一 K-均值聚类(K-means)概述
-
聚类
“类”指的是具有相似性的集合。聚类是指将数据集划分为若干类,使得类内之间的数据最为相似,各类之间的数据相似度差别尽可能大。聚类分析就是以相似性为基础,对数据集进行聚类划分,属于无监督学习。
-
无监督学习和监督学习
上一篇对KNN进行了验证,和KNN所不同,K-均值聚类属于无监督学习。那么监督学习和无监督学习的区别在哪儿呢?监督学习知道从对象(数据)中学习什么,而无监督学习无需知道所要搜寻的目标,它是根据算法得到数据的共同特征。比如用分类和聚类来说,分类事先就知道所要得到的类别,而聚类则不一样,只是以相似度为基础,将对象分得不同的簇。
-
K-means
k-means算法是一种简单的迭代型聚类算法,采用距离作为相似性指标,从而发现给定数据集中的K个类,且每个类的中心是根据类中所有值的均值得到,每个类用聚类中心来描述。对于给定的一个包含n个d维数据点的数据集X以及要分得的类别K,选取欧式距离作为相似度指标,聚类目标是使得各类的聚类平方和最小,即最小化:
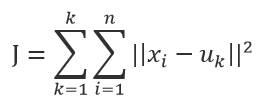
结合最小二乘法和拉格朗日原理,聚类中心为对应类别中各数据点的平均值,同时为了使得算法收敛,在迭代过程中,应使最终的聚类中心尽可能的不变。
- 算法流程
K-means是一个反复迭代的过程,算法分为四个步骤:
1) 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心;
2) 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类;
3) 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值;
4) 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)。
用以下例子加以说明:

图1:给定一个数据集;
图2:根据K = 5初始化聚类中心,保证 聚类中心处于数据空间内;
图3:根据计算类内对象和聚类中心之间的相似度指标,将数据进行划分;
图4:将类内之间数据的均值作为聚类中心,更新聚类中心。
最后判断算法结束与否即可,目的是为了保证算法的收敛。
二 python实现
首先,需要说明的是,我采用的是python2.7,直接上代码:
#k-means算法的实现
#-*-coding:utf-8 -*-
from numpy import *
from math import sqrt
import sys
sys.path.append("C:/Users/Administrator/Desktop/k-means的python实现")
def loadData(fileName):
data = []
fr = open(fileName)
for line in fr.readlines():
curline = line.strip().split('\t')
frline = map(float,curline)
data.append(frline)
return data
'''
#test
a = mat(loadData("C:/Users/Administrator/Desktop/k-means/testSet.txt"))
print a
'''
#计算欧氏距离
def distElud(vecA,vecB):
return sqrt(sum(power((vecA - vecB),2)))
#初始化聚类中心
def randCent(dataSet,k):
n = shape(dataSet)[1]
center = mat(zeros((k,n)))
for j in range(n):
rangeJ = float(max(dataSet[:,j]) - min(dataSet[:,j]))
center[:,j] = min(dataSet[:,j]) + rangeJ * random.rand(k,1)
return center
'''
#test
a = mat(loadData("C:/Users/Administrator/Desktop/k-means/testSet.txt"))
n = 3
b = randCent(a,3)
print b
'''
def kMeans(dataSet,k,dist = distElud,createCent = randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
center = createCent(dataSet,k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):
minDist = inf
minIndex = -1
for j in range(k):
distJI = dist(dataSet[i,:],center[j,:])
if distJI < minDist:
minDist = distJI
minIndex = j
if clusterAssment[i,0] != minIndex:#判断是否收敛
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist ** 2
print center
for cent in range(k):#更新聚类中心
dataCent = dataSet[nonzero(clusterAssment[:,0].A == cent)[0]]
center[cent,:] = mean(dataCent,axis = 0)#axis是普通的将每一列相加,而axis=1表示的是将向量的每一行进行相加
return center,clusterAssment
'''
#test
dataSet = mat(loadData("C:/Users/Administrator/Desktop/k-means/testSet.txt"))
k = 4
a = kMeans(dataSet,k)
print a
'''
最终的结果如下图5和图6:

