《算法导论》——计数排序
-
计数排序是一个非基于比较的排序算法,该算法于1954年由 Harold H. Seward 提出。它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法。当然这是一种牺牲空间换取时间的做法,而且当O(k)>O(nlog(n))的时候其效率反而不如基于比较的排序(基于比较的排序的时间复杂度在理论上的下限是O(nlog(n)), 如归并排序,堆排序)。
-
计数排序的基本思想为一组数在排序之前先统计这组数中其他数小于这个数的个数,则可以确定这个数的位置。例如要排序的数为 7 4 2 1 5 3 1 5;则比7小的有7个数,所有7应该在排序好的数列的第八位,同理3在第四位,对于重复的数字,1在1位和2位(暂且认为第一个1比第二个1小),5和1一样位于6位和7位。
-
计数排序的实现办法:
首先需要三个数组,第一个数组记录A要排序的数列大小为n,第二个数组B要记录比某个数小的其他数字的个数所以第二个数组的大小应当为K(数列中最大数的大小),第三个数组C为记录排序好了的数列的数组,大小应当为n。接着需要确定数组最大值并确定B数组的大小。并对每个数由小到大的记录数列中每个数的出现次数。因为是有小到大通过出现次数可以通过前面的所有数的出现次数来确定比这个数小的数的个数,从而确定其位置。对于重复的数,每排好一个数则对其位置数进行减减操作,以此对完成其余相同的数字进行排位。
计数排序伪代码
A为原始数组,B为输出数组,C为临时数组。2~3行初始化临时数组.4-5行对A数组中的数出现的次数进行统计,此时C中的值为索引在A中出现的次数。7-8行通过相加计算得到对每个i=0…K,有多少个元素小于等于i。10-11行将A中的元素放在B中对应的位置上。因为共有C[A[j]]个元素小于或等于A[j],所有的元素可能都不是互异的,所以放入正确的位置后要减一。
计数排序流程图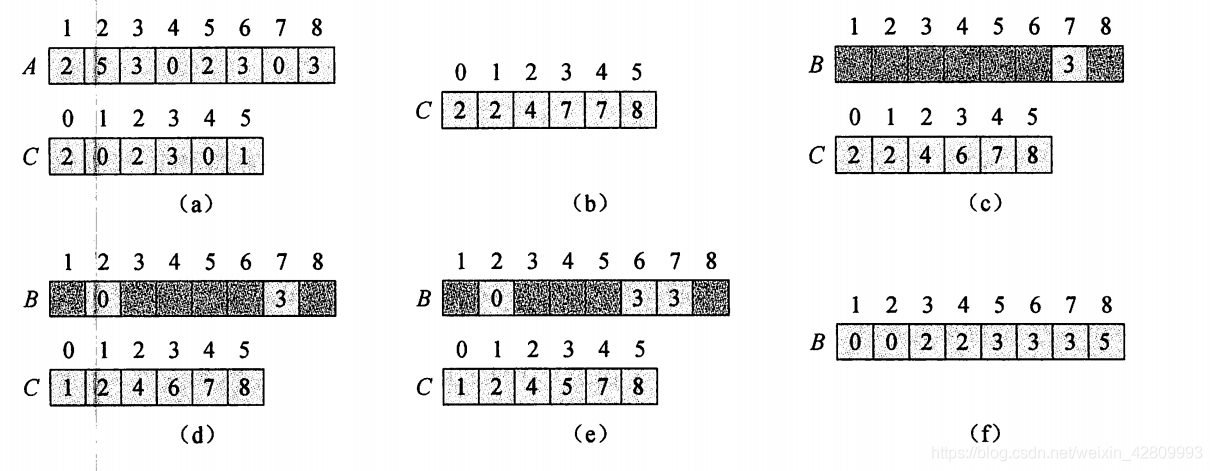
计数排序C++代码
#include "iostream"
using namespace std;
void Counting_Sort(int a[], int len,int* b, int k)
{
int* temp = new int[k+1];//最大值为K,那么temp中数组最大下标应为K,个数由K+1个
memset(temp, 0, sizeof(int)*(k+1));
for (int i = 0; i < len; i++)//统计数组a中各元素出现的次数
{
temp[a[i]]++;
}
for (int j = 1; j < k+1; j++)//temp中每个位置的值为数组中小于等于当前位置索引的个数
{
temp[j] = temp[j] + temp[j - 1];
}
for (int m = 0; m < len; m++)
{
b[temp[a[m]]-1] = a[m]; //例如,放在b中的第4个位置,那么在b中的索引应为b[3]
temp[a[m]] --;
}
delete[] temp;
}
void main()
{
int a[] = { 2,6,1,7,3,2,0 };
int max = a[0];
int length = sizeof(a) / sizeof(a[0]);
int *des = new int[length];
memset(des, 0, sizeof(int)*length);
for (int i = 1; i < length; i++)//找到最大值
{
if (max < a[i])
max = a[i];
}
Counting_Sort(a, length,des, max);
for (int i = 0; i < length; i++)
cout << des[i];
cout << endl;
delete [] des;
system("pause");
}