Scikit-learn 数据预处理之标准化StandardScaler
1 声明
本文的数据来自网络,部分代码也有所参照,这里做了注释和延伸,旨在技术交流,如有冒犯之处请联系博主及时处理。
2 StandardScaler简介
StandardScaler当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的标准正态分布,该过程叫数据标准化(Standardization,又称Z-score normalization)。
应用场景:在分类、聚类、通过距离计算相似性时、使用PCA技术进行降维时。
3 StandardScaler
计算方法:
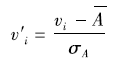
import pandas as pd
from sklearn.preprocessing import StandardScaler
data = pd.DataFrame(
{
'a':[1,2,3],
'b':[5,6,6],
'c':[9,100,2]
}
)
#标准化(StandardScaler),对列进行特征转换。
scale_x = StandardScaler()
scale_data = scale_x.fit_transform(data)
print(scale_data)
print("均值:",round(scale_data.mean()))
print("标准差:",round(scale_data.std()))
注:数据的矩阵形式如下:

计算过程示例版:
扫描二维码关注公众号,回复:
12408422 查看本文章