学习《scikit-learn机器学习》时的一些实践。
原理见K-means和K-means++的算法原理及sklearn库中参数解释、选择。
sklearn中的KMeans
from sklearn.datasets import make_blobs
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
def show_sample():
"""展示样本点"""
plt.figure(figsize=(6, 4), dpi=100)
plt.xticks([])
plt.yticks([])
plt.scatter(X[:, 0], X[:, 1], s=20, marker='o')
plt.show()
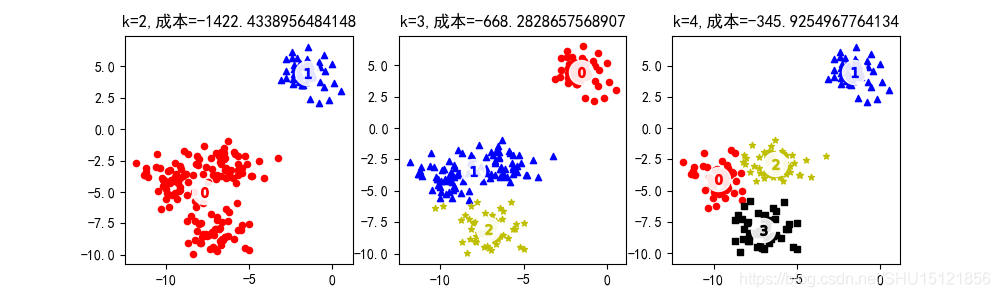
def fit_plot_kmeans_model(k, X):
"""使样本X聚k类,并绘制图像"""
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
# 这里score得到的是一个负数,其绝对值越大表示成本越高
# sklearn中对该成本的计算为:样例到其所属的聚类中心点的距离总和(而不是平均值)
plt.title("k={},成本={}".format(k, kmeans.score(X)))
# 聚类得到的类别标签,这里都用从0开始的自然数表示
labels = kmeans.labels_
assert len(labels) == len(X)
# 聚类中心
centers = kmeans.cluster_centers_
assert len(centers) == k
markers = ['o', '^', '*', 's']
colors = ['r', 'b', 'y', 'k']
# 对每一个类别
for i in range(k):
# 绘制该类对应的样本
cluster = X[labels == i]
plt.scatter(cluster[:, 0], cluster[:, 1], marker=markers[i], s=20, c=colors[i])
# 绘制聚类中心点
plt.scatter(centers[:, 0], centers[:, 1], marker='o', c='white', alpha=0.9, s=300)
# 在中心点大白点(位置cnt)上绘制类别号i
for i, cnt in enumerate(centers):
plt.scatter(cnt[0], cnt[1], marker="$%d$" % i, s=50, c=colors[i])
if __name__ == '__main__':
# 生成标准差为1的200个聚4类的2维样本点,聚类中心随机生成且每个维度都在-10到10的范围,最终将生成的两样本打乱
X, y = make_blobs(n_samples=200, n_features=2, centers=4, cluster_std=1, center_box=(-10.0, 10.0), shuffle=True,
random_state=1)
# 聚类的类别数
n_clusters = [2, 3, 4]
plt.figure(figsize=(10, 3), dpi=100)
# plt.xticks([])
# plt.yticks(())
for i, k in enumerate(n_clusters):
plt.subplot(1, len(n_clusters), i + 1)
fit_plot_kmeans_model(k, X)
plt.show()
k-均值算法做文本聚类
from sklearn.datasets import load_files
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn import metrics
# 读取数据
docs = load_files("E:\Data\code\datasets\clustering\data")
data = docs.data
target_names = docs.target_names
print("summary: {} documents in {} categories.".format(len(data), len(target_names)))
summary: 3949 documents in 4 categories.
