感知机(perceptron)是一个二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1与-1二值。
感知机对应于输入空间(特征空间)中将实例分为正负两类的分离超平面,属于判别模型。
感知机的学习旨在求出将训练集数据进行线性划分的超平面,为此,导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型。
感知机模型分为原始形式和对偶形式。
请看感知机的定义:

数据的线性可分性:给定一个数据集,如果存在某个超平面,能够将数据集的正实例点和负实例点完全正确的划分到超平面的两侧,则称数据集是线性可分的。
感知机的学习策略:

这里补充一点,经验风险和期望风险的区别,以前总以为是一个东西,期望风险是相对有所有数据来说的,是一个理想化的,本质是不可求的;而经验风险是争对与训练集所说,本质是可以求得的。
还有L1范数,L2范数:先说什么是范数:范数是具有“长度”概念的函数。在向量空间内,为所有的向量的赋予非零的增长度或者大小。不同的范数,所求的向量的长度或者大小是不同的。
L1范数:
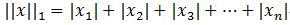
L2范数:
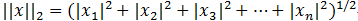
感知机的学习算法:
原始形式:

对偶形式:

对偶形式和原始形式的区别:就在于把w的更新换成更新w的增量,还有将实例内积后保存到gram矩阵中。
gram的运算方式是:
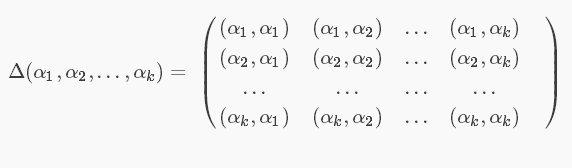
当训练集数据集线性可分时,感知机算法是收敛的,感知机算法在训练数据集上的误分类次数k满足不等式:

