课程目录 小象学院 - 人工智能
关注公众号【Python家庭】领取1024G整套教材、交流群学习、商务合作。整理分享了数套四位数培训机构的教材,现免费分享交流学习,并提供解答、交流群。
你要的白嫖教程,这里可能都有喔~
恭喜你闯进了第13关,让我们继续探索人工智能的奥秘,体验算法的魔力Amazing~

场景引入
本关我们要学习的机器学习算法是决策树,决策树是最经典的机器学习算法之一。
我们从这个算法的名字应该可以猜出一些端倪了,这个算法应该是跟树型结构有关系,还有就是它解决应该是分类问题。
为什么说决策树解决的是分类问题呢?因为“决策”这俩字就让我想起了公司领导拍脑门做决策。 比如,有一天公司的品牌负责人找到公司老板,跟老板说:老板我遇到一个问题不知道怎么解决,需要您做下决策。 老板:什么问题。 品牌总监:咱们公司在做品牌宣传的时候,应该把公司定位在哪个领域呢? 老板:都有哪些领域可以选?现在什么领域最火? 品牌总监:可选的领域有物联网、大数据、人工智能,现在最火的是人工智能。 老板:这还用想,拍脑门都知道应该定位在人工智能领域。 品牌总监:好嘞,我明白啦,咱们公司确实是 人工 + 智能! 老板:没毛病!
通过上面的小故事,你应该能够对决策树算法有一个简单的认识,当遇到分类问题的时候,可以尝试使用决策树解决。
我们来继续研究决策树,慢慢地把决策树学明白。
你相信读心术吗?我通过问你几个问题就能猜出你明天去干嘛?
听起来是不是很玄乎?其实道理很简单,我给你画个树状图你一看就明白了^_^
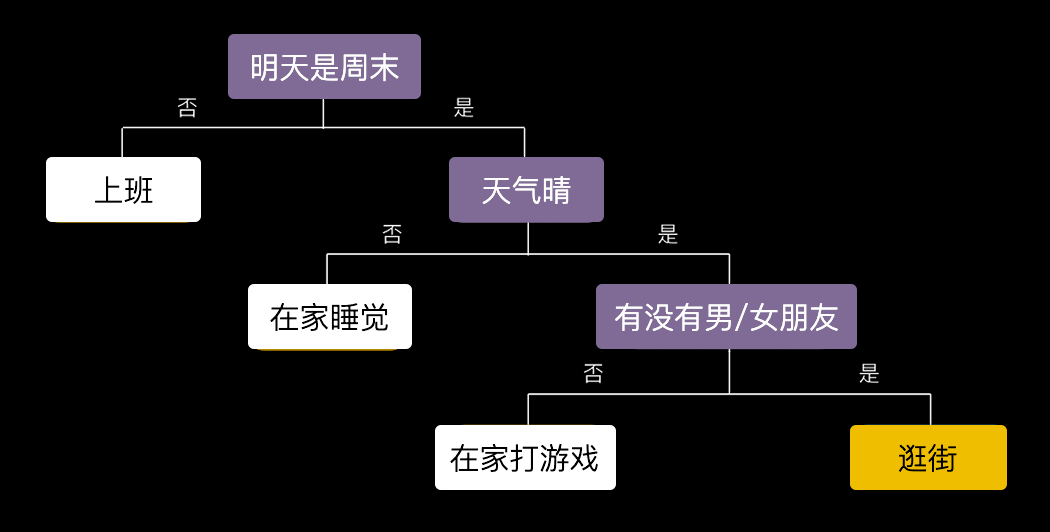
我采取的策略是从一个根问题开始,根据你的回答不停地进行分支,然后细化我的问题,直到得出一个答案为止。
案例:手机应用推荐
像这种由浅入深、层层递进的决策过程是非常直观的,下面我们再来看一个更加具体的例子给新用户推荐下载的手机App,进而引出决策树的概念。
假设我们现在有一些用户下载过的手机应用(App)的记录,如下所示,每条记录分别包含了用户的性别、年龄以及该用户下载过的App:

我们要做的事情是:给新用户推荐下载的手机App,怎么推荐呢?这就要分析历史用户的App下载数据,看看有没有什么特点和规律,然后根据新用户的特征给他/她推荐一款App下载。
我们通过观察上图中历史用户下载App的数据发现用户有两个特征:性别和年龄,那我们可以大胆猜测下,不同性别或者不同年龄的人下载App的偏好会不会不同呢?
按性别分类
那我们先按照性别把App的下载记录划分开,看看有什么样的效果?
提示:蓝色背景色的是女性用户下载App的记录,黄色背景色的是男性用户下载App的记录。