# 生成词典并将文档转化为TF-IDF向量
# 在生成词典时,过滤超过max_df比例(或数目)或者min_df比例(或数目)的词,最大保留20000个特征,编码ISO-8859-1
vectorizer = TfidfVectorizer(max_df=0.4, min_df=2, max_features=20000, encoding='latin-1')
X = vectorizer.fit_transform(data)
print("n_samples:{},n_features:{}".format(*X.shape))
print("0号样本中的非零特征数目:", X[0].getnnz())
n_samples:3949,n_features:20000
0号样本中的非零特征数目: 56
k = 4
# 参数n_init即是多次选取不同的初始化聚类中心,而最终输出的是score最大(成本最小)的聚类
# 参数max_iter指定一次KMeans过程中最大的循环次数,即便聚类中心还可以移动,到达这个最大次数也结束
# 参数tol决定中心点移动距离小于多少时认定算法已经收敛
kmeans = KMeans(n_clusters=k, max_iter=100, tol=0.01, verbose=0, n_init=3)
kmeans.fit(X)
print("k={},cost={}".format(k, "%.3f" % kmeans.inertia_))
k=4,cost=3816.220
# 查看1000~1009这10个文档的聚类结果及其本来的文件名,可以看一下目录一样的也就是同一类的
print(kmeans.labels_[1000:1010])
print(docs.filenames[1000:1010])
[1 1 1 2 0 2 2 1 2 2]
[‘E:\Data\code\datasets\clustering\data\sci.crypt\10888-15289’
‘E:\Data\code\datasets\clustering\data\sci.crypt\11490-15880’
‘E:\Data\code\datasets\clustering\data\sci.crypt\11270-15346’
‘E:\Data\code\datasets\clustering\data\sci.electronics\12383-53525’
‘E:\Data\code\datasets\clustering\data\sci.space\13826-60862’
‘E:\Data\code\datasets\clustering\data\sci.electronics\11631-54106’
‘E:\Data\code\datasets\clustering\data\sci.space\14235-61437’
‘E:\Data\code\datasets\clustering\data\sci.crypt\11508-15928’
‘E:\Data\code\datasets\clustering\data\sci.space\13593-60824’
‘E:\Data\code\datasets\clustering\data\sci.electronics\12304-52801’]
# 查看每种类别文档中,影响最大(即那个维度数值最大)的10个单词
# 对得到的每个聚类中心点进行排序得到排序索引,这里"::-1"使其按照从大到小排序
order_centroids = kmeans.cluster_centers_.argsort()[:, ::-1]
# 显然越排在前面的对应的索引值所对应的单词影响越大
# 取出词典中的词
terms = vectorizer.get_feature_names()
# 对每个聚类结果i
for i in range(k):
print("Cluster %d" % i, end='')
# 取出第i行(也就是第i个聚类中心点)前10重要的词的索引
for ind in order_centroids[i, :10]:
# 在词典term中可以按这个索引拿到对应的词
print(" %s" % terms[ind], end='')
print()
Cluster 0 henry toronto zoo spencer hst zoology mission utzoo orbit space
Cluster 1 key clipper chip encryption government keys will escrow we algorithm
Cluster 2 space by any my will know like some nasa we
Cluster 3 my she msg pitt he your has do her gordon
# 评价聚类表现
label_true = docs.target # 标记的类别
label_pred = kmeans.labels_ # 聚类得到的类别
print("齐次性: %.3f" % metrics.homogeneity_score(label_true, label_pred))
print("完整性: %.3f" % metrics.completeness_score(label_true, label_pred))
print("V-measure: %.3f" % metrics.v_measure_score(label_true, label_pred))
print("Adjust Rand Index: %.3f" % metrics.adjusted_rand_score(label_true, label_pred))
print("轮廓系数: %.3f" % metrics.silhouette_score(X, label_pred, sample_size=1000))
齐次性: 0.352
完整性: 0.481
V-measure: 0.406
Adjust Rand Index: 0.250
轮廓系数: 0.005
聚类算法性能评估
聚类因为得到的类别和标注类别未必有什么关系(也许有一定程度的对应关系,如上面的文本聚类和实际标签的比较),不能用分类的MSE损失等方法来对其评估。
而sklearn里聚类模型的score值也没有一个确切的范围,不像分类模型中总是从0到1之间,所以单纯的看这个score值也没有太大用处。
以下方法中,只有轮廓系数是不基于标注标签对聚类性能做评估的方法,其它方法都使用了标注标签。
Adjust Rand Index
该方法可以衡量两个序列相似性,针对两个结构相同的序列其值接近1,主要优点是对类别标签不敏感。
from sklearn import metrics
import numpy as np
# 随机序列
label_true = np.random.randint(1, 4, 6)
