背景:
模型越来越大,训练复杂度越来越高,需要训练的时间也是越来越长。那么我们该如何在现有的硬件基础上对模型做训练呢。
模型规模的扩大,对硬件(算力、内存)的发展提出要求。然而,因为 内存墙 的存在,单一设备的算力及容量,受限于物理定律,持续提高芯片的集成越来越困难,难以跟上模型扩大的需求。
为了解决算力增速不足的问题,人们考虑用多节点集群进行分布式训练,以提升算力,分布式训练势在必行。
这篇文章会跟大家分享分布式计算的几种策略:数据并行、模型并行、混合并行,以及模型并行工程上常用的两种框架ps、ring-allreduce;然后会给大家介绍显存都消耗在哪些地方了;接着跟大家介绍如何针对显存消耗多的地方优化。
文章引用比较多的oneflow公司和清华大学的课程内容。
常见的并行策略¶
简单的机器堆叠并不一定会带来算力的增长。因为神经网络的训练并不是单纯的“把原来一个设备做的事情,现在分给多个设备各自做”,它不仅需要多个设备进行计算,还涉及到设备之间的数据传输,只有协调好集群中的计算与通信,才能做高效的分布式训练。
我们将以矩阵乘法的例子,解释数据并行、模型并行的区别。
先了解以下逻辑上的矩阵乘法例子:
假设神经网络中某一层是做矩阵乘法,其中的输入 x 的形状为 4×5,模型参数 w 的形状为 5×8,那么,矩阵乘法输出形状为 4×8。示意图如下:

单机单卡的训练中,以上矩阵乘法,先计算得到 out,并将 out传递给下一层,并最终计算得到 loss,然后在反向传播过程中,得到 aloss/aw,用于更新 w。
分布式训练中,依据是切分 x 还是 w的不同,分为“数据并行”和“模型并行”策略。接下来,我们介绍常见的并行策略。

数据并行¶
所谓的数据并行,就是将数据 x 进行切分,而每个设备上的模型 w是完整的、一致的。如下图所示,x被按照第0维度平均切分到2个设备上,两个设备上都有完整的 w。
这样,在两台设备上,分别得到的输出,都只是逻辑上输出的一半(形状为 2×8),将两个设备上的输出拼接到一起,才能得到逻辑上完整的输出。

