一, 主题式网络爬虫设计方案
1, 主题式网络爬虫的名称
1.1去哪网攻略的爬取
2, 主题式网络爬虫的内容与数据特征分析
2.1爬虫的内容
url: 文章链接,title:标题,describle: 简要描述信息
username: 发布者,label: 发布者的个人标签,date: 出发日期
days: 天数,photo_nums: 拍照数量,people: 出行的类型
trip: 旅行的标签,via_places: 途径,distance: 行程路线
price: 人均消费,view_nums: 观看数,praise_nums: 点赞数
comment_nums: 评论数
2.2 数据特征分析
2.2.1对trip,days和price做一个透视表并可视化
2.2.2对label,peope和price做一个透视表并可视化
3, 主题式网络爬虫设计方案概述(包括实现思路和技术难点)
3.1实现思路
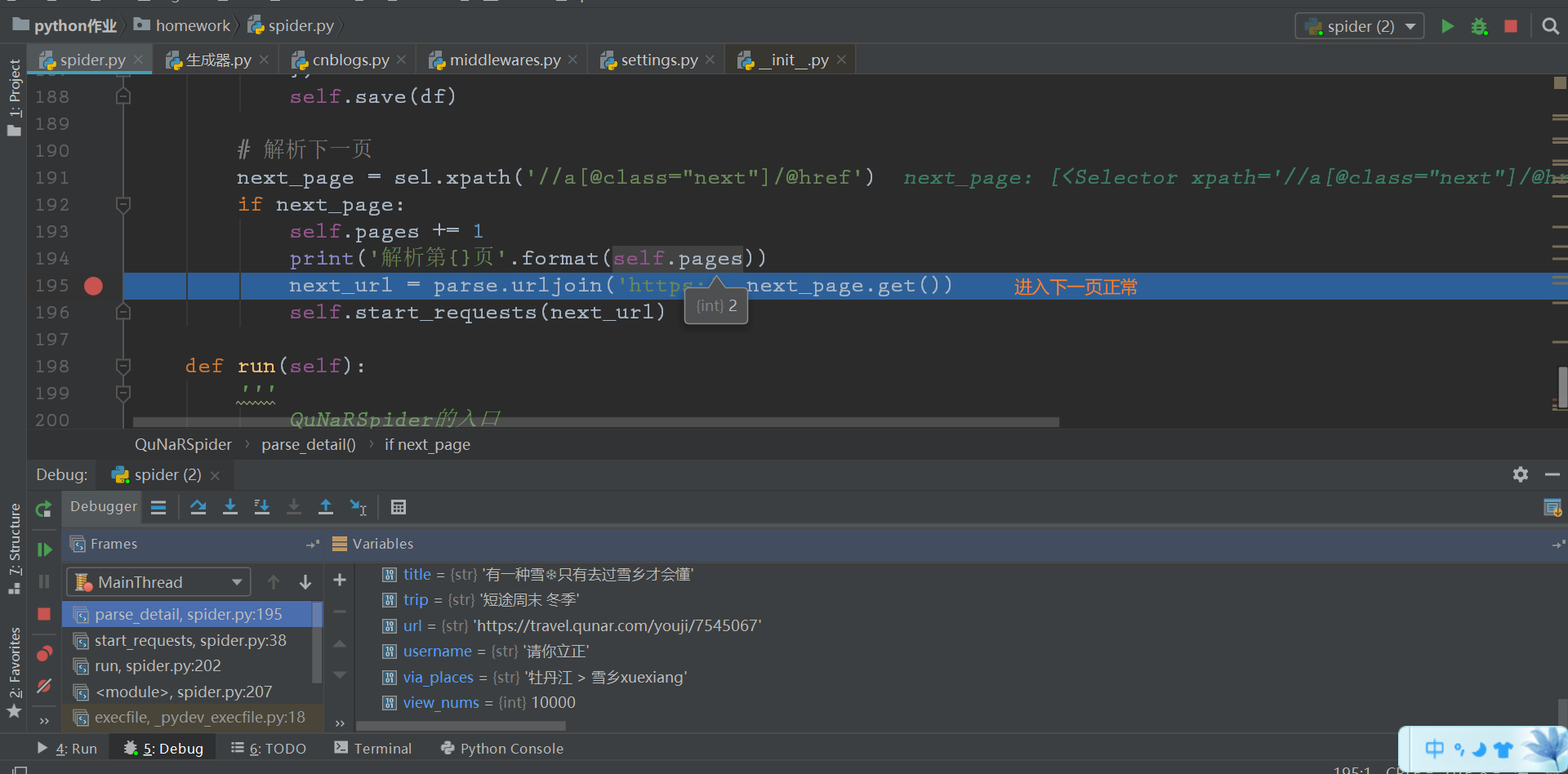
创建一个QuNaRSpider的类,定义start_requests()方法用来处理每一的请求,process_number()方法用来对整数数据的进一步加工,parse_detail()方法处理具体内容字段的提取,save()方法保存数据到csv文件中,run()用来启动爬虫,具体如下图解。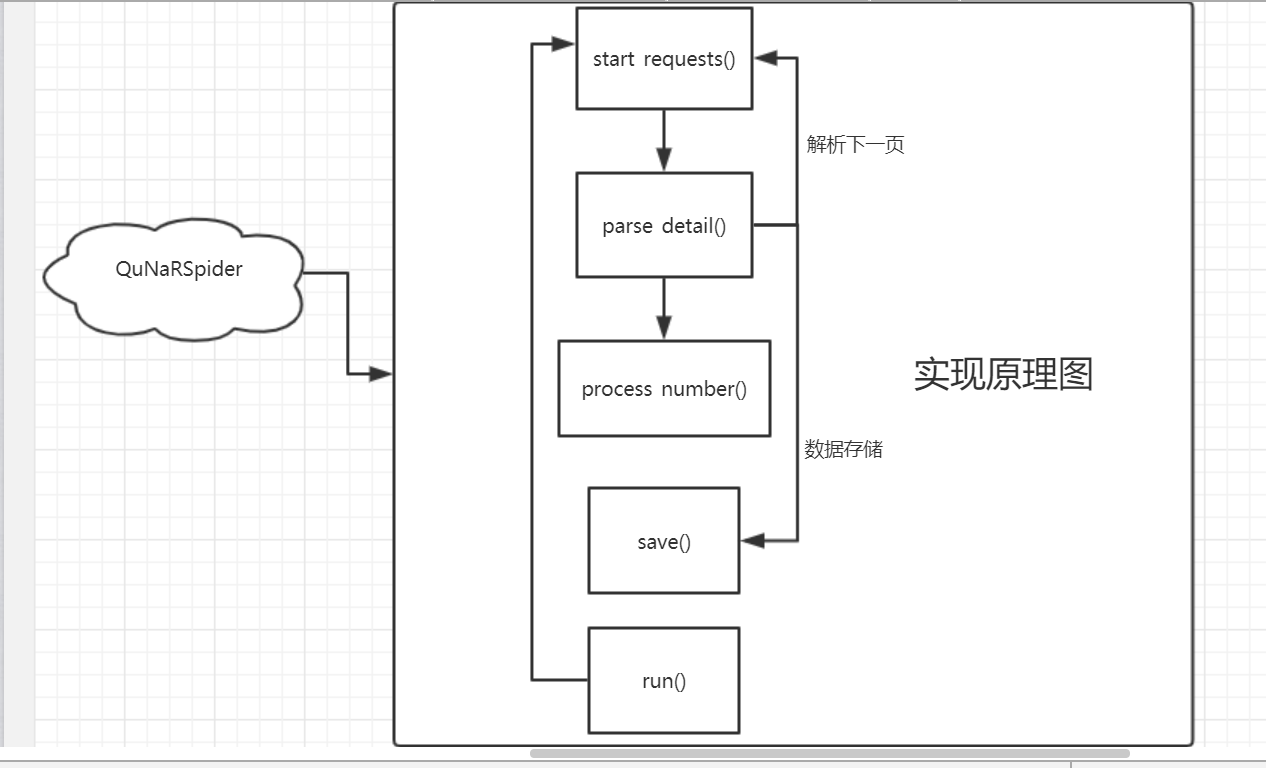
3.2技术难点
爬取过程中并未遇到阻拦,既不需要设置header, 也没遇到在爬取过程中被重定向到登录页面(整个爬取5-6分钟)。
二, 主题页面的结构特征分析
1, 主题页面的特征结构
每页10项数据,共计200页,数据项2000,不存在应拖动滚动条而动态加载的数据项,即li,通过右键查看网页源代码分析需要提取的数据是否存在动态生成的数据,任意查看一个数据项中与原网页中的数据对比后,发现所需要爬取的数据都是静态的。
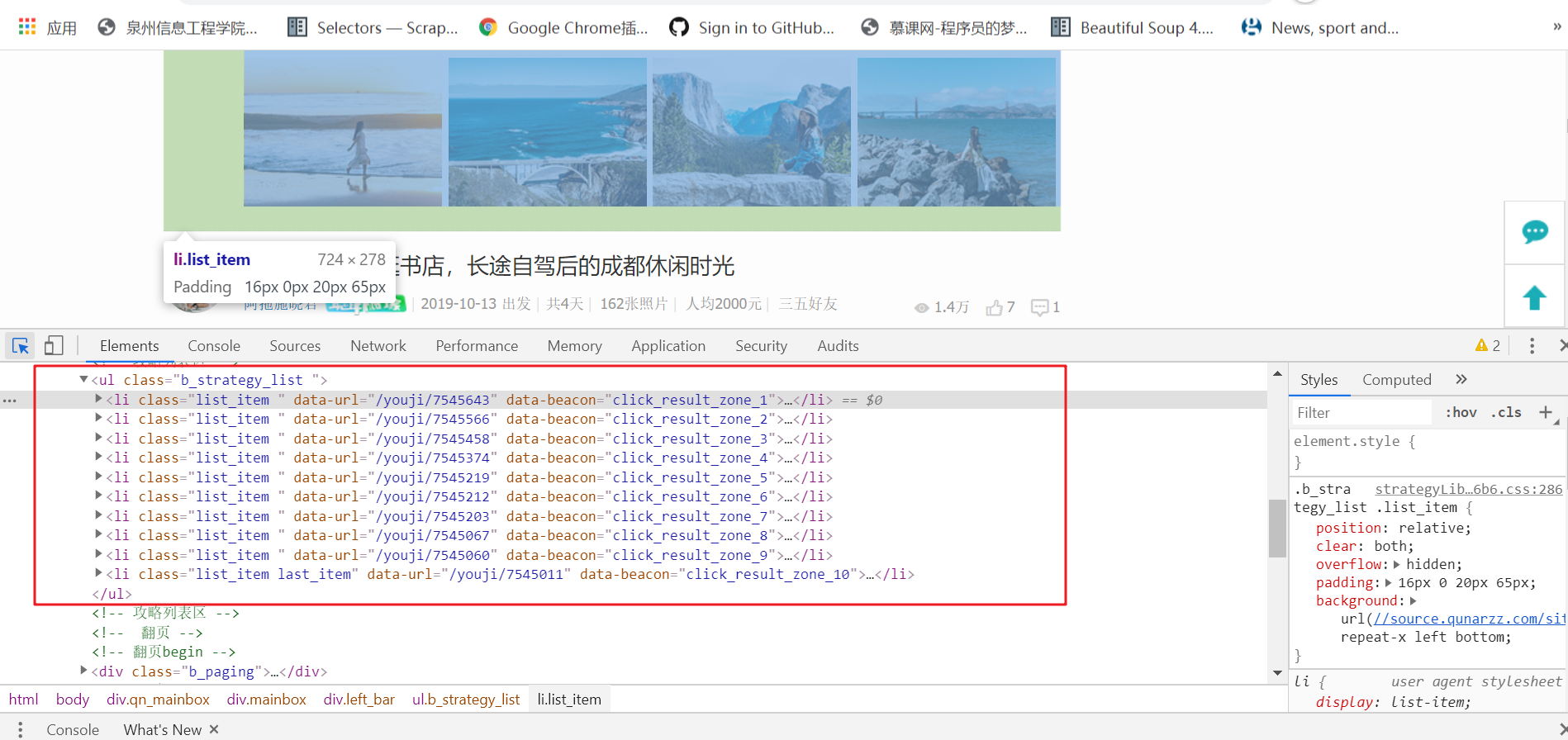
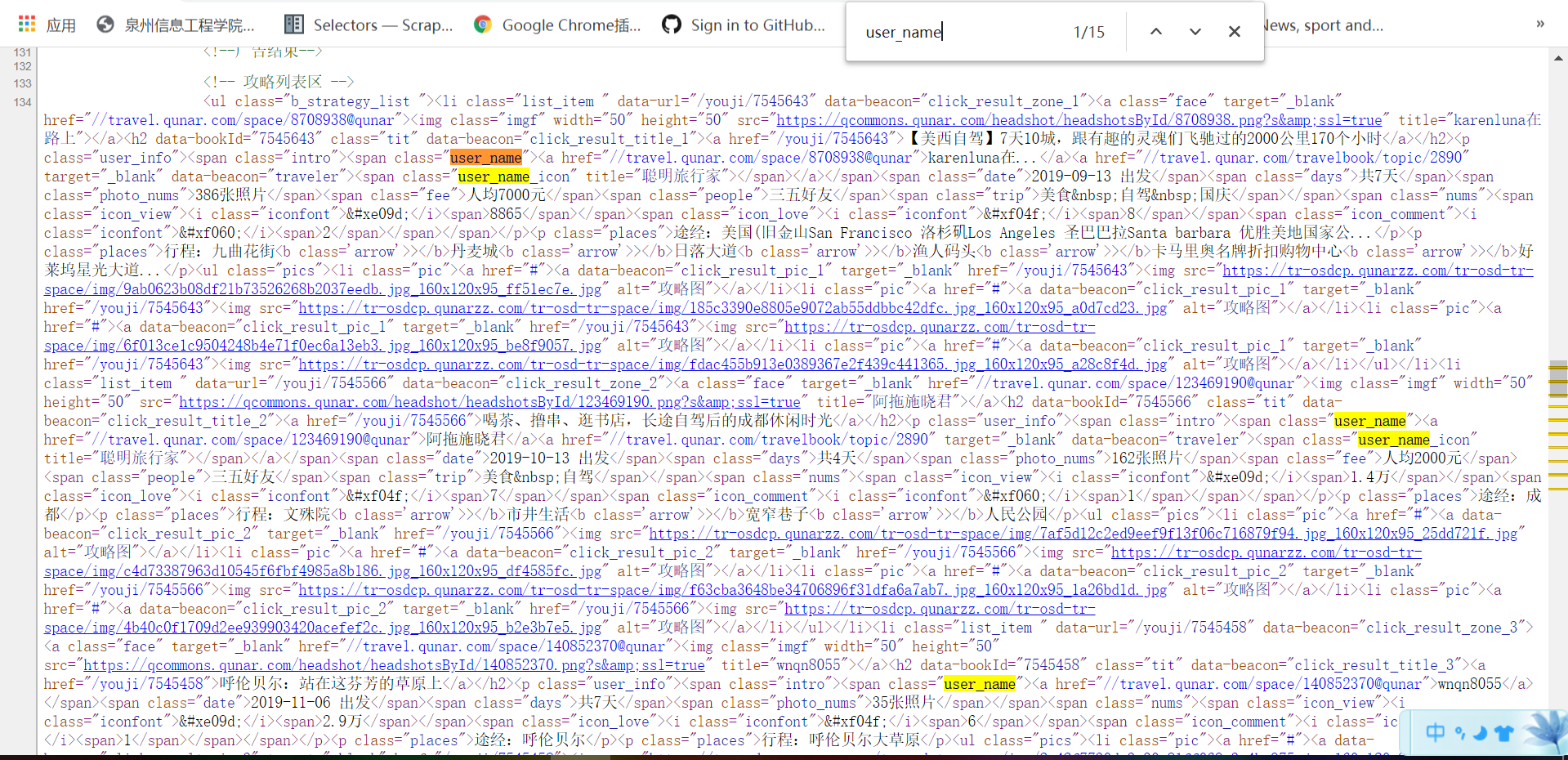
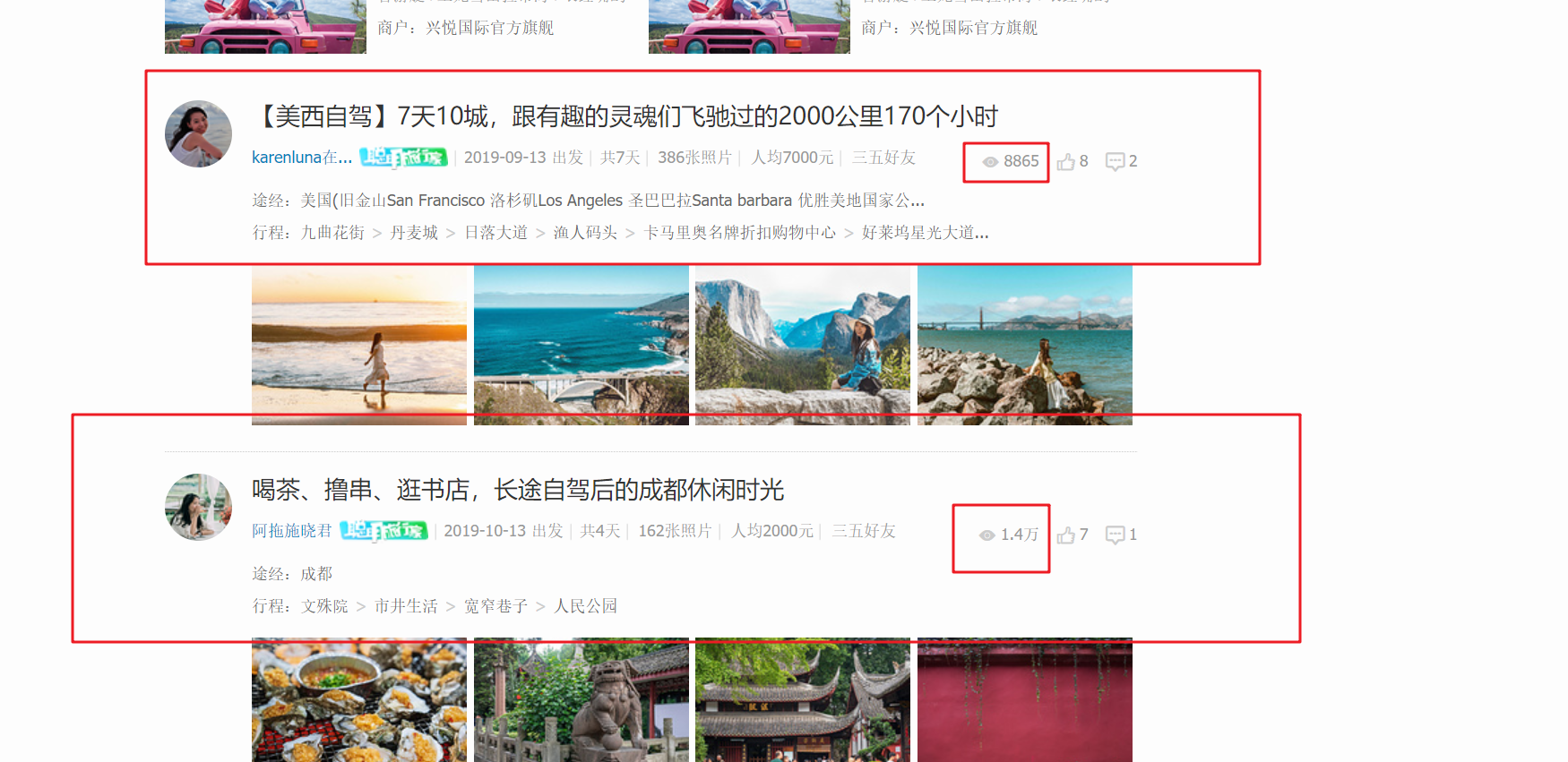
2, HTML页面解析
框框中的数据都是需要爬取的字段。
3, 节点(标签)查找方法与遍历发法(必要时画出节点数结构)
查找节点的方法采用scrapy的Selector选择器,用xpath来提取所需要的数据。从整体到部分的查找方式,即先确定爬取的数据所在哪个html的节点中,找到这个节点的所有直接子节点,也就是每一个攻略项,再用for循环依次遍历,然后再具体解析遍历的每一项攻略的数据。
三, 网络爬虫程序设计
1,爬虫程序主题要包括以下部分,要附源代码及较详解注释,并在每部分程序后面提供输出结果的截图。
import requests import re import os from fake_useragent import UserAgent from scrapy import Selector from datetime import datetime from urllib import parse from w3lib.html import remove_tags from pandas import DataFrame class QuNaRSpider: ''' 爬取去哪儿网的攻略 ''' start_url = 'https://travel.qunar.com/travelbook/list.htm?order=hot_heat' domain = 'https://travel.qunar.com' headers = { "User-Agent": UserAgent().random } pages = 1 # 将数据保存在当前文件的目录下 file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'qunar_data.csv') def start_requests(self, url): ''' 处理每一次的请求 ''' res = requests.get(url) try: res.raise_for_status() # 不建议使用res.encoding = res.apparent_encoding # 因为body中内容的charset有可能不是utf-8,导致解析中文时会出现乱码 res.encoding = 'UTF-8' self.parse_detail(res.text) except Exception as e: raise e def process_number(self, value): ''' 处理观看数,点赞数,评论数 ''' if "万" in value: r = re.search('(\d+\.*\d*)', value) if r: r = float(r.group(1)) return int(r * 10000) return int(value) def save(self, df): ''' 将数据写入csv ''' # 如果文件已经存在了,追加的形式写入文件,且不设置columns if os.path.exists(self.file_path): # 字符编码采用utf-8-sig,因为存在表情包 df.to_csv(self.file_path, header=False, index=False, mode="a+", encoding="utf_8_sig") else: df.to_csv(self.file_path, index=False, mode="w+", encoding="utf_8_sig") def parse_detail(self, html): ''' 解析的攻略中,每个攻略的发布者发布的信息略有不同 对于没有的字段,统一采用字段 "" 来进行标识 解析的字段如下: url: 文章链接 title:标题 describle: 简要描述信息 username: 发布者 label: 发布者的个人标签 date: 出发日期 days: 天数 photo_nums: 拍照数量 people: 出行的人员 trip: 旅行的标签 via_places: 途径 distance: 行程路线 price: 人均消费 view_nums: 观看数 praise_nums: 点赞数 comment_nums: 评论数 ''' sel = Selector(text=html) lis = sel.xpath('//ul[contains(@class, "b_strategy_list")]/li') for li in lis: url = li.xpath('.