文章目录
C5 文件系统的实现
本章介绍一个简单的文件系统实现,称为
VSFS(Very Simple File System),它是典型的UNIX文件系统的简化版本,因此可以用它来学习一些基本磁盘结构,访问方法和各种策略
文件系统是纯软件,与CPU虚拟化和内存虚拟化不同,对于文件系统不会添加硬件功能以提升效率,由于文件系统具有很大的灵活性,人们构建了许多不同的文件系统,所有这些文件系统都有不同的数据结构,在某些方面优于或劣于同类系统
5.1 关于文件系统的两个问题
理解文件系统时,需要考虑它们的两个不同方面:
1,文件系统的数据结构,即文件系统在磁盘上采用哪些类型的数据结构来组织其数据和元数据?较为简单的文件系统(如VSFS)采用简单的数据结构,如块和其它对象的数组,而复杂些的文件系统(如XFS)使用更复杂的基于树的结构
2,访问方法,即如何将进程发出的调用,如open(),read(),write()等映射到它的数据结构上?在执行特定系统调用期间读取哪些结构?改写哪些结构?这些步骤的执行效率如何?
5.2 VSFS的整体组织
现在开发VSFS文件系统在磁盘上的数据结构的整体组织:
(1) 将磁盘分成块
简单的文件系统只使用一种块大小,这里也是这样,块大小选择4KB,对于构建简单文件系统的磁盘分区的做法很简单,即将磁盘看成线性的一些块,每块大小为4KB
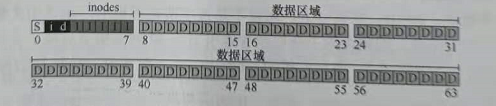
在大小为N个4KB块的分区中,这些块的地址从0~N-1,假设有一个非常小的磁盘,只有64块:

(2) 用户数据的存放:数据区域
有了一系列等大的线性块后,接着要像其中存储数据,首先是用户数据,任何文件系统中大多数空间都应该是用户数据,将用于存放用户数据的磁盘区域称为数据区域,这里将最后56个块作为数据区域:

(3) 记录每个文件的详细信息:inode表
文件系统必须记录每个文件的信息,该信息是
元数据(除了用户数据外的信息统称为元数据)的关键部分,并且记录了文件中包含哪些数据块,文件的大小,文件的所有者和访问权限,访问和修改时间等类似的详细信息,为了存储这些信息,文件系统有一个名为inode的结构
为了存放inode,还需要在磁盘上留出一些空间,称这部分磁盘空间为inode表,它只是保存了一个磁盘上inode的数组,假设inode表大小为5个块,磁盘看起来如下:

(4) 空闲空间的记录:位图
目前为止,文件系统有了数据块和inode表,但是还需要某种方法记录inode或数据块是空闲还是已分配,因此这种分配结构是所有文件系统中必需的部分
存在很多可行的分配方法,如采用空闲列表,指向第一个空闲块,然后它又指向下一个空闲块,这里采用一种简单又流行的结构
位图(位图是一种简单的结构,每个位用于指示相应的块是否空闲),一种用于数据区域,一种用于inode表
新的磁盘布局如下:

(5) 文件系统信息的存储:超级块
对于上述的磁盘布局,还有一块,这块留给超级块,超级块包含关于该特定文件系统的信息,包括例如文件系统中有多少个inode和数据块,inode表的开始位置,还可能包括一些幻数用来标识文件系统的类型(如VSFS)
因此,在挂载文件系统时,操作系统将首先读取超级块,初始化各种参数,然后将该卷添加到文件系统中,当卷中的文件被访问时,系统就会知道在哪里查找所需的磁盘上的结构
5.3 文件组织:inode(index node 索引节点)
文件系统最重要的磁盘结构之一是inode,几乎所有的文件系统都有类似的结构,用于描述保存给定文件的元数据的结构,如其长度,权限及组成块的位置,inode是index node的缩写,因为这些节点最初放在一个数组中,在访问特点inode时会用到该数组
(1) inode结构寻址
每个inode都由一个数字隐式引用,也称为文件的低级名称,如在VSFS中,给定一个文件低级名称,应该可以计算出该文件的inode结构在磁盘上的位置,根据之前的磁盘结构,假设inode表为20KB,因此最多存在80个inode结构,假设inode表从12KB开始,读取inode号32号:

