参考代码:暂无
1. 概述
介绍:BEV算法部署过程中会遇到camera的变化,这个变化包含了相机内外参数,其中内参决定了成像物体在图像中的大小,外参决定了物体成像的位置。对此文章提出了一种内外参数对齐的方案(工作是以BEVDepth为 基准),对于内参导致的物体大小问题采用深度补偿的方式解决,对于外参数导致的成像位置变化采用单应矩阵映射的解决,同时为了使得图像特征对于相机内参鲁棒,设计了一个Domain Classifier去提升生成特征的泛化能力。不过从实际效果上看最后一个改进效果相比前面两种不是那么明显。
对于相机内外参对物体成像的差异见下图所示:
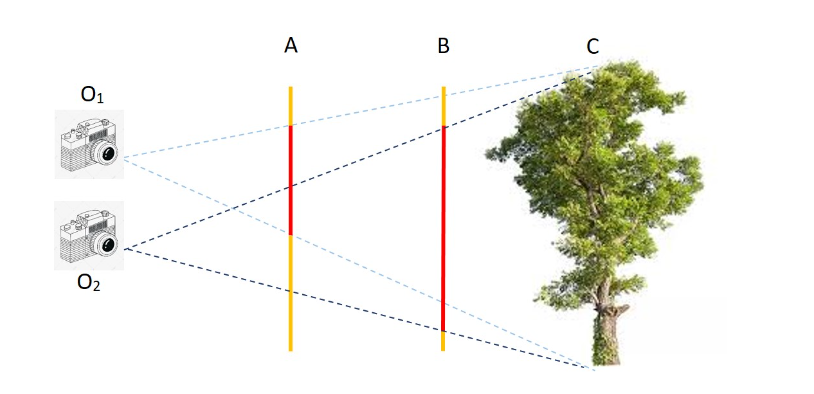
从上图可知相机的内外参会对物体在图像中成像的大小和位置带来差异,则只有将内外参数对齐才能避免在target domain中掉点严重。
2. 方法实现
文章的方法其实就是对内外参数进行补偿和适应,同时添加类似GAN Loss的方式使得图像特征对内参鲁棒,也就是对应下图中的三个部分:
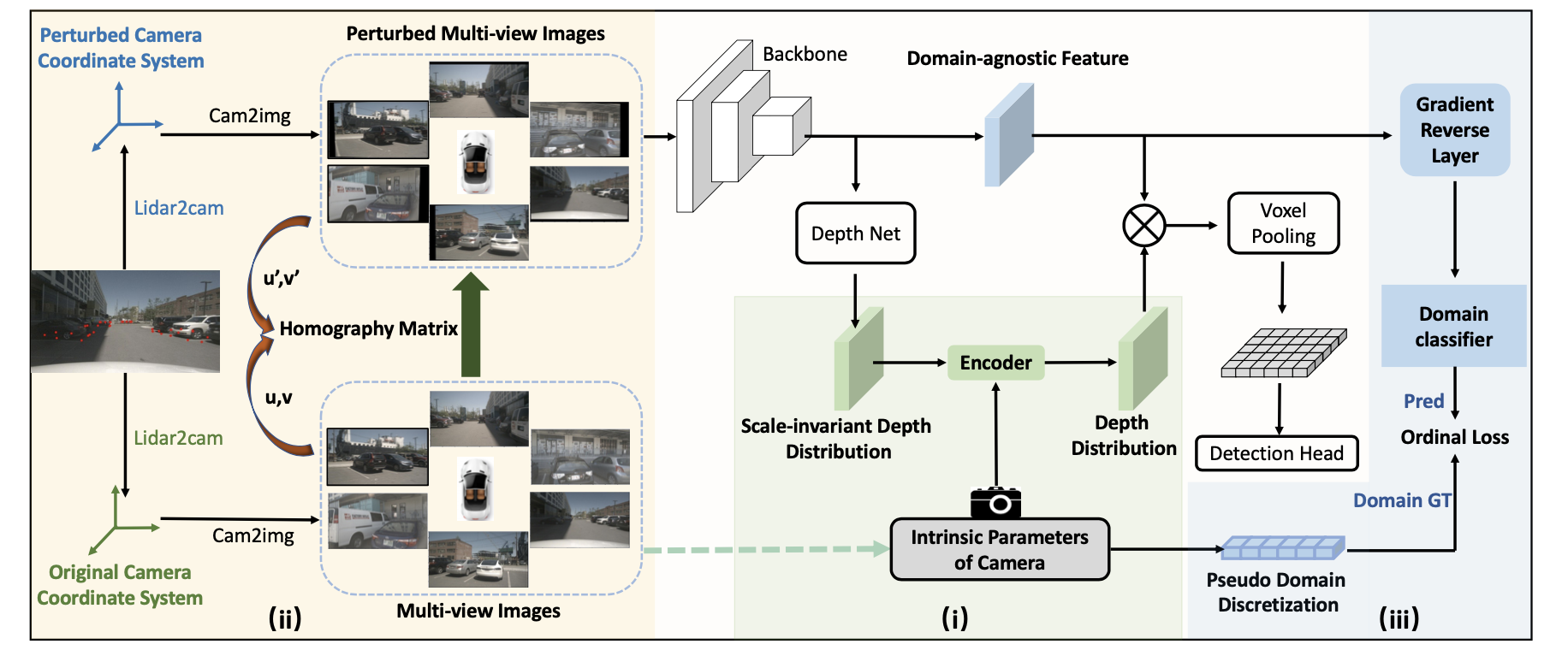
内参对齐(IDD):
相机的内参中焦距起到了比较关键的作用,它很大程度上决定了物体在图像上的成像大小,则基于LSS方案的算法中深度估计就会存在问题,对此最直接的思路便是对深度的scale进行补偿,也就是对网络深度估计结果进行如下变换:
d = s c ⋅ d m d=\frac{s}{c}\cdot d_m d=cs⋅dm
其中当前尺度的计算描述为:
s = 1 f x 2 + 1 f y 2 s=\sqrt{\frac{1}{f_x^2}+\frac{1}{f_y^2}} s=fx21+fy21
其中, c c c是ref-camera的基准。其实除了这种方式之外还可以直接公用内参也能处理这样的情况。
