用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
无忧无虑电影网通用爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
2.主题式网络爬虫爬取的内容与数据特征分析
爬取电视剧列表以及电视剧的详细内容(包括剧名,年份,评分,集数,主演,导演,地区,地址等)


分析地区和地区电视剧评分是否有关系
使用requests库和beautifulSoup4库爬取并解析提取所需内容,将其数据保存到excel表格中
技术难点:在于将不同页数的数据保存在一个excel表格的不同工作簿中,还有对数据的封装
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征
只要修改路径中的数字,即可爬取不同页数的网页电视剧列表
![]()
想要获取电视剧详细页的数据,只需要从电视剧列表中的a标签href中提取电视剧id即可,url中数字之前的路径固定
2.Htmls页面解析
解析电视剧列表


想要获取图中的数据,需要解析下html源码


3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)

三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
# 用于获取网页源码的函数 def getHTMLText(url): try: # 使用requests库爬取网页源码2 r = req.get(url, headers={'user-agent': 'Mozilla/5.0'}) # 判断是否爬取过程中出现错误 r.raise_for_status() # 设置源码的编码格式 r.encoding = r.apparent_encoding return r.text except: return "爬取失败" # 拼接地址,返回爬取地址数组 def urlSplit(path, sheet): array = [] for i in sheet["href"]: url = path+i array.append(url) return array # 获取指定url页面中电视剧列表集合 def TvList(html): # 外部传来的全局数组 Tvlist = [] #使用BeautifulSoup类解析html文本 soup = BeautifulSoup(html, "html.parser") #获取每个电视剧的a链接数组 As = soup.select("ul.fed-list-info > li >a.fed-list-title") #从a标签中获取电视剧id,name,href for a in As: # 获取href href = a.attrs["href"] # 获取电视剧id id = href.split('/')[-2] # 获取Tv name name = a.text tem = [id,name,href] Tvlist.append(tem) return Tvlist # 获取电视剧详情页数据集合 def TvDetailList(html, TvDetaillist): # 解析网页源码 soup = BeautifulSoup(html, "html.parser") # 电视剧名称 title = soup.h1.a.string # 电视剧地址 href = "https://www.bt5156.com"+soup.h1.a.attrs['href'] # 临时数组 temp = [] for index, value in enumerate(soup.find_all('li', 'fed-part-eone')): if(index > 5): break temp.append(value.text) # 主演 actor = temp[0].split(":")[1] # 导演 director = temp[1].split(":")[1] # 地区 sort = temp[2].split(":")[1] # 地址 location = temp[3].split(":")[1] # 年份 year = temp[4].split(":")[1] # 最新修改时间 date = temp[5].split(":")[1] # 判断可能会出现错误的地方,将错误跳过 try: # 集数 number = soup.find_all('span', 'fed-list-remarks')[0].text number = re.findall('\d+', number)[0] except: number = '' # 不论number数据是否错误,都执行以下代码 finally: # 评分 score = soup.find_all('span', 'fed-list-score')[0].text # 简介 description = soup.find_all('div', 'fed-part-esan')[0].text # 对数据进行组装,一个temp就是一个电视剧详细信息 temp = [title, href, actor, director, sort,location, year, date, number, score, description] # 将电视剧信息存入集合 TvDetaillist.append(temp) print(title) # 将数据保存到excel文件中 def saveExcel(writer,sheet,df): # 将数据写入excel表中 df.to_excel(writer, sheet_name=sheet) def saveTvListToExcel(urls, pages, TvlistPath): writer = pd.ExcelWriter(TvlistPath) # 爬取网站前n页电视剧列表,分别存储在不同的工作簿中 for index, url in enumerate(urls): print(url+" "+pages[index]) # 网页源码 html = getHTMLText(url) # 返回电视剧列表 Tvlist = TvList(html) # 将列表转为pandas中的DataFrame df = pd.DataFrame(Tvlist, columns=['id', 'name', 'href']) # 将DataFrame写入excel中,数据持久化 saveExcel(writer, pages[index], df) # 从内存中写入excel writer.save() def saveTvDetailListToExcel(path,pages, TvlistPath, TvDetaillistPath): col = ["title", "href", "actor", "director", "sort", "location", "year", "date", "number", "score", "description"] writer = pd.ExcelWriter(TvDetaillistPath) for page in pages: TVDetaillist = [] sheet = pd.read_excel(TvlistPath, sheet_name=page) for url in urlSplit(path, sheet): # 循环地址,爬取电视剧详情页 html = getHTMLText(url) try: TvDetailList(html, TVDetaillist) except: # 发生错误立即将数据保存至excel中并停止爬取 df = pd.DataFrame(TVDetaillist, columns=col) saveExcel(writer, page, df) writer.save() print("有一条数据爬取错误") return 0 df = pd.DataFrame(TVDetaillist, columns=col) saveExcel(writer, page, df) writer.save() # 爬取的页数 def SpiderPageNum(n, urls, pages): for i in range(1, n+1): url = "https://www.bt5156.com/vodshow/lianxuju--------" + \ str(i) + "---/" urls.append(url) page = "page" + str(i) pages.append(page)
#主函数 if __name__ == "__main__": # 网站域名 path = "https://www.bt5156.com" # 电视剧列表存储文件路径 TvlistPath = "TV.xlsx" # 电视剧详细信息列表存储文件路径 TvDetaillistPath = "TVdatail.xlsx" # 电视剧列表地址 urls = [] # excel工作蒲 pages = [] # 爬取4页电视剧列表 SpiderPageNum(4, urls, pages) # 开始爬取电视剧列表 saveTvListToExcel(urls, pages, TvlistPath) # 开始爬取电视机详情列表 saveTvDetailListToExcel(path, pages, TvlistPath, TvDetaillistPath)
2.对数据进行清洗和处理
pages = [] urls = [] def SpiderPageNum(n, urls, pages): for i in range(1, n+1): url = "https://www.bt5156.com/vodshow/lianxuju--------" + \ str(i) + "---/" urls.append(url) page = "page" + str(i) pages.append(page) SpiderPageNum(4,urls,pages) print(pages) #从excel文件中获取数据 page1 = pd.read_excel("TVdatail.xlsx", sheet_name=pages[0]) page2 = pd.read_excel("TVdatail.xlsx", sheet_name=pages[1]) page3 = pd.read_excel("TVdatail.xlsx", sheet_name=pages[2]) page4 = pd.read_excel("TVdatail.xlsx", sheet_name=pages[3])
# 获取page1中位空的数据个数 page1['location'].isnull().value_counts()

