创建、管理、增删改表
创建和管理表
标识符命名规则

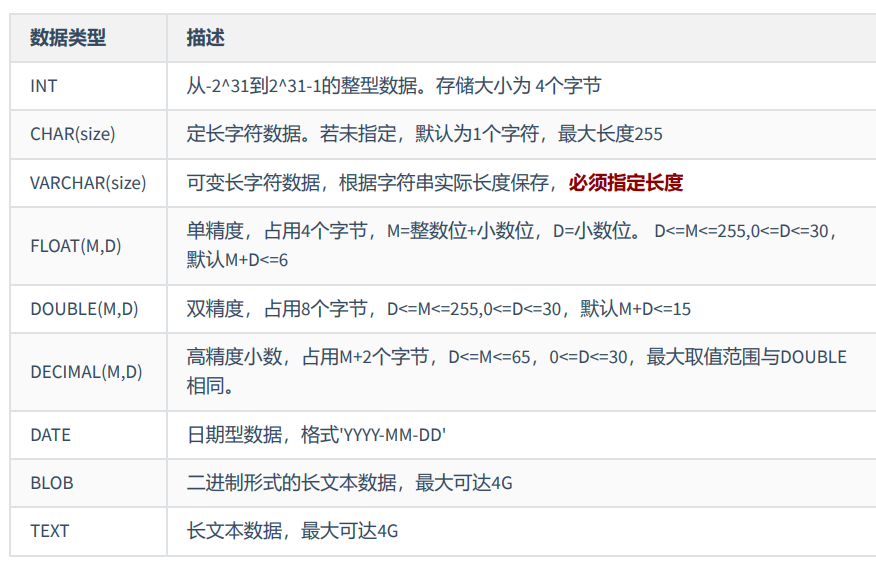
MySQL中的数据类型
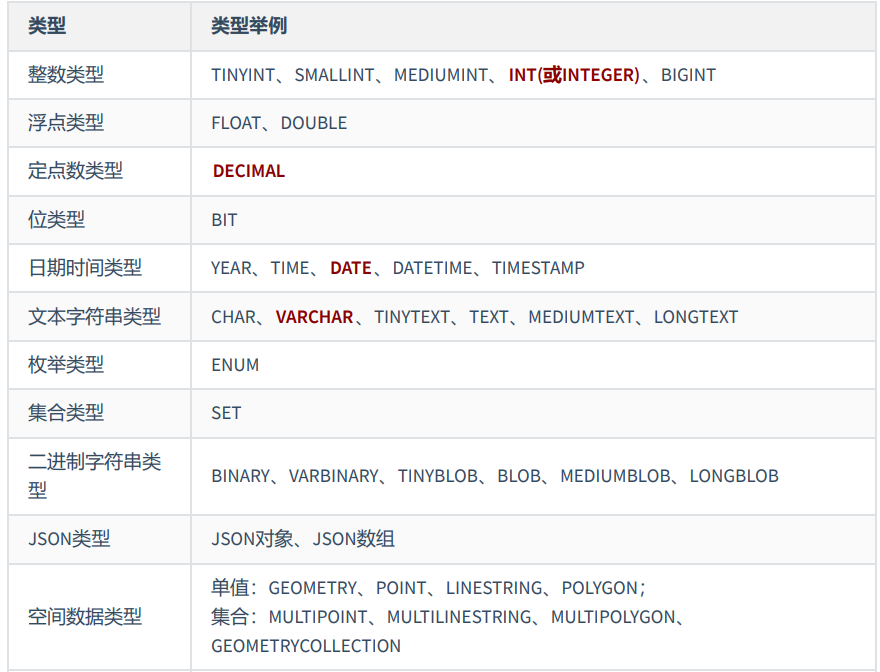
其中,常用的几类类型介绍如下:
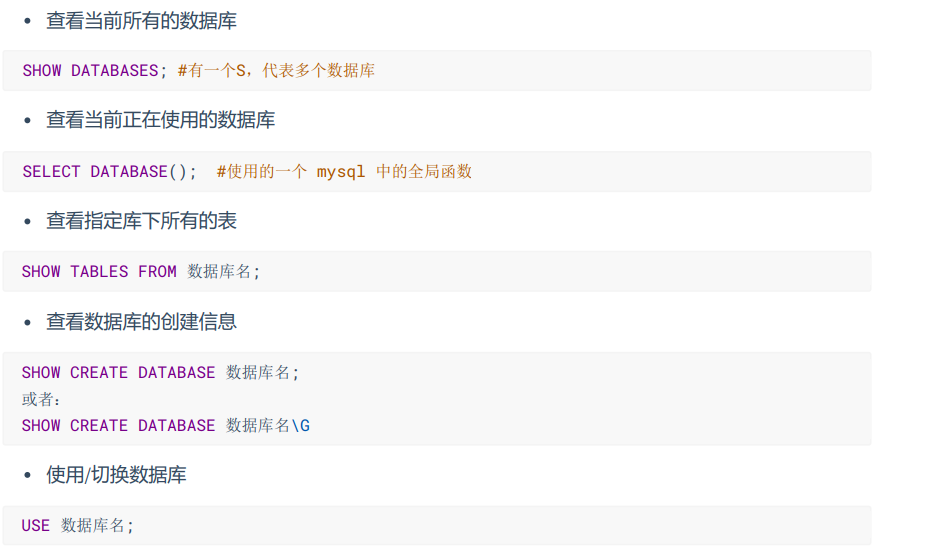
操作数据库
更改数据库字符集
ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
删除数据库
方式1:删除指定的数据库
DROP DATABASE 数据库名;
方式2:删除指定的数据库( 推荐 )
DROP DATABASE IF EXISTS 数据库名;
查看数据表结构
mysql> show create table test2\G
创建数据库
-
创建数据库
CREATE DATABASE 数据库名; CREATE DATABASE db1; -
创建数据库并指定字符集
数据库默认字符集为拉丁,不能识别中文
CREATE DATABASE 数据库名 CHARACTER SET 字符集; CREATE DATABASE db2 CHARACTER SET utf_8; -
判断数据库是否存在相关的数据库,不存在则创建数据库(推荐使用)
CREATE DATABASE IF NOT EXISTS 数据库名; CREATE DATABASE IF NOT EXISTS db3;数据库的名字创建后是不能改名的,一些可视化工具是可以直接改名的
这些工具其实是建立了新库删除旧库,然后把数据拷贝过去完成的
使用数据库
比较常见,这里直接截图了
创建表
创建方式1
CREATE TABLE [IF NOT EXISTS] 表名(
字段1, 数据类型 [约束条件] [默认值],
字段2, 数据类型 [约束条件] [默认值],
字段3, 数据类型 [约束条件] [默认值],
……
[表约束条件]
);
加上了IF NOT EXISTS关键字,则表示:如果当前数据库中不存在要创建的数据表,则创建数据表; 如果当前数据库中已经存在要创建的数据表,则忽略建表语句,不再创建数据表。
必须指定: 表名 列名(或字段名),数据类型,长度
可选指定: 约束条件 默认值
示例
-- 创建表
CREATE TABLE emp (
-- int类型
emp_id INT,
-- 最多保存20个中英文字符
emp_name VARCHAR(20),
-- 总位数不超过15位
salary DOUBLE,
-- 日期类型
birthday DATE
);
MySQL在执行建表语句时,将id字段的类型设置为int(11),这里的11实际上是int类型指定的显示宽度,默 认的显示宽度为11。也可以在创建数据表的时候指定数据的显示宽度
示例2:
CREATE TABLE dept(
-- int类型,自增
deptno INT(2) AUTO_INCREMENT,
dname VARCHAR(14),
loc VARCHAR(13),
-- 主键
PRIMARY KEY (deptno)
);