注意,因为数据被分发到了2个设备上,因此反向传播过程,各自设备上得到的 会不一样,如果直接使用各个设备上的梯度更新各自的模型,会造成2个设备上的 模型不一致,训练就失去了意义(到底用哪个模型好呢?)。
因此,数据并行策略下,在反向传播过程中,需要对各个设备上的梯度进行 AllReduce,以确保各个设备上的模型始终保持一致。
当数据集较大,模型较小时,由于反向过程中为同步梯度产生的通信代价较小,此时选择数据并行一般比较有优势,常见的视觉分类模型,如 ResNet50,比较适合采用数据并行。
模型并行¶
当神经网络非常巨大,数据并行同步梯度的代价就会很大,甚至网络可能巨大到无法存放到单一计算设备中,这时候,可以采用模型并行策略解决问题。
所谓的模型并行,就是每个设备上的数据是完整的、一致的,而模型 � 被切分到了各个设备上,每个设备只拥有模型的一部分,所有计算设备上的模型拼在一起,才是完整的模型。
如下图所示,� 被按照第1维度平均切分到2个设备上,两个设备上都有完整的 �。两个设备上的输出也需要通过拼接才能得到逻辑上的输出。
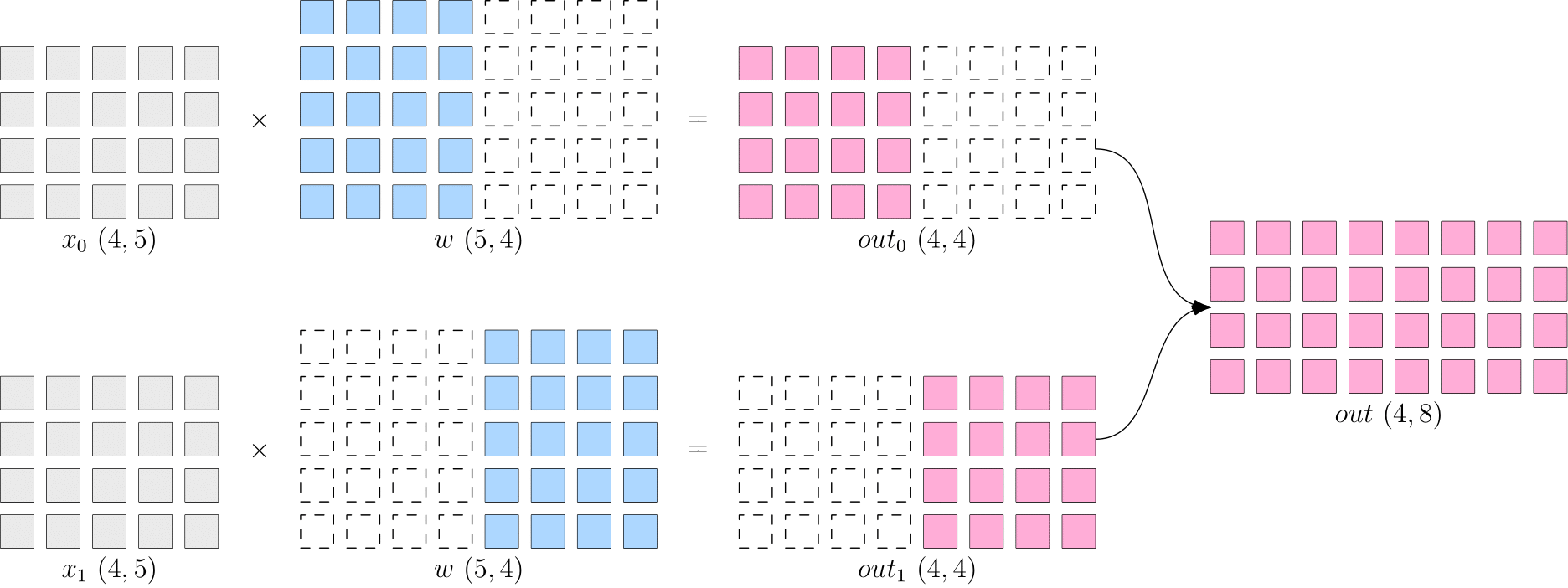
模型并行的好处是,省去了多个设备之间的梯度 AllReduce;但是,由于每个设备都需要完整的数据输入,因此,数据会在多个设备之间进行广播,产生通信代价。比如,上图中的最终得到的 ��� (4×8) ,如果它作为下一层网络的输入,那么它就需要被广播发送到两个设备上。
语言模型,如 BERT,常采用模型并行。
流水并行¶
当神经网络过于巨大,无法在一个设备上存放时,除了上述的模型并行的策略外,还可以选择流水并行。 流水并行指将网络切为多个阶段,并分发到不同的计算设备上,各个计算设备之间以“接力”的方式完成训练。
如下图,展示了一个逻辑上的4层网络(T1 至 T4)是如何做流水并行的。
4层网络被切分到2个计算设备上,其中 GPU0 上进行 T1 与 T2 的运算,GPU1 上进行 T3 与 T4 的计算。
GPU0 上完成前两层的计算后,它的输出被当作 GPU1 的输入,继续进行后两层的计算。