#查询是否存在空值 print(page2['location'].isnull().value_counts()) #对存在空值的地方填充 其他地区 page2['location'] = page2['location'].fillna('其他地区')

3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
page1['number'] = page1['number'].fillna(page1['number'].mean()) # print(page1) sns.set(style="white") # 绘制剧集和评分的散点分布 sns.scatterplot(x="number",y='score',data = page1)

sns.set(style="white")#显示风格 sns.jointplot(x="number",y='score',data = page1,kind='reg',height=5)

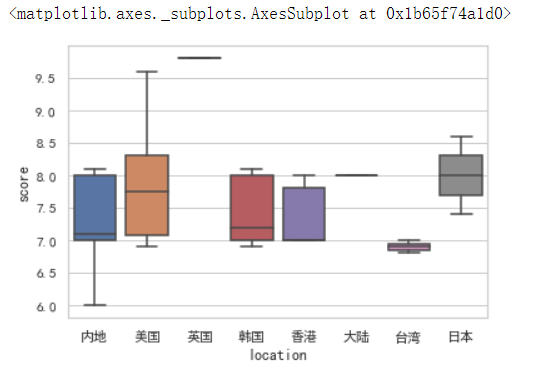
# 解决seaborn中文乱码问题 sns.set_style('whitegrid',{'font.sans-serif':['simhei','Arial']}) # 查询各个国家电视剧的评分分布 sns.boxplot(x='location',y='score', data=page1)
sns.distplot(page1['score'])

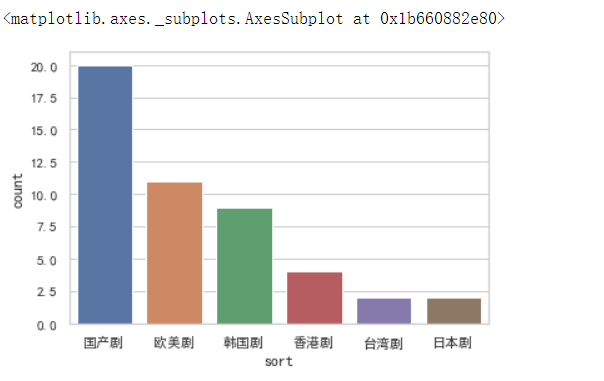
# 统计各个剧种的数量直方图 sns.countplot(page1['sort'])
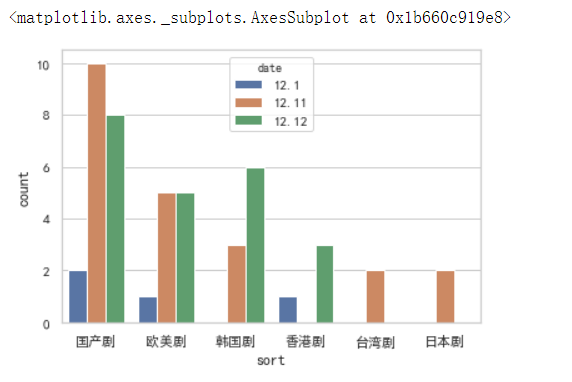
# 不同时间段各个国家电视剧更新次数直方图 sns.countplot(x=page1['sort'], hue=page1['date'])
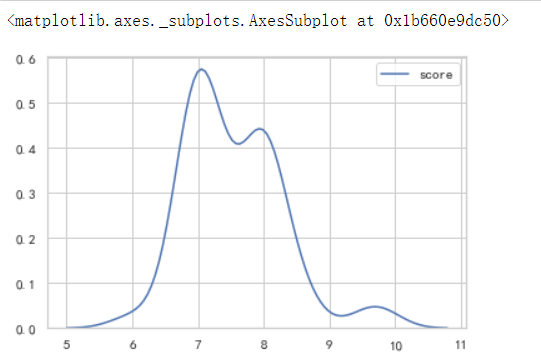
# 电视剧评分密度图 sns.kdeplot(page1['score'],kernel='gau')
# 散点图 sns.catplot(x="sort", y="score", data=page1)

电视剧列表数据
电视剧详情数据

四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过数据可视化,得出了英剧的电视剧质量(评分)较高,台湾电视剧质量较差劲
看出电视剧集数越多并不代表质量越好
网页的电视剧数量国产剧数量较多
从更新量来看,国产剧的更新次数较多,英剧其次,韩剧第三
欧美剧的电视剧质量最高
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次的爬虫项目,让我对爬虫的了解进一步加深,也对网站的解构有了更深的了解,对于今后爬取动态网站打下基础