在MySQL 8.x版本中,不再推荐为INT类型指定显示长度,并在未来的版本中可能去掉这样的语法。
创建方式2
相当于拷贝了一份别人的查询结果
-- 将创建表和插入数据结合起来
CREATE TABLE dept100 AS SELECT
employee_id,
last_name,
salary * 12 ANNSAL,
hire_date
FROM
employees
WHERE
department_id = 100;
Query OK, 6 rows affected (0.03 sec)
Records: 6 Duplicates: 0 Warnings: 0
查看数据表结构
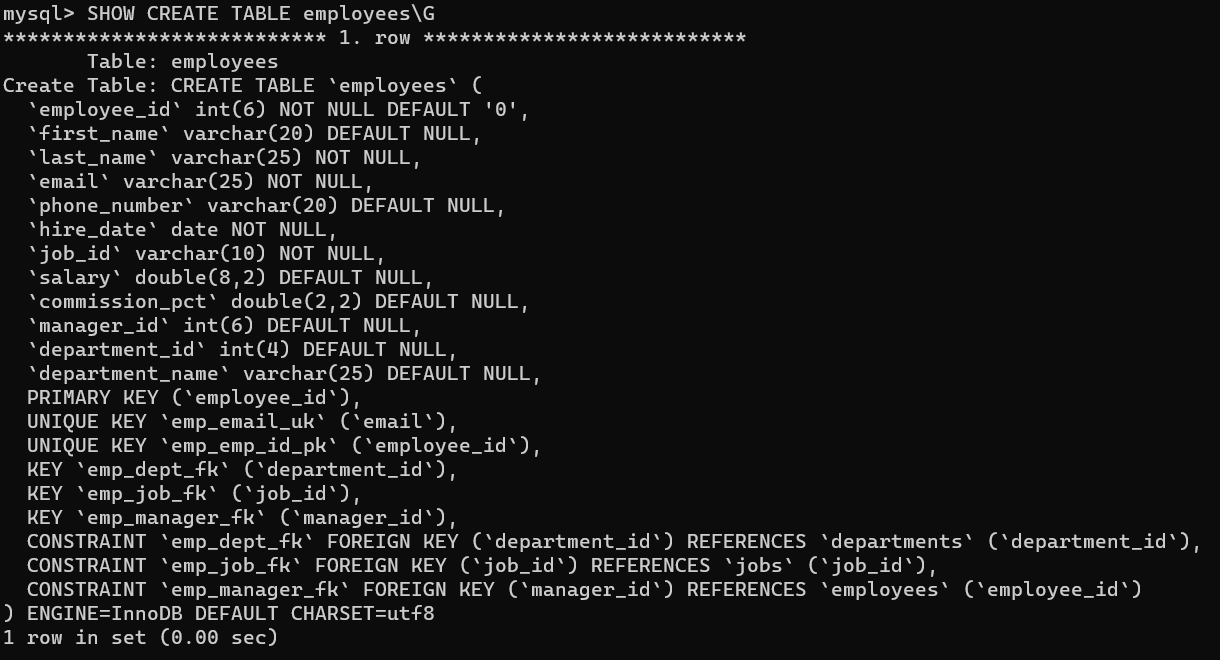
使用SHOW CREATE TABLE语句不仅可以查看表创建时的详细语句,还可以查看存储引擎和字符编码。
修改表
追加一个列
ALTER TABLE 表名 ADD 【COLUMN】 字段名 字段类型 【FIRST|AFTER 字段名】;
ALTER TABLE dept80
ADD job_id varchar(15)
修改一个列
ALTER TABLE 表名 MODIFY 【COLUMN】 字段名1 字段类型 【DEFAULT 默认值】【FIRST|AFTER 字段名 2】;
ALTER TABLE dept80
MODIFY last_name VARCHAR(30);
ALTER TABLE dept80
MODIFY salary double(9,2) default 1000;
重命名一个列
ALTER TABLE 表名 CHANGE 【column】 列名 新列名 新数据类型;
ALTER TABLE dept80
CHANGE department_name dept_name varchar(15);
删除一个列
ALTER TABLE 表名 DROP 【COLUMN】字段名
ALTER TABLE dept80
DROP COLUMN job_id;
重命名表
RENAME TABLE emp
TO myemp;
ALTER table dept
RENAME [TO] detail_dept; -- [TO]可以省略
删除表
整个表都被删除,包括表的结构和数据
DROP TABLE 语句不能回滚
在MySQL中,当一张数据表 没有与其他任何数据表形成关联关系 时,可以将当前数据表直接删除。
数据和结构都被删除
所有正在运行的相关事务被提交
所有相关索引被删除
语法格式:
DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n];
DROP TABLE dept80;
TRUNCATE和DELE FROM
只删除数据,表的结构还在
TRUNCATE也不可以回滚,而DELETE删除数据的话是可以回滚的
TRUNCATE TABLE语句:
TRUNCATE TABLE detail_dept;
DCL中COMMIT和ROLLBACK
COMMIT:提交数据,数据一旦执行COMMIT,则数据就被永久的保存在了数据库中,意味着数据不可以回滚