混合并行¶
网络的训练中,也可以将多种并行策略混用,以 GPT-3 为例,以下是它训练时的设备并行方案:
它首先被分为 64 个阶段,进行流水并行。每个阶段都运行在 6 台 DGX-A100 主机上。在6台主机之间,进行的是数据并行训练;每台主机有 8 张 GPU 显卡,同一台机器上的8张 GPU 显卡之间是进行模型并行训练。
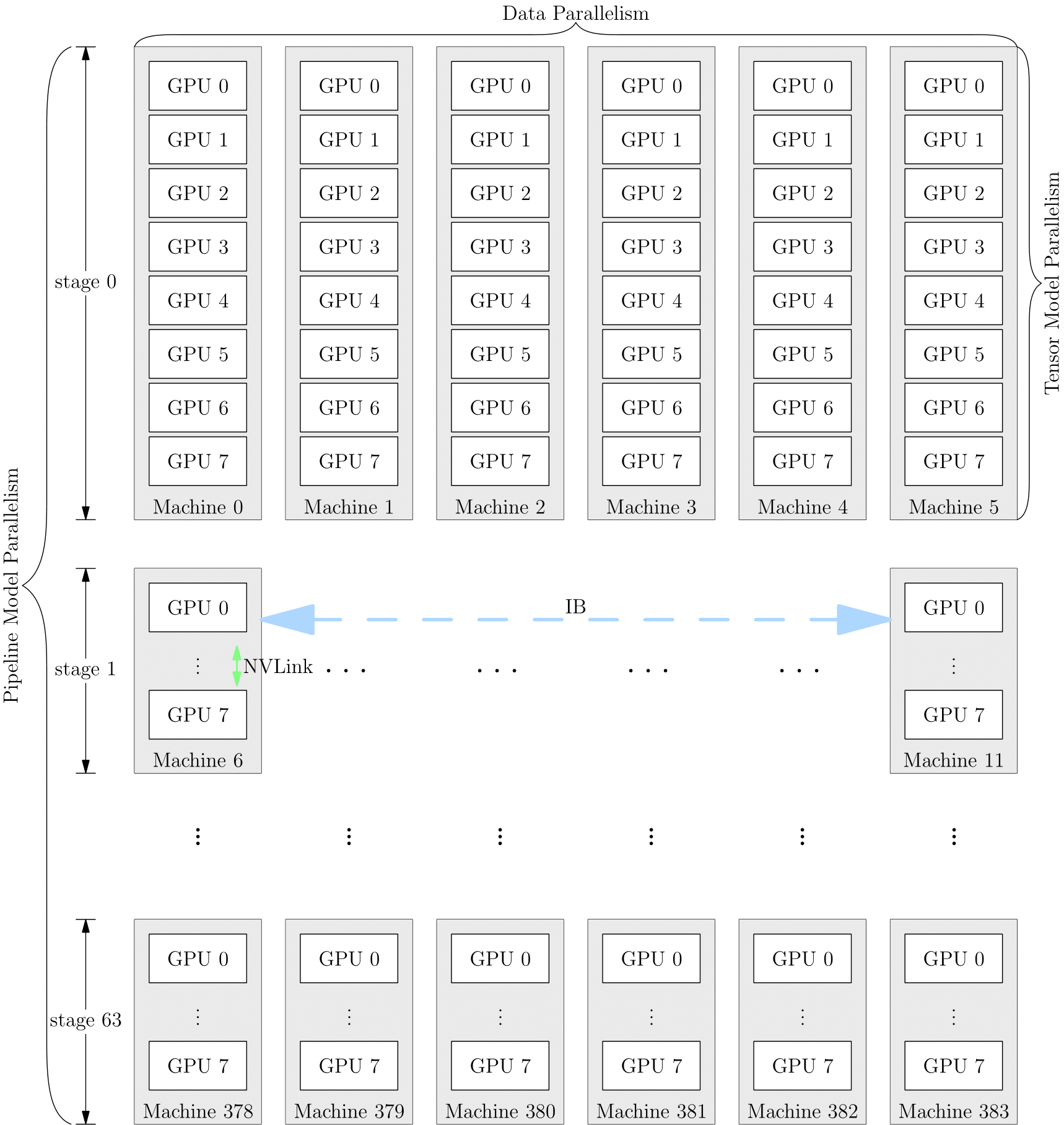
并行策略的选择影响着训练效率,框架对并行训练的接口支持程度,决定了算法工程师的开发效率。OneFlow 针对分布式训练所做的系统级设计和创新,为用户轻松上手分布式训练做足了铺垫。我们将在本专题的其它文章中看到相关示例。
分布式训练系统架构
分布式训练系统架构主要有两种:
Parameter Server Architecture(就是常见的PS架构,参数服务器)
Ring-allreduce Architecture

Parameter Server架构
在Parameter Server架构(PS架构)中,集群中的节点被分为两类:parameter server和worker。其中parameter server存放模型的参数,而worker负责计算参数的梯度。在每个迭代过程,worker从parameter sever中获得参数,然后将计算的梯度返回给parameter server,parameter server聚合从worker传回的梯度,然后更新参数,并将新的参数广播给worker。见下图的左边部分。