//h2/a/@href').get() url = parse.urljoin(self.domain, url) print("解析: " + url) title = li.xpath('.//h2/a/text()').get() try: # 利用scrapy的Selector自带的re_first方法可以以正则表达式的方法提取数据 describle = li.xpath('.//p[contains(@class, "icon_r")]/@class').re_first(r'icon_r\s*(\w+)') except: describle = '' username = li.xpath('.//span[@class="user_name"]/a[1]/text()').get() # 有些攻略不存在label try: label = li.xpath('.//span[@class="user_name"]/a[2]/span/@title').get() except: label = '' # 转换成日期的数据类型 date = li.xpath('.//span[@class="date"]/text()').re_first(r'(\d+-\d+-\d+)') date = datetime.strptime(date, "%Y-%m-%d") days = int(li.xpath('.//span[@class="days"]/text()').re_first(r'\d+')) photo_nums = int(li.xpath('.//span[@class="photo_nums"]/text()').re_first(r'\d+')) try: people = li.xpath('.//span[@class="people"]/text()').get() except: people = '' try: trip = li.xpath('.//span[@class="trip"]/text()').get() except: trip = '' # 途径和行程的爬取时存在四种情况 # 1,途径 + 行程 # 2,途径 # 3,行程 # 4,两者都没 via_places = '' distance = '' try: places = li.xpath('.//p[@class="places"]') except: places = None if places: if len(places) == 2: via_places = remove_tags(places[0].get()) distance = remove_tags(places[1].get()) if ">" in via_places: via_places = via_places.replace(">", " > ").replace("途经:", "") else: via_places = via_places.replace("途经:", "") if ">" in distance: distance = distance.replace(">", ' > ').replace("行程:", "") else: distance = distance.replace("行程:", "") else: via_places = remove_tags(places[0].get()) if ">" in via_places: via_places = via_places.replace(">", " > ").replace("途经:", "") else: via_places = via_places.replace("途经:", "") # 有些攻略不存在price try: price = int(li.xpath('.