用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
烽火戏诸侯的历年小说情况
2.主题式网络爬虫爬取的内容与数据特征分析
2.主题式网络爬虫爬取的内容与数据特征分析
烽火戏诸侯的各本小说名称
各本小说的总点击量
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
http://home.zongheng.com/show/userInfo/166130.html
http://book.zongheng.com/book/{}.html
先从作者信息页面爬取书籍url地址,然后根据书籍url地址爬取书籍名称和点击量,然后把名称和点击量制成Excel和图表。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征
http://home.zongheng.com/show/userInfo/166130.html
http://book.zongheng.com/book/{}.html
在作者信息页面抓取作品url,通过在括号中填入不同代码。
2.Htmls页面解析
2.Htmls页面解析

从class类型为imgbox的div下抓取a标签,再从a标签的href下抓取不同作品的url。

从class类型为book-info的div标签下抓取作品名称。
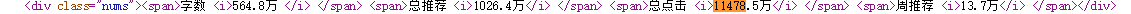
从class类型为nums的div下抓取i标签,再从第二个i标签中抓取作品点击量。
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
(必要时画出节点树结构)
def namesinfo(html): soup = BeautifulSoup(html, 'html.parser') #获取属性为book-name的div name = soup.find_all("div", attrs='book-name') #正则获取中文书名 namess = re.findall(r"[\u4e00-\u9fa5]+", str(name[0]))
find_all方法查找,再用正则表达式获取中文书名。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
from bs4 import BeautifulSoup import requests, matplotlib, re, xlwt import matplotlib.pyplot as plt #获取页面 def gethtml(url): info = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'} try: data = requests.get(url, headers=info) data.raise_for_status() data.encoding = data.apparent_encoding return data.text except: return " " #书籍url def urlinfo(url): books = [] book = gethtml(url) soup = BeautifulSoup(book, "html.parser") #获取属性为tit的p标签 p = soup.find_all("p", attrs="tit") for item in p: #获取书籍地址 books.append(item.a.attrs['href']) return books #点击量信息 def numsinfo(html): n = [] soup = BeautifulSoup(html, 'html.parser') div = soup.find_all("div", attrs='nums') nums = div[0] i = 0 for spa in nums.find_all("i"): if i == 2: #获取点击量 n.append(spa.string.split('.')[0]) break i += 1 return n #书名信息 def namesinfo(html): soup = BeautifulSoup(html, 'html.parser') #获取属性为book-name的div name = soup.find_all("div", attrs='book-name') #正则获取中文书名 namess = re.findall(r"[\u4e00-\u9fa5]+", str(name[0])) return namess #修复中文方框 matplotlib.rcParams['font.sans-serif'] = ['SimHei'] matplotlib.rcParams['font.family'] = 'sans-serif' matplotlib.rcParams['axes.unicode_minus'] = False #柱形图 def Bar(x, y, user): plt.bar(left=x, height=y, color='y', width=0.5) plt.ylabel('点击量') plt.xlabel('书名') plt.title(user) plt.savefig(user, dpi=300) plt.show() def file(book, nums, address): # 创建Workbook,相当于创建Excel excel = xlwt.Workbook(encoding='utf-8') #创建名为One的表 sheet1 = excel.add_sheet(u'One', cell_overwrite_ok=True) #写入列名 sheet1.write(0, 0, 'book') sheet1.write(0, 1, 'nums') for i in range(1, len(book)): sheet1.write(i, 0, book[i]) for j in range(1, len(nums)): sheet1.write(j, 1, nums[j]) excel.save(address) #列表元素类型转换 def convert(lista): listb = [] for i in lista: listb.append(i[0]) return listb def main(): #作者页面 author = 'http://home.zongheng.com/show/userInfo/166130.html' user = '烽火戏诸侯' urls = urlinfo(author) namelist = [] countlist = [] for url in urls: html = gethtml(url) namelist.append(namesinfo(html)) countlist.append(numsinfo(html)) namelist = convert(namelist) countlist = convert(countlist) for i in range(len(countlist)): countlist[i] = int(countlist[i]) #保存地址 addr = f'D:\\{user}.xls' file(namelist, countlist, addr) Bar(namelist, countlist, user) if __name__ == '__main__': main()
1.数据爬取与采集
def urlinfo(url): books = [] book = gethtml(url) soup = BeautifulSoup(book, "html.parser") #获取属性为tit的p标签 p = soup.find_all("p", attrs="tit") for item in p: #获取书籍地址 books.append(item.a.attrs['href']) return books
def numsinfo(html): n = [] soup = BeautifulSoup(html, 'html.parser') div = soup.find_all("div", attrs='nums') nums = div[0] i = 0 for spa in nums.find_all("i"): if i == 2: #获取点击量 n.append(spa.string.split('.')[0]) break i += 1 return n
2.对数据进行清洗和处理
数据清洗
for spa in nums.find_all("i"): if i == 2: #获取点击量 n.append(spa.string.split('.')[0]) break i += 1
数据清洗
namess = re.findall(r"[\u4e00-\u9fa5]+", str(name[0])) return namess
3.文本分析(可选):jieba分词、wordcloud可视化
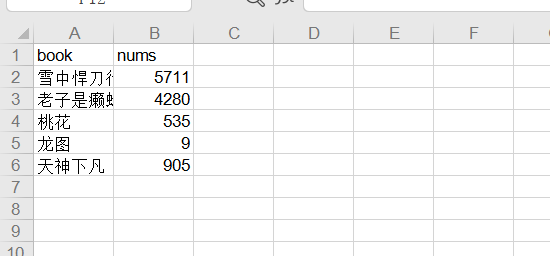
def file(book, nums, address): # 创建Workbook,相当于创建Excel excel = xlwt.Workbook(encoding='utf-8') #创建名为One的表 sheet1 = excel.add_sheet(u'One', cell_overwrite_ok=True) #写入列名 sheet1.write(0, 0, 'book') sheet1.write(0, 1, 'nums') for i in range(1, len(book)): sheet1.write(i, 0, book[i]) for j in range(1, len(nums)): sheet1.write(j, 1, nums[j]) excel.save(address)
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)

def Bar(x, y, user): plt.bar(left=x, height=y, color='y', width=0.5) plt.ylabel('点击量') plt.xlabel('书名') plt.title(user) plt.savefig(user, dpi=300) plt.show()
5.数据持久化

四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
剑来和雪中是作者最为畅销的小说。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过本次实验,是我对python的应用,让我对网络爬取有了更加深刻地理解。