Ring-allreduce架构
在Ring-allreduce架构中,各个设备都是worker,并且形成一个环,如上图所示,没有中心节点来聚合所有worker计算的梯度。在一个迭代过程,每个worker完成自己的mini-batch训练,计算出梯度,并将梯度传递给环中的下一个worker,同时它也接收从上一个worker的梯度。对于一个包含N个worker的环,各个worker需要收到其它N-1个worker的梯度后就可以更新模型参数。其实这个过程需要两个部分:scatter-reduce和allgather,百度开发了自己的allreduce框架,并将其用在了深度学习的分布式训练中。
相比PS架构,Ring-allreduce架构有如下优点:
带宽优化,因为集群中每个节点的带宽都被充分利用。而PS架构,所有的worker计算节点都需要聚合给parameter server,这会造成一种通信瓶颈。parameter server的带宽瓶颈会影响整个系统性能,随着worker数量的增加,其加速比会迅速的恶化。
此外,在深度学习训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于前面层,Ring-allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。在百度的实验中,他们发现训练速度基本上线性正比于GPUs数目(worker数)。
显存消耗分析

cpu拥有更少的核数,更强大的core,适合来做复杂的逻辑处理、流程控制,通用性更强。
gpu拥有更多的核数,但是每个core的能力是相对弱的,适合来做简单的单一的事情,比如计算。
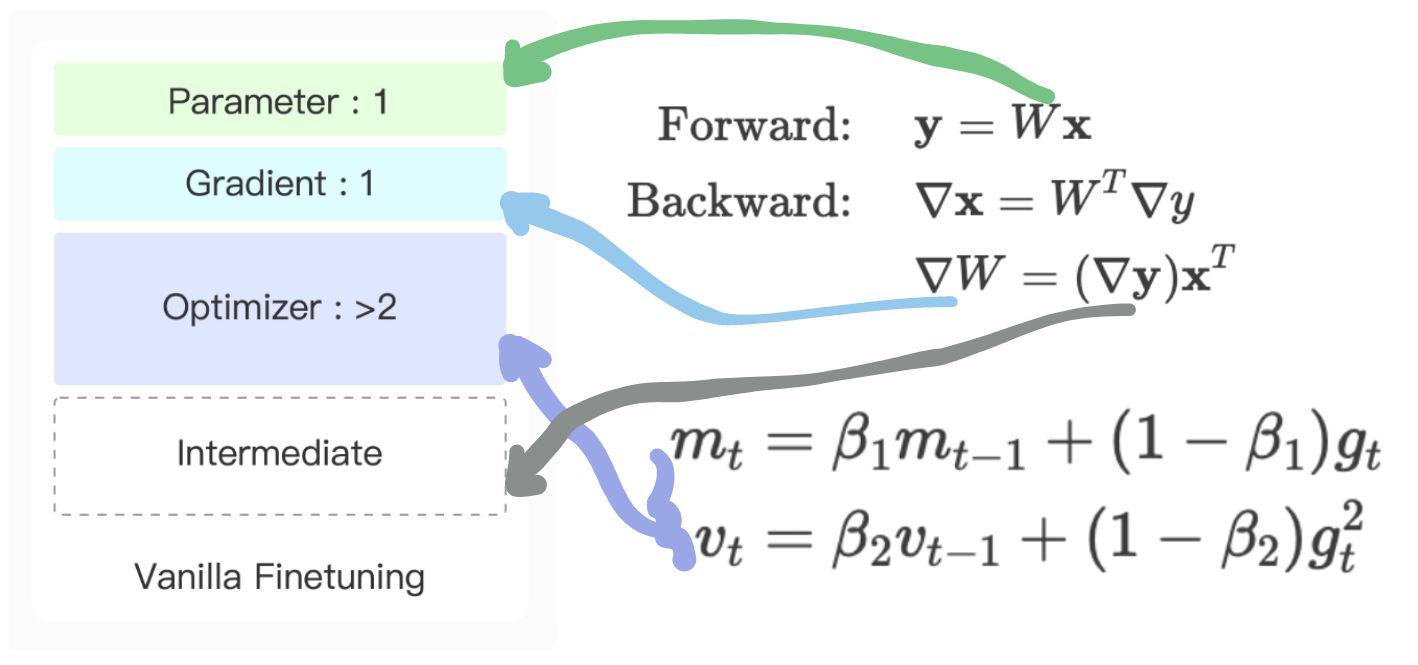
模型训练时候显卡主要花在哪些地方:
1.网络参数如上的绿色线指示W
2.网络训练用到的回传梯度蓝色线指示的deltaW
3.优化器的各种正则器比如Adam有两倍参数的数据
4.计算回传梯度的中间deltaY,这个和训练数据量、数据特征长度直接相关
数据并行显存消耗分析