label_pred = np.random.randint(1, 4, 6)
print("Adjust Rand Index for 随机序列: %.3f" % metrics.adjusted_rand_score(label_true, label_pred))
Adjust Rand Index for 随机序列: -0.296
# 结构相同,这个例子里能看出"对类别标签不敏感"
label_true = [1, 1, 3, 3, 2, 2]
label_pred = [3, 3, 2, 2, 1, 1]
print("Adjust Rand Index for 结构相同的序列: %.3f" % metrics.adjusted_rand_score(label_true, label_pred))
Adjust Rand Index for 结构相同的序列: 1.000
Homogeneity(齐次性)
Homogeneity表征每个聚类类别中的元素只由同种标注标签的元素组成的程度。
from sklearn import metrics
import numpy as np
label_true = [1, 1, 2, 2]
label_pred = [2, 2, 1, 1]
print("齐次性值 for 结构相同: %.3f" % metrics.homogeneity_score(label_true, label_pred))
齐次性值 for 结构相同: 1.000
label_true = [1, 1, 2, 2]
label_pred = [0, 1, 2, 3]
print("齐次性值 for 每个类别内只由一种原类别元素组成: %.3f" % metrics.homogeneity_score(label_true, label_pred))
齐次性值 for 每个类别内只由一种原类别元素组成: 1.000
label_true = [1, 1, 2, 2]
label_pred = [1, 2, 1, 2]
print("齐次性值 for 每个类别内不由一种原类别元素组成: %.3f" % metrics.homogeneity_score(label_true, label_pred))
齐次性值 for 每个类别内不由一种原类别元素组成: 0.000
label_true = np.random.randint(1, 4, 6)
label_pred = np.random.randint(1, 4, 6)
print("齐次性值 for 随机序列: %.3f" % metrics.homogeneity_score(label_true, label_pred))
齐次性值 for 随机序列: 0.685
Completeness(完整性)
Completeness表征同种标注标签的元素全部分配到同种聚类类别中的程度。
from sklearn import metrics
import numpy as np
label_true = [1, 1, 2, 2]
label_pred = [2, 2, 1, 1]
print("完整性值 for 结构相同: %.3f" % metrics.completeness_score(label_true, label_pred))
完整性值 for 结构相同: 1.000
label_true = [0, 1, 2, 2]
label_pred = [2, 0, 1, 1]
print("完整性值 for 原类别相同的都分到一个聚类中: %.3f" % metrics.completeness_score(label_true, label_pred))
完整性值 for 原类别相同的都分到一个聚类中: 1.000
label_true = [0, 1, 2, 2]
label_pred = [2, 0, 1, 2]
print("完整性值 for 原类别相同的未分到一个聚类中: %.3f" % metrics.completeness_score(label_true, label_pred))
完整性值 for 原类别相同的未分到一个聚类中: 0.667
label_true = np.random.randint(1, 4, 6)
label_pred = np.random.randint(1, 4, 6)
print("完整性值 for 随机序列: %.3f" % metrics.completeness_score(label_true, label_pred))
完整性值 for 随机序列: 0.457
V-measure
V-measure结合了Homogeneity和Completeness这一组互为补充的评价指标。若将聚类结果和标注标签反转,得到的V-measure值是相同的。
from sklearn import metrics
import numpy as np
label_true = [1, 1, 2, 2]
label_pred = [2, 2, 1, 1]
print("V-measure for 结构相同: %.3f" % metrics.v_measure_score(label_true, label_pred))
V-measure for 结构相同: 1.000
label_true = [0, 1, 2, 3]
label_pred = [1, 1, 2, 2]
print("V-measure for 不齐次,但完整: %.3f" % metrics.v_measure_score(label_true, label_pred))
print("V-measure for 齐次,但不完整: %.3f" % metrics.v_measure_score(label_pred, label_true))
V-measure for 不齐次,但完整: 0.667
V-measure for 齐次,但不完整: 0.667
label_true = [1, 1, 2, 2]
label_pred = [1, 2, 1, 2]
print("V-measure for 既不齐次,也不完整: %.3f" % metrics.v_measure_score(label_true, label_pred))
V-measure for 既不齐次,也不完整: 0.000
label_true = np.random.randint(1, 4, 6)
label_pred = np.random.randint(1, 4, 6)
print("V-measure for 随机序列: %.3f" % metrics.v_measure_score(label_true, label_pred))
V-measure for 随机序列: 0.457
轮廓系数
使用metrics.silhouette_score(样本集,聚类标签,)计算。