一、seq2seq架构图
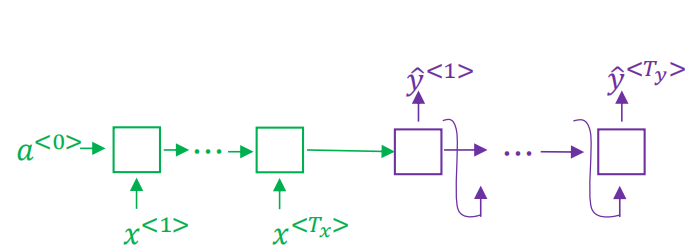
seq2seq模型左边绿色的部分我们称之为encoder,decoder会根据左边的循环输入最终生成一个固定向量作为右侧的输入,右边紫色的部分我们称之为decoder。单看右侧这个结构跟我们之前学习的语言模型非常相似,如下:
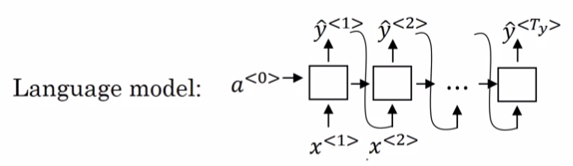
唯一不同的是,语言模型的输入a<0>是一个零向量,而seq2seq模型decoder部分的输入是由encoder编码得到的一个固定向量。所以可以称seq2seq模型为条件语言模型p(y|x)。
语言模型生成的序列y是可以随机生成的,而seq2seq模型用于到机器翻译中,我们是要找到概率最大的序列y,即最可能或者说最好的翻译结果,max p(y|x)。
seq2seq模型如何寻找到最可能的序列y呢?
是不是可以采用贪心算法呢?如果采用贪心算法找的结果不一定是最优的,只能说是其中一个结果。因为贪心算法的思路是先找到第一个最好的y<1>,第一个输出结果y<1>再找到第二个最好的y<2>,以此类推。这种方式的最终结果是每一个元素可能是最优的,但是整个句子却未必是最好的。例如下面的句子:

采用贪心算法,最可能的结果就是第二句,因为如果前两个是Jane is ,第三个最可能的是going,而不是visiting,这是因为is going在英语中大量存在。但是最好的结果却是第一个句子。
二、beam search(集束搜索)