前向计算
1.参数复制到每一个设备
2.每个设备利用部分数据计算参数
后向计算
1.梯度从每个分片回传计算均值
2.均值梯度更新参数
把数据广播到每个设备,每个GPU计算梯度要消耗显存,有网络开销

把每台设备的梯度回传到一台计算平均梯度,计算平均梯度设备有显存消耗

把计算完平均梯度传给每台设备,接受设备在更新参数时有显存消耗

计算平均梯度,其实还可以每台设备计算一部分参数的梯度,optimizer参数变成全量参数计算1/n

每部分梯度计算完后,在进行参数广播给其他设备(这种每天计算部分参数,在广播给其他设备,并行性会更好,但是网络开销更大,每台设备的峰值显存消耗会稍微小些)

数据并行,每台设备上计算的数据batch尺寸减小了,所以显卡内存intermediate消耗会减少。
模型并行显卡消耗分析

1.把参数矩阵分块,分发给每块设备
2.每块设备处理全样数据计算

模型并行计算:
1.参数变小了,分成多少块,参数量就是全有参数的1/n
2.梯度参数变成全部参数的1/n
3.优化参数变成全部参数的1/n
4.因为要对全量数据计算,所以每个batch参数是不变的,intermediate数据量不变
显存优化
ZERO参数优化策略
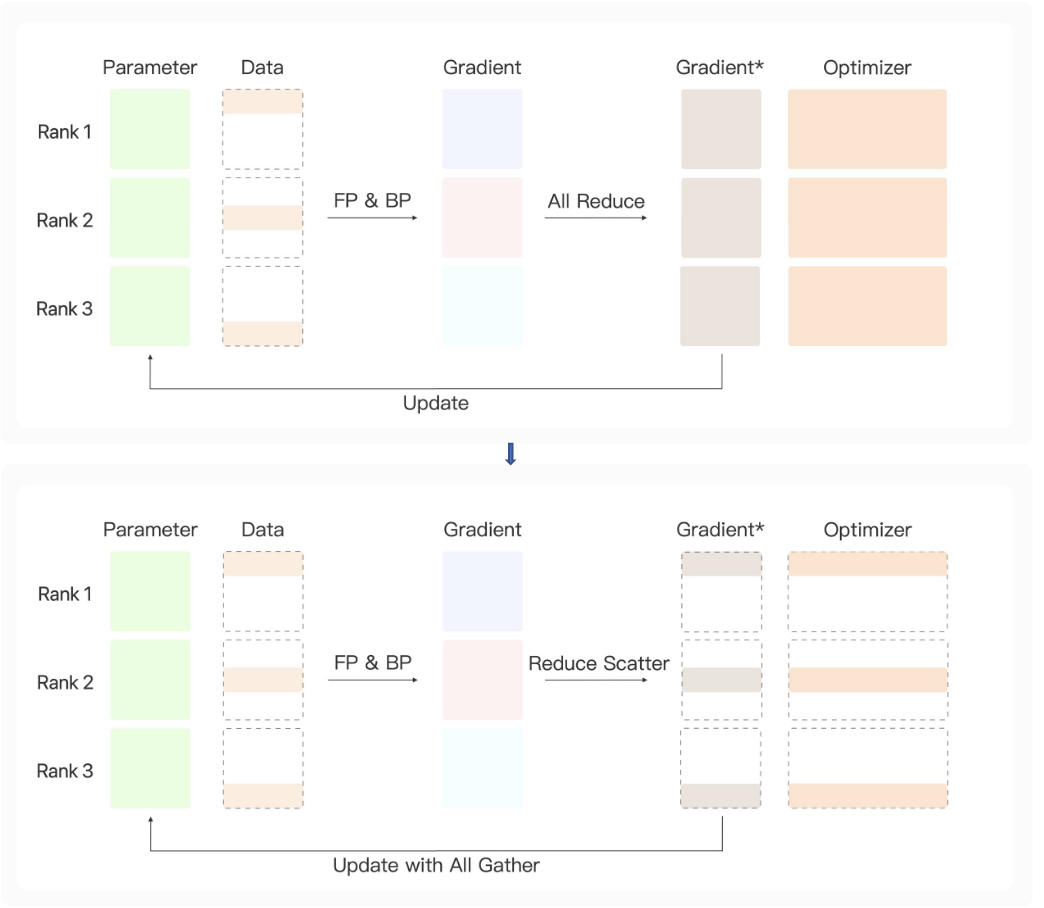
Zero-Stage1策略优化:
1.采用数据并行,intermediate参数变成全量数据1/n
2.梯度汇总的时候采用reduce scatter策略,每台设备计算一部分参数,optimizer参数变成全量参数计算1/n
3.需要更新全局参数时候在进行All Gather,对所有参数更新
显存消耗较多,适用于参数不大模型计算。

