WebMagic爬图片,简单
jar包等就不导了,直接上代码。
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @author ZFH
* @version 创建时间:2018年11月17日 上午8:34:55
*/
/**
* @author ZFH
* @version 创建时间:2018年11月17日 上午8:34:55
*/
public class WebmagicUtilP implements PageProcessor{
/**
* 爬取的列表页,页数。
*/
/**
* 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
*/
private Site site = Site.me().setSleepTime(1000).setRetryTimes(3);
/**
* 爬取图片
*/
int j=1;
public void process(Page page) {
//获取图片
while(page.getHtml().xpath("//span[@class=\"RichText ztext CopyrightRichText-richText\"]/figure["+j+"]/img").css("img","data-original").toString()!=null) {
String string1 = page.getHtml().xpath("//span[@class=\"RichText ztext CopyrightRichText-richText\"]/figure["+j+"]/img").css("img","data-original").toString();
j++;
System.out.println(string1);
}
}
/**
* 设置属性
*/
public Site getSite() {
return site;
}
public static void main(String[] args) {
System.out.println("开始爬取...");
String url = "https://www.zhihu.com/question/29784516/answer/54897151";
//启动爬虫
Spider.create(new WebmagicUtilP())
//添加初始化的URL
.addUrl(url)
.thread(1)
//运行
.run();
System.out.println("爬取结束");
}
}
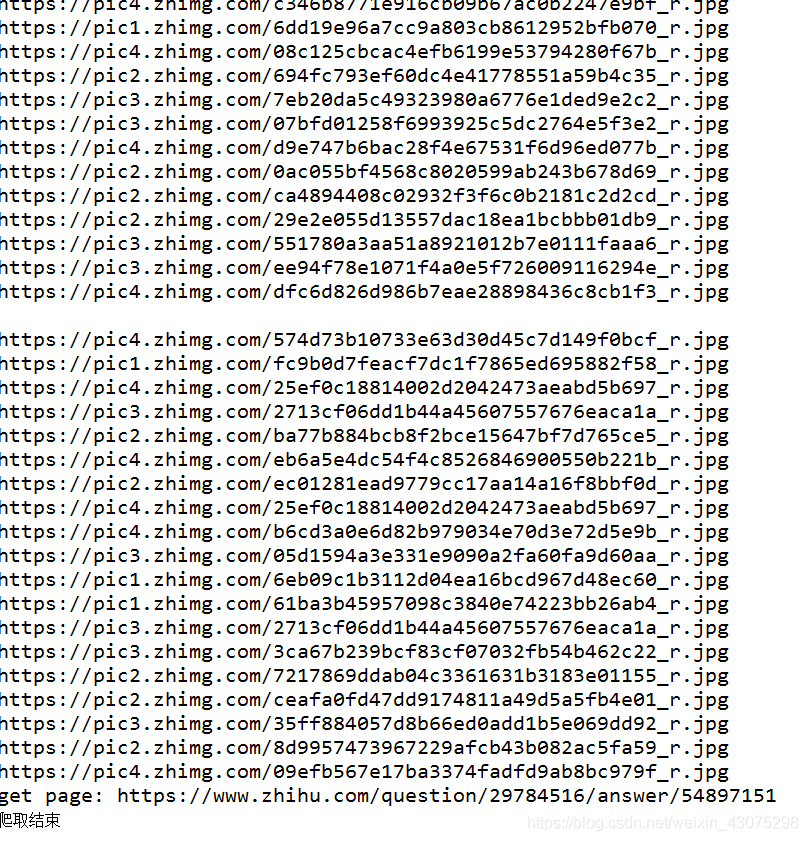
图片:

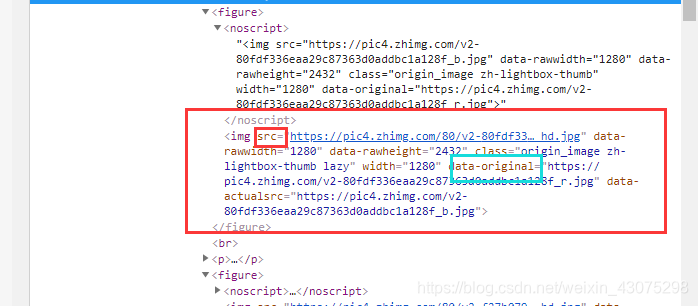
结果如下:
有人肯定会疑惑,为什么不取img的src呢?
因为img的src属性获得不了,是这样的:

暂时先这样弄,我再研究一下如何下载这些图片。。。