我们按照性别这种划分方法分析一下:男生里有的下载了王者荣耀,有的下载了QQ;女生里有的下载了微信,有的下载了王者荣耀。这种划分方法貌似没有太好地把用户和App之间的关系清晰的划分开。
按年龄分类
我们再按照年龄把App的下载记录划分开,年龄大于等于20岁的分为一组,年龄小于20岁的分为一组,看看划分之后的效果如何?
提示:绿色背景色的是年龄小于20岁的用户下载App的记录,红色背景色的是年龄大于等于20岁的用户下载App的记录。

我们再按照年龄这种划分方法分析一下:低于20岁的用户都下载的是王者荣耀;高于20岁的男生下载了微信,女生下载了QQ。这种划分方法看上去是对现有数据是一个非常不错的划分!
通过上面的分析,我们可以给出这样的决策规则:当有新的用户,先询问用户年龄是否低于20岁,如果是,则预测会下载王者荣耀,推荐给用户下载;如果不是,再询问其性别,若为女生,则预测会下载微信,若为男生,则预测会下载QQ。如下图所示:

最终,我们根据上面的分析,针对已有的6条历史用户下载App的数据构建出一棵决策树。一旦有新用户要下载App,就可以利用这棵决策树进行预测。
例如,新来一个24岁的女生,根据决策树的决策规则首先判断她的年龄大于20岁,然后再判断她的性别是女性,那么通过决策树预测她会下载微信,那我们就把微信这个App推荐给她下载。
学到这里,相信你学习的还算顺利,但你可能会有这样的担忧:在这个例子中,只有性别和年龄2个特征,只有6条样本数据,所以我们可以通过观察来给出决策规则。一旦特征和数据的数量增多,使用观察法就行不通了。比如历史用户下载App的记录中有10个用户特征,10亿条下载记录,这种情况用观察法就没法直接观察出决策规则。
构建决策树的通用方法
如果能有一种更加通用的方法来构建决策树,那将会多么美妙!
为了找到这种通用的方法,我们再回头分析一下推荐下载APP这个例子,在预测新用户可能会下载哪个App的时候,我们问了两个问题,年龄是否小于20岁和性别是否是女生。
请你思考一下:为什么要把“年龄是否小于20岁”作为第一个问题?换句话说,这两个问题的提问顺序可以改变么?
之所以把“年龄是否小于20岁”作为第一个问题,是因为这个问题可以最大程度地缩小答案的范围,为什么这么说呢?因为20岁以下的用户下载的App只有一个王者荣耀,只要来一个新用户他/她的年龄小于20岁就直接推荐下载王者荣耀,这是一个非常肯定的结果,直接把范围缩小到了最终的结果,缩小到了终点。
如果把“性别是否是女生”作为第一个问题,当一个新用户来了不管是男生还是女生,回答完第一个问题后,都还要再回答第二个问题才能得出推荐下载的App,相对于把“年龄是否小于20岁”作为第一个问题,这种方式缩小答案的范围就没有那么小了。
“最大程度地缩小答案的范围”换一种说法就是“最大程度地减少答案的不确定性”,因为我们更希望得到的是肯定的答案,以简单快速的方法锁定最终结果,所以最大程度地减少答案的不确定性就是我们做每一步决策所遵循的基本原则。
既然我们选择问题的目的是最大程度地减少答案的不确定性,那么目前的不确定性是多少?要减少到什么?没有个度量的方法。
信息量
接下来我们就要寻找用什么方法可以对“不确定”的信息进行度量?
我们知道刘翔跑110栏用时12秒88打破世界纪录,12秒88就是对时间的度量,时间的度量我们经常会用小时、分钟、秒来度量。
那么针对信息的度量,也有类似时、分、秒这样的度量单位,它就是信息量,用信息量可以度量信息的大小。
信息量的大小跟一个随机事件发生的概率有关,事件发生的概率越小,该事件产生的信息量越大;事件发生的概率越大,该事件产生的信息量越小。
例如:2008年汶川发生的8.0级大地震,当时我们每个人听到这个消息都非常吃惊,因为发生地震是个小概率事件,8.0级的大地震更是非常小的小概率事件,所以汶川发生8.0级地震这条信息的信息量非常大。
例如:我非常兴奋地告诉你:“太阳从东方升起”,你肯定会觉得我有病。因为地球人都知道太阳从东方升起,是一个肯定发生的事件,所以这条信息没有什么信息量。