Zero-Stage2策略优化:
1.采用数据并行,intermediate参数变成全量数据1/n
2.每台设备计算梯度回传的时候采用reduce scatter策略,每台设备计算一部分参数,Gradient、optimizer参数变成全量参数计算1/n
3.需要更新全局参数时候在进行All Gather,对所有参数更新

Zero-Stage2策略优化:
1.采用模型并行+数据并行混合,参数变为全量1/n
2.采用数据并行,intermediate参数变成全量数据1/n
3.每台设备计算梯度回传的时候采用reduce scatter策略,每台设备计算一部分参数,Gradient、optimizer参数变成全量参数计算1/n
小结

1.Zero-1stage在静态链路上看,intermediate、optimizer显存减少为全量1/n
2.zero-2stage在静态链路上看,intermediate、optimizer、gradient显存减少为全量1/n
3.zero-3stage在静态链路上看,intermediate、optimizer、gradient、parameter显存减少为全量1/n
流水线并行策略

模型是一层一层的,所谓流水线并行就是:
1.每层模型分到不同的GPU上做计算
2.数据并行的计算
3.intermediate、optimizer、gradient、parameter显存减少为全量1/n
动态优化
同样是选择了zero策略+流水线策略,为什么deepspeed的框架和megatron、BMtrain、ColossalAI框架在Runtime时候显存消耗会出现很大的差异。这里主要原因是zero策略虽然是规定了大的规范,但是在实现时候计算流程从前到后传递参数,保留多久、何时丢弃、丢弃什么,各家的理解和实现都是有差异的。所以导致虽然都是zero策略、流水线策略用起来Runtime的显存消耗和计算速度差异很大。

实际运算中,一块Gpu配置多块cpu(一般是6-12块,看参数大小),在计算时候可以把optimizer参数部分卸载到cpu。
1.把梯度计算参数从gpu卸载部分到cpu减少显存
2.optimizer早cpu上处理用(openmp+SMID)
3.更新参数时候再把参数从cpu传给gpu

流水线并行,不用等到所有层都算完,再反过来计算每一层参数。可以异步每算完一层就把前面一层的参数修改,这样就只要记住上一次上一层的参数就可以。
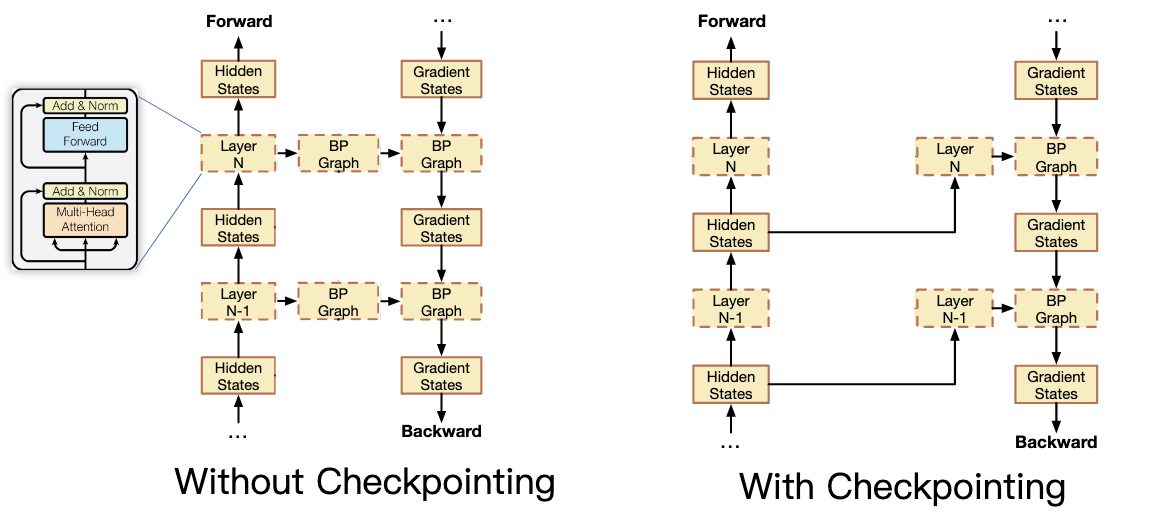
重新计算释放的中间体,并在获得梯度状态后再次释放。减少显卡内存,以时间换空间。