文件系统首先开始计算inode区域的偏移量
(32*inode的大小1/4KB = 8192B),
将它加上磁盘inode表的其实地址(12KB),从而得到20KB
inode号为32的inode结构
(2) inode结构中的内容
在每个inode中,实际上是关于对应文件的所有信息:文件类型,大小,所得数据块数,权限,时间信息等

(3) 多级索引
设计inode时,最重要的决定之一是它如何引用数据块的位置,一种简单的方法是在inode中有一个或多个直接指针,每个指针指向属于该文件的一个磁盘,但当面对大文件时,直接指针不能满足需要:

如上所述,当文件足够大时,分配一个间接块里面存储指向文件的块的指针,而inode结构中的间接指针则指向这个块,如果想支持更大的文件,可以使用双重间接指针,双重间接指针允许访问最大为102410244KB的文件,即所支持访问的文件大小超过了4GB,如果不够,还可以使用三重间接指针
许多文件系统使用多级索引,包括常用的文件系统,Linux的ext2和ext3,以及原始的UNIX等,多级索引的机制能让inode直接指向较小的文件,也可以通过一个或多个间接块指向大文件
5.4 目录组织
在VSFS中,目录的组织很简单,
一个目录基本上只包含一个二元组(条目名称,inode号)的列表
加上dir中有3个文件,dir在磁盘上的数据可能如下显示:
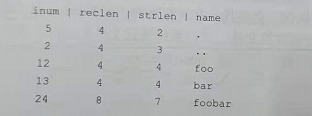
每个目录都有两个额外的条目,.(当前目录 dir) 和 …(父目录 /)
通常文件系统将目录视为特殊类型的文件,目录有一个inode,位于inode表,该目录也有inode指向的数据块,这些数据块存在于我们简单文件系统的数据区域中
这个简单的线性目录列表并不是存储这些信息的唯一方法,任何数据结构都是有可能的,如XFS文件系统采用B树来存储目录,使文件创建操作快于使用简单列表的文件系统
5.5 空闲空间管理
文件系统必须要记录哪些inode和数据块是空闲的,哪些不是,这样在分配文件或目录时,就可以为它找到空间,空闲空间管理对于所有文件系统都很重要,VSFS采用两个位图来完成
当创建一个文件时,必须为该文件分配一个inode,文件系统将通过位图来搜索一个空闲的inode结构并分配个该文件,文件系统将该inode结构标记为已经使用(位图中置1)
接着分配数据块时,大致是相同的,不过是根据数据块位图来寻找空闲空间,但是一些LInux文件系统在创建文件并需要数据块时,会寻找一系列数据块,通过查找一系列的数据块,将它们分配给创建的文件,文件系统保证该文件的一部分在磁盘上是连续的,从而提高性能,这种预分配策略,是为数据块分配空间时的常用方法
5.6 访问路径:读取和写入
现在已经解决了第一个问题文件系统的数据结构,知道了文件和目录如何存在于磁盘上,接着考虑第二个问题,进程如何访问这些文件
对于下面的例子,假设文件系统已挂载,超级块已经处于内存中,其它内容(inode,目录,用户数据)仍在磁盘上
(1) 从磁盘读取
假设要打开一个文件(如/foo/bar,该文件只有4KB),读取后并关闭
第一步发出一个open("/foo/bar", O_RDONLY)调用时,文件系统先要找到文件bar的inode,从而获取该文件的一些基本信息(权限,大小,数据块位置等),为此文件系统必须要找到bar的inode,但现在只给了路径名,文件系统必须遍历路径名,以找到bar的inode