外参对齐(DPA):
由于车型和传感器位置的不同,它们相对车体坐标的外参也会变化,则就会导致物体成像的位置发生变化。对此这里是使用扰动的方式去模拟这样的变化,也就是在原本相机旋转角度的基础上添加随机扰动:
P ^ i = ( y i + Δ y i , p i + Δ p i , r i + Δ r i ) \hat{P}_i=(y_i+\Delta y_i,p_i+\Delta p_i,r_i+\Delta r_i) P^i=(yi+Δyi,pi+Δpi,ri+Δri)
那么在一个物体上寻找几个点,文中是取GT下面的4个顶点+中点,对于这些3D点按照新旧外参在图像中投影的位置为 q q q和 q ^ \hat{q} q^,那么要是这些点还在图像上,就可以使用最小二乘的方法去获取新旧外参下图像的单应矩阵:
q ^ = H q \hat{q}=Hq q^=Hq
图像特征内参鲁棒(DIFL):
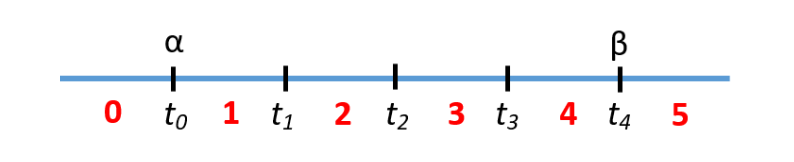
对于焦距可能存在的区间 [ α , β ] [\alpha,\beta] [α,β]划分为 K K K份:
t i = α + ( β − α ) ∗ i K t_i=\alpha+\frac{(\beta-\alpha)*i}{K} ti=α+K(β−α)∗i
则可以到 K + 1 K+1 K+1个划分阈值, K + 2 K+2 K+2个划分类别。下图是 K = 4 K=4 K=4的例子:
在网络中使用参数 θ \theta θ去预测图像的内参分布:
y = ϕ ( x , θ ) , y ∈ R 2 ( K + 1 ) y=\phi(x,\theta),y\in R^{2(K+1)} y=ϕ(x,θ),y∈R2(K+1)