//span[@class="fee"]/text()').re_first(r'\d+')) except: price = 0 # 存在2.1万, 3000这两种类型的数据 view_nums = li.xpath('.//span[@class="nums"]/span[@class="icon_view"]/span/text()').get() view_nums = self.process_number(view_nums) praise_nums = li.xpath('.//span[@class="nums"]/span[@class="icon_love"]/span/text()').get() praise_nums = self.process_number(praise_nums) comment_nums = li.xpath('.//span[@class="nums"]/span[@class="icon_comment"]/span/text()').get() comment_nums = self.process_number(comment_nums) # 写入csv文件 df = DataFrame({ "url": [url], "title": [title], "describle": [describle], "username": [username], "label": [label], "date": [date], "days": [days], "photo_nums": [photo_nums], "people": [people], "trip": [trip], "via_places": [via_places], "distance": [distance], "price": [price], "view_nums": [view_nums], "praise_nums": [praise_nums], "comment_nums": [comment_nums] }) self.save(df) # 解析下一页 next_page = sel.xpath('//a[@class="next"]/@href') if next_page: self.pages += 1 print('解析第{}页'.format(self.pages)) next_url = parse.urljoin('https:', next_page.get()) self.start_requests(next_url) def run(self): ''' QuNaRSpider的入口 ''' self.start_requests(self.start_url) if __name__ == '__main__': qunar = QuNaRSpider() qunar.run()
具体截图如下:


2,对数据进行清洗和处理
2.1导包操作
# 导包操作
import numpy as np import pandas as pd import matplotlib.pyplot as plt from pandas import DataFrame, Series from pylab import mpl # 指定默认字体:解决plot不能显示中文问题 mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 解决保存图像是负号'-'显示为方块的问题 mpl.rcParams['axes.unicode_minus'] = False %matplotlib inline
2.2 读取爬虫爬取到的数据
df = pd.read_csv(r"D:\python作业\homework\origin_data.csv")
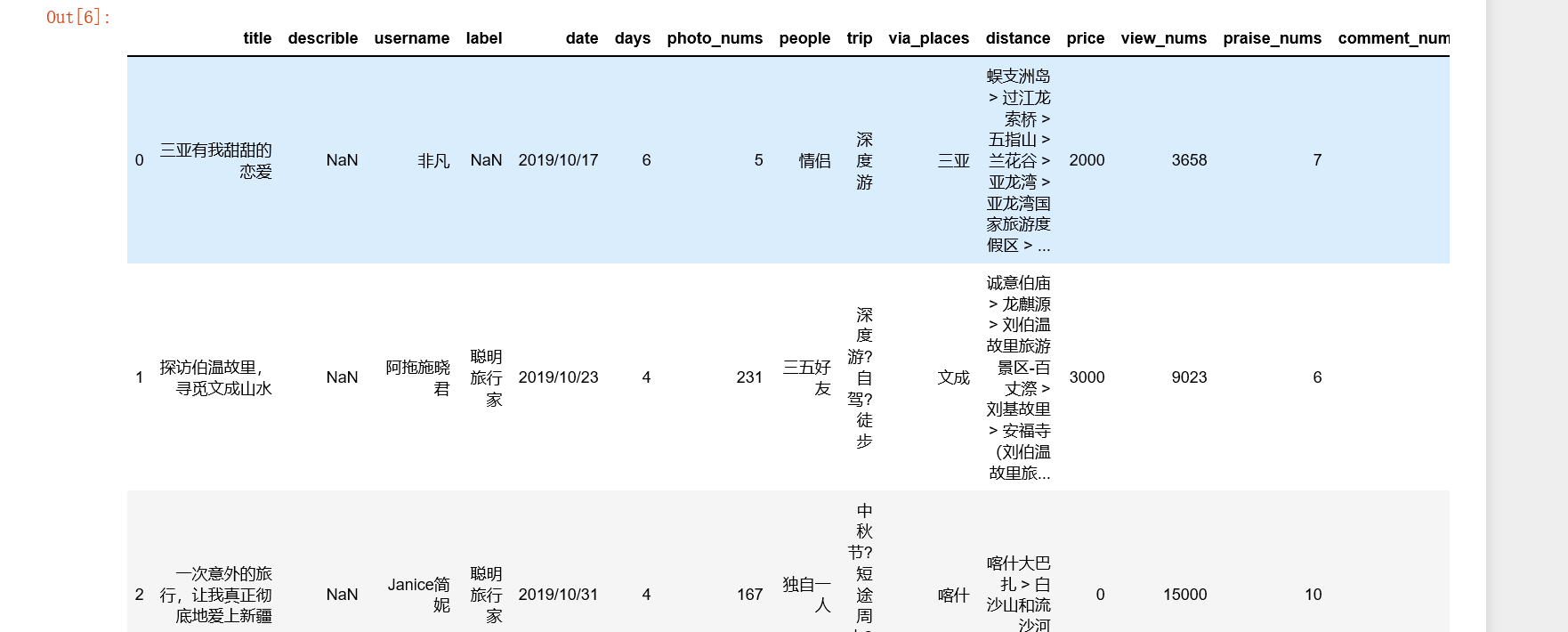
2.3 查看数据大小并显示前5条数据
df.shape
df.head()
2.4 产看是否存在重复值
df.duplicated()