ROLLBACK:执行回滚操作,一旦执行ROLLBACK,则可以实现数据的回滚。只能回滚到最近的一次COMMIT之后
SET autocommit = FALSE;
DELETE FROM emp2;
#TRUNCATE TABLE emp2;
SELECT * FROM emp2;
ROLLBACK;
SELECT * FROM emp2;
数据库命名规范
-
正例:aliyun_admin,rdc_config,level3_name
-
反例:AliyunAdmin,rdcConfig,level_3_name
-
禁用保留字,如 desc、range、match、delayed 等,请参考 MySQL 官方保留字
-
表必备三字段:id, gmt_create, gmt_modified
- 说明:其中 id 必为主键,类型为BIGINT UNSIGNED、单表时自增、步长为 1。
- gmt_create, gmt_modified 的类型均为 DATETIME 类型,前者现在时表示主动式创建,后者过去分词表示被 动式更新
-
表的命名最好是遵循 “业务名称_表的作用”
- 正例:alipay_task 、 force_project、 trade_config
-
库名与应用名称尽量一致
练习
-- 创建和管理
CREATE DATABASE 数据库名 CHARACTER SET 字符集
-- 将创建表和插入数据结合起来
-- 相当于拷贝了一份
CREATE TABLE dept80 AS SELECT
employee_id,
last_name,
salary * 12 ANNSAL,
hire_date
FROM
employees
WHERE
department_id = 80;
#1. 创建数据库test01_office,指明字符集为utf8。并在此数据库下执行下述操作
CREATE DATABASE IF NOT EXISTS test01_office CHARACTER SET 'utf8'
#2. 创建表dept01
/*
字段 类型
id INT(7)
NAME VARCHAR(25)
*/
#3. 将表departments中的数据插入新表dept02中
#4. 创建表emp01
/*
字段 类型
id INT(7)
first_name VARCHAR (25)
last_name VARCHAR(25)
dept_id INT(7)
*/
#5. 将列last_name的长度增加到50
ALTER TABLE employees MODIFY last_name VARCHAR(50)
#6. 根据表employees创建emp02
#7. 删除表emp01
DROP TABLE IF EXISTS emp01
#8. 将表emp02重命名为emp01
RENAME TABLE emp02 TO emp01
#9.在表dept02和emp01中添加新列test_column,并检查所作的操作
ALTER TABLE dept02 ADD test_column VARCHAR(10)
#10.直接删除表emp01中的列 department_id