第二步开始遍历,从根目录 / 开始,文件系统第一次磁盘读取是根目录的inode,根的node号必须是众所周知的,通常在Linux中,根的inode为2,因此一开始会读入inode号为2的块
第三步,有了根的inode,文件系统根据inode中指向数据块的指针来查找条目foo,一旦找到,文件系统也会找到下一个需要的foo的inode号
第四步,递归遍历路径名,直到找到所需的inode,本例中,文件系统读取包含foo的inode及其目录的数据的块,最后找到bar的inode
第五步,open()将bar的inode读入内存,然后文件系统对它进行最后的权限检查,在每个进程的打开文件表中,为此进程分配一个文件描述符,并将它返回给用户
第六步,发出read()调用,从文件中读取,第一次读取将在文件的第一个块中,读取将进一步更新此文件描述符在内存中的打开文件表,更新文件偏移量,以便下一次读取会读取第二个文件块
第七步,关闭文件,文件描述符被释放
整个过程中,打开文件导致了多次读取,以便找到目标文件的inode,之后,读取每个块需要文件系统先查询inode,然后读取该块,再使用写入更新inode的最后访问时间字段
open()导致的I/O量与路径长度成正比,对于路径中每个增加的目录,都需要读取它的inode及其数据,更糟的是会出现大型目录,对于大型目录需要读取更多的块
(2) 向磁盘写入
写入文件是一个类似的过程,首先文件必须被找到且打开,其次应用程序可以发出write()调用以更新文件内容,最后关闭文件
与读取不同,写入文件时可能会分配一个块,当写入一个新文件时,每次的操作不仅要将数据写入磁盘,还要先先决定将那个块分配给文件,从而更新磁盘的其它结构(数位图,inode表),因此每次写入文件在逻辑上有5个I/O:
1,一个读取数据位图
2,一个写入位图
3,读取inode
4,写inode
5,写入数据块
创建一个文件的工作量比向已存在的文件中写数据更大,要创建一个文件,文件系统不仅要分别配一个inode,还要在包含新文件的目录中分配空间,这样的I/O总量非常大
5.7 缓存和缓冲
(1) 减少读的I/O:缓存
读取和写入文件是昂贵的,会导致磁盘有很多I/O,因此降低性能,为了弥补这个问题,
大多数文件系统积极使用系统内存 DRAM来缓存重要的块
想象一个有缓存的文件打开的例子,第一次可能引起很多I/O,来读取目录中的inode和数据,但是随后打开该文件,大部分会命中缓存,因此不需要或只进行少量I/O
(2) 减少写的I/O:缓冲
尽管可以通过足够大的缓存来避免读取/O,但写入操作必须进入磁盘,高速缓存不能减少写流量,可以通过写缓冲来弥补,首先,通过延迟写入,文件系统可以将零碎的一些更新积攒成一批,放入一组较小的I/O中,通过减少写I/O的次数来减少写I/O引起的问题
如果一在创建一个文件时,inode位图被更新,稍后再创建另一个文件时又被更新,则文件系统可以再第一次更新后延迟写入,从而节省一次I/O,其次,通过将一些写入缓冲的内存中,系统可以调度后续的I/O,从而提高性能
由于上述原因,大多数现代文件系统将写入在内存中缓冲5~30s,这代表了另一种折中,如果系统在更新传递到磁盘之前崩溃,更新就会丢失,但是如果时间延长,则可以通过批处理,调度甚至避免写入来提高性能,而像数据库管理系统这种软件不喜欢这种折中,它会调用fsync()立刻强制写入磁盘,以保证数据更新不会丢失
5.8 小结
构建一个文件系统需要有关每个文件的一些详细信息,这通常存储在名为inode的结构中,目录只是”存储名称->inode号“映射的特定类型的文件,还需要诸如位图的结构来记录inode或数据块是空闲的还是已分配了的