2.5 去重复值,以title和username为去重的依据, 并查看其大小
df.drop_duplicates(['title', 'username']).shape

2.6 查看在爬取数据过程中无法通过直接方式提取到中文标识
df['describle'].value_counts()

2.7 数据的替换将拼音替换成汉字
df['describle'] = df['describle'].replace("meitu", "美图") df['describle'] = df['describle'].replace("duantupai", "短途派") df['describle'] = df['describle'].replace("jinghua", "臻品") df['describle'] = df['describle'].replace("wenyifan", "文艺范") df['describle'] = df['describle'].replace("ganhuo", "干货") df['describle'].value_counts()

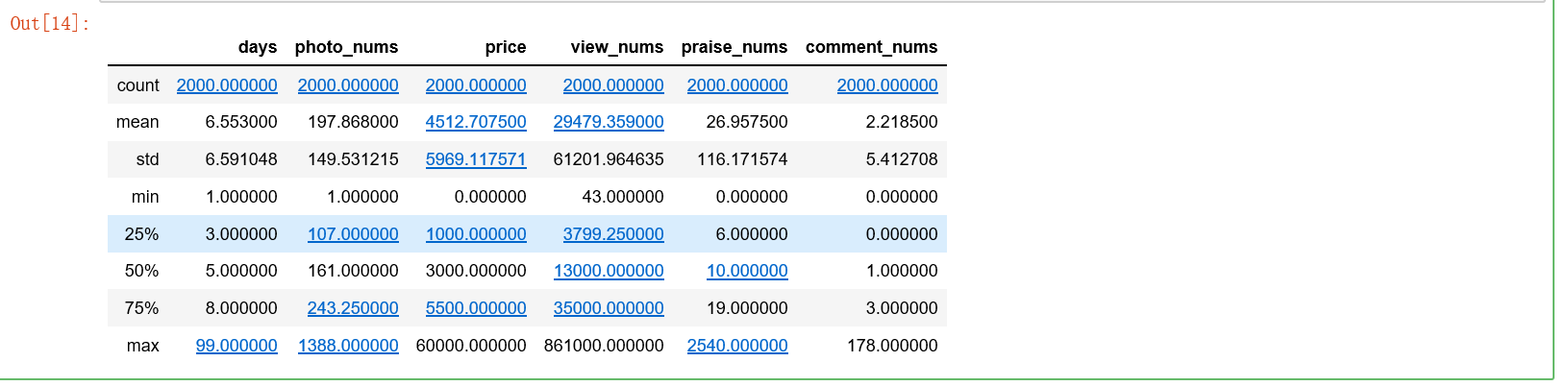
2.8 查看数据的整体分布
df.describe()
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
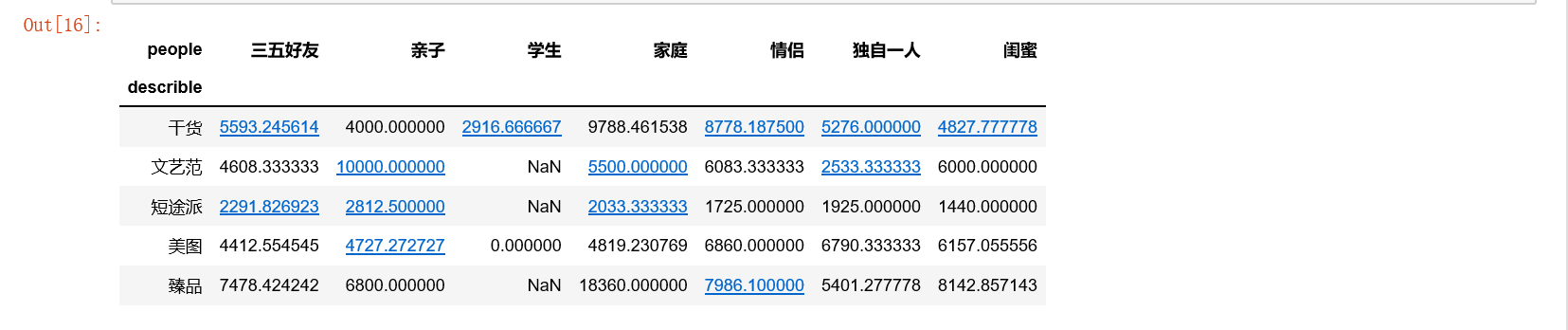
4.1 需求1:decrible与价格,people的透视表,查看好的体验的平均消费
df_pivot = df.pivot_table(index="describle", columns="people", values="price") df_pivot.shape
df_pivot
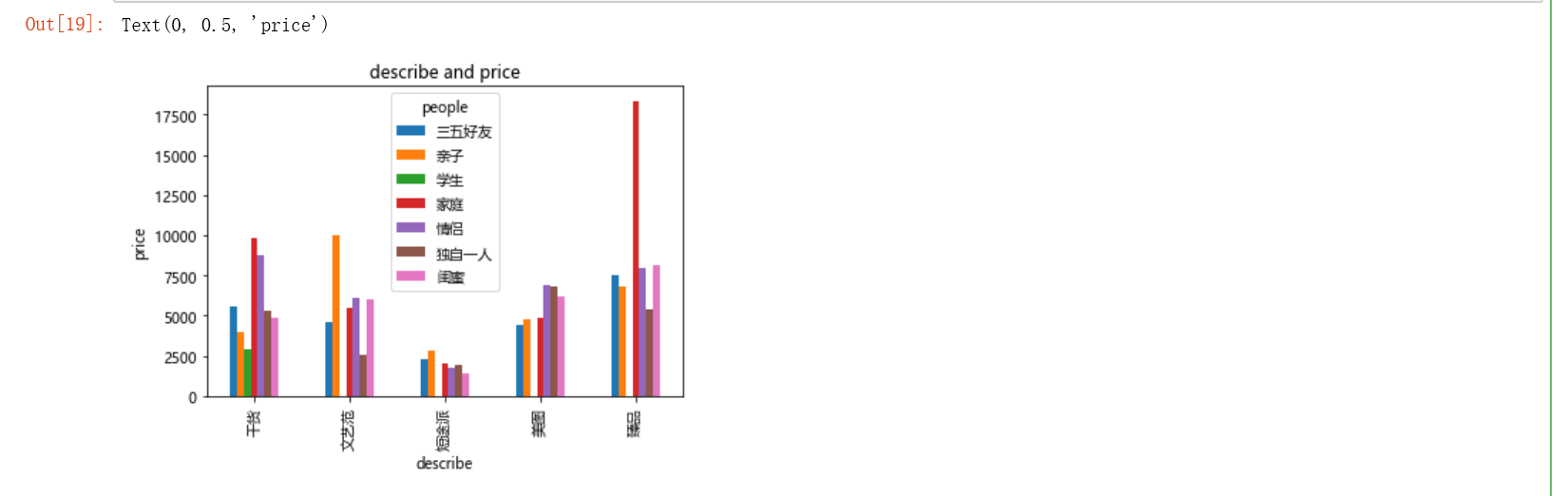
# 数据可视化 df_pivot.plot(kind='bar', title='describe and price') plt.xlabel('describe') plt.ylabel('price')
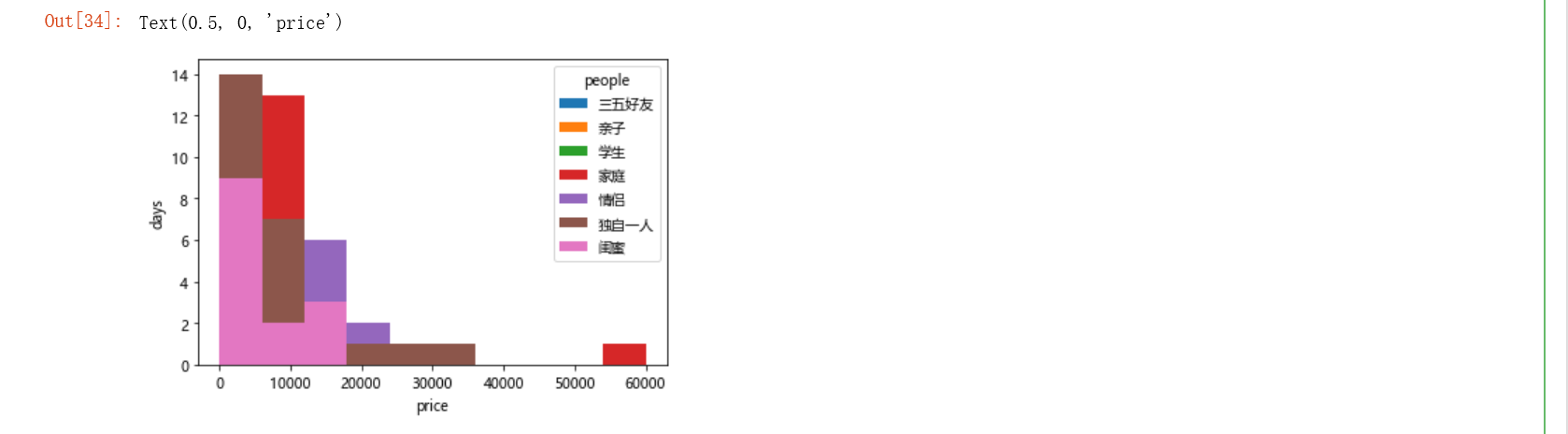
4.2 需求2: 对出行的方式, 天数和价格做一个透视表