我们将信息量用H来表示,一个事件出现的概率用p来表示,借用前面的给新用户推荐下载App的例子解释一下:

总数据量:6条数据
我们把下载王者荣耀定义为事件1,在总的下载记录中事件1有3条记录,所以事件1出现的概率 ![]()
我们把下载微信定义为事件2,在总的下载记录中事件2有2条记录,所以事件2出现的概率![]()
我们把下载QQ定义为事件3,在总的下载记录中事件3有1条记录,所以事件3出现的概率![]()
上面我介绍了信息量H和事件出现的概率p成反比,为了清晰地表达它们之间的关系,我们可以寻找一个单调递减的函数来表达二者之间的关系,这让我们想起了之前讲逻辑回归的时候用到的y=-log(x)的曲线图,y随x的增大而减小。

我们知道概率的取值范围是:[0,1],所以要把y=-log(x)曲线中x>1的部分截掉。

前面我们举了个太阳从东方升起的例子,这是个肯定发生的事件,几乎没有什么信息量,它的信息量就是0,这是信息量的最小值了,所以信息量会大于等于0。
我们再观察下y=-log(x),x取值区间:[0,1],满足信息量H随着事件发生的概率增加而减小的规律,而且y值是大于等于0的,所有条件都满足,那么我们就可以将信息量H和事件出现的概率p用y=-log(x)表示:![]()
我们在日常使用的时候,一般会使用2作为公式中对数log的底数![]() ,你肯定会问为什么以2为底呢?
,你肯定会问为什么以2为底呢?
这是因为,我们只需要信息量满足低概率事件对应的信息量高,高概率事件对应的信息低就行了,那么对数的底数选择是任意的,至于你用2还是用10做底数没关系,2只是一个常用的底数而已。
有了信息量H与事件发生概率P的表达式![]() ,我们就可以对前面推荐下载App的例子计算信息量了。
,我们就可以对前面推荐下载App的例子计算信息量了。
推荐下载App例子,没有按照特征划分之前的信息量计算过程:
事件1(下载王者荣耀)的信息量为 ![]()
事件2(下载微信)的信息量为 ![]()
事件3(下载QQ)的信息量为 ![]()
信息熵
在了解了信息量的定义之后,就可以引出信息熵这个概念了。信息量是对一个具体事件发生产生的信息的度量,而信息熵则是在结果出来之前对所有可能发生事件产生的信息所带来的平均信息量。
信息熵用Entropy表示,那么信息熵的表达式是:![]()
公式中的n表示有n个可能发生的事件,![]() 是第i个事件发生的概率。
是第i个事件发生的概率。
我们来计算下上面推荐下载App例子没有按照特征划分之前的信息熵:
可能发生3个事件:下载王者荣耀、下载微信、下载QQ,所以信息熵计算公式中的n=3。
![]()
![]()
我们知道信息量越大,事件发生的概率越低,那么事件发生的不确定性就越高。同理,信息熵越大,则不确定性越高;信息熵越小,则不确定性越低。
我们再通过两个例子加深对信息熵的理解:
假设某个数据集一共有两种类别,标签为{0,1,1,0,1,0,1,0},即 ![]() ,
,![]() ,则该数据集的信息熵为
,则该数据集的信息熵为 ![]() 。
。
假设某个数据集一共有两种类别,标签为{0,0,0,0,0,0,0,0},即 ![]() ,
,![]() ,则该数据集的信息熵为
,则该数据集的信息熵为 ![]() 。
。
可以看出,当数据集中两种类别的样本分布比较均匀时,不确定性是最高的,信息熵也最大;当数据集中只有一种类别的样本,此时没有不确定性,信息熵最小,为0。
本关总结:在本关,我们先从直观上了解了什么是决策树,然后介绍了对“不确定性”进行度量的方法。有了这些内容的铺垫,我们在下一关将教会你“如何构建一棵决策树”,是不是很期待?
今天我们就先学到这里吧,下一关见,拜拜~
联系我们,一起学Python吧
分享Python实战代码,入门资料,进阶资料,基础语法,爬虫,数据分析,web网站,机器学习,深度学习等等。
 关注公众号「Python家庭」领取1024G整套教材、交流群学习、商务合作
关注公众号「Python家庭」领取1024G整套教材、交流群学习、商务合作