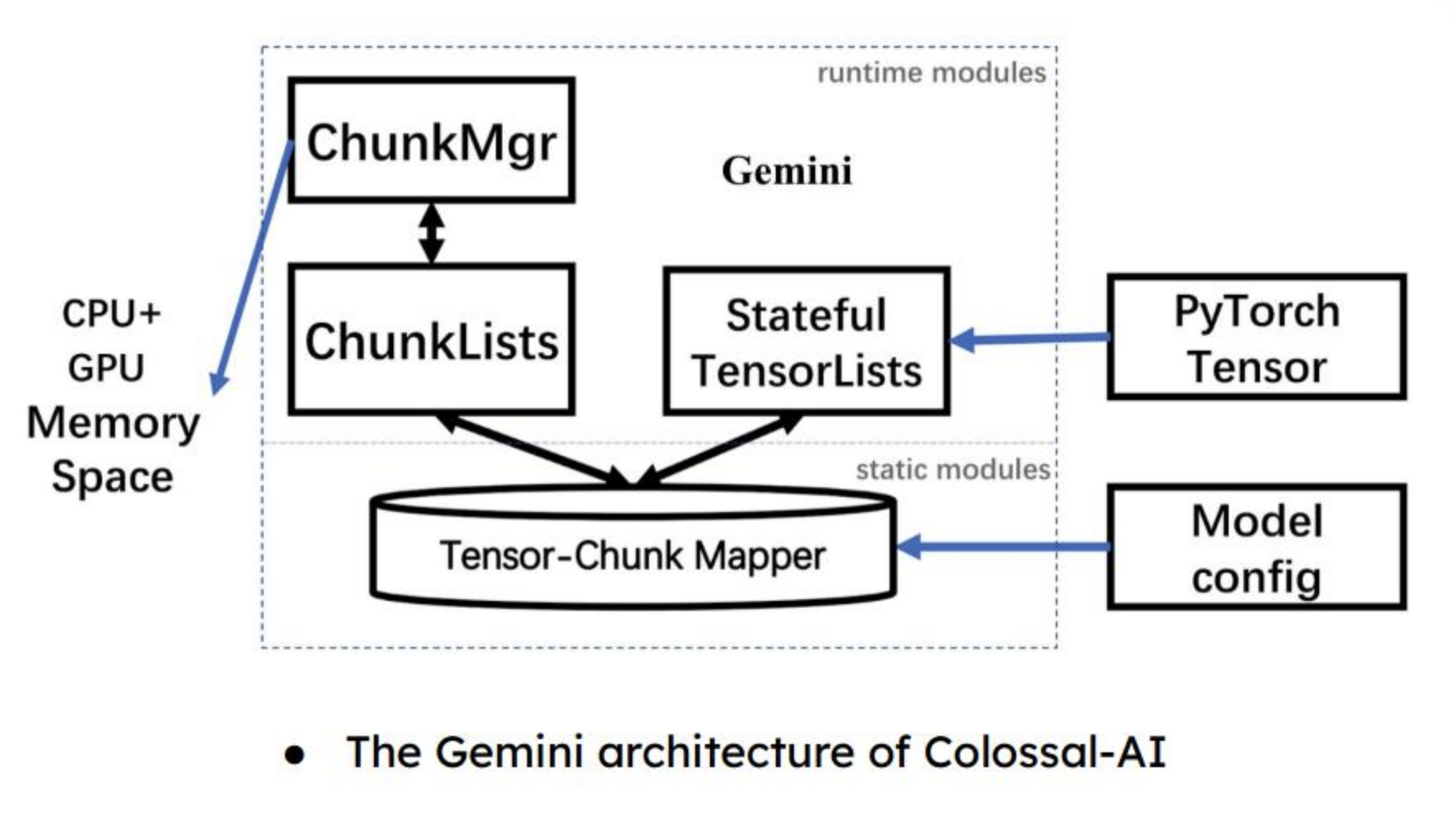
利用异构的内存系统,在Runtime流程中各种工程技巧极限压缩显存使用。