文章目录
C7 常见的并发问题
7.1 有哪些类型的缺陷
并发缺陷有很多常见的模式,了解这些模式是写出健壮,正确程序的第一步
在4个重要的开源应用中,研究人员检查了这几个应用已经修复的并发缺陷,主要分为两类,非死锁缺陷和死锁缺陷
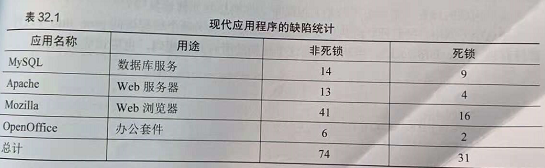
共有105个缺陷,其中大多数是非死锁缺陷,剩下的是死锁缺陷,对于第一类的非死锁缺陷,通过该研究的例子来讨论,对于第二类死锁缺陷,讨论人们在阻止,避免和处理死锁上完成的大量工作
7.2 非死锁缺陷
非死锁缺陷主要分为两类:违反原子性缺陷和违反顺序缺陷
(1) 违反原子性缺陷
MySQL中曾经出现的一个问题:
Thread 1:
if(thd->proc_info) {
...
fputs(thd->proc_info, ...);
...
}
Thread 2:
thd->proc_info = null;
在这个例子中,两个线程都要访问thd结构体中的成员proc_info,第一个线程检查proc_info非空,然后打印出值,第二个线程将设置proc_info为空,当第一个线程在调用fputs()前被中断,第二个线程将proc_info设置为空后,第一个线程恢复执行后,由于引用了空指针,会导致程序的崩溃
更正式的违反原子性缺陷的定义是:违反了多次内存访问中预期的可串行性(即代码段本意是原子性的,但在执行中没有强制实现原子性)
对于上述的例子,解决很简单,只需要给共享变量的访问加锁即可,确保每个线程访问proc_info时都持有锁:
pthread_mutex_t proc_info_lock = PTHREAD_MUTEX_INITIALIZER;
Thread 1:
pthread_mutex_lock(&proc_info_lock);
if(thd->proc_info) {
...
fputs(thd->proc_info, ...);
...
}
pthread_mutex_unlock(&proc_info_lock);
Thread 2:
pthread_mutex_lock(&proc_info_lock);
thd->proc_info = null;
pthread_mutex_unlock(&proc_info_lock);
(2) 违反顺序缺陷
另一种常见的非死锁缺陷是违反顺序缺陷,观察下面的代码:
Thread1:
void init() {
...
mThread = PR_CreateThread(mMain, ...);
...
}
Thread2:
void mMain(..) {
...
mState = mThread->State;
...
}
对于上述的两个线程,线程2中的代码假定mThread已经被初始化了(不为空),然而如果线程1没有先于线程2执行,那么线程2就可能因为引用空指针崩溃
违反顺序缺陷更正式的定义是:两个内存访问的预期顺序被打破了(即A应该先于B执行,但实际运行中却不是这个顺序)
对于上述的例子,解决顺序缺陷可以依靠条件变量来控制顺序:
pthread_mutex_t mtLock = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t mtCond = PTHREAD_COND_INITIALIZER;
Thread1:
void init() {
...
mThread = PR_CreateThread(mMain, ...);
pthread_mutex_lock(&mtLock);
mtInit = 1;
pthread_cond_signal(&mtCond);
pthread_mutex_unlock(&mtLock);
...
}
Thread2:
void mMain(..) {
...
pthread_mutex_lock(&mtLock);
//只有当线程1执行过后,将mtInit的值初始化后
//线程2才能进行,否则自旋
while(mtInit == 0) {
pthread_cond_wait(&mtCond, &mtLock);
}
pthread_mutex_unlock(&mtLock);
mState = mThread->State;
...
}
(3) 非死锁缺陷的小结
大部分(97%)的非死锁问题是违反原子性和违反顺序这两种,因此在并发编程中对这两种缺陷模式要仔细考量避开,此外随着更自动化的代码检查工具的发展,他们也应该关注这两种错误,因为开发中的非死锁问题大部分是这两种
7.3 死锁缺陷
死锁是一种在许多复杂并发系统中出现的经典问题,当线程1持有锁L1,正在等待另一个锁L2,而线程2持有锁L2,却在等待锁L1释放时,死锁就产生了

当线程1占有锁L1,上下文切换到线程2,线程2获得锁L2,试图获得L1,这时就产生了死锁,两个线程相互等待
(1) 为什么发生死锁
其中的一个原因是因为在大型的代码库内,组件之间会有复杂的依赖,以操作系统为例,虚拟内存系统在需要访问文件系统才能从磁盘读到内存页,文件系统随后又要和虚拟内存交互,去申请一页内存,以便存放读取到的块,因此在设计大型系统的锁机制时,必须仔细地避免循环依赖导致的死锁
第二个原因是封装,软件开发者一直倾向于隐藏实现细节,以模块化的方式让软件开发更容易,然而模块化和锁不是很契合,某些看起里没有关系的接口可能会导致死锁
(2) 产生死锁的条件
产生死锁要满足4个条件:
1,互斥:线程对于需要的资源进行互斥的访问(一个线程抢到锁)
2,持有并等待:线程持有了资源(已持有的锁),同时又在等待其它资源(需要获得的锁)
3,非抢占:线程获得的资源(锁),不能被抢占
4,循环等待:线程之间存在一个环路,环路上每一个线程都额外持有一个资源,而这个资源又是下一个线程要申请的
这4个条件如果有一个没有被满足,那么死锁就不会产生
(3) 预防死锁
1,顺序加锁:避免死锁循环等待最直接的方法就是获取锁时提供一个全序,假如系统有两个锁L1和L2,那么每次都先申请L1再申请L2,就可以避免死锁,这样严格的顺序避免了循环等待,也就不会出现死锁
当然更复杂的系统中不会只有两个锁,锁的全序可能很难做到,因此偏序可能是一种有用的方法,安排锁的获取并避免死锁,但全序和偏序都需要细致的锁策略的设计和实现
2,原子地抢占锁:死锁的持有并等待条件,可以通过原子地抢锁来避免
lock(prevention);
lock(L1);
lock(L2);
...
unlock(prevention);
当抢到prevention这个锁后,代码保证了在抢锁地过程中,不会有不合时宜地线程切换,从而避免了死锁,但它不适用于封装,且因为要提前抢到所有锁,而不是在真正需要地时候,所以可能降低了并发
3,利用硬件指令避免互斥:通常来说,代码都会存放在临界区,因此很难避免互斥,有人提出了设计各种无等待数据结构的思想,想法很简单,通过强大的硬件指令,可以构造出不需要锁的数据结构
如有比较交换指令,是由硬件提供的原子指令:
int CompareAndSwap(int *address, int expected, int new) {
if(*address == expected) {
*address = new;
return 1;
}
return 0;
}
这样直接由硬件提供的原子指令无需获取锁,更新值,释放锁,使用类似地指令完成任务,由于没有使用锁,所以就不会出现死锁问题
(4) 通过调度避免死锁
除了预防死锁,某些场景更应该避免死锁,我们需要了解全局的信息,包括不同线程在运行中对锁的需求情况,从而使得后续通过调度线程避免产生死锁
如,在两个处理器上调度4个线程,假设线程1需要锁L1,L2,线程2需要L1和L2,线程3需要锁L2,线程4不需要锁

通过合理的调度也能避免死锁的出现,只要线程1和线程2不同时运行,就不会产生死锁:

线程3可以和线程1或者线程2重叠,虽然线程3会抢占锁L2,但由于它只用到一把锁,和其它线程并发执行都不会产生死锁
(5) 检查和恢复
最后一种策略就是允许死锁偶尔发生,如果死锁很少见,这种办法也很实用,很多数据库系统采用了死锁检测和恢复技术,死锁检测器会定期运行,通过构建资源图来检查循环,当死锁发生时,系统需要重启,如果还需要更复杂的数据结构相关的修复,那么需要人工参与