Scikit-learn 数据预处理之行范数缩放NormalizerScaler
1 声明
本文的数据来自网络,部分代码也有所参照,这里做了注释和延伸,旨在技术交流,如有冒犯之处请联系博主及时处理。
2 NormalizerScaler简介
NormalizerScaler是对样本的行进行范数缩放,主要有两种形式:
- norm="l2",按行求出每个特征的欧氏距离等于1。
- norm="l1",按行求出每个特征的绝对值距离等于1。
应用场景:有许多等价的特征时,比如文本分类里的每个单词都是一个特征时。
3 NormalizerScaler
- 示例一:
import numpy as np
from sklearn.preprocessing import Normalizer
# Create feature matrix
features = np.array([[0.5, 0.5],
[1.1, 3.4],
[1.5, 20.2],
[1.63, 34.4],
[10.9, 3.3]])
normalizer = Normalizer(norm="l2")
print(normalizer.transform(features))
L2法计算方法:
![]()
注: 1 这里是按照行(样本)求,每次取列的一个元素。
2 求的新的x之间仍保持原比例。
计算示例详解:

L1法计算方法:
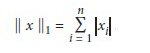
注: 1 这里是按照行求,每次取列的一个元素。
2 求的新的x之间仍保持原比例。
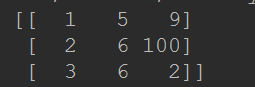
- 示例二:
import pandas as pd
from sklearn.preprocessing import Normalizer
data = pd.DataFrame(
{
'a':[1,2,3],
'b':[5,6,6],
'c':[9,100,2]
}
)
normalizer = Normalizer(norm="l2")
normalizer_data = normalizer.fit_transform(data)
print(normalizer_data)

normalizer = Normalizer(norm="l1")
normalizer_data = normalizer.fit_transform(data)
print(normalizer_data)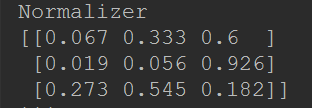
注:这里的数据矩阵形式如下: