
def forward(x, regularizer): w= b= y= return y def get_weight(shape, regularizer): w=tf.Variable() tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w)) return w def get_biase(shape): b = tf.Variable() return b



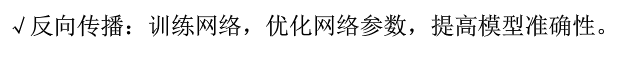
def backward( ): x = tf.placeholder( ) y_ = tf.placeholder( ) y = forward.forward(x, REGULARIZER) global_step = tf.Variable(0,trainable=False) loss =


learning_rate = tf.train.exponential_decay( LEARNING_RATE_BASE, global_step 数据集总样本数 / BATCH_SIZE, LEARNING_RATE_DECAY, staircase = True ) train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step = global_step)
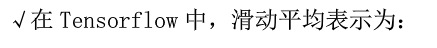
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step) ema_op = ema.apply(tf.trainable_variables()) with tf.control_dependencies([train_step, ema_op]): train_op = tf.no_op(name='train')


with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) for i in range(STEPS): sess.run(train_step, feed_dict={x: , y_: }) if i % 轮数 == 0: print