# 数据可视化 df_pivot2.plot(kind='hist') plt.ylabel('days') plt.xlabel('price')
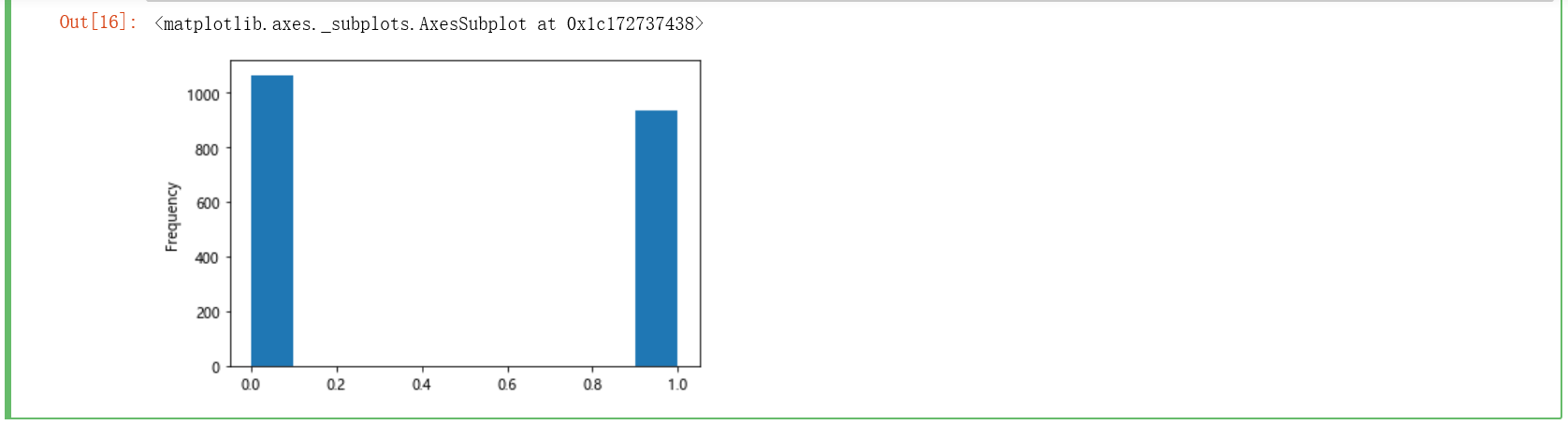
4.3 需求3:想知道被去哪儿网确定为聪明旅行家所占的比例
df['label'].value_counts() / df.shape[0]

