最近已有不少大厂都在秋招宣讲,也有一些已在 Offer 发放阶段了。
节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。
总结链接如下:
喜欢本文记得收藏、关注、点赞。

利用Ollama本地LLM(大语言模型)搭建AI的REST API服务是一个实用的方法。下面是一个简单的工作流程。
1. 安装Ollama和LLMs
首先,在本地机器上安装Ollama和本地LLMs。Ollama可以帮助你轻松地在本地部署LLMs,并让它们更方便地处理各种任务。
安装 Ollama
Ollama安装界面
Ollama下载页面

安装应用文件
为Ollama安装LLMs
ollama pull llama3
ollama run llama3
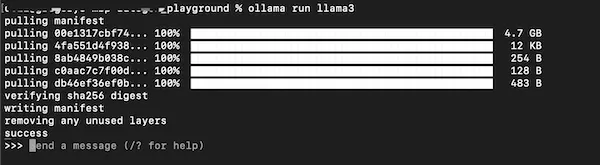
下载并运行llama3

在本地与llama3对话
Ollama命令
可用的命令:
/set 设置会话变量
/show 显示模型信息
/bye 退出
/?, /help 帮助命令
使用 "" 开始多行消息
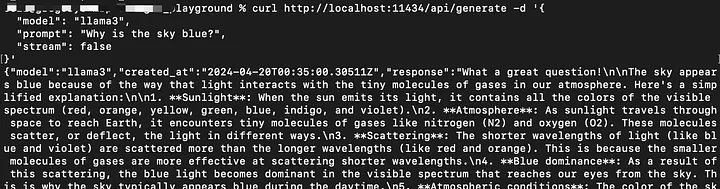
测试Ollama
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "为什么天空是蓝色的?",
"stream": true
}'
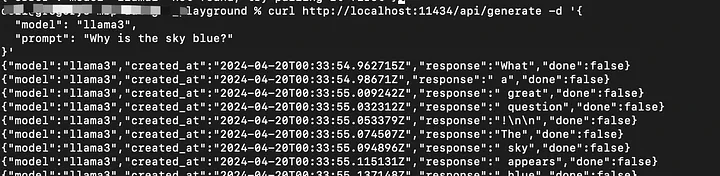
如果stream设置为false,响应将是一个完整的JSON对象。
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "为什么天空是蓝色的?",
"stream": false
}'
2. 设置FastAPI
接下来,设置一个Python的FastAPI应用。FastAPI是一个现代、快速(高性能)的Web框架,基于标准的Python类型提示,支持Python 3.7及以上版本。它是构建稳健高效API的理想选择。
编写FastAPI的路由和端点,以便与Ollama服务器进行交互。这个过程包括发送请求给Ollama以处理任务,比如文本生成、语言理解或其他LLM支持的AI任务。以下是一个简单的代码示例(你也可以使用 Ollama Python库 来优化代码)。
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
import json
import requests
app = FastAPI(debug=True)
class Itemexample(BaseModel):
name: str
prompt: str
instruction: str
is_offer: Union[bool, None] = None
class Item(BaseModel):
model: str
prompt: str
urls = ["http://localhost:11434/api/generate"]
headers = {
"Content-Type": "application/json"
}
@app.get("/")
def read_root():
return {
"Hello": "World"}
@app.post("/chat/{llms_name}")
def update_item(llms_name: str, item: Item):
if llms_name == "llama3":
url = urls[0]
payload = {
"model": "llama3",
"prompt": "为什么天空是蓝色的?",
"stream": False
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
if response.status_code == 200:
return {
"data": response.text, "llms_name": llms_name}
else:
print("错误:", response.status_code, response.text)
return {
"item_name": item.model, "error": response.status_code, "data": response.text}
return {
"item_name": item.model, "llms_name": llms_name}
测试REST-API服务
curl --location 'http://127.0.0.1:8000/chat/llama3' \
--header 'Content-Type: application/json' \
--data '{
"model": "llama3",
"prompt": "为什么天空是蓝色的?"
}'
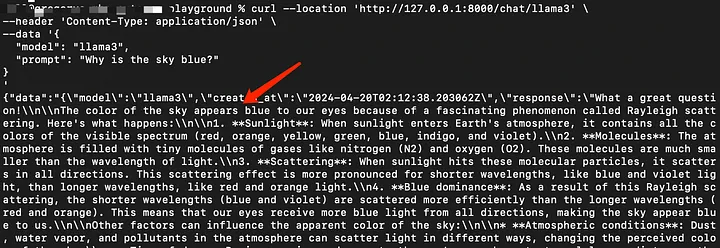
通过API发送Curl请求

API日志
3. 部署
当你对REST API的功能和性能感到满意后,可以将此服务部署到生产环境。这可能涉及将其部署到云平台、使用Docker进行容器化,或者在服务器上部署。
在这个简单的示例中,我们通过使用Ollama进行本地LLM部署并结合FastAPI构建REST API服务器,创建了一个免费的AI服务解决方案。你可以通过自己的训练数据对模型进行微调以实现定制用途(我们将在未来讨论)。