ALTER TABLE emp01 DROP COLUMN department_id
数据处理之增删改
插入数据
VALUES的方式添加
情况1:为表的所有字段按默认顺序插入数据
不指定字段名,按照默认字段的默认顺序进行添加
INSERT INTO 表名 VALUES (value1,value2,....);
INSERT INTO departments VALUES (70, 'Pub', 100, 1700);
情况2:为表的指定字段插入数据
INSERT INTO 表名(column1 [, column2, …, columnn]) VALUES (value1 [,value2, …, valuen]);
INSERT INTO departments(department_id, department_name) VALUES (80, 'IT')
情况3:同时插入多条记录
INSERT INTO table_name
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
或者如下:
INSERT INTO table_name(column1 [, column2, …, columnn])
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
示例如下:
mysql> INSERT INTO emp(emp_id,emp_name)
-> VALUES (1001,'shkstart'),
-> (1002,'atguigu'),
-> (1003,'Tom');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
使用INSERT同时插入多条记录时,MySQL会返回一些在执行单行插入时没有的额外信息,这些信息的含 义如下:
- Records:表明插入的记录条数。
- Duplicates:表明插入时被忽略的记录,原因可能是这 些记录包含了重复的主键值。
- Warnings:表明有问题的数据值,例如发生数据类型转换。
一个同时插入多行记录的INSERT语句等同于多个单行插入的INSERT语句,但是多行的INSERT语句 在处理过程中 效率更高 。因为MySQL执行单条INSERT语句插入多行数据比使用多条INSERT语句 快,所以在插入多条记录时最好选择使用单条INSERT语句的方式插入。
小结
- VALUES 也可以写成 VALUE ,但是VALUES是标准写法。
- 字符和日期型数据应包含在单引号中。
将查询结果插入到表中
INSERT INTO 目标表名
(tar_column1 [, tar_column2, …, tar_columnn])
SELECT
(src_column1 [, src_column2, …, src_columnn])
FROM 源表名
[WHERE condition]
- 在 INSERT 语句中加入子查询。
- 不必书写 VALUES 子句。
- 子查询中的值列表应与 INSERT 子句中的列名对应。
例子:
INSERT INTO dept80 (
