最近在做一个基于支持向量机机器学习的项目, 打算用matlab构建分类器和回归model.在R2014a版本中,在stats工具箱自带有三个SVM函数,svmclassify,svmsmoset,svmtrain.而台湾的林智仁先生及其实验室在此基础上开发出了基于JAVA,matlab,python多语言平台的Libsvm toobox.为广大人工智能研究者提供了方便的功能接口。帖子最后贴上下载链接,请到林先生个人主页上下载最新版本Libsvm 3.22
SVM(Support Vector Machine,支持向量机)是一种有监督的机器学习方法,可以学习不同类别的已知样本的特点,进而对未知的样本进行预测。
SVM本质上是一个二分类的算法,对于n维空间的输入样本,它寻找一个最优的分类超平面,使得两类样本在这个超平面下可以获得最好的分类效果。这个最优可以用两类样本中与这个超平面距离最近的点的距离来衡量,称为边缘距离,边缘距离越大,两类样本分得越开,SVM就是寻找最大边缘距离的超平面,这个可以通过求解一个以超平面参数为求解变量的优化问题获得解决。给定适当的约束条件,这是一个二次优化问题,可以通过用KKT条件求解对偶问题等方法进行求解。
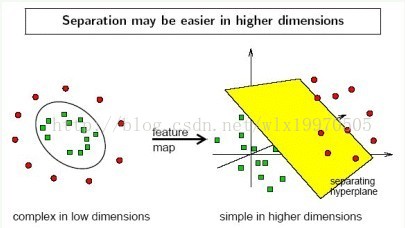
对于不是线性可分的问题,就不能通过寻找最优分类超平面进行分类,SVM这时通过把n维空间的样本映射到更高维的空间中,使得在高维的空间上样本是线性可分的。在实际的算法中,SVM不需要真正地进行样本点的映射,因为算法中涉及到的高维空间的计算总是以内积的形式出现,而高维空间的内积可以通过在原本n维空间中求内积然后再进行一个变换得到,这里计算两个向量在隐式地映射到高维空间的内积的函数就叫做核函数。SVM根据问题性质和数据规模的不同可以选择不同的核函数。
虽然SVM本质上是二分类的分类器,但是可以扩展成多分类的分类器,常见的方法有一对多(one-versus-rest)和一对一(one-versus-one)。在一对多方法中,训练时依次把k类样本中的某个类别归为一类,其它剩下的归为另一类,使用二分类的SVM训练处一个二分类器,最后把得到的k个二分类器组成k分类器。对未知样本分类时,分别用这k个二分类器进行分类,将分类结果中出现最多的那个类别作为最终的分类结果。而一对一方法中,训练时对于任意两类样本都会训练一个二分类器,最终得到k*(k-1)/2个二分类器,共同组成k分类器。对未知样本分类时,使用所有的k*(k-1)/2个分类器进行分类,将出现最多的那个类别作为该样本最终的分类结果。
二,自带SVM的分类测试
注:核函数可以自行选择最优情况
function [ classification ] = svm1( )
figure
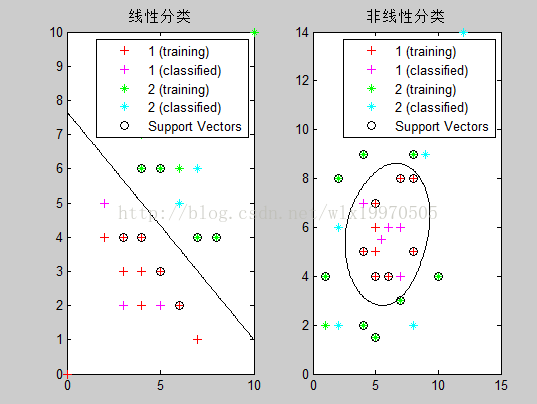
%非线性
subplot(1,2,2);
train1=[5 5;6 4;5 6;5 4;4 5;8 5;8 8;4 5;5 7;7 8;1 2;1 4;4 2;5 1.5;7 3;10 4;4 9;2 8;8 9;8 10]; %训练样本
group1=[1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,2]; %特征学习
test1=[6 6;5.5 5.5;7 6;12 14;7 11;2 2;9 9;8 2;2 6;5 10;4 7;7 4]; %测试集
svmModel = svmtrain(train1,group1,'kernel_function','rbf','showplot',true); %训练模型
classification=svmclassify(svmModel,test1,'Showplot',true); %测试结果
title('非线性分类');
%线性
subplot(1,2,1);
train2=[0 0;2 4;3 3;3 4;4 2;4 4;4 3;5 3;6 2;7 1;2 9;3 8;4 6;4 7;5 6;5 8;6 6;7 4;8 4;10 10];
group2=[1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2,2]';
test2=[3 2;4 8;6 5;7 6;2 5;5 2];
svmModel = svmtrain(train2,group2,'kernel_function','linear','showplot',true);
classification=svmclassify(svmModel,test2,'Showplot',true);
title('线性分类');
end
测试结果如下:
三.Libsvm安装和测试
1. 下载
在LIBSVM的主页上下载最新版本的软件包,并解压到合适目录中。这里建议解压到matlab安装目录的toolbox文件夹下
2. 编译
网上有说64位的matlab不需要编译这一说法,我自己亲自试过,不编译是不行的,即使生成了自带了.mexw64(或.mexw32)的文件也不行
>>mex –setup
然后Matlab会提示你选择编译mex文件的C/C++编译器,就选择一个已安装的编译器,如Microsoft Visual C++ 2010。之后Matlab会提示确认选择的编译器,输入y进行确认。
注:这里有个常见的错误是:
错误使用 mex
未找到支持的编译器或 SDK。有关选项,请访问
http://www.mathworks.com/support/compilers/R2014a/win64。

这其实是因为64位的matlab不带编译器,而电脑又没有安装过任何编译器,2014版本的matlab支持SDK7.1,不过我是安装Visual Studio的,安装的时候勾选相应的编译器即可
>>make
编译成功后,当前目录下会出现若干个后缀为mexw64(64位系统)或mexw32(32位系统)的文件。
3. 修改函数名
编译完成后,在当前目录下回出现svmtrain.mexw64、svmpredict.mexw64(64位系统)或者svmtrain.mexw32、svmpredict.mexw32(32位系统)这两个文件,把文件名svmtrain和svmpredict相应改成libsvmtrain和libsvmpredict。
这是因为高版本的Matlab中自带有SVM的工具箱,而且其函数名字就是svmtrain和svmpredict,和LIBSVM默认的名字一样,在实际使用的时候有时会产生一定的问题,比如想调用LIBSVM的变成了调用Matlab SVM。
也可以不用改名,只要将要使用的函数目录定位到当前文件夹就行了,因为matlab搜索文件的方式是先是当前路径,再从设置的搜索路径由上到下查找。
如果有进行重命名的,以后使用LIBSVM时一律使用libsvmtrain和libsvmpredict这两个名字进行调用。
4. 添加路径
为了以后使用的方便,建议把LIBSVM的编译好的文件所在路径添加到Matlab的搜索路径中。
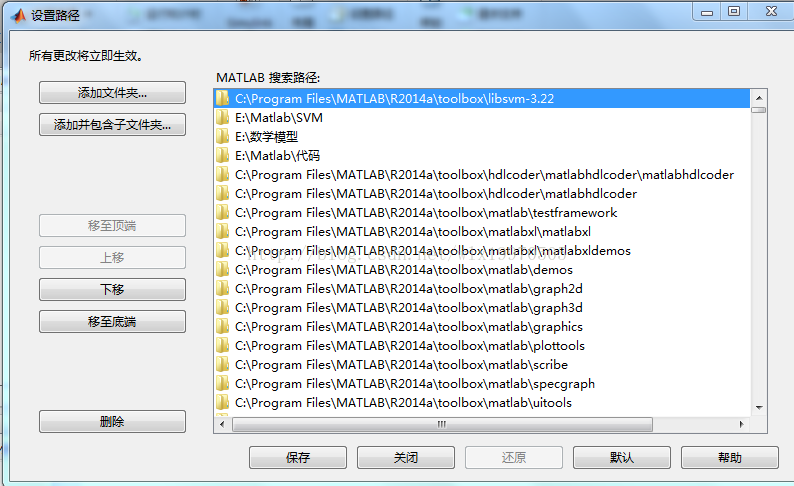
当然也可以把那4个编译好的文件复制到想要的地方,然后再把该路径添加到Matlab的搜索路径中。
二 测试
LIBSVM软件包中自带有测试数据,为软件包根目录下的heart_scale文件,可以用来测试LIBSVM是否安装成功。安装包里的heart_scale不是mat格式,即不是matlab型测试集,这里,大家可以去CSDN下载或者联系我
>> load heart_scale.mat
>> model = svmtrain(heart_scale_label,heart_scale_inst);
optimization finished, #iter = 162
nu = 0.431029
obj = -100.877288, rho = 0.424462
nSV = 132, nBSV = 107
Total nSV = 132
>> [predict_label,accuracy] = svmpredict(heart_scale_label,heart_scale_inst,model);
Accuracy = 86.6667% (234/270) (classification)
如果LIBSVM安装正确的话,会出现以下的运行结果,显示正确率为86.6667%。