# 数据可视化 1 代表聪明旅行家 0 代表无
s = [] for i in df['label']: if '聪明旅行家' == i: s.append(1) else: s.append(0) s = Series(s) s.head() s.plot(kind='hist')
4.4 需求4:想知道攻略排名消费前10的信息
df.sort_values('price',ascending=False).head(10)

需求5:想知道攻略中最多人观看的出行方式,作为出行参考的信息
df.sort_values('view_nums',ascending=False).head(10)

需求6:想知道人们具体出行的方式都有哪些
# 对trip进行一个重新组装,找出所有的trip标签,并进行标签的去重操作 trip_list = [] for val in df['trip'].dropna(): if '?' in val: val_list = val.strip().split('?') for sub_val in val_list: trip_list.append(sub_val) else: trip_list.append(val) trip_series = Series(trip_list).drop_duplicates()
trip_series

trip_series.shape

5.数据持久化
写入csv文件
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.1 消费前10的出行方式,基本都是出国游
2.2 针对不同出行的方式的体验,比如说干货等,出行消费都不低,其中臻品的消费是最高的
2.3 通过对针对战队针对
2.对本次程序设计任务完成的情况做一个简单的小结。
本次作业,对爬虫和数据分析做了个整合,将所学的知识都有用上,感觉很好,期待自己的每一次进步
一, 主题式网络爬虫设计方案
1, 主题式网络爬虫的名称
1.1去哪网攻略的爬取
2, 主题式网络爬虫的内容与数据特征分析
2.1爬虫的内容
url: 文章链接,title:标题,describle: 简要描述信息
username: 发布者,label: 发布者的个人标签,date: 出发日期
days: 天数,photo_nums: 拍照数量,people: 出行的类型
trip: 旅行的标签,via_places: 途径,distance: 行程路线
price: 人均消费,view_nums: 观看数,praise_nums: 点赞数
comment_nums: 评论数
2.2 数据特征分析
2.2.1对trip,days和price做一个透视表并可视化
2.2.2对label,peope和price做一个透视表并可视化
3, 主题式网络爬虫设计方案概述(包括实现思路和技术难点)
3.1实现思路
创建一个QuNaRSpider的类,定义start_requests()方法用来处理每一的请求,process_number()方法用来对整数数据的进一步加工,parse_detail()方法处理具体内容字段的提取,save()方法保存数据到csv文件中,run()用来启动爬虫,具体如下图解。

3.2技术难点
爬取过程中并未遇到阻拦,既不需要设置header, 也没遇到在爬取过程中被重定向到登录页面(整个爬取5-6分钟)。
二, 主题页面的结构特征分析
1, 主题页面的特征结构
每页10项数据,共计200页,数据项2000,不存在应拖动滚动条而动态加载的数据项,即li,通过右键查看网页源代码分析需要提取的数据是否存在动态生成的数据,任意查看一个数据项中与原网页中的数据对比后,发现所需要爬取的数据都是静态的。



2, HTML页面解析
框框中的数据都是需要爬取的字段。

3, 节点(标签)查找方法与遍历发法(必要时画出节点数结构)
查找节点的方法采用scrapy的Selector选择器,用xpath来提取所需要的数据。从整体到部分的查找方式,即先确定爬取的数据所在哪个html的节点中,找到这个节点的所有直接子节点,也就是每一个攻略项,再用for循环依次遍历,然后再具体解析遍历的每一项攻略的数据。
三, 网络爬虫程序设计
爬虫程序主题要包括以下部分,要附源代码及较详解注释,并在每部分程序后面提供输出结果的截图。
1, 数据爬取与采集



2, 对数据进行清洗和处理
2.1 读取数据

2.2 去除重复值

2.3 替换在爬取数据过程中无法通过直接方式提取到中文标识

2.4 查看数据的整体分布

3, 文本分析(可选):jieba分词,wordclound可视化
4, 数据分析与可视化
4.1 需求1:decrible与价格,people的透视表,查看好的体验的平均消费


4.2 # 需求2:对出行的方式, 天数和价格做一个透视表


4.3 # 需求3:想知道聪明旅行家所占的比例

4.4 # 需求4:想知道攻略排名消费前10的信息

4.5 # 需求5:想知道攻略中最多人观看的出行方式,作为出行参考的信息

5, 数据持久化
写入csv文件