employee_id,
last_name,
ANNSAL,
hire_date
)
SELECT
employee_id,
last_name,
ANNSAL,
hire_date
FROM
dept100;
更新数据
UPDATE table_name SET column1=value1, column2=value2, … , column=valuen [WHERE condition]
-
可以一次更新多条数据。
-
如果需要回滚数据,需要保证在DML前,进行设置:SET AUTOCOMMIT = FALSE;
-
使用 WHERE 子句指定需要更新的数据。
UPDATE employees SET department_id = 70 WHERE employee_id = 113; -
如果省略 WHERE 子句,则表中的所有数据都将被更新
删除数据
使用 DELETE 语句从表中删除数据
DELETE FROM table_name [WHERE <condition>];
使用 WHERE 子句删除指定的记录
DELETE FROM departments
WHERE department_name = 'Finance';
如果省略 WHERE 子句,则表中的全部数据将被删除
MySQL8新特性:计算列
什么叫计算列呢?简单来说就是某一列的值是通过别的列计算得来的。
例如,a列值为1、b列值为2,c列 不需要手动插入,定义a+b的结果为c的值,那么c就是计算列,是通过别的列计算得来的。
在MySQL 8.0中,CREATE TABLE 和 ALTER TABLE 中都支持增加计算列。
CREATE TABLE tb1(
id INT,
a INT,
b INT,
c INT GENERATED ALWAYS AS (a + b) VIRTUAL
);
INSERT INTO tb1(a,b) VALUES (100,200);
mysql> SELECT * FROM tb1;
+------+------+------+------+
| id | a | b | c |
+------+------+------+------+
| NULL | 100 | 200 | 300 |
+------+------+------+------+
1 row in set (0.00 sec)
练习
当需要对数据库数据进行分类统计的时候,往往会用上groupby进行分组。
而在groupby后面还可以加入withcube和withrollup等关键字对数据进行汇总。
建表加数据
CREATE TABLE books (
id INT,
NAME VARCHAR ( 50 ),
AUTHORS VARCHAR ( 100 ),
price FLOAT,
pubdate YEAR,
note VARCHAR ( 100 ),
num INT
)
INSERT INTO books ( id, NAME, `authors`, price, pubdate, note, num )
VALUES
