一、概述
本篇文章作为Flink的TableAPI&SQL的入门案例,在TableAPI自定义UDF函数,继承了TableFunction()函数来实现WordCount单词统计,这里只做了简单的实现,让你对TableAPI&SQL有一个简单的认识。
二、代码实战
1.pom依赖,这里只贴了新引用的依赖:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java-bridge_2.11</artifactId> <version>1.10.0</version></dependency><dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-scala-bridge_2.11</artifactId> <version>1.10.0</version></dependency><dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-common</artifactId> <version>1.10.0</version></dependency><dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner_2.11</artifactId> <version>1.10.0</version></dependency><dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner-blink_2.11</artifactId> <version>1.10.0</version></dependency>
2.自定义UDF函数,代码如下:
package com.hadoop.ljs.flink110.tableApi;import org.apache.flink.api.common.typeinfo.TypeInformation;import org.apache.flink.api.common.typeinfo.Types;import org.apache.flink.table.functions.TableFunction;import org.apache.flink.types.Row;/** * @author: Created By lujisen * @company ChinaUnicom Software JiNan * @date: 2020-05-06 16:10 * @version: v1.0 * @description: com.hadoop.ljs.flink110.tableApi */public class UDFWordCount extends TableFunction<Row> { /*设置返回类型*/ @Override public TypeInformation<Row> getResultType() { return Types.ROW(Types.STRING, Types.INT); } /*消息处理*/ public void eval(String line){ String[] wordSplit=line.split(","); for(int i=0;i<wordSplit.length;i++){ Row row = new Row(2); row.setField(0, wordSplit[i]); row.setField(1, 1); collect(row); } }}
3.主函数,代码如下:
package com.hadoop.ljs.flink110.tableApi;import org.apache.flink.api.common.functions.FilterFunction;import org.apache.flink.api.common.typeinfo.Types;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.table.api.EnvironmentSettings;import org.apache.flink.table.api.Table;import org.apache.flink.table.api.java.StreamTableEnvironment;import org.apache.flink.types.Row;/*** @author: Created By lujisen* @company ChinaUnicom Software JiNan* @date: 2020-05-06 15:55* @version: v1.0* @description: com.hadoop.ljs.flink110.tableApi*/public class WordCountByTableAPI {public static void main(String[] args) throws Exception {// FLINK STREAMING QUERY tableAPI执行环境初始化EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);DataStream<String> sourceDS = fsEnv.socketTextStream("localhost", 9000);Table table = fsTableEnv.fromDataStream(sourceDS,"inputLine");// 注册自定义UDF函数fsTableEnv.registerFunction("wordCountUDF", new UDFWordCount());Table wordCount= table.joinLateral("wordCountUDF(inputLine) as (word, countOne)").groupBy("word").select("word, countOne.sum as countN");/*table 转换DataStream*/DataStream<Tuple2<Boolean, Row>> result = fsTableEnv.toRetractStream(wordCount, Types.ROW(Types.STRING, Types.INT));/*统计后会在 统计记录前面加一个true false标识 这里你可以注释掉跑下看看 对比下*/result.filter(new FilterFunction<Tuple2<Boolean, Row>>() {@Overridepublic boolean filter(Tuple2<Boolean, Row> value) throws Exception {if(value.f0==false){return false;}else{return true;}}}).print();fsEnv.execute();}}
4.函数测试:
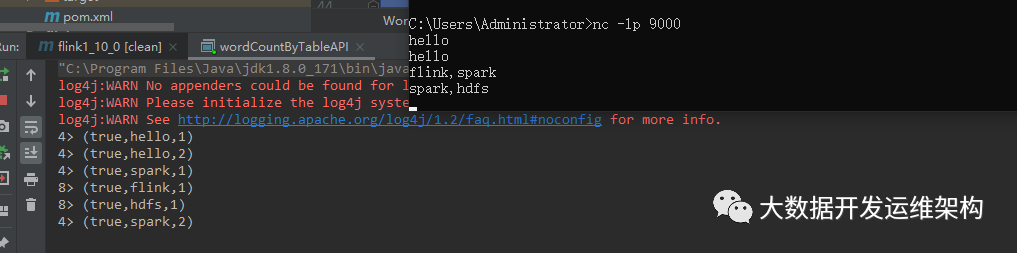
后续我们会常用的几个自定义函数的抽象类和接口简单给大家介绍一下,这里只做一个入门程序。