当训练集线性可分时,感知机学习算法存在无穷多个解,其解由于不同的初值,或不同的迭代顺序而可能有所不同。
具体看代码实现:
手写感知机,没用sklean库:
#__author__ = '峰'
#date:2019/2/24
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
'''
f(x)=sign(w∗x+b) 符号函数,(x>0:1);(x<=0:-1)
损失函数 L(w,b)=−Σyi(w∗xi+b)L(w,b)=−Σyi(w∗xi+b)
'''
#加载数据(鸢尾花数据集),有五个列
# 1. 花萼長度(Sepal Length): 計算單位是公分。
# 2. 花萼寬度(Sepal Width): 計算單位是公分。
# 3. 花瓣長度(Petal Length) :計算單位是公分。
# 4. 花瓣寬度(Petal Width): 計算單位是公分。
# 5. 類別(Class):可分為Setosa多刺的,Versicolor杂色的和Virginica三個品種。
'''
数据预处理
'''
iris = load_iris()
# dataframe 是一个二维的、表格型的数据结构
df = pd.DataFrame(iris.data,columns=iris.feature_names)
df['label'] = iris.target
#label标签
# 指定列的名字
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
# 统计标签的次数
# 这个数据集有150个数,前50个标签是0,中间50是1,最后50个是2
# print(df.label.value_counts())
# 本模型中只拿出iris数据集中(两个分类的数据)和[sepal length,sepal width]作为特征
# 可视化散点图
# plt.scatter(df[0:50]['sepal length'],df[0:50]['sepal width'],label='0')
# plt.scatter(df[50:100]['sepal length'],df[50:100]['sepal width'],label='1')
# # x,y轴坐标
# plt.xlabel('sepal length')
# plt.ylabel('sepal width')
# 图例
# plt.legend()
# plt.show()
#
# 将数据集分为100行三列的数据(列只取花萼的长宽和类别)
data = np.array(df.iloc[:100,[0,1,-1]])
# 获取输入空间(特征向量集合)
X =data[:100,:-1]
# 获取类标签数据集(输出空间类别集合)
y =data[:100,-1]
# 因为本模型符号函数,分类x>0正1,x<0负1
# 所以对类别进行处理,因为本数据集类别是0,1
y =np.array([-1 if i==0 else 1 for i in y])
# 自动划分训练集和数据集
X, X_test, y, y_test = train_test_split(X, y, test_size=0.2)
'''
Perceptron感知器模型
'''
class PerceptronModel():
def __init__(self):
# 权重 初始化为全1矩阵,-1是因为,x特征向量是两维的,如果不减1,w就是三维的
#三维和两维求内积,会报错,维度不同
self.w =np.ones(len(data[0])-1,dtype=np.float32)
# 偏置项(截距)(加上这个偏置项b,才能保证分类器可以在空间的任何位置画决策面)
self.b = 0
# 学习率
self.learningRate = 0.1
#符号函数
def sign(self,w,x,b):
# f(x) = sign(w∗x + b)
y = np.dot(w,x)+b
return y
def gradientDescentFitting(self,Xtrain,ytrain):
#定义误分类标志
wrong = True
#当他误分类时,循环迭代
while wrong:
# 误分类次数
wrong_num=0
for i in range(len(Xtrain)):
X = Xtrain[i]
y = ytrain[i]
# 当y(w*x+b)<0时,
if y*self.sign(self.w,X,self.b)<=0:
self.w = self.w+self.learningRate*np.dot(y,X)
self.b = self.b+self.learningRate*y
wrong_num+=1
# 如果没有误分类点了则使误分类点标记为False
if wrong_num ==0:
wrong = False
print("感知机模型成功,得到的权重:" + str(self.w) + "得到的偏置:" + str(self.b))
# 分类结果(预测结果)
def predict(self,xtest):
result = [1 if (np.dot(self.w, xtest) + self.b) > 0 else -1]
print("感知机模型预测" + str(xtest) + "结果为:"+str(result))
return result
# 感知机模型得分(模型的优劣)
def score(self,xtest,ytest):
count = 0
for X,y in zip(xtest,ytest):
label = self.predict(X)
if label == y:
count+=1
print("感知机模型得分:",count/len(xtest))
if __name__ == '__main__':
PerceptronModel = PerceptronModel()
# 测试数据
# xtest = [5,4]
# 训练模型
PerceptronModel.gradientDescentFitting(X,y)
# 模型预测结果
for i in X_test:#每一个样本进行预测
PerceptronModel.predict(i)
# 训练的模型得分
PerceptronModel.score(X_test,y_test)
# 可视化( 通过感知机模型得出分类曲线)
# x_points x 轴坐标(10个点均匀分布在4-7之间)
# x_points = np.linspace(4,7,10)
#
# #y=PerceptronModel.w[0]*x_points+PerceptronModel.b,(y/w=x)
# # 这里的y是对应的x2,而x_point对应的是x1。y是根据x1反解出来的,方便画图
# # 根据感知机训练的权重与偏置来画图,负号是用来防止图像在第四象限与数据分离。
# Y = -(PerceptronModel.w[0]*x_points+PerceptronModel.b)/PerceptronModel.w[1]
#
#
# plt.plot(x_points,Y)
# # 'o'表示数据点用小圆圈表示,'bo'是蓝色小圆圈,'ro'是红色小圆圈
# plt.plot(data[:50,0],data[:50,1],'ro',label='-1')
# plt.plot(data[50:100,0],data[50:100,1],'bo',label='1')
# plt.plot(X_test[0],X_test[1], 'yo', label='test_point')
# plt.xlabel('sepal length')
# plt.ylabel('sepal width')
# plt.legend()
# plt.show()核心代码就是当y(wx+b)<=0(也就是存在误分类点时)梯度下降,更新w,b。当没有分类点时得到的w,b所确定的超平面就能将实例划分为两类。
使用sklearn库来实现感知机
import 感知机
from sklearn.linear_model import Perceptron
import numpy as np
from matplotlib import pyplot as plt
X=感知机.X
y=感知机.y
data = 感知机.data
# fit_intercept 拟合截距,max_iter最大迭代次数, shuffle顺序打乱
# 调用感知机(处理参数)
per = Perceptron(fit_intercept=False,max_iter=1000,shuffle=False)
per.fit(X,y)
#赋予特征的权重(coef:系数)
# print(per.coef_)
# (intercept)截距 Constants in decision function(决策函数常数).偏置
# print(per.intercept_)
# 预测
print("感知机模型预测结果为:",per.predict([[5,4]]))
# x坐标
x_ponits = np.linspace(4,7)
y_ = -(per.coef_[0][0]*x_ponits + per.intercept_)/per.coef_[0][1]
plt.plot(x_ponits, y_)
plt.plot(data[:50, 0], data[:50, 1], 'bo', label='-1')
plt.plot(data[50:100, 0], data[50:100, 1], 'ro', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
plt.show()总结:感知机是机器学习重要的算法之一,是svm和神经网络的基础。特别重要,核心代码不难,就是有些库,例如可视化库,自己的掌握还不够,慢慢努力。
2018-2-28