( 3, 'Story of Jane', 'Jane Tim', 40, 2001, 'novel', 0 ),
( 4, 'Lovey Day', 'George Byron', 20, 2005, 'novel', 30 ),
( 5, 'Old land', 'Honore Blade', 30, 2010, 'Law', 0 ),
( 6, 'The Battle', 'Upton Sara', 30, 1999, 'medicine', 40 ),
( 7, 'Rose Hood', 'Richard haggard', 28, 2008, 'cartoon', 28 );
-
查询书名达到10个字符的书,不包括里面的空格
CHAR_LENGTH(str) 返回以字符来测量字符串str的长度。
REPLACE ()三个参数,第一个为字段,第二个为被替换的字符,第三个为替换的字符
updatearticleset name=replace(name,’ ‘,’');SELECT * FROM books WHERE CHAR_LENGTH( REPLACE ( NAME, ' ', '' ))>= 10; -
按照note分类统计书的库存量,显示库存量最多的
SELECT note, SUM(num) FROM books GROUP BY note ORDER BY num DESC LIMIT 0,1 -
查询书名和类型, 其中note值为 novel显示小说,law显示法律,medicine显示医药,cartoon显示卡通,joke显示笑话
SELECT NAME AS "书名", note, CASE note WHEN 'novel' THEN '小说' WHEN 'law' THEN '法律' WHEN 'medicine' THEN '卡通' END '类型' FROM books; -
查询书名、库存,其中num值超过30本的,显示滞销,大于0并低于10的,显示畅销,为0的显示需要无货
SELECT name,num,CASE WHEN num>30 THEN '滞销' WHEN num>0 AND num<10 THEN '畅销' WHEN num=0 THEN '无货' ELSE '正常' END AS "库存状态" FROM books; -
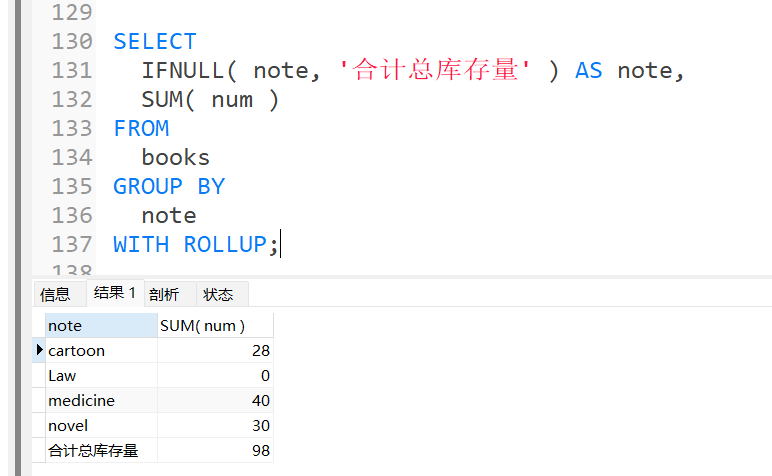
统计每一种note的库存量,并合计总量
当需要对数据库数据进行分类统计的时候,往往会用上groupby进行分组。而在groupby后面还可以加入withcube和withrollup等关键字对数据进行汇总。
IFNULL 函数是MySQL控制流函数之一,它接受两个参数,如果不是 NULL ,则返回第一个参数。. 否则, IFNULL 函数返回第二个参数。
SELECT
IFNULL( note, '合计总库存量' ) AS note,
SUM( num )
FROM
books
GROUP BY
note
WITH ROLLUP;
对WITH ROLLUP的理解:
不加如下:
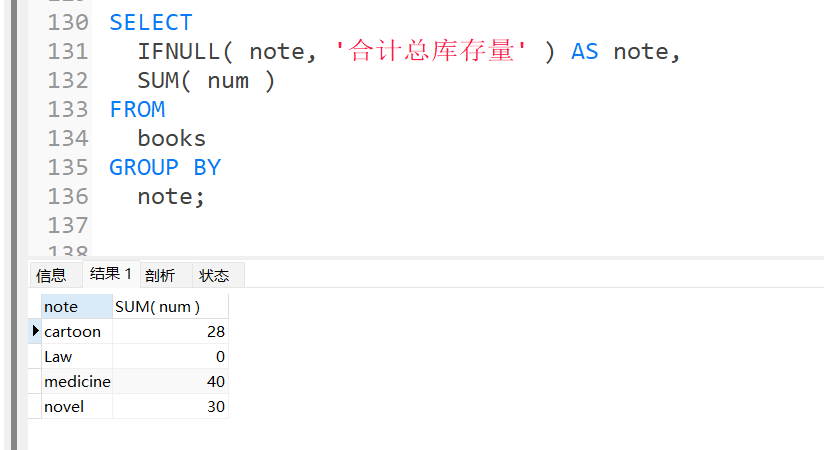
加了: