
//需要注意Reduce的输出是直接写入HDFS进行持久化存储的,就是输出目录中可见的的文件
}
cleanup(context);
}