对应的GT为 l = { 0 , 1 , … , K + 1 } l=\{0, 1, \dots,K+1\} l={
0,1,…,K+1},那么预测的结果与GT进行损失函数计算便是离散交叉熵的形式:
L ( y , l ) = ∑ k = 0 K + 1 γ ( k , l ) l o g ( P k ) + ( 1 − γ ( k , l ) ) l o g ( 1 − P k ) L(y,l)=\sum_{k=0}^{K+1}\gamma(k,l)log(P^k)+(1-\gamma(k,l))log(1-P^k) L(y,l)=k=0∑K+1γ(k,l)log(Pk)+(1−γ(k,l))log(1−Pk)
其中,区间划分函数:
γ ( k , l ) = { 1 if l ≤ k 0 , if l > k \gamma(k,l) = \begin{cases} 1 & \text{if $l\le k$} \\[2ex] 0, & \text{if $l\gt k$ } \end{cases} γ(k,l)=⎩
⎨
⎧10,if l≤kif l>k
分类概率计算:
P k = e y 2 k e y 2 k + e y 2 k + 1 P^k=\frac{e^{y_{2k}}}{e^{y_{2k}}+e^{y_{2k+1}}} Pk=ey2k+ey2k+1ey2k
这里的梯度并不是求去最小化而是求去最大化,目的就是使得生成的图像特征对相机内参鲁棒,借用的是gradient reverse layer (GRL) 来实现的。对于GRL的理解可以参考:
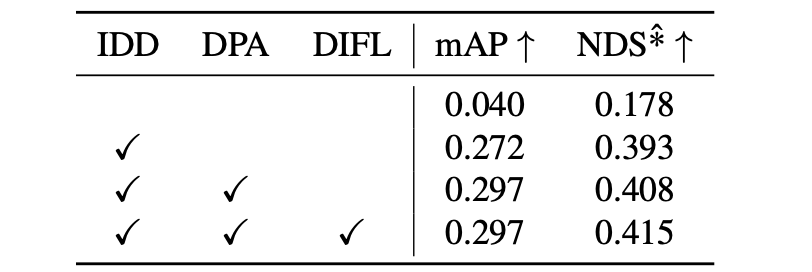
上面的几个部分对性能的影响:
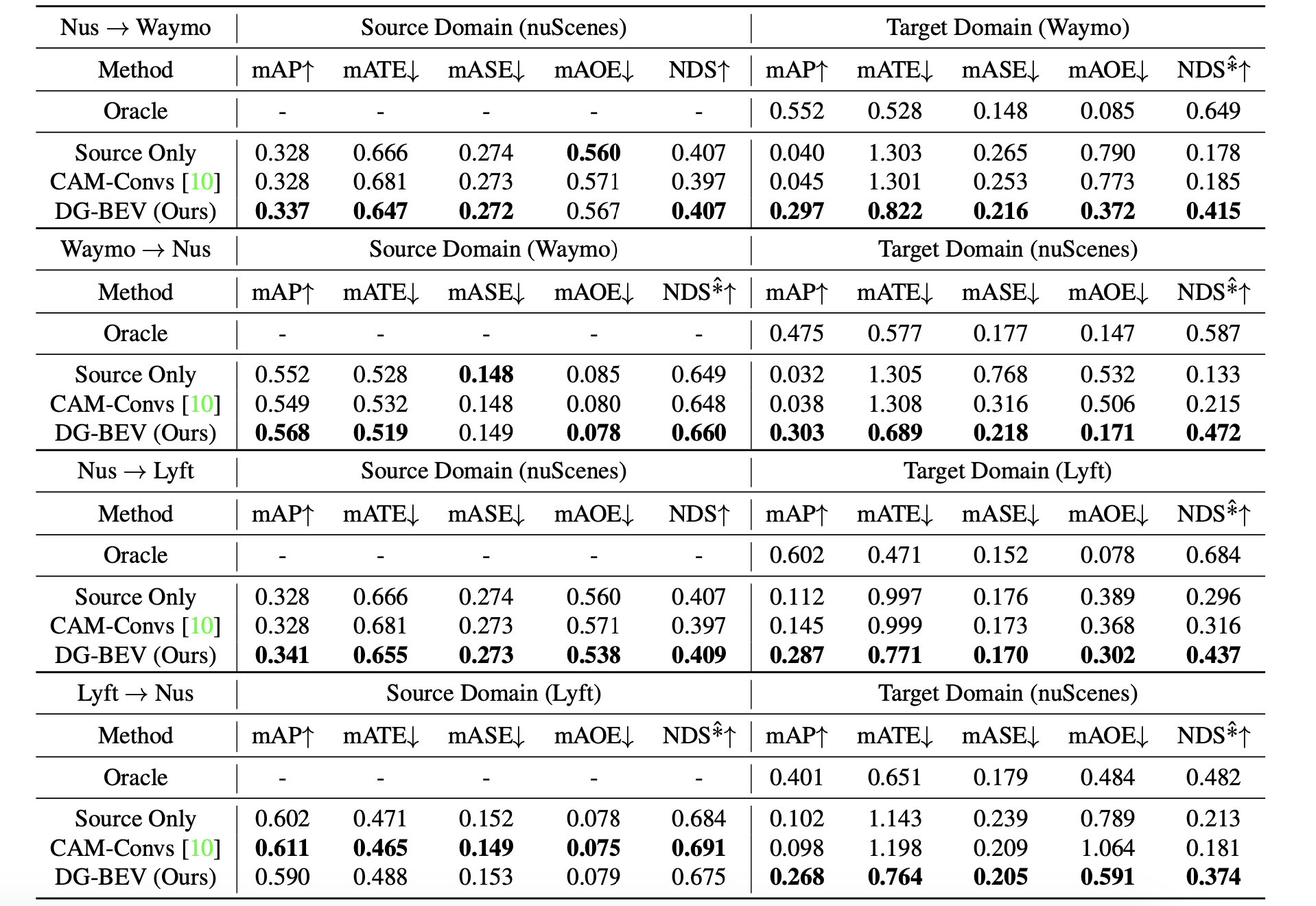
3. 实验结果
在不同数据集下迁移的实验结果: