原文:KDNuggets
使用回归模型预测加密货币价格
原文:
www.kdnuggets.com/2022/05/predicting-cryptocurrency-prices-regression-models.html

来源: unsplash.com/s/photos/cryptocurrency
介绍
我们的前三大课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
 2. Google 数据分析专业证书 - 提升您的数据分析能力
2. Google 数据分析专业证书 - 提升您的数据分析能力
 3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
截至 2022 年 3 月,加密货币市场市值超过 2 万亿美元 [1],但仍然极其波动,曾在 2021 年 11 月达到 3 万亿美元。个别加密货币也表现出相同的波动性,仅在过去一个月内,以太坊和比特币分别下降了超过 18% 和 19%。新货币进入市场的数量也在增加,截至 2022 年 3 月,已有超过 18,000 种加密货币存在 [2]。
这种波动性使得长期加密货币预测更加困难。本文将介绍如何使用线性回归模型开始进行加密货币预测。我们将查看多个时间间隔的预测,同时使用各种模型特征,如开盘价、最高价、最低价和交易量。本文中讨论的加密货币包括更为成熟的比特币和以太坊,以及仍处于相对早期阶段的 Polkadot 和 Stellar。
方法
在本文中,我们将使用多元线性回归。回归模型用于通过拟合一条线来确定变量之间的关系。简单线性回归是用来预测一个依赖变量(例如加密货币的收盘价),使用一个自变量(如开盘价),而多元线性回归则考虑多个自变量。
我们将使用的数据来自 CoinCodex [3],提供了每日的开盘价、最高价、最低价和收盘价以及交易量和市值。我们实验了各种特征组合,以生成模型,并对每日和每周的间隔进行了预测。使用了 Python 的 sklearn 包来训练模型,并用 R2 值作为模型准确性的指标,其中 1 表示完美模型。
使用的数据和生成的模型已上传至Layer 项目,可以下载以供进一步使用和研究。所有结果和相应图表也可以在Layer 项目中找到。本文将讨论实现模型所用代码的各个部分。完整代码可在此collab notebook中访问。
为了初始化项目并访问数据和模型,您可以运行:
import layer
layer.login()
layer.init("predictingCryptoPrices")
数据被上传到 Layer 项目中,涵盖了 4 个加密货币数据集(比特币、以太坊、Polkadot 和 Stellar),通过定义用于读取数据的函数,并用数据集和资源装饰器进行了注释。
@dataset("bitcoin")
@resources(path="./data")
def getBitcoinData():
return pd.read_csv("data/bitcoin.csv")
layer.run([getBitcoinData])
您可以运行以下命令来访问数据集并将其保存到 pandas 数据框中。
layer.get_dataset("bitcoin").to_pandas()
layer.get_dataset("ethereum").to_pandas()
layer.get_dataset("polkadot").to_pandas()
layer.get_dataset("stellar").to_pandas()
预测
每日预测
第一组多元回归模型是为了预测每日间隔的价格而构建的。首先使用当天的开盘价、最低价和最高价来预测收盘价。使用了一年的每日价格数据,并进行了 75%-25%的训练-测试拆分。以下函数用于训练给定数据集的模型。
def runNoVolumePrediction(dataset):
# Defining the parameters
# test_size: proportion of data allocated to testing
# random_state: ensures the same test-train split each time for reproducibility
parameters = {
"test_size": 0.25,
"random_state": 15,
}
# Logging the parameters
# layer.log(parameters)
# Loading the dataset from Layer
df = layer.get_dataset(dataset).to_pandas()
df.dropna(inplace=True)
# Dropping columns we won't be using for the predictions of closing price
dfX = df.drop(["Close", "Date", "Volume", "Market Cap"], axis=1)
# Getting just the closing price column
dfy = df["Close"]
# Test train split (with same random state)
X_train, X_test, y_train, y_test = train_test_split(dfX, dfy, test_size=parameters["test_size"], random_state=parameters["random_state"])
# Fitting the multiple linear regression model with the training data
regressor = LinearRegression()
regressor.fit(X_train,y_train)
# Making predictions using the testing data
predict_y = regressor.predict(X_test)
# .score returns the coefficient of determination R² of the prediction
layer.log({
"Prediction Score :":regressor.score(X_test,y_test)})
# Logging the coefficient corresponding to each variable
coeffs = regressor.coef_
layer.log({
"Opening price coeff":coeffs[0]})
layer.log({
"Low price coeff":coeffs[1]})
layer.log({
"High price coeff":coeffs[2]})
# Plotting the predicted values against the actual values
plt.plot(y_test,predict_y, "*")
plt.ylabel('Predicted closing price')
plt.xlabel('Actual closing price')
plt.title("{} closing price prediction".format(dataset))
plt.show()
#Logging the plot
layer.log({
"plot":plt})
return regressor
函数运行时使用了模型装饰器,以将模型保存到 Layer 项目中,如下所示。
@model(name='bitcoin_prediction')
def bitcoin_prediction():
return runNoVolumePrediction("bitcoin")
layer.run([bitcoin_prediction])
要访问此预测集中的所有模型,您可以运行以下代码。
layer.get_model("bitcoin_prediction")
layer.get_model("ethereum_prediction")
layer.get_model("polkadot_prediction")
layer.get_model("stellar_prediction")
表 1 总结了使用该模型的 4 种加密货币的 R2 统计数据。

表 1:使用当天的开盘价、最低价和最高价预测加密货币收盘价的准确性
下面的图表显示了最佳和最差表现的货币 Polkadot 和 Stellar(图 1a 和 1b)的预测值与真实值的对比。

图 1a:Stellar 预测的收盘价与当天真实收盘价的对比,使用开盘价、最低价和最高价作为特征!Polkadot 预测的收盘价
图 1b:Polkadot 预测的收盘价与当天真实收盘价的对比,使用开盘价、最低价和最高价作为特征
从图表和 R2 值中,我们可以看到使用开盘价、最低价和最高价的线性回归模型对于所有 4 种货币都非常准确,无论它们的成熟程度如何。
接下来,我们研究是否添加交易量可以改进模型。交易量对应于当天的总交易笔数。有趣的是,在使用开盘价、最低价、最高价和交易量拟合回归模型后,结果基本相同。你可以在 Layer 项目中访问 bitcoin_prediction_with_volume、ethereum_prediction_with_volume、polkadot_prediction_with_volume 和 stellar_prediction_with_volume 模型。进一步的调查显示,4 种加密货币中交易量变量的系数都是 0。这表明,加密货币的交易量并不是预测当天价格的良好指标。
每周预测
在下一个模型中,我们查看了使用本周一的开盘价以及本周的最低价和最高价预测周末价格。对于这个模型,使用了过去 5 年的比特币、以太坊和 Stellar 的数据。对于 2020 年才发布的 Polkadot,则使用了所有历史数据。
下载数据后,计算了每周的最低价和最高价,并记录了本周的开盘价和收盘价。这些数据集也可以通过运行 Layer 来访问:
layer.get_dataset("bitcoin_5Years").to_pandas()
layer.get_dataset("ethereum_5Years").to_pandas()
layer.get_dataset("polkadot_5Years").to_pandas()
layer.get_dataset("stellar_5Years").to_pandas()
再次使用了 75%-25%的训练-测试拆分,并利用一周的开盘价、最高价和最低价拟合了多重线性回归模型。这些模型也可以在 Layer 项目中访问。R2 指标再次用于与下表 2 中显示的结果进行比较。

表 2:使用开盘价、最低价和最高价预测加密货币收盘价的准确性
在用一周的数据进行预测时,模型的准确性略低于用一天的数据进行预测,但准确性仍然非常高。即便是表现最差的加密货币 Stellar,其 R2 分数也达到了 0.985。
结论
总体而言,使用开盘价、最低价和最高价作为特征的线性回归模型在每日和每周间隔上表现都很好。这些模型的自然扩展是预测更远的未来,例如使用本周的数据预测下周的价格。
[3] https://coincodex.com/crypto/stellar/historical-data/
Eleonora Shantsila 是一位全栈软件工程师,目前在名为 Lounge 的活动初创公司工作,之前曾在金融服务领域担任全栈工程师。Eleonora 拥有数学(圣安德鲁斯大学本科)和计算科学(哈佛大学硕士)的背景,闲暇时喜欢从事数据科学项目。欢迎在LinkedIn 上连接。
更多相关话题
使用机器学习预测心脏病?不要!
原文:
www.kdnuggets.com/2020/11/predicting-heart-disease-machine-learning.html
评论
Venkat Raman,True Influence 的数据科学家

我们的三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析水平
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
 3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
最近,我被邀请担任数据科学竞赛的评委。学生们被提供了“心脏病预测”数据集,可能是 Kaggle 上可用数据集的改进版本。我之前见过这个数据集,并且经常看到各种自称数据科学大师的人教导天真的人如何通过机器学习预测心脏病。
我相信“使用机器学习预测心脏病”是一个经典的例子,展示了如何不将机器学习应用于一个问题,特别是在需要大量领域经验的情况下。
让我拆解一下在这个数据集上应用机器学习的各种问题。
直接投入问题的综合症 – 这通常是许多人犯的第一个错误。直接投入到问题中,想着应用哪种机器学习算法。将 EDA 等作为这一过程的一部分,并不是在思考问题。相反,这表明你已经接受了问题需要数据科学解决方案的观点。相反,在开始任何分析之前需要提出的一个相关问题是,“这个问题通过应用机器学习真的可以预测吗?”。
对数据的盲目信任 – 这是第一个要点的扩展。直接投入问题意味着你对数据有盲目的信任。人们假设数据是正确的,而不去仔细审查数据。例如,数据集只提供了收缩压。如果你和任何医生或甚至急救员谈话,他们会告诉你,单靠收缩压不能给出完整的情况。舒张压的报告也很重要。很多人甚至不会问“特征是否足够预测结果,还是需要更多特征”这个问题。

**每位患者的数据不足:**我们来看看上面的数据集。如果你注意到,每个特征下只有一个数据点。根本性的问题在于血压、胆固醇、心跳等特征不是静态的。它们是有范围的。一个人的血压每小时和每天都可能变化,心跳也是如此。因此,当涉及到预测问题时,无法确定 135 mm hg 的血压是否是导致心脏病的因素,还是 140 mm hg,而数据集可能报告的是 130 mm hg。理想情况下,每个特征应对每位患者进行多次测量。
现在让我们来探讨问题的核心。
在没有领域经验的情况下应用算法 - 数据科学应用在医疗保健中失败率高的原因之一是,应用算法的数据科学家缺乏足够的医学知识。
其次,在医疗保健中,因果关系被非常重视。进行许多严格的临床和统计测试以推断因果关系。
在案例研究中,任何机器学习算法只是试图将输入映射到输出,同时减少一些误差度量。此外,机器学习算法本身不是分类器,我们通过设置一些切割点或阈值将其作为分类器。再次强调,这些切割点不是为了推导因果关系,而只是为了获得“有利的指标”。
这个问题被低代码库的使用所加剧。这个案例研究恰恰展示了低代码库可能危险的原因。低代码库适合十几种或更多的算法。大多数人甚至不知道这些算法中的一些是如何工作的!他们只是根据像 F1、精准率、召回率和准确率这样的指标选择“最佳”算法。
专注于准确性指标的低代码库导致了‘古德哈特法则’——“当一个衡量标准成为目标时,它就不再是一个好的衡量标准。”

图片来源:https://sketchplanations.com/goodharts-law
如果你在进行预测,你就暗示了因果关系。在医疗保健中,单纯的预测是不够的,需要证明因果关系。机器学习分类算法无法回答‘因果关系’的问题。
认为他们解决了一个真正的医疗保健问题 – 最后但同样重要的是,许多人认为,通过将机器学习算法应用于医疗保健数据集并获得一些准确性指标,他们已经解决了一个真正的医疗保健问题。尤其是在涉及医疗保健领域时,没有什么比这更远离真相的了。
总结:
也许有成千上万的商业问题真正需要数据科学/机器学习解决方案。但与此同时,人们不应陷入“对一个拿着锤子的人来说,所有的东西都像钉子”的陷阱。把一切都看作钉子(数据科学问题),把机器学习算法看作(锤子),可能会非常适得其反。数据科学在商业问题中的 80%失败率很大程度上可以归因于此。
优秀的数据科学家就像优秀的医生。优秀的医生会在开重药或手术前首先建议保守的治疗。同样,优秀的数据科学家在盲目应用多个机器学习算法之前,应首先提出一些相关的问题。
医生:手术 :: 数据科学家 : 机器学习
欢迎您的评论和意见。
个人简介:Venkat Raman 是一位具有商业头脑的数据科学家。他通过数据科学帮助企业蓬勃发展。他在创新和将数据科学技术应用于商业问题方面有着良好的业绩记录。他是一个永恒的知识追求者,并相信对任何任务都应尽最大努力。
原文。已获得许可转载。
相关内容:
-
人工智能将如何变革医疗保健(它能解决美国医疗系统的问题吗?)
-
用于精准医学和更好医疗保健的人工智能
-
医疗保健中的人工智能:创新初创公司的回顾
相关主题
预测:2015 年分析和数据科学招聘市场
原文:
www.kdnuggets.com/2015/01/predictions-2015-analytics-data-science-hiring-market.html
当我写下2014 年的预测时,我写到由于大数据的存在,分析已变得不可避免。展望 2015 年,我比以往任何时候都更相信这一点。
这不仅仅是公众关注的分析问题——数据科学也被推到了聚光灯下,分析专业人员和数据科学家的招聘市场已经进入了过度驱动阶段。尽管薪资上涨公司仍然在努力招聘,而且有才华的专业人员几乎比你打个响指的速度还要快地进出市场。虽然保持求职技能的敏锐依然至关重要,但现在对于寻求工作的量化分析师来说,没有比现在更好的时机了。
那么这些兴奋的迹象对明年意味着什么呢?我有几个预测:
-
如果你不是数据迷,就忘了 C 级高管的位置——也许不是明年的情况,但这是商业发展的方向。有效管理任何大型组织的复杂性已经显著升级,未来的成功将取决于任何 C 级领导者对“大数据”的敏锐程度。
-
传统的财富 100 强公司加入数据科学热潮——随着数据科学趋势的不断加剧,我预测传统公司将建立他们的数据科学团队。尽管去年仍存在一些困惑和犹豫,今年将看到更多的投资和招聘计划。我收到的公司询问电话数量显著增加,我预计这种情况将持续到 2015 年。从谷歌、LinkedIn、亚马逊或 Uber 等科技公司,到 Gap、苏黎世保险、通用汽车、Clorox 和 AIG 等传统公司,各行各业的组织都在加入数据科学的热潮中。
-
加州失去光彩 – 几乎一半的数据科学家——这些大数据运动中的关键人物——都在西海岸为技术和游戏公司工作。然而,加州的城市占据了美国房价最高的前十个城市中的九个,而且租金也非常高。然而,我预测加州热潮将会减退的最大原因是,专业人士们将开始意识到,在金州之外有很多高薪工作,这些工作可能提供更多的机会来产生可衡量的影响、推动职业发展,或在公司中领导大数据计划,而不是成为大型科技公司中的“另一个量化分析师”。
-
招聘初创公司变得更加困难 – 初创公司泡沫几年的时间,热潮刚刚开始消退,但我预测明年初创公司吸引顶尖人才的能力将会减弱。专业人士将不再盲目跳槽到初创公司,希望获得一场彩票般的成功,因为他们看到许多同事失败了。
-
分析与数据科学之间的界限模糊 – 随着更多预测分析专业人士习惯于处理非结构化数据,我相信分析将会自然演变,更多的分析专业人士将掌握处理数据科学中常见的非结构化数据所需的技能。想知道成为数据科学家需要什么吗?这里是我列出的必备数据科学技能 ,这是公司都在寻找的。
-
训练营和 MOOCs 继续风靡 – 希望弥补人才缺口的公司正在寻找更快的方式来提高员工技能,而希望获得新技能的专业人士则在寻找快速的入门课程。这些项目在准备学生方面的成功如何还有待观察,但只要你有强大的定量基础,它们是更快、更便宜的过渡方式。查看这篇文章以了解更多关于这些不同学习方法的内容。
-
告别 Hadoop,迎接 Spark!SAS,那是什么? – 如果相信谷歌的话,那么 Hadoop 正逐渐退出大数据的讨论。除了 Hortonworks 最近的 IPO 外,我听到的消息全是关于 Spark 的。编程语言如 R 和 Python 无处不在,我相信未来在于开源工具;正如总是保持工具的新鲜度对成功至关重要一样,这一领域快速发展的特点也要求如此。
-
分析师薪资区间上涨 – 根据我们的薪资研究报告,预测分析薪资(非管理层)的平均为$88.4k,平均奖金 11%,管理层的薪资为$160k,奖金 19.1%。此外,这些薪资正在上涨。数据科学家的薪资更高,非管理层的平均薪资为$120k,平均奖金 14.5%,管理层的薪资为$183k,奖金 19.5%。想要招聘大数据专业人才的公司需要确保薪资竞争力,并且考虑其他吸引人才的方式,特别是考虑到他们可能面临多个竞争报价。欲了解分析师、数据科学家和市场研究专业人员的完整薪资信息,可以免费下载我们所有的薪资研究报告。
原文: www.burtchworks.com/2015/01/12/predictions-2015-analytics-data-science-hiring-market/
相关:
-
成为数据科学家需要具备的 9 项必备技能
-
招聘量化分析师,请修正您的招聘流程
-
难以捉摸的数据科学家推动高薪资
更多相关话题
人工智能、分析、机器学习、数据科学、深度学习研究 2019 年的主要发展及 2020 年的关键趋势
原文:
www.kdnuggets.com/2019/12/predictions-ai-machine-learning-data-science-research.html
评论
又到年末了,这意味着是时候进行 KDnuggets 年度年终专家分析和预测。今年我们提出了这个问题:
2019 年人工智能、数据科学、深度学习和机器学习的主要发展是什么?2020 年你期望哪些关键趋势?
我们的前三大课程推荐
 1. Google 网络安全证书 - 加入网络安全领域的快车道。
1. Google 网络安全证书 - 加入网络安全领域的快车道。
 2. Google 数据分析专业证书 - 提升你的数据分析能力
2. Google 数据分析专业证书 - 提升你的数据分析能力
 3. Google IT 支持专业证书 - 支持你组织的 IT 需求
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
回顾我们专家一年前的预测,我们看到了一些可以被视为自然技术进步的混合,以及一些更为雄心勃勃的预测。出现了一些普遍的主题,以及几个值得注意的单独预测。
尤其是,对人工智能的持续担忧被多次提及,这一预测确实似乎已经实现。有关自动化机器学习的进展的讨论普遍存在,但关于它是否有用还是会失败的观点意见不一。我认为这在一定程度上仍未定论,但当对技术的期望得到缓解时,它更容易被视为一种有用的补充,而不是一个即将取代的存在。增加善用人工智能也被特别提到,原因充分,且有大量例子可以证明这一预测的准确性。提出实用机器学习将迎来考验的观点,标志着趣味和游戏的时代即将结束,现在是机器学习需要有所作为的时候了。这一点确实符合实际,越来越多的从业者正在寻找这些机会。最后,提到对反乌托邦人工智能发展(包括监控、恐惧和操控)的担忧,可以通过对过去一年新闻的简单检查,自信地将其归入成功预测的类别。
也有一些预测尚未实现。这在这样的活动中是不可避免的,我们将把这些留给感兴趣的读者自行探索。
今年我们的专家名单包括 Imtiaz Adam、Xavier Amatriain、Anima Anandkumar、Andriy Burkov、Georgina Cosma、Pedro Domingos、Ajit Jaokar、Charles Martin、Ines Montani、Dipanjan Sarkar、Elena Sharova、Rosaria Silipo 和 Daniel Tunkelang。我们感谢他们从繁忙的年终日程中抽出时间为我们提供见解。
这是未来一周中 3 篇类似文章的第一篇。虽然这些文章将分别涉及研究、部署和行业,但这些学科之间存在相当大的重叠,因此我们建议你在发布时查看所有 3 篇文章。

不再耽搁,以下是今年专家组对 2019 年关键趋势和 2020 年预测的分析。
Imtiaz Adam (@DeepLearn007) 是一位人工智能与战略执行官。
2019 年,各组织对数据科学中的伦理和多样性问题有了更高的意识。
《彩票票假设》论文展示了用剪枝简化深度神经网络训练的潜力。《神经符号概念学习者》论文展示了将逻辑与深度学习结合起来,提升数据和记忆效率的潜力。
GANs 的研究获得了动力,深度强化学习尤其受到了大量研究关注,包括逻辑强化学习和用于参数优化的遗传算法等领域。
TensorFlow 2 带来了集成了 Keras 的 eager execution 默认模式。
2020 年,数据科学团队和商业团队将更加整合。5G 将成为智能物联网增长的催化剂,边缘的 AI 推理意味着 AI 将越来越多地进入物理世界。深度学习与增强现实的结合将改变客户体验。
Xavier Amatriain (@xamat) 是 Curai 的联合创始人兼首席技术官。
我认为,很难争辩这一点:这一年确实是深度学习和自然语言处理的年份。更具体地说,是语言模型的年份。甚至更具体地说,是 Transformers 和 GPT-2 的年份。是的,可能很难相信,但自 OpenAI 首次发布谈论他们的GPT-2 语言模型已经不到一年。这篇博客文章引发了关于 AI 安全的大量讨论,因为 OpenAI 对发布该模型感到不安。从那时起,该模型被公开复制,并最终发布。然而,这并不是这一领域唯一的进展。我们看到 Google 发布了AlBERT或XLNET,并谈论 BERT 是近年来对 Google 搜索的最大改进。从Amazon和Microsoft到Facebook,每个人似乎都真正投身于语言模型革命中,我期待在 2020 年看到这一领域的令人印象深刻的进展,似乎我们越来越接近通过图灵测试。
Anima Anandkumar (@AnimaAnandkumar) 是 NVIDIA 的机器学习研究主任和加州理工学院的布伦教授。
研究人员旨在更好地理解深度学习及其泛化特性和失败案例。减少对标记数据的依赖是关键焦点,自我训练等方法获得了关注。模拟变得在 AI 训练中更加相关,并在如自动驾驶和机器人学习等视觉领域变得更为逼真,包括在 NVIDIA 平台如 DriveSIM 和 Isaac 上。语言模型变得越来越庞大,例如 NVIDIA 的 80 亿参数 Megatron 模型在 512 个 GPU 上训练,并开始生成连贯的段落。然而,研究人员发现这些模型中存在虚假的相关性和不良的社会偏见。AI 监管成为主流,许多知名政治家表示支持政府机构禁止面部识别。AI 会议开始执行行为规范,并增加了提高多样性和包容性的努力,从去年 NeurIPS 更名开始。在即将到来的一年里,我预测将会有新的算法发展,而不仅仅是深度学习的肤浅应用。这将特别影响“科学中的 AI”,如物理学、化学、材料科学和生物学等许多领域。
Andriy Burkov (@burkov) 是 Gartner 的机器学习团队负责人,且是《百页机器学习书》的作者。
主要的发展无疑是 BERT,这种语言建模神经网络模型提高了几乎所有任务的自然语言处理质量。谷歌甚至将其作为相关性的主要信号之一——多年来最重要的更新。
在我看来,关键趋势将是 PyTorch 在行业中的更广泛应用,对更快的神经网络训练方法和在便捷硬件上快速训练神经网络的研究增加。
乔治娜·科斯马 (@gcosma1) 是拉夫堡大学的高级讲师。
在 2019 年,我们欣赏到深度学习模型的令人印象深刻的能力,例如 YOLOv3,特别是在实时物体检测等各种复杂计算机视觉任务中。我们还看到生成对抗网络继续在深度学习社区中受到关注,尤其是在图像合成方面,如 BigGAN 模型在 ImageNet 生成中的应用,以及 StyleGAN 在人体图像合成中的应用。今年我们还意识到欺骗深度学习模型的容易程度,一些研究还表明深度神经网络容易受到对抗性示例的攻击。在 2019 年,我们还见证了偏见的 AI 决策模型被用于面部识别、招聘和法律应用中。2020 年,我预计会看到多任务 AI 模型的发展,这些模型旨在通用且多功能,同时也期待看到对伦理 AI 模型的兴趣增加,因为 AI 正在改变健康、金融服务、汽车及其他许多领域的决策。
佩德罗·多明戈斯 (@pmddomingos) 是华盛顿大学计算机科学与工程系的教授。
2019 年的主要发展:
-
上下文嵌入的迅速传播。它们虽然不到两岁,但现在已主导了自然语言处理,谷歌已经在其搜索引擎中部署了这些嵌入,据报道改善了 10%的搜索结果。从视觉到语言,先在大数据上预训练模型,然后针对特定任务进行调整,已成为标准做法。
-
双重下降的发现。我们对过度参数化模型如何在完全拟合训练数据的同时进行良好泛化的理论理解显著提高,特别是对于观察到的现象的候选解释——与经典学习理论预测相反——即随着模型容量的增加,泛化误差先下降,再上升,然后再次下降。
-
媒体和公众对 AI 进展的看法变得更加怀疑,对自动驾驶汽车和虚拟助手的期望降低,华而不实的演示也不再被轻信。
2020 年的关键趋势:
-
深度学习圈试图从低级感知任务如视觉和语音识别“爬升”到高级认知任务如语言理解和常识推理的速度将会加快。
-
依靠不断增加数据和计算能力来获得更好结果的研究模式将达到其极限,因为它处于一个比摩尔定律更陡峭的指数成本曲线上,已经超出了即使是富有公司能够承担的范围。
-
如果运气好的话,我们将进入一个黄金时代,在这个时代里,既没有关于人工智能的过度炒作,也没有另一个人工智能寒冬。
Ajit Jaokar (@AjitJaokar) 是牛津大学“人工智能:云和边缘实现”课程的课程主任。
在 2019 年,我们在牛津大学重新品牌了我们的课程,改为人工智能:云和边缘实现。这也反映了我个人的观点,即 2019 年是云计算成熟的一年。这一年,我们所谈论的各种技术(大数据、人工智能、物联网等)在云计算的框架内汇聚在一起。这一趋势将继续——特别是对于企业。公司将进行“数字化转型”——他们将利用云作为统一的范式来转型由人工智能驱动的过程(有点像重新工程化企业 2.0)。
在 2020 年,我还看到自然语言处理的成熟(BERT、Megatron)。5G 将继续部署。我们将在 5G 全面部署后看到物联网的更广泛应用(例如:自动驾驶汽车)。最后,在物联网方面,我关注一种叫做 MCU(微控制器单元)的技术——特别是机器学习模型在 MCU 上的部署。
我相信人工智能是一个颠覆性的变化,每天我们都能看到令人着迷的人工智能应用实例。艾尔文·托夫勒在《未来冲击》中预测的许多情景今天已经发生——人工智能将如何进一步放大这些变化仍待观察!遗憾的是,人工智能的变化速度将让许多人被抛在后面。
Charles Martin 是人工智能科学家、顾问及 Calculation Consulting 的创始人。
BERT、ELMO、GPT2 等等!2019 年的人工智能在自然语言处理领域取得了巨大进展。OpenAI 发布了他们的大型 GPT2 模型——即文本的深度伪造。谷歌宣布使用 BERT 进行搜索——自 Panda 以来最大的一次变化。即使是我在加州大学伯克利分校的合作者也发布了(量化的)QBERT 以适应低足迹硬件。现在每个人都在制作自己的文档嵌入。
这对 2020 年意味着什么?根据搜索专家的说法,2020 年将是相关性*(嗯,他们都在做什么?)*的年份。预计向量空间搜索将最终获得 traction,采用 BERT 风格的精细调优嵌入。
在 2019 年,PyTorch 超过 Tensorflow 成为 AI 研究的首选。随着 TensorFlow 2.x 的发布(以及对 pytorch 的 TPU 支持),2020 年的 AI 编程将完全围绕急切执行展开。
大公司在 AI 方面取得进展了吗?报告显示成功率为 1/10。不太理想。因此,AutoML 在 2020 年将会受到需求,尽管我个人认为,就像制作出色的搜索结果一样,成功的 AI 需要特定于业务的定制解决方案。

伊内斯·蒙塔尼(@_inesmontani)是一位从事人工智能和自然语言处理技术的程序开发人员,并且是 Explosion 的联合创始人。
每个人都选择“DIY AI”而不是云解决方案。推动这一趋势的一个因素是迁移学习的成功,这使得任何人都可以用较高的准确性训练自己的模型,且能够针对非常具体的使用案例进行微调。由于每个模型只有一个用户,因此服务提供商无法利用规模经济。迁移学习的另一个优点是数据集不再需要那么大,因此标注工作也在内部进行。内部化的趋势是一个积极的发展:商业 AI 远比许多人预期的要分散。几年前,人们担心每个人都只会从一个提供商那里获取“他们的 AI”。然而,人们并没有从任何提供商那里获取 AI——他们自己动手做。
迪潘詹·萨尔卡 是 Applied Materials 的数据科学负责人,Google 开发者专家 - 机器学习,作者、顾问和培训师。
2019 年,人工智能领域的主要进展集中在 Auto-ML、可解释 AI 和深度学习方面。数据科学的民主化在过去几年中仍然是一个关键方面,各种与 Auto-ML 相关的工具和框架正试图简化这一过程。然而,仍需注意的是,我们在使用这些工具时必须小心,以确保不会得到有偏见或过拟合的模型。公平性、问责制和透明性仍然是客户、企业和公司接受 AI 决策的关键因素。因此,可解释 AI 不再只是研究论文中的话题。许多优秀的工具和技术已经开始使机器学习模型的决策更加可解释。最后但同样重要的是,我们看到深度学习和迁移学习,特别是自然语言处理领域的许多进展。我期待在 2020 年看到更多关于自然语言处理和计算机视觉的深度迁移学习研究和模型,希望能看到结合深度学习和神经科学精华的工作,从而引领我们迈向真正的 AGI。
埃琳娜·沙罗娃 是 ITV 的高级数据科学家。
到目前为止,2019 年最重要的机器学习进展是在玩游戏时使用深度强化学习,通过 DeepMind 的DQN和AlphaGo实现的;这导致了围棋冠军李世石的退休。另一个重要进展是在自然语言处理领域,Google 开源了 BERT(深度双向语言表示),而微软领导了 GLUE 基准并通过开发和开源 MT-DNN集成体用于发音分辨任务。
重要的是要强调欧洲委员会发布的《可信 AI 伦理指南》——这是首个设定合法、道德和稳健 AI 合理指南的官方出版物。
最后,我想和 KDnuggets 的读者分享的是,PyData London 2019的所有主题演讲者都是女性——这是一个令人欢迎的发展!
我预期 2020 年的主要机器学习发展趋势将继续集中在自然语言处理(NLP)和计算机视觉(computer vision)领域。采用机器学习(ML)和数据科学(DS)的行业已经认识到,他们在定义共享的最佳实践标准方面已经滞后,包括招聘和留住数据科学家、管理涉及 DS 和 ML 的项目复杂性,以及确保社区保持开放和合作。因此,我们应该会看到未来会更多关注这些标准。
Rosaria Silipo(@DMR_Rosaria)是 KNIME 的首席数据科学家。
2019 年最令人期待的成就是主动学习、强化学习和其他半监督学习程序的采用。半监督学习可能为处理目前充斥我们数据库的未标记数据带来希望。
另一个伟大的进展是将 autoML 概念中的“auto”纠正为“guided”。对于更复杂的数据科学问题,专家干预似乎是不可或缺的。
在 2020 年,数据科学家将需要一个快速的解决方案来进行模型部署、持续模型监控和灵活的模型管理。真正的商业价值将来自数据科学生命周期的这三个最终部分。
我还相信,深度学习黑箱的更广泛应用将引发机器学习解释性(MLI)的问题。我们将在 2020 年底看到 MLI 算法是否能够应对解释深度学习模型内部运作的挑战。
Daniel Tunkelang (@dtunkelang) 是一名独立顾问,专注于搜索、发现和机器学习/人工智能。
人工智能的前沿依然专注于语言理解和生成。
OpenAI 宣布了 GPT-2 以预测和生成文本。OpenAI 当时没有发布训练模型,担心恶意应用,但最终他们 改变了主意。
谷歌发布了一款 80MB 的设备端语音识别器,使得在移动设备上进行语音识别成为可能,而无需将数据发送到云端。
与此同时,我们看到对人工智能和隐私的担忧越来越严重。今年,所有主要的数字助手公司都遭遇了员工或承包商监听用户对话的反对声。
2020 年人工智能会发生什么?我们将看到对话式人工智能的进一步发展,以及更好的图像和视频生成。这些进展将引发更多关于恶意应用的担忧,我们可能会看到一两起丑闻,尤其是在选举年。善与恶的人工智能之间的紧张关系不会消失,我们必须学习更好的应对方式。
相关:
-
2018 年机器学习与人工智能的主要发展及 2019 年的关键趋势
-
2018 年人工智能、数据科学、分析的主要发展及 2019 年的关键趋势
-
行业预测:2018 年人工智能、机器学习、分析与数据科学的主要发展及 2019 年的关键趋势
更多相关话题
AI、分析、机器学习、数据科学、深度学习技术 2019 年的主要进展和 2020 年的关键趋势
原文:
www.kdnuggets.com/2019/12/predictions-ai-machine-learning-data-science-technology.html
评论在 2019(以及之前的几年),我们询问了一些顶尖专家他们对 2020 年的预测。
去年预测的一些趋势已经显现:
-
对 AI 伦理的更多关注
-
数据科学的民主化
-
强化学习的进展
-
中国在 AI 领域的成功增长
2019 年也有一些惊喜——去年的专家们没有预测到自然语言处理的突破(如 GPT-2 以及其他版本的 BERT 和 Transformers)。
我们今年再次询问了我们的专家:
2019 年人工智能、数据科学、深度学习和机器学习的主要进展是什么?你对 2020 年有何关键趋势预期?
我们收到了大约 20 个回复,第一部分,主要关注研究,已经发布。
这是第二部分,更加关注技术、行业和部署。一些共同的主题包括:AI 炒作、AutoML、云计算、数据、可解释 AI、AI 伦理。
这里是 Meta Brown、Tom Davenport、Carla Gentry、Nikita Johnson、Doug Laney、Bill Schmarzo、Kate Strachnyi、Ronald van Loon、Favio Vazquez 和 Jen Underwood 的回答。

Meta Brown,@metabrown312,是《Data Mining for Dummies》的作者和 A4A Brown 的主席
在 2018 年,我们看到“人工智能”一词的使用剧增,这一术语被用来描述从真正复杂的应用程序和日益成功的自动驾驶汽车到在直销中使用的普通倾向评分。我预测在 2019 年,人们会意识到这全是数学。我有一半的预测是对的。
一方面,越来越多的人开始看到现在所谓的“AI”的局限性。公众意识到面部识别技术可以被 Juggalo 化妆所干扰,客户服务聊天机器人背后没有智能生命,试图让软件比医生更聪明可能花费数百万仍然可能失败。
尽管如此,“人工智能”仍然是一个热门的流行词,风险投资的钱仍在不断涌入。2019 年前 9 个月,AI 初创企业获得了超过 130 亿美元的投资。
在 2020 年,预计人工智能的两种前景之间会出现越来越明显的二分化:一种是公众对 AI 的疑虑、怀疑和对其局限性的认识不断增长;另一种是商业和投资界继续对 AI 的承诺投入希望、梦想和资金。
汤姆·达文波特、@tdav 是巴布森学院信息技术与管理的总统杰出教授,国际分析学会的联合创始人,麻省理工学院数字经济倡议的研究员,以及德勤分析的高级顾问。
2019 年的主要发展:
-
在数据科学的更结构化方面,自动化机器学习工具的广泛部署。
-
广泛认识到分析和人工智能具有需要有意识地解决的伦理维度。
-
越来越多的人认识到,大多数分析和人工智能模型没有被部署,结果对创建这些模型的组织没有价值。
2020 年的即将发展:
-
提供创建、管理和监控组织的机器学习模型套件的工具,重点是对漂移模型进行持续重新训练和模型库存管理。
-
对分析和人工智能翻译员的地位和认可有所改善,他们与业务用户和领导者合作,将业务需求转化为模型的高级规范。
-
认识到模型与数据的契合度只是决定其是否有用的一个考虑因素。
卡拉·根特里、@data_nerd 是咨询数据科学家和 Analytical-Solution 的所有者。
又一年关于人工智能、机器学习和数据科学能做什么和不能做什么的炒作,我对大量未经培训的专业人士涌入这些领域感到不安,以及那些不断颁发所谓认证和学位的学院,教师们根本没有资格教授这些课程。
数据科学和机器学习依赖于大量数据,但我们面临另一年的偏见误解,数据需要解释总是存在偏见风险。无偏数据是独立的,不需要解释,例如 - 玛丽通过增加销售投资回报率 10%与玛丽是个勤奋工作的人,这是一种意见,无法衡量。
前几天有一篇文章的标题引起了我的注意“数据科学正在衰退吗”?我在阅读之前的初步想法是“不是,但所有那些想当专家和炒作确实没有帮助我们的领域 - 数据科学不仅仅是编写代码”。对技术的误解加上缺乏数据和必要的基础设施将继续困扰我们,但至少有些人意识到 21 世纪最性感的工作其实并不那么性感,因为我们大部分时间都在清洗和准备数据,然后才能获得洞察并回答业务问题。
在 2020 年,让我们都记住,关键在于数据,并确保我们能够以诚信和透明度推动我们的领域发展。要想继续朝着积极的方向前进,AI 的“黑箱”时代必须结束。记住,你所构建的算法、模型、聊天机器人等可能会对某人的生活产生影响,数据库中的数据点对应的是一个生命,因此要消除你的偏见,让事实本身说话……像往常一样,享受数据的乐趣,并负责任地使用数据。
尼基塔·约翰逊,@teamrework,创始人,RE.WORK 深度学习与 AI
在 2019 年,我们见证了多个领域的突破,这些突破使得 AI 得到了前所未有的广泛应用。先进的软件技术,如迁移学习和强化学习,也帮助推动了 AI 突破和应用的进展,帮助分离系统改进与我们作为人类的知识限制。
明年 2020 年,我们将看到向“可解释 AI”的转变,以提供更多的透明度、问责制和 AI 模型及技术的可重复性。我们需要增加对每种工具的局限性、优缺点的了解。增强的学习将提高我们与所用产品建立信任的能力,同时也让 AI 的决策更具合理性!
道格·拉尼,@Doug_Laney,首席数据策略师,Caserta,《信息经济学》畅销书作者,伊利诺伊大学 Gies 商学院客座教授
AI 从 90 年代早期的辉煌日子复苏,以及数据科学的主流化,完全是由数据推动的。今天的大数据“只是数据”。尽管其规模不断扩大,但不再会压倒存储或计算能力。至少现在没有任何组织会因为数据庞大而受到阻碍。(提示:云计算。)确实,渐进改进的技术和方法已经出现,但来自社交媒体平台的数据泛滥、伙伴间的数据交换、从网站采集的数据以及来自连接设备的数据滴漏,带来了前所未有的洞察、自动化和优化。这也催生了新的数据驱动业务模型。
在 2020 年,我设想(没有恶意,或者说有点恶意?)扩展的信息生态系统将出现,进一步促进 AI 和数据科学驱动的商业伙伴数字协调。一些组织可能会选择自建数据交换解决方案,以货币化他们及他人的信息资产。其他组织则会通过区块链支持的数据交换平台和/或数据聚合器提供各种替代数据,来推动其高级分析能力。
Bill Schmarzo,@schmarzo,是 Hitachi Vantara 的首席技术官,负责物联网与分析。
2019 年的主要发展
-
在智能手机、网站、家居设备和车辆中集成 AI,日益增长的“消费者验证点”。
-
数据工程角色日益重要,数据操作(DataOps)类别的正式化也证明了这一点。
-
在高管层中对数据科学业务潜力的尊重日益增加。
-
首席信息官(CIO)继续在兑现数据货币化承诺方面遇到困难;数据湖的失望导致数据湖的“第二次手术”。
2020 年的关键趋势
-
更多现实世界的例子展示了工业公司如何利用传感器、边缘分析和 AI 创建随着使用变得更智能的产品;这些产品在使用过程中价值上升,而非贬值。
-
由于无法提供合理的财务或运营影响,宏大的智能空间项目仍然在初始试点阶段挣扎,难以进一步发展。
-
经济衰退将加大“拥有者”和“非拥有者”之间的差距,特别是在利用数据和分析推动有意义的业务成果的组织中。
Kate Strachnyi,@StorybyData,致力于用数据讲述故事 | 跑者 | 两个孩子的妈妈 | 数据科学与分析领域的顶级声音。
2019 年,我们看到数据可视化/商业智能软件领域的整合;Salesforce 收购了 Tableau 软件,Google 收购了 Looker。这些对商业智能工具的投资展示了公司对数据民主化和使用户更容易查看和分析数据的重视。
我们可以预期 2020 年将继续向自动化数据分析/数据科学任务转变。数据科学家和工程师需要可以扩展的工具来解决更多问题。这种需求将促使自动化工具在数据科学过程的多个阶段得到开发。例如,某些数据准备和清洗任务已经部分自动化,但由于公司的独特需求,完全自动化仍然困难。其他自动化候选任务包括特征工程、模型选择等。
Ronald van Loon,@Ronald_vanLoon,广告总监,帮助数据驱动的公司取得成功。大数据、数据科学、物联网、AI 领域的 Top10 影响者
在 2019 年,行业见证了可解释 AI 和增强分析的日益采用,这使得企业能够弥合 AI 潜力与基于无偏见 AI 结果的决策技术复杂性之间的差距。全栈 AI 方法是 2019 年的另一项发展,组织们接受了这种方法,以帮助加快创新路径并支持 AI 增长,同时改善不同团队和个人之间的集成与沟通。
在 2020 年,我们将看到一些由于对话式 AI 易用性和直观界面而出现的客户体验改进趋势。这种自动化解决方案使公司能够扩大规模并转变客户体验,同时提供 24/7 的客户通道,并提供快速问题解决和可靠的自助服务机会。此外,狭义智能将继续支持我们如何最有效地利用人类和机器的优势,同时将 AI 融入我们的现有流程,并努力改变我们向 AI 提出的问题。
Favio Vazquez、@FavioVaz,Closter 的首席执行官
在 2019 年,我们看到了人工智能最前沿领域的惊人进展,主要集中在深度学习方面。数据科学有能力利用这些进展解决更难的问题并塑造我们所生活的世界。数据科学是利用科学催化变革并将论文转化为产品的引擎。我们的领域不再仅仅是“炒作”,它正在成为一个严肃的领域。我们将看到关于数据科学及其相关领域的重要在线和离线教育的增加。希望我们能对所做的工作及其方式更有信心。语义技术、决策智能和知识数据科学将在未来几年成为我们的伙伴,因此我建议大家开始探索图数据库、本体论和知识表示系统。
Jen Underwood、@idigdata,推动组织更快发展的自然力量
在 2019 年,我们达到了一个关键点,即组织必须认真对待在算法经济中的竞争。市场领先的公司通过规划企业范围的 AI 战略,提高了数据科学的显著性,而不是仅仅赞助一次性的项目。与此同时,成熟的数据科学组织启动了伦理、治理和 ML Ops 计划。不幸的是,尽管机器学习的采用率有所提高,但大多数人仍未取得成功。
从技术角度来看,我们见证了混合分布式计算和无服务器架构的兴起。同时,算法、框架和 AutoML 解决方案迅速从创新发展到商品化。
我预计 2020 年个人数据安全、监管、算法偏见和深度伪造话题将主导头条新闻。欣慰的是,可解释 AI 的进步以及自然语言生成和优化技术将有助于弥合数据科学与商业之间的差距。随着数据素养和公民数据科学项目的进一步出现,机器学习从业者应继续蓬勃发展。
这是基于他们预测的词云

相关:
更多相关内容
行业预测:2018 年 AI、机器学习、分析与数据科学的主要进展以及 2019 年的关键趋势
 评论
评论
随着我们继续为 KDnuggets 读者带来年终总结和 2019 年的预测,我们向许多有影响力的行业公司征询了他们的看法,提出了这个问题:
2018 年 AI、机器学习、分析与数据科学的主要进展是什么?你预期 2019 年会有什么关键趋势?
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
 3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
对于行业对今年发生的事件及未来发展趋势的看法,我们收集了来自 Domino Data Lab、dotData、Figure Eight、GoodData、KNIME、MapR、MathWorks、OpenText、ParallelM、Salesforce、Splice Machine、Splunk 和 Zoomdata 的见解。

这些专家指出的关键主题包括变化中的分析格局、数据科学如何继续影响业务,以及将被用来实现这一点的新兴技术。
一定要查看我们上周分享的收集意见,当时我们向一组专家提出了相关问题,“2018 年数据科学和分析的主要进展是什么?你预期 2019 年会有什么关键趋势?”
Josh Poduska 是 Domino Data Lab 的首席数据科学家。
AI:从炒作到 2019 年的业务影响。人工智能的蜜月期正式结束。2019 年将是人工智能成为组织现实的一年,而非实验、调试和疑虑。
忘记谷歌的 AI 呼叫中心代理。数据科学的最大影响将体现在你未曾想到的地方……在业务中那些较少“性感”的部分,比如更快的客户技术支持电话服务、优化库存、更智能的产品摆放、减少购买中的浪费时间等。
消费者对 AI 的理解将会发生剧烈变化。我们将不再将 AI 与未来的机器人和自动驾驶汽车联系在一起,而是与提升生产力的工具和帮助日常琐事的预测联系在一起。
藤卷亮平博士是 dotData 的首席执行官兼创始人,该公司专注于为企业提供端到端的数据科学自动化和操作化。
对从 AI 和 ML 项目中获得更大投资回报的压力将推动更多商业领袖寻求创新解决方案。 尽管许多行业正在对数据科学进行大量投资,但数据科学技能和资源的稀缺限制了组织内 AI 和 ML 项目的进展。此外,由于过程的迭代性质和数据准备及特征工程的手动工作,一支数据科学团队每年只能执行几个项目。到 2019 年,数据科学自动化平台将占据大量思维份额。数据科学自动化将涵盖比机器学习自动化更广泛的领域,包括数据准备、特征工程、机器学习和数据科学管道的生产。这些平台将加速数据科学,执行更多商业举措,同时保持当前的投资和资源。
数据科学任务将变成 5 分钟的操作,并在几天内带来业务价值。 过去需要几个月时间的数据科学项目已经不再存在。到 2019 年,我们将看到企业在实施和优化他们的 AI 和机器学习项目方面发生转变。新的数据科学自动化平台提供了一个单一的、无缝的平台,使公司能够加速、普及和操作整个数据科学过程——从原始数据到特征工程再到机器学习——消除数据科学中最耗时、最劳动力和技能密集的任务。因此,曾经需要几个月完成的工作,现在只需几天,这大大加快了 AI 和机器学习项目的价值实现时间。
戴尔·布朗是 Figure Eight 的业务发展副总裁。
-
AI 平台供应商将创建更多工具,以便非数据科学家/开发者能够更快地构建 AI - “随着公司对 AI 需求的增加,我们也看到训练有素的数据科学家持续短缺。为了提高 AI 的采用,AI 平台需要赋能传统开发者,提供工具以使他们能够更快地创建机器学习模型,并确保他们拥有一个集成平台,允许开发者注释和标记数据,以提高模型的准确性。”
-
企业级 AI 集成与整合将会发生 - “AI 的广泛采用将迫使企业级公司要么加速开发 AI 相关工具,要么收购并将其整合到他们的平台中——速度要快于他们的竞争对手。”
凯文·史密斯是 GoodData 的产品营销副总裁。
数据科学家的需求将发生急剧变化。数据科学家,曾被认为是 21 世纪最性感的职业,将与我们今天所知的非常不同。随着分析被推向最终用户,自助服务成为常态,数据准备工具变得更加强大,数据科学家将更多地转变为顾问,而不是数据来源和准备专家。他们将负责帮助企业理解数据、解释结果以及可能采取的行动方案。这对数据科学家而言是一个更高价值的角色,最终也是更好地利用他们的技能。
迈克尔·伯瑟尔德是KNIME的首席执行官。
我看到的两个持续的趋势是自动化和可解释性。前者将在 2019 年继续受到关注,但随后会面临一个问题,即只有相对明确的数据科学问题才适合完全自动化。更强大的环境是数据科学家可以将自动化与互动结合,真正允许他们将数据科学部署给他人,而不必将所有工作外包给自称的专家。对于所有需要理解(或控制)基础决策的数据类型,深度学习的可解释性将变成一个更大的问题。我们永远不会接受 AI 在安全关键决策中的“人为失败”。
杰克·诺里斯是MapR的数据和应用高级副总裁。
2019 年是容器和人工智能在主流中相遇的一年 - NVIDIA 在今年年底宣布了开源 Rapids。这预示着在操作化 AI、数据科学家之间更好的共享以及在各地分布处理的关注点如何推动容器化。另一个推动这一预测的上升技术是 Kubeflow,它将补充容器和分布式分析。
塞斯·德兰是MathWorks的数据分析产品营销经理。
机器学习将被整合到产品和服务中 - 公司将越来越多地使用机器学习算法来使产品和服务“从数据中学习”并提高性能。机器学习已经出现在一些领域:图像处理和计算机视觉用于面部识别,能源生产的价格和负荷预测,工业设备故障预测等等。预计在来年,随着更多公司受到启发,将机器学习算法集成到他们的产品和服务中,机器学习将变得越来越普遍,这些公司将使用可扩展的软件工具,包括 MATLAB。
公司将利用领域专家来弥补数据科学技能差距——许多公司难以找到数据科学专才,企业正在为现有的工程师和科学家提供可扩展的工具,如 MATLAB,以使他们能够进行数据科学。由于这些工程师和科学家具有现有的流程和业务知识,他们将能够很好地应用数据科学技术,评估结果,并确定将模型与业务系统集成的最佳方法。
Zachary Jarvinen 是OpenText的技术战略、人工智能和分析部门负责人。
2019 年,长期承诺的企业人工智能转型将开始真正展开。大多数企业已经达到了数字成熟的阶段,确保能够大规模访问高质量数据。凭借成熟的数据集,人工智能供应商可以提供更低成本、更易于使用的人工智能工具,适用于特定的业务场景。大规模的企业人工智能效应将会非常显著。Gartner 预计,到 2022 年,人工智能的商业价值将达到近 3.9 万亿美元。消费者也将在几乎每个行业中受益。他们将看到更多创新的产品和服务、更智能的家居、工厂和城市、改善的健康状况以及更高的生活质量。
人工智能将增强——而不是取代——劳动力。人工智能应用将具有变革性,提高效率和性能,产生巨大的成本节省,并催生更多创新的产品和服务。然而,未来的工作将涉及人类和人工智能。最具创新性的公司已经开始规划如何最好地实现这种共生的未来。在短期内——这意味着数据科学领域的技术工人缺口将持续存在,需求将保持非常高。教育机会将扩展以帮助解决这一需求。在长期内——随着我们发展解锁人工智能的技能和技术,社会将从人工智能增强的工人、家居、车辆、电网、工厂、城市等方面受益巨大。
Sivan Metzger 是ParallelM的首席执行官,该公司在机器学习运营(MLOps)领域迅速成长。
其他业务领域将被引入,共享机器学习的责任。随着公司面临从竞争对手中脱颖而出的压力增加以及商业领袖的挫折感加剧,其他职能将被拉入以帮助实现机器学习计划。这些职能包括运营和业务分析师,他们可以在数据科学家完成机器学习模型的构建后,接过这些责任。
Ketan Karkhanis 是Salesforce的高级副总裁兼分析总经理。
AI 增强分析将成为主流 - 2019 年将是 AI 主导的分析(被称为自动化发现)成为主流的一年。人脑并不具备在亚秒速度下评估数百万种数据组合的能力,但机器学习正是为解决这个问题而构建的完美解决方案。企业领导者和数据分析师越来越明白,AI 不会取代工作,而是增强工作能力,我预计在未来一年中,大多数数据分析师将能够在无需编写代码的情况下掌握数据科学的力量。
Monte Zweben 是 Splice Machine 的首席执行官,这是一款用于实时应用的智能数据平台。
-
Hadoop 的新客户增长将减缓,Hadoop 集群的增长将放慢。
-
基于云的 SQL 数据平台将实现大规模增长
-
机器学习将进入运营阶段,从后台实验中走出,融入实时、关键任务的企业应用程序。
-
Oracle 的客户转向扩展 SQL 平台将达到一个点,届时公司将在季度披露中透露风险因素。
Andi Mann 是 Splunk 的首席技术倡导者。
-
2019 年将是机器学习在工作场所全面实现的一年——“AI 即服务(AIaaS)”的增加将涌入市场,为企业提供更多解决方案。
-
到 2019 年,工程招聘将继续上升,因为更多的组织需要工程师来帮助管理孤立的工具集成。
-
“工具为工具”的崛起,专注于更好地支持 IT 操作。
最终的预测来自 Zoomdata 的高管。
数据可视化的增长(由于数据结构化程度的提升) - 到 2019 年,企业将最终接受数据可视化,并看到其潜力。我们别无选择——数据增长是指数级的,并且由于物联网(见图表)变得越来越结构化。就像今天的消费者可以查看自己家的能耗并与邻居的能耗进行比较一样,我们将开始看到这种情况(终于!)渗透到供应链中。例如,自动化分析将发现一些有趣的内容,创建该项内容的可视化表示——然后向人类展示,以便采取行动。数据将从整个数据集中提取,使企业管理者能够以前所未有的方式看清全局。

相关信息:
-
行业预测:2017 年主要 AI、大数据、数据科学发展及 2018 年趋势
-
机器学习与 AI 在 2018 年的主要发展及 2019 年关键趋势
-
AI、数据科学、分析在 2018 年的主要发展及 2019 年的关键趋势
更多相关主题
2018 年机器学习与人工智能的主要发展及 2019 年的关键趋势
原文:
www.kdnuggets.com/2018/12/predictions-machine-learning-ai-2019.html
 comments
comments
在 KDnuggets,我们努力保持对行业、学术界和技术主要事件和发展的关注。我们还尽力展望即将出现的关键趋势。
在往年,我们曾带来过专家的预测和分析的集合。今年我们提出了以下问题:
2018 年机器学习和人工智能的主要发展是什么,您对 2019 年的关键趋势有什么预期?
以下是 Anima Anandkumar、Andriy Burkov、Pedro Domingos、Ajit Jaokar、Nikita Johnson、Zachary Chase Lipton、Matthew Mayo、Brandon Rohrer、Elena Sharova、Rachel Thomas 和 Daniel Tunkelang 的回应。

这些专家提到的关键主题包括深度学习的进展、迁移学习、机器学习的局限性、自然语言处理的变化趋势等。
请务必查看我们上周分享的意见,当时我们向一组专家询问了相关问题,“2018 年数据科学和分析的主要发展是什么,您对 2019 年的关键趋势有什么预期?”
Anima Anandkumar (@AnimaAnandkumar) 是 NVIDIA 的机器学习研究主任和加州理工学院的布伦教授。
2018 年机器学习和人工智能的主要发展是什么?
“深度学习的低垂果实已经基本被采摘完毕”
重点开始从标准的监督学习转向更具挑战性的机器学习问题,如半监督学习、领域适应、主动学习和生成模型。生成对抗网络(GANs)继续受到研究人员的热捧,他们尝试更困难的任务,如照片真实感(bigGANs)和视频到视频的合成。开发了替代生成模型(如神经渲染模型),以将生成和预测结合在一个网络中,以帮助半监督学习。研究人员将深度学习应用扩展到许多科学领域,如地震预测、材料科学、蛋白质工程、高能物理和控制系统。在这些情况下,领域知识和约束与学习相结合。例如,为了改善无人机的自主着陆,学习了地面效应模型来修正基础控制器,并且学习被保证是稳定的,这在控制系统中非常重要。
预测:
“人工智能将弥合模拟和现实之间的差距,使其更加安全和具备物理感知能力”
我们将看到新领域适应技术的发展,这些技术可以无缝地将知识从模拟环境转移到现实世界。模拟的使用将帮助我们克服数据稀缺问题,加速新领域和新问题的学习。从模拟到真实数据的适应(Sim2real)将在机器人技术、自动驾驶、医学影像、地震预测等领域产生重大影响。模拟是考虑所有可能情景的绝佳方式,尤其在安全关键应用如自动驾驶中。内置于复杂模拟器中的知识将以新的方式被利用,使 AI 更加具备物理意识,更加健壮,并能够推广到新的、未见过的情景。
安德烈·布尔科夫 (@burkov) 是 Gartner 的机器学习团队负责人。
这是我作为从业者的个人看法,并非基于研究的 Gartner 官方声明。以下是我的想法:
2018 年机器学习和人工智能的主要发展是什么?
TensorFlow 在学术界输给了 PyTorch。谷歌的巨大影响力和覆盖面有时可能会使市场走向次优方向,就像 MapReduce 和随后的 hadoop 狂热一样。
深度伪造(及其类似技术,包括声音)摧毁了最可信的信息来源:视频镜头。没有人再能够像以前那样说:我看到了那个家伙说这些话的视频。几十年前我们就不再相信印刷文字,但视频直到现在才变得不可靠。
强化学习以深度学习的形式卷土重来,这非常出乎意料且令人兴奋!
谷歌的系统可以代表你拨打餐厅电话,并成功地伪装成人类,这是一个重要的里程碑。然而,这也引发了许多关于伦理和 AI 的问题。
个人助手和聊天机器人很快达到了它们的极限。虽然它们比以往更出色,但仍未达到大家去年所期望的水平。
你期待 2019 年有哪些关键趋势?
-
我预计大家会比今年更为兴奋于 AutoML 的承诺。我也预期它会失败(除了某些非常具体和明确的用例,如图像识别、机器翻译和文本分类,在这些情况下,手工特征不是必需的,或者是标准的,原始数据接近机器所期望的输入,并且数据量充足)。
-
营销自动化:随着成熟的生成对抗网络和变分自编码器的发展,我们现在可以生成成千上万张同一人的照片或风景照片,这些图片之间仅有小的面部表情或情绪差异。根据消费者对这些图片的反应,我们可以生成最佳的广告活动。
-
在移动设备上实时生成的语音几乎无法与真人区分。
-
自动驾驶出租车将继续停留在测试/概念验证阶段。
佩德罗·多明戈斯 (@pmddomingos) 是华盛顿大学计算机科学与工程系的教授。
经过多年的炒作,2018 年是对人工智能的过度担忧的一年。听媒体和一些研究人员的话,你会认为剑桥分析公司在 2016 年选举中帮助特朗普赢得了胜利,机器学习算法充斥着偏见和歧视,机器人正来抢夺我们的工作甚至我们的生活。这不仅仅是空谈:欧洲和加利福尼亚已通过了严厉的隐私法律,联合国正在讨论禁止智能武器等。公众对人工智能的看法越来越黑暗,这既危险又不公平。希望 2019 年能是理智回归的一年。
阿吉特·贾奥卡尔 (@AjitJaokar) 是首席数据科学家以及牛津大学物联网数据科学课程的创始人。
2018 年,一些趋势开始兴起。自动化机器学习就是其中之一,强化学习则是另一个。这两种新兴趋势将在 2019 年显著扩展。作为我在牛津大学(物联网数据科学课程)教学的一部分,我看到物联网越来越多地融入到大型生态系统中,如自动驾驶汽车、机器人和智慧城市。通过与Dobot的合作,我认为协作机器人(cobots)是 2019 年的一个关键趋势。与之前的流水线机器人不同,新型机器人将具备自主性,并且能够理解情感(在我的课程中,我们还与情感研究实验室在这一领域合作)。最后,一个有些争议的观点是:在 2019 年,我们所知的数据科学家的角色将趋向于从研究转向产品开发。我认为人工智能将与下一代数据产品的创造更加紧密地联系在一起。数据科学家的角色也将随之变化。
尼基塔·约翰逊 (@nikitaljohnson) 是 RE.WORK 的创始人。
我们在 2018 年见证的一个发展是,开源工具数量的增加降低了入门门槛,使人工智能更加普及,确保了组织之间的更好合作。这些社区对确保人工智能在社会和商业所有领域的传播至关重要。
同样,在 2019 年,我们将看到更多公司专注于“善用 AI”,继承 Google 最近宣布的 AI for Social Good 项目,以及微软的 AI for Good 倡议。这种向积极影响的 AI 转变正在获得关注,因为社会要求公司具有更高的社会目的。
Zachary Chase Lipton (@zacharylipton) 是卡内基梅隆大学的机器学习助理教授及Approximately Correct Blog的创始人。
让我们从深度学习场景开始,它占据了公众对机器学习和人工智能讨论的主要份额。也许我会让一些人不悦,但这是对 2018 年的一个合理解读:最大的进展是没有进展!当然,这种看法过于简单,但请允许我详细说明。相当大一部分最大的进展更多地是“调整”而非质新想法。BigGAN是一个更大的 GAN。逐步增长的 GAN 产生了非常吸引眼球的结果,在某些方面是一个巨大的进步,但在方法上,它只是一个带有巧妙课程学习技巧的 GAN。在 NLP 领域,年度最大新闻是ELMO和BERT的上下文嵌入。这些在经验上绝对是了不起的进展。但自 2015-16 年 Andrew Dai 和 Quoc Le 在更小规模上进行这项工作以来,我们一直在预训练语言模型并微调以进行下游分类任务。所以,也许更悲观的看法是,这一年并没有被新“重大想法”主导。另一方面,积极的看法可能是现有技术的全部能力尚未发挥出来,硬件、系统和工具的快速发展可能会在挤出这些 3-4 年旧想法的所有价值方面发挥第二幕。
我认为,现在有很多新鲜的想法在深度学习的新兴理论中酝酿。包括Sanjeev Arora、Tengyu Ma、Daniel Soudry、Nati Srebro等在内的大量研究人员正在进行一些非常激动人心的工作。长久以来,我们有的是严谨的第一原理理论,但往往忽视了实践,然后是“实验性的”机器学习,这实际上关心的是科学而不是排行榜追逐。现在出现了一种新的探究模式,其中理论和实验更加紧密地结合。你开始看到受到实验启发的理论论文,以及进行实验的理论论文。最近,我有一个启发性的经历,从一篇理论论文中获得了一个点子,真正揭示了一种我没有预料到的自然现象。
对于 2019 年及以后,我认为应用机器学习将面临一场审视。我们正急于进入所有这些实际领域,声称要“解决”问题,但到目前为止,我们工具箱中唯一可靠的工具仍然是监督学习,而仅凭模式匹配我们能做的事有一定限制。监督模型找出关联,但它们并不能提供理由。它们不知道哪些信息是可靠的,哪些信息是不稳定的(即可能随时间变化)。这些模型不能告诉我们干预的效果。当我们在与人类互动的系统中部署基于监督学习的自动化系统时,我们没有预见到它们如何扭曲激励,从而改变其环境,破坏它们所依赖的模式。我认为在接下来的一年里,我们将看到更多的机器学习项目被废弃,或者因为这些限制而陷入麻烦,我们也会看到社区中更具创意的成员将更多关注从功能拟合排行榜转向解决表征学习和因果推理之间的差距的问题。
Matthew Mayo (@mattmayo13) 是 KDnuggets 的编辑。
对我来说,2018 年在机器学习领域似乎是一个精细化的年份。例如,迁移学习得到了更广泛的应用和关注,特别是在自然语言处理领域,这要归功于诸如通用语言模型微调用于文本分类(ULMFiT)和双向编码器表示(BERT)等技术。这些并不是去年自然语言处理领域唯一的进展;另一个值得注意的是来自语言模型的嵌入(ELMo),这是一个深度上下文化的词表示模型,在模型所用的每个任务上都取得了显著的改进。其他的突破似乎集中在现有技术的改进上,例如BigGANs。此外,由于许多倡导社区成员的声音,关于机器学习中的包容性和多样性的非技术性讨论也成为主流(可以参考NeurIPS作为一个例子)。
我相信在 2019 年,研究的关注将从监督学习转向如强化学习和半监督学习等领域,因为这些领域的潜在应用正变得越来越显著。现在我们已经处于图像识别和生成被“解决”(为了避免使用更具负担的术语)的阶段,例如,我们在此过程中学到的知识可以帮助研究人员追求更复杂的机器学习应用。
作为一名业余的自动化机器学习(AutoML)倡导者,我认为我们将继续看到 AutoML 的渐进式进展,以至于普通的监督学习任务将能够通过现有和开发中的方法自信地进行算法选择和超参数优化。我认为,自动化机器学习的广泛认知将从替代实践者转变为增强实践者(或者可能已经达到了这一临界点)。AutoML 将不再被视为替代机器学习工具箱的威胁,而是作为工具箱中的另一个工具。相反,我觉得实践者将定期在日常场景中使用这些工具已是板上钉钉的事情,并且被期望知道如何使用它们。
布兰登·罗赫尔 (@brohrer) 是 Facebook 的数据科学家。
2018 年的一个重要趋势是数据科学教育机会的激增和成熟。在线课程是最早的数据科学教育场所。它们在所有级别上继续受到欢迎,每年有更多的学生、变体和话题。
在学术界,新的数据科学硕士项目正在以每年大约十几个的速度启动。我们的高等教育机构正在响应公司和学生的呼声,提供专门的数据相关领域项目。(今年,18 位行业合著者和我以及 11 位学术贡献者,共同创建了一个虚拟行业顾问委员会来帮助支持这一爆炸性增长。)
在非正式的领域,教程博客帖子随处可见。它们为数据科学的集体理解做出了很大贡献,无论是对读者还是作者。
从 2019 年开始,学术数据科学项目将成为获取进入首个数据科学职位所需的基本技能的更常见方式。这是一件好事。受认证机构监管的机构将填补一个长期存在的空白。到目前为止,数据科学的资格主要是通过以往的工作经验来证明的。这造成了一个悖论:新的数据科学家无法展示他们的资格,因为他们从未有过数据科学职位,而他们无法获得数据科学职位,因为他们不能展示自己的资格。来自教育机构的凭证是打破这一循环的一种方式。
然而,在线课程不会消失。对许多人来说,大学教育的时间和经济承诺使其无法实现。既然数据科学教育已经确立,它将始终拥有实际的轨道。通过坚持不懈地展示项目工作、相关经验和在线培训,新数据科学家将能够展示他们的技能,即使没有学位。在线课程和教程将继续变得更加普遍、复杂和重要于数据科学教育。实际上,一些知名的数据科学和机器学习项目甚至将他们的课程放到线上,并提供非在校学生的注册选项。我预计数据科学大学学位与在线培训课程之间的界限将继续模糊。在我看来,这才是“数据科学民主化”的最真实形式。
埃琳娜·沙罗娃是 ITV 的高级数据科学家。
2018 年在机器学习(ML)和人工智能(AI)领域的主要发展是什么?
在我看来,2018 年将因以下三件事件而被 AI 和 ML 社区铭记。
首先,欧盟全球数据保护条例(GDPR)旨在提高个人数据使用的公平性和透明度。该条例揭示了个人对控制其个人数据的权利,并获取关于数据使用的信息,但也引起了对法律解释的一些困惑。迄今为止的结果是,大多数公司认为自己已经符合规定,仅仅对数据处理做了一些表面上的更改,而忽视了重新设计数据存储和处理基础设施的根本需要。
其次,剑桥分析丑闻在整个数据科学(DS)社区投下了阴影。如果说之前的争论主要集中在确保人工智能(AI)和机器学习(ML)产品的公平性上,那么这个丑闻引发了更深层次的伦理问题。对Facebook 涉事的最新调查意味着它不会很快平息。随着数据科学领域的成熟,这样的发展将发生在许多行业中,超越了政治。有些将更加悲剧,例如Uber 在亚利桑那州的自动驾驶汽车事件,这些事件将引发强烈的公众反应。技术是权力,权力伴随着责任。正如诺姆·乔姆斯基所说:“只有在民间故事、儿童故事和智识期刊中,权力才被明智地使用以摧毁邪恶。现实世界教给我们的教训却非常不同,只有故意和专注的无知才能未能察觉这些教训。”
最后,从积极的角度来看,亚马逊推出自家服务器处理器芯片意味着我们可能会接近一个云计算普及不再成为成本问题的日子。
你对 2019 年有哪些主要趋势的预期?
数据科学家的角色和责任正超越了建立能够准确预测的模型。2019 年,机器学习(ML)、人工智能(AI)和数据科学(DS)从业者的主要趋势将是对遵循既定软件开发实践的责任日益增加,特别是在测试和维护方面。数据科学的最终产品必须与公司技术堆栈的其他部分共存。对专有软件高效运行和维护的要求将适用于我们构建的模型和解决方案。这意味着最佳的软件开发实践将支撑我们需要遵循的机器学习规则。
Rachel Thomas (@math_rachel) 是 fast.ai 的创始人,也是 USF 的助理教授。
2018 年的两个主要人工智能发展是:
1. 转移学习在自然语言处理中的成功应用
2. 对人工智能的反乌托邦滥用(包括仇恨团体和独裁者的监控与操控)的关注不断增加
转移学习是将预训练模型应用于新数据集的实践。转移学习是计算机视觉进展爆炸性增长的关键因素,2018 年,转移学习在自然语言处理领域成功应用,包括来自fast.ai和 Sebastian Ruder 的ULMFiT、艾伦研究所的 ELMo、OpenAI 变换器和谷歌的 Bert。这些进展既令人兴奋又令人担忧,详见这篇纽约时报文章。
像 Facebook 的决定性角色在缅甸种族灭绝中的作用,YouTube 不成比例地推荐阴谋理论(其中许多推广了白人至上主义),以及政府监控和执法机构使用人工智能的情况,终于在 2018 年开始获得更多主流媒体的关注。虽然这些人工智能的误用情况严重且令人恐惧,但更多的人开始意识到这些问题,并越来越多地反对它们,这是一件好事。
我预计这些趋势会在 2019 年继续,随着自然语言处理的快速进展(正如 Sebastian Ruder今年夏天所写,“自然语言处理的 ImageNet 时刻已经到来”),以及在技术如何用于监控、煽动暴力和被危险政治运动操控方面的更多反乌托邦发展。
Daniel Tunkelang (@dtunkelang)是一位独立顾问,专注于搜索、发现和机器学习/人工智能。
2018 年在自然语言处理和理解中,词嵌入的复杂性取得了两个重大进展。
第一个是在三月。来自艾伦人工智能研究所和华盛顿大学的研究人员发布了“深度语境化词表示”,并引入了 ELMo(Embeddings from Language Models),这是一种开源的深度语境化词表示,相较于 word2vec 或 GloVe 等上下文无关的词嵌入有所改进。作者通过简单地用 ELMo 预训练模型中的向量替代,展示了对现有自然语言处理系统的改进。
第二个突破发生在 11 月。谷歌开源了 BERT(双向编码器表示从变换器),这是一个双向、无监督的语言表示,预先在维基百科上进行训练。正如作者在《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》中所展示的那样,他们在各种自然语言处理基准测试中取得了显著改进,甚至相对于 ELMo 也有显著提高。
在智能扬声器快速普及(到 2018 年底约为 1 亿台)和移动手机上数字助手的普及之间,自然语言理解的进展正迅速从实验室转向实际应用。这是自然语言处理研究和实践的激动人心的时代。
但我们仍然有很长的路要走。
今年,艾伦研究所的研究人员发布了“Swag: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference”,这是一个用于句子完成任务的数据集,需要常识理解。他们的实验表明,最先进的自然语言处理技术仍远远落后于人类表现。
但希望我们能在 2019 年看到更多的自然语言处理突破。计算机科学领域的许多顶尖人才正在努力研发,行业也渴望应用他们的成果。
相关内容:
-
2018 年 AI、数据科学、分析的主要发展与 2019 年的关键趋势
-
机器学习与人工智能:2017 年的主要发展与 2018 年的关键趋势
-
数据科学、机器学习:2017 年的主要发展与 2018 年的关键趋势
我们的前三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
 3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
-
[AI、分析、机器学习、数据科学、深度学习等的主要发展](https://www.kdnuggets.com/2021/12/developments-predictions-ai-machine-learning-data-science-research.html)
预测科学与数据科学
原文:
www.kdnuggets.com/2016/11/predictive-science-vs-data-science.html
 评论
评论

我们可以谈论营养科学,它关注我们吃什么。我们可以谈论运动科学,它关注我们如何利用这些卡路里。或者我们可以全面地讨论结果——我认为这涉及到一个更重要的问题,大多数人最终关心的——健康科学。鉴于结果——健康科学——通常比原料——营养学——或将原料转化为更有用的东西的过程——运动科学——更有趣,我们为何往往讨论数据科学而非预测科学?
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
 3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
明确来说,数据科学不仅仅是预测或分类。它还包括其他机器学习技术,如聚类和频繁项集挖掘。它还包括数据可视化和数据讲述。它也可以涵盖传统的数据挖掘框架的各个方面,例如 KDD 过程,包括数据选择、预处理和转换。数据科学还可以包括其他算法和数据相关任务的方法,超出我在这里提到的内容。
我以前已经全面定义了数据科学:
数据科学是一门多方面的学科,包括机器学习和其他分析过程、统计学及相关的数学分支,越来越多地借用高性能科学计算,以最终从数据中提取洞察,并利用这些新发现的信息讲述故事。
在考虑“预测科学”与数据科学时,我将数据科学的细微相关部分作为对照。事实上,将数据科学拆解为组成的“科学”(例如聚类科学)无疑有助于表达我们究竟在做什么,但显然以一个吸引眼球的总括性术语为代价。
但退一步看,数据无疑是输入,是原材料。从这个意义上讲,数据科学强调的是预测过程中的“什么”。虽然数据是预测难题中的主要成分,且可能是最难获取的,“数据科学”似乎忽略了另一个主要组成部分以及有趣的见解。
算法是变革性的过程。那么 算法科学 呢?它关注的是工具,即“如何”,并且深深根植于计算机科学中。然而,这仍然无法准确描述整体预测过程;数据被抛弃,转而关注将其转化为预测的过程。任何成功的描述可能会集中在最终结果上。
整体预测过程的结果是预测。或者是假设呢?我不是以一种普通的“假设与预测”的方式来提问,而是在询问“预测还是假设是特定分类器/模型的更有价值的输出?”
无论是预测还是假设,这两者中的一个将是整体预测科学难题中最有趣的部分。预测科学——或者如果你觉得“预测科学”更合适——听起来还不错。但实际上,这不就是“科学”?这似乎非常不具体。
那么统计学呢?我们是应用统计学家吗?来源于维基百科:
“应用统计”包括描述统计和推断统计的应用。
加入处方统计,这似乎是朝着正确方向迈出的一步。然而,在这种情况下,重点放在统计过程的应用上,而… 实际上并没有牺牲多少。但我会争辩说,这实际上没有对推断统计和处方统计给予适当的重视,或许过于依赖描述统计,因此在描述预测科学时也显得不够充分。
预测分析?也许是最接近的术语,但这个词目前似乎更贴近商业世界而非科学世界。我没有在研究中看到这个术语,通常它似乎完全属于大企业的领域。这对于它本身来说是可以的,但它的性质似乎并未将科学置于前沿(尽管显然科学支撑着它的使用)。
我不知道是否有解决方案。公平地说,我甚至不知道这个问题是否存在于我的脑海之外。但我认为一切归结为以下几点,并且可以在数据科学的预测方面之外进行概括:数据科学这个术语是否真的对我们这些数据科学家,或者对其他人有实际价值?
我不打算给出建议,即使我有,恐怕也会被忽视。这没关系。但作为一个对“数据科学”这个术语并不特别感到兴奋或舒适的人,我认为值得对我们所做的工作以及如何分类这些任务进行自省。确实,将某个名称赋予广泛相关任务的职业是方便的,但我们是否因为这个森林而看不到树木?
当谈到非常复杂的预测科学时,数据可能是新石油,而算法则是特别的调味料,但它们的配对预测能力才是真正的“钱景”,无论是比喻上还是字面上。
相关:
-
数据科学与大数据的解释
-
数据科学的核心
-
数据科学的分裂会导致一个帝国还是多个共和国?
相关话题
Prefect 自动化与协调数据管道的方法
原文:
www.kdnuggets.com/2021/09/prefect-way-automate-orchestrate-data-pipelines.html
评论
由 Murallie Thuwarakesh,Stax, Inc. 的数据科学家提供。

插图来自 Undraw。
我曾经是 Apache Airflow 的大粉丝。即使今天,我对它也没有太多抱怨。但新技术 Prefect 让我惊叹不已,我忍不住将所有内容迁移到它上面。
Prefect(以及 Airflow)是一个工作流自动化工具。你可以协调各个任务以完成更复杂的工作。你可以管理任务依赖关系、在任务失败时重试任务、调度任务等。
我相信工作流管理是每个数据科学项目的支柱。即使是小项目,也可以通过像 Prefect 这样的工具获得显著的好处。它消除了大量重复任务的部分。不用说,它还消除了复杂项目中的心理负担。
本文涵盖了关于 Prefect 的一些常见问题,包括:
-
Prefect 核心概念的简短介绍;
-
为什么我决定从 Airflow 迁移。
-
Prefect 的令人惊叹的功能和与其他技术的集成,以及;
-
如何在其云部署与本地部署选项之间做出决定。
快速启动 Prefect。
Prefect 是一个既简约又完整的工作流管理工具。它的设置极其简单。然而,它能够完成 Airflow 等工具能够做的所有任务,甚至更多。
你可以使用 PyPI、Conda 或 Pipenv 安装它,它就绪待用。更多关于此的内容在 Airflow 部分中有比较。
pip install prefect
# conda install -c conda-forge prefect
# pipenv install --pre prefect
在我们深入使用 Prefect 之前,先来看一个未管理的工作流。这有助于理解 Prefect 在工作流管理中的角色。
以下脚本查询一个 API(提取 — E),从中选择相关字段(转换 — T),并将其追加到文件中(加载 — L)。它包含执行每个任务的三个函数。这是一个直接但日常使用的工作流管理工具用例 —— ETL。
代码由 作者 提供。
该脚本从 OpenWeatherMap API 下载天气数据,并将风速值存储在一个文件中。现实生活中的 ETL 应用可能很复杂。但这个示例应用很好地涵盖了基本方面。
注意:请将 API 密钥替换为真实的密钥。你可以从 openweathermap.org/api 获取一个。
你可以使用命令 python app.py 运行此脚本,其中 app.py 是你脚本文件的名称。这将创建一个名为 windspeed.txt 的新文件,包含一个值。这是你访问 API 时波士顿的风速。如果你重新运行脚本,它将向同一文件追加另一个值。
你的第一个 Prefect ETL 工作流。
上面的脚本运行良好。然而,它缺少完整 ETL 的一些关键特性,比如重试和调度。此外,如前所述,实际的 ETL 可能在一个工作流中有数百个任务。其中一些可以并行运行,而有些则依赖于一个或多个其他任务。
想象一下,如果有一个临时网络问题阻止你调用 API,脚本会立即失败而不会再做进一步尝试。在实时应用程序中,这种停机时间并不奇怪。它们发生的原因有很多——服务器停机、网络停机、服务器查询限制超出。
此外,你必须每次手动执行上述脚本以更新你的 windspeed.txt 文件。然而,将工作流调度在预定时间内运行在 ETL 工作流中是很常见的。
这时像 Prefect 和 Airflow 这样的工具就派上用场了。下面是你如何调整上面的代码使其成为 Prefect 工作流的方法。
代码来自 作者。
@task 装饰器将一个普通的 Python 函数转换为 Prefect 任务。可选参数允许你指定其重试行为。在上面的例子中,我们配置了该函数在失败之前尝试三次。我们还配置了每次重试之间延迟三分钟。
使用这种新设置,我们的 ETL 对我们之前讨论的网络问题具有弹性。
要测试其功能,请将计算机从网络断开连接,并用python app.py运行脚本。你会看到一条消息,说明第一次尝试失败,下一次将会在接下来的 3 分钟内开始。在三分钟内,将计算机重新连接到互联网。已经运行的脚本现在将无错误地完成。
使用 Prefect 调度工作流。
重试只是 ETL 故事的一部分。许多工作流应用程序的另一个挑战是按计划间隔运行它们。Prefect 的调度 API 对任何 Python 程序员来说都是直接了当的。它是如何工作的,下面是说明。
代码来自 作者。
我们创建了一个 IntervalSchedule 对象,它在脚本执行后五秒启动。我们还将其配置为以一分钟为间隔运行。
如果你用python app.py运行脚本并监控 windspeed.txt 文件,你会看到每分钟都会有新值出现。
除了这种简单的调度外,Prefect 的调度 API 提供了更多的控制。你可以用类似 cron 的方法调度工作流,使用带有时区的时钟时间,或者做一些更有趣的事情,比如仅在周末执行工作流。我在这里没有涵盖所有内容,但 Prefect 的官方 文档 非常完美。
Prefect UI。
像 Airflow(和许多其他工具)一样,Prefect 也附带一个具有美观 UI 的服务器。它允许你控制和可视化你的工作流执行。

插图来自 作者。
要运行这个,你需要在计算机上安装 docker 和 docker-compose。不过,启动它只需一个命令,令人惊讶。
**$** prefect server start

插图由 作者 提供。
这个命令将启动 prefect 服务器,你可以通过你的网页浏览器访问它:[localhost:8080/](http://localhost:8080/)。
然而,Prefect 服务器本身无法执行你的工作流。它的作用只是为所有 Prefect 活动提供一个控制面板。由于这个仪表板与应用程序的其余部分解耦,你可以使用 Prefect cloud 完成相同的任务。我们将在稍后详细讨论这个问题。
执行任务时,我们还需要一些其他东西。好消息是,它们也不复杂。
因为服务器仅作为控制面板,我们需要一个代理来执行工作流。以下命令将启动一个本地代理。如果你的项目需要,你也可以选择 docker 代理或 Kubernetes 代理。
**$** prefect agent local start

插图由 作者 提供。
一旦服务器和代理运行,你将需要创建一个项目并将工作流注册到该项目中。为此,请将执行工作流的行更改为以下内容。
代码由 作者 提供。
现在在终端中,你可以使用 prefect create project <project name> 命令创建一个项目。然后重新运行脚本将其注册到项目中,而不是立即运行。
**$** prefect create project 'Tutorial'
**$** python app.py

插图由 作者 提供。
在网页界面中,你可以看到新项目‘Tutorial’出现在下拉菜单中,我们的风速跟踪器在工作流列表中。该工作流已经计划并正在运行。如果你愿意,也可以手动运行它们。

插图由 作者 提供。
带参数的工作流运行。
我们在前一个练习中创建的工作流是固定的。它只查询波士顿,马萨诸塞州,我们无法更改它。这时我们可以使用参数。下面是如何调整我们的代码以在运行时接受参数。
代码由 作者 提供。
我们已经将函数更改为接受城市参数,并在 API 查询中动态设置它。在 Flow 内部,我们创建一个默认值为‘Boston’的参数对象,并将其传递给 Extract 任务。
如果你在 UI 中手动运行风速跟踪器工作流,你会看到一个名为 input 的部分。在这里,你可以为每次执行设置城市的值。

插图由 作者 提供。
这是运行工作流的一种方便方法。在许多情况下,ETL 和其他工作流都附带运行时参数。
我为什么决定从 Airflow 迁移到 Prefect?
Airflow 是一个出色的工作流管理平台。在许多项目中,它为我节省了大量时间。然而,我们需要欣赏那些取代旧技术的新技术。这就是 Airflow 和 Prefect 的情况。
Airflow 很多地方做得很好,但其核心假设从未预见到数据应用的丰富多样性。
— Prefect 文档。
我在这里描述的内容并不是说如果你偏好 Airflow 就没有解决方案。我们有大多数问题的解决办法。然而,在 Prefect 中,这些问题的解决方案是工具原生支持的。
相比于 Airflow,Prefect 的 安装 非常简单。对于训练有素的眼睛,这可能不是问题。然而,对于任何想要开始工作流编排和自动化的人来说,这是一种麻烦。
Airflow 需要在后台运行一个 服务器 来执行任何任务。然而,在 Prefect 中,服务器是可选的。这是使用 Prefect 的一个巨大优势。我有许多在计算机上作为服务运行的小项目。以前,我必须在启动时启动 Airflow 服务器。因为 Prefect 可以独立运行,所以我不再需要启动这个额外的服务器。
Airflow 不具备使用 参数 运行工作流(或 DAG)的灵活性。我使用的解决方法是让应用程序从数据库中读取这些参数。这对于如此简单的任务来说不是一个很好的编程技术。在这方面,Prefect 的参数概念非常出色。
Prefect 允许拥有相同工作流的不同 版本。每次你将工作流注册到项目中时,它会创建一个新版本。如果你需要运行以前的版本,你可以轻松地在下拉菜单中选择它。这在 Airflow 中是不可能的。
Prefect 还允许我们创建团队和基于角色的访问控制。每个团队可以管理自己的配置。授权 是每个现代应用程序的重要部分,Prefect 以最佳方式处理它。
最后,我发现 Prefect 的 UI 更加直观和吸引人。Airflow 的 UI,尤其是其任务执行可视化,刚开始时很难理解。
Prefect 的生态系统及其与其他技术的集成。
Prefect 内置了与许多其他技术的集成。它消除了大量的开销,使得与这些技术的工作变得非常简单。
现实项目经常需要处理多种技术。例如,当你的 ETL 失败时,你可能想要向维护者发送电子邮件或 Slack 通知。
在 Prefect 中,发送这样的通知是非常简单的。你可以使用 Prefect 的任务库中的 EmailTask,设置凭据,然后开始发送电子邮件。
你可以在他们的 官方文档 中了解更多关于 Prefect 丰富生态系统的内容。在本文中,我们将看到如何发送电子邮件通知。
要发送电子邮件,我们需要使凭证对 Prefect 代理可访问。你可以通过在$HOME/.prefect/config.toml中创建以下文件来实现。
代码来自作者。
你的应用程序现在已准备好发送电子邮件。以下是我们成功捕获风速测量时如何发送通知。
代码来自作者。
在上述代码中,我们创建了 EmailTask 类的一个实例。在初始化期间,我们使用了电子邮件配置的所有静态元素。然后在 Flow 中,我们使用了带有变量内容的实例。
上述配置将发送包含捕获的风速测量的电子邮件。但其主题将始终保持为‘捕获的新风速’。
Prefect Cloud 与本地服务器部署。
我们已经了解了如何启动本地服务器。因为这个服务器只是一个控制面板,你可以轻松地使用云版本代替。要做到这一点,我们需要遵循一些额外的步骤。
-
创建一个Prefect cloud账户。
-
从API 密钥页面生成一个密钥。
-
在你的终端中,将后端设置为云:
prefect backend cloud。 -
还需要使用生成的密钥登录:
prefect auth login --key YOUR_API_KEY。 -
现在,像往常一样启动代理:
prefect agent local start。
在云仪表板中,你可以管理之前在本地服务器上完成的所有操作。
在选择云版本和服务器版本时,一个重要问题是安全性。根据 Prefect 的文档,服务器仅存储与工作流执行相关的数据和用户提供的自愿信息。由于代理在你的本地计算机上执行逻辑,你可以控制数据存储的位置。
云选项在性能方面也很合适。使用一个云服务器,你可以管理多个代理。因此,你可以轻松地扩展你的应用程序。
最后的想法
Airflow 曾是我构建 ETL 和其他工作流管理应用程序的最终选择。然而,Prefect 让我改变了主意,现在我正在将所有内容从 Airflow 迁移到 Prefect。
Prefect 是一个简单的工具,具有超越 Airflow 的灵活扩展性。你甚至可以在 Jupyter notebook 中运行它。同时,你可以将其作为完整的任务管理解决方案进行托管。
除了工作流管理的核心问题外,Prefect 还解决了你可能在实时系统中经常遇到的其他问题。管理带有授权控制的团队、发送通知等就是其中的一些。
在这篇文章中,我们讨论了如何创建一个 ETL,它
-
根据配置重试一些任务;
-
按计划运行工作流;
-
接受运行时参数,并且;
-
当操作完成时,发送电子邮件通知。
我们只是触及了 Prefect 能力的表面。我建议阅读官方文档以获取更多信息。
还不是 Medium 会员?请使用此链接 成为会员。你可以享受数千篇有见地的文章,并支持我,因为我通过推荐你获得少量佣金。
个人简介:Murallie Thuwarakesh (@Thuwarakesh) 是 Stax, Inc. 的数据科学家,并且是 Medium 上的顶级分析写作者。Murallie 分享了他在数据科学中的每日探索。
原文。经授权转载。
相关内容:
-
Prefect:如何使用 Python 编写和安排你的第一个 ETL 管道
-
使用 Gretel 和 Apache Airflow 构建合成数据管道
-
本地开发和测试 AWS 的 ETL 管道
我们的三大课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业道路
1. Google 网络安全证书 - 快速进入网络安全职业道路
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
 3. Google IT 支持专业证书 - 支持你的组织 IT
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关内容
Prefect: 如何用 Python 编写和调度您的第一个 ETL 管道
原文:
www.kdnuggets.com/2021/08/prefect-write-schedule-etl-pipeline-python.html
评论
由 Dario Radečić,NEOS 的顾问

照片由 Helena Lopes 提供,来自 Pexels
我们的三大课程推荐
 1. Google Cybersecurity Certificate - 快速进入网络安全职业轨道
1. Google Cybersecurity Certificate - 快速进入网络安全职业轨道
 2. Google Data Analytics Professional Certificate - 提升您的数据分析技能
2. Google Data Analytics Professional Certificate - 提升您的数据分析技能
 3. Google IT Support Professional Certificate - 支持您在 IT 领域的组织
3. Google IT Support Professional Certificate - 支持您在 IT 领域的组织
Prefect 是一个基于 Python 的工作流管理系统,基于一个简单的前提*— 您的代码可能正常工作,但有时它并不*(source)。当一切按预期工作时,没有人会考虑工作流系统。但当事情出问题时,Prefect 将确保您的代码成功失败。
作为一个工作流管理系统,Prefect 使得在数据管道中添加日志记录、重试、动态映射、缓存、失败通知等变得非常容易。当您不需要它时,它是隐形的——当一切按预期运行时;而当您需要它时,它是可见的。就像保险一样。
虽然 Prefect 不是唯一的 Python 用户工作流管理系统,但它无疑是最高效的一个。像 Apache Airflow 这样的替代品通常表现良好,但在处理大型项目时会带来很多麻烦。您可以在这里阅读 Prefect 与 Airflow 的详细比较。
本文涵盖了库的基础知识,例如任务、流程、参数、失败和计划,并解释了如何在本地和云端设置环境。我们将使用 Saturn Cloud 来完成这部分,因为它使配置变得毫不费力。这是由数据科学家制作的云平台,因此大部分繁重的工作都为您完成了。
Saturn Cloud 可以轻松处理 Prefect 工作流。它也是从仪表板到分布式机器学习、深度学习和 GPU 训练的前沿解决方案。
今天您将学习如何:
-
本地安装 Prefect
-
使用 Python 编写一个简单的 ETL 管道
-
使用 Prefect 声明任务、流程、参数、调度并处理失败
-
在 Saturn Cloud 中运行 Prefect
如何在本地安装 Prefect
我们将在虚拟环境中安装 Prefect 库。以下命令将通过 Anaconda 创建并激活一个名为prefect_env的环境,基于 Python 3.8:
conda create — name prefect_env python=3.8
conda activate prefect_env
你需要输入y几次来指示 Anaconda 继续,但这在每次安装时都是这样的。在库方面,我们需要Pandas用于数据处理,Requests用于下载数据,当然,还需要Prefect用于工作流管理:
conda install requests pandas
conda install -c conda-forge prefect
我们现在拥有了开始编写 Python 代码所需的一切。接下来我们开始动手吧。
用 Python 编写 ETL 管道
今天我们将使用 Prefect 完成一个相对简单的任务——运行一个 ETL 管道。这个管道将从一个虚拟 API 下载数据,转换数据,并将其保存为 CSV 文件。JSON Placeholder 网站将作为我们的虚拟 API。除此之外,它还包含十个用户的虚假数据:

图 1 — 虚假用户数据(来源:https://jsonplaceholder.typicode.com/users))(图片由作者提供)
首先创建一个 Python 文件——我将其命名为01_etl_pipeline.py。另外,请确保有一个文件夹来保存提取和转换的数据。我称之为data,它位于 Python 脚本所在的位置。
任何 ETL 管道都需要实现三个功能——用于提取、转换和加载数据。在我们的案例中,这些功能将完成以下任务:
-
extract(url: str) -> dict— 对url参数发出一个 GET 请求。测试是否返回了一些数据——如果是的话,它将作为字典返回。否则,会抛出一个异常。 -
transform(data: dict) -> pd.DataFrame— 转换数据,仅保留特定的属性:ID、姓名、用户名、电子邮件、地址、电话号码和公司。将转换后的数据作为 Pandas DataFrame 返回。 -
load(data: pd.DataFrame, path: str) -> None— 将之前转换过的data保存到path处的 CSV 文件中。我们还会在文件名中添加时间戳,以免文件被覆盖。
在函数声明之后,所有三个函数在执行 Python 脚本时都会被调用。这是完整的代码片段:
现在你可以通过在终端中执行以下命令来运行脚本:
python 01_etl_pipeline.py
如果一切正常,你不应该看到任何输出。然而,你应该在data文件夹中看到 CSV 文件(我运行了文件两次):

图 2 — 运行 ETL 管道两次后 data 文件夹中的 CSV 文件列表(图片由作者提供)
正如你所看到的,ETL 管道运行并完成没有任何错误。但如果你想按照计划运行管道呢?这时Prefect派上用场了。
探索 Prefect 的基础知识
在本节中,你将学习 Prefect 任务、流程、参数、调度等的基础知识。
Prefect 任务
让我们从最简单的开始 — 任务。它基本上是你工作流中的一个单独步骤。为了跟上进度,创建一个名为 02_task_conversion.py 的新 Python 文件。从 01_etl_pipeline.py 复制所有内容,然后你就可以开始了。
要将 Python 函数转换为 Prefect 任务,你首先需要进行必要的导入 — from prefect import task,然后装饰任何感兴趣的函数。以下是一个示例:
@task
def my_function():
pass
这就是你需要做的全部!这是我们 ETL 流程的更新版本:
让我们运行它,看看会发生什么:
python 02_task_conversion.py

图 3 — 使用 Prefect 将函数转换为任务(图片由作者提供)
看起来似乎出了问题。这是因为 Prefect Task 不能在没有 Prefect Flow 的情况下运行。接下来我们来实现它。
Prefect 流程
将 02_task_conversion.py 中的所有内容复制到一个新文件 — 03_flow.py。在声明之前,你需要从 prefect 库中导入 Flow。
要声明一个流程,我们将编写另一个 Python 函数 — prefect_flow()。它不会接受任何参数,也不会被装饰。函数内部,我们将使用 Python 的上下文管理器来创建一个流程。该流程应包含与之前在 if __name__ == '__main__' 代码块中相同的三行代码。
在提到的代码块中,我们现在需要用相应的 run() 函数来运行流程。
这是该文件的完整代码:
让我们运行它,看看会发生什么:
python 03_flow.py

图 4 — 第一次运行 Prefect 流程(图片由作者提供)
这真是太棒了!不仅 ETL 流程被执行了,我们还获得了关于每个任务开始和结束时间的详细信息。我已经运行了文件两次,因此应该会有两个新的 CSV 文件保存到 data 文件夹中。让我们验证一下是否如此:

图 5 — Prefect 流程生成的 CSV 文件(图片由作者提供)
这就是如何使用 Prefect 运行一个简单的 ETL 流程。它目前还没有比纯 Python 实现带来很多好处,但我们很快会改变这一点。
Prefect 参数
硬编码参数值从来不是一个好主意。这就是 Prefect Parameters 发挥作用的地方。首先,将 03_flow.py 中的所有内容复制到一个新文件 — 04_parameters.py。你需要从 prefect 包中导入 Parameter 类。
你可以在流程上下文管理器中使用这个类。以下是你可能会觉得有用的参数:
-
name— 参数的名称,将在运行流程时使用。 -
required— 一个布尔值,指定该参数是否是执行流程所必需的。 -
default— 指定参数的默认值。
我们将声明一个用于 API URL 的参数 — param_url = Parameter(name='p_url', required=True)。
要给参数赋值,你需要将 parameters 字典指定为 run() 函数的一个参数。参数名称和值应以键值对的形式编写。
这是该文件的完整代码:
让我们运行文件,看看会发生什么:
python 04_parameters.py

图 6 — 运行包含参数的 Prefect 流(图像作者提供)
我已经运行了两次文件,因此data文件夹中应出现两个新的 CSV 文件。让我们确认一下:

图 7 — Prefect 流生成的 CSV 文件(图像作者提供)
就这样——在一个地方指定参数值。这使得将来进行更改变得容易,也方便管理更复杂的工作流。
接下来,我们将探讨 Prefect 的一个特别有用的功能——调度。
Prefect 调度
今天我们将探讨两种调度任务的方法——间隔调度和Cron 调度。第二种可能听起来很熟悉,因为 Cron 是在 Unix 上调度任务的著名方法。
我们将从 间隔调度器 开始。首先,将04_intervals.py中的所有内容复制到05_interval_scheduler.py。你需要从prefect.schedules中导入IntervalScheduler。
然后,我们将在 prefect_flow() 函数声明之前创建导入类的实例,并指示其每十秒运行一次。这可以通过设置 interval 参数的值来实现。
要将调度器连接到工作流,你需要在使用上下文管理器初始化Flow类时为schedule参数指定值。
整个脚本文件应如下所示:
让我们运行文件,看看会发生什么:
python 05_interval_scheduler.py

图 8 — 使用间隔调度(图像作者提供)
如你所见,整个 ETL 管道运行了两次。Prefect 将向终端报告下一次执行的时间。
现在,让我们探讨 Cron 调度器。将05_interval_scheduler.py中的所有内容复制到06_cron_scheduler.py。这一次,你将导入CronSchedule而不是IntervalSchedule。
在类初始化时,你需要为cron参数指定一个 cron 模式。五个星号符号将确保工作流每分钟运行一次。这是 Cron 的最低可能间隔。
其余部分保持不变。以下是代码:
让我们运行文件:
python 06_cron_scheduler.py

图 9 — 使用 Cron 调度(图像作者提供)
如你所见,ETL 管道每分钟运行两次,正如 Cron 模式所指定的。接下来的部分,我们将探讨如何处理失败——并解释为什么你应该总是做好准备。
完美失败
迟早,你的工作流中会发生意外错误。Prefect 提供了一种极其简单的方法来重试任务的执行。首先,将04_parameters.py中的所有内容复制到一个新文件中 — 07_failures.py。
extract()函数可能因为各种网络原因而失败。例如,API 可能暂时不可用,但几秒钟后会恢复。这些情况在生产环境中时有发生,不应该完全崩溃你的应用程序。
为了避免不必要的崩溃,我们可以稍微扩展一下task装饰器。它可以接受不同的参数,今天我们将使用max_retries和retry_delay。这两个参数不言自明,所以我不会进一步解释。
唯一的问题是 — 我们的工作流现在不会失败。但如果我们在flow.run()内部放置一个不存在的 URL 作为参数值,它会失败。以下是代码:
让我们运行文件:
python 07_failures.py

图 10 — 使用 Prefect 防止失败(作者提供的图像)
任务失败了,但工作流并没有崩溃。当然,在经过十次重试后,它会崩溃,不过你始终可以更改参数规格。
这就是在本地使用 Prefect 的所有内容。接下来,让我们将代码移到云端,并探讨一下变化。
在 Saturn Cloud 中运行 Prefect
让我们立即开始动手吧。首先,注册一个免费的Prefect Cloud账户。注册过程简单明了,不需要进一步解释。注册完成后,创建一个项目。我将其命名为SaturnCloudDemo。
在转到Saturn Cloud之前,你需要在 Prefect 中创建一个 API 密钥来连接这两个服务。你可以在设置中找到API Key选项。如你所见,我将其命名为SaturnDemoKey:

图 11 — 创建 Prefect Cloud API 密钥(作者提供的图像)
现在你已经具备了所需的一切,前往Saturn Cloud创建一个免费账户。一旦进入仪表板,你会看到多个项目创建选项。选择Prefect选项,如下所示:

图 12 — 在 Saturn Cloud 中创建 Prefect 项目(作者提供的图像)
Saturn Cloud 现在会自动为你完成所有繁重的工作,几分钟后,你可以通过点击按钮打开 JupyterLab 实例:

图 13 — 在 Saturn Cloud 中打开 JupyterLab(作者提供的图像)
你将可以访问两个笔记本 — 第二个笔记本展示了在 Saturn Cloud 中使用 Prefect 的快速演示。如下所示:

图 14 — Saturn Cloud 中的 Prefect Cloud 笔记本(作者提供的图像)
你只需要更改两个设置来使笔记本正常工作。首先,将项目名称更改为 Prefect Cloud 中你的项目名称。其次,将 <your_api_key_here> 替换为几分钟前生成的 API 密钥。如果你做对了,你应该会看到以下消息:

图 15 — Saturn Cloud 中的登录成功消息(图片由作者提供)
为了进行测试,请运行接下来的每个单元格。然后转到 Prefect Cloud 仪表板并打开你的项目。它不会像几分钟前那样空着:

图 16 — 成功的 Prefect 任务调度(图片由作者提供)
这就是你需要做的全部!随意复制/粘贴我们的 ETL 管道并验证其是否有效。这就是 Saturn Cloud 的亮点——你可以从本地机器上复制/粘贴代码,几乎无需更改,因为所有繁琐的配置都自动完成。
让我们在下一部分总结一下。
最后的思考
那么,这就是 Prefect 的基础知识介绍,包括本地和云端的内容。我希望即使在阅读这篇文章之前你对这个话题一无所知,也能看到工作流管理系统在生产应用中的价值。
要获取更高级的指南,即配置日志记录和 Slack 通知,请参考 官方文档。提供的示例足以帮助你入门。
保持联系
简介: Dario Radečić 是 NEOS 的顾问。
原文。经许可转载。
相关内容:
-
AWS 本地 ETL 管道的开发与测试
-
什么是 ETL?
-
dbt 数据转换 – 实用教程
更多相关主题
准备数据科学面试中的行为问题
原文:
www.kdnuggets.com/2021/07/prepare-behavioral-questions-data-science-interviews.html
评论
作者 Zijing Zhu,经济学博士,数据科学认证专家

照片由Clem Onojeghuo拍摄,来源于Unsplash
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
 3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
在我之前关于数据科学面试准备的文章中,我列出了用于练习的技术问题,包括machine learning、statistics和probability theory。我还讨论了在数据科学面试前后准备案例分析问题的策略。这篇文章是数据科学面试准备系列的第五篇,主要关注行为问题。我将首先讨论如何准备行为环节,然后列出一些常见问题,供你练习这些技巧。
我在面试过程中最喜欢行为面试,因为与其他技术面试相比,它相对轻松。在我了解回答行为面试问题的策略之前,我总感觉在这个环节中我是在和人聊我经历过的有趣事情。尽管在面试过程中保持较少的压力心态是件好事,但过于放松可能会让你无法给面试官留下深刻的印象。我最终讲述了过多的细节,错过了证明自己符合面试官要求的机会。请记住,即使你主要是在与面试官聊天,你仍然会通过这轮对话被评估。你应该把这轮面试视为展示你基于经验和个性为何是最佳候选人的机会。没有扎实的例子和明确的结构,你无法有效地展示自己,这将在本文中讨论。
第一部分:收集有力的例子
行为面试问题的回答内容是基础。在面试过程中,为了保持对话流畅,你很少有时间思考完美的例子来回答问题。因此,在准备面试时,我们应从收集所有“有用”的经历开始,并按问题类型进行分类。这样,你就会知道你总会有话题可谈,并且有合适的例子来支持你的论点。在这一部分,我将讨论收集有力例子的过程。
制作你的清单
你应该使用哪些例子来回答行为面试问题?考虑一下你过去的工作和学习经历,并将其分类到不同的类别中。
当我准备行为面试问题时,我使用了以下表格来头脑风暴我所经历的经验。尽管问题可以用无数种方式提出,我们可以将它们概括为以下八类。你遇到过哪些挑战?你如何优先安排工作?你有哪些成就想要分享?有哪些例子能展示你的领导能力?你什么时候遇到过冲突,如何处理的?你犯过哪些错误?你如何适应新环境,融入其中?

类别清单
对于每个类别,搜索你的记忆并准备至少一个例子分享。如果每个类别有多个例子,那就更好!将它们全部写下来,并从不同方面加以强调。例如,在展示你的成就的同一类别中,你可能会找到一个例子强调你的自学能力,另一个则显示你是一个团队合作者。这些都是面试官可能会寻找的优秀特质。收集所有这些例子,并学习如何根据面试中的问题背景优先选择分享的例子。
优先考虑例子
如果你有多个挑战已经克服,那么在回答特定问题时,你应该选择哪个挑战?我建议你遵循以下原则来优先考虑例子:
-
优先考虑影响力较大的例子:影响力是关键。它展示了你工作的成果,并证明你符合申请的要求。当你说你为项目构建了一个新模型时,人们可能会质疑,直到你提到这个模型增加了 x%的客户留存率。
-
优先考虑相关的例子:相关性有几个方面。首先,根据问题的背景和提问方式,答案可能会有所不同。因此,在面试过程中,积极倾听非常重要。尽管你可能已经准备好了很好的演讲,但如果与问题无关,你应该根据问题调整你的回答。此外,如果你申请的是工作岗位,那么工作相关的例子比学校项目更为相关。
-
优先考虑近期的例子:讨论最近发生的例子比讨论很久以前发生的事情更好。例如,你可以讨论你在最近职位上的经历。如果你有工作经验,当被问及领导力技能时,你仍然使用学校的例子,面试官可能会对你在职场中实践技能的能力产生疑虑。这会发出不好的信号。
研究公司的核心价值观和职位描述
面试官希望从你讲述的经历中发现一些关键特征。一般来说,这些特征包括:
-
良好的沟通者
-
自信与谦逊
-
主动进取者
-
遵守规则和协议的能力
-
独立自主
-
与他人合作良好
-
问题解决者
-
对角色和公司的承诺
-
领导力特质
-
公司的积极代表
你使用的例子应向面试官展示你具备他们所寻找的关键特征。此外,每家公司都有其核心价值观,可能会优先考虑某些品质。你应该在线上轻松找到这些核心价值观或从职位描述中总结出来。在准备例子时,记住所有核心价值观,并在回答中尽量融入并优先考虑它们。
充分利用每个例子
在回答有关解决冲突的问题时,除了展示你解决问题的技能外,你还可以展示你出色的沟通能力和领导力。 因此,我建议你也为你所有的代表性例子制作下表:

首先总结这个例子的量化影响。然后尝试挖掘这个例子并勾选这个例子有助于展示的类别。你可以写一个关于你在这个例子中完成的任务的单句总结,展示你在这一类别中的质量。
如果你有工作经验,你可以很容易找到许多例子,无论是全职、兼职还是实习。对于新毕业生,学术经验也可以作为工作经验来处理。你可以谈谈你参与的一个个人研究项目;你如何与顾问合作,他们类似于职场中的主管;你如何与其他研究生合作,他们类似于职场中的同事。如果你曾经担任过助教,即使这份工作本身可能与你现在申请的职位无关,你仍然可以谈谈一些展现你沟通和领导技能的经历。
诚实
不要编造任何例子! 不要假装成你不是的人。 找到工作不是故事的终点,而是开始的篇章。你不希望给未来的同事或老板留下错误的印象,让他们觉得你以后每天都要假装成别人的样子。与其编造例子,不如回顾你已有的经验,并深入挖掘细节。当我寻找我的第一份全职工作时,我在向一些面试官证明我在职场上的能力时遇到了一些困难。我特别强调了我在初创公司实习的经历,尤其是我与来自不同团队的主管和同事合作的部分。这段经历给了我很多可以用来证明我的沟通和领导技能的例子,并向面试官展示我能够在快节奏的工作环境中表现出色。这也是为什么我们需要深入挖掘并充分利用所有例子的原因。
第二部分:建立和实践结构
你的回答应该始终有条理。否则,你会发现自己很容易在没有重点的情况下滔滔不绝或喋喋不休。你不是在跟朋友聊天,所以你不需要深入每一个细节。你也不是在写悬疑小说,所以不需要让读者绞尽脑汁并尝试给他们惊喜。在面试中,你的回答应该直接、简洁明了。
遵循 STAR 结构
STAR 代表 Situation(情境)、Task(任务)、Action(行动)、Result(结果)。这是一个可靠的方法来构建你的回答。

作者绘制
你从简要描述你所处的情况或需要完成的任务开始你的回答。然后谈谈你需要完成的任务。接着列出你为完成这些任务所采取的行动。最后,总结一下你的行动结果是什么。例如,发生了什么?事件如何结束?你达成了什么?你学到了什么?注意:
-
你可以用结果来描述情况。例如,你可以从“我想分享一下我建立了一个模型,减少了 x%的客户流失”开始你的回答。
-
你选择的任务需要是具体的,而非一般的或假设性的。
-
即使是一个团队项目,也要专注于描述你的任务和行动。如果你需要提到其他人的任务,强调沟通和协作技能。
-
如果你能量化结果,它总是会显得更令人印象深刻。
有关更多细节和示例,请参阅这篇文章和许多其他在线文章,以帮助你练习这种结构。
关注影响而非过程
我无法强调足够展示你工作的影响有多么重要。你怎么做固然重要,但不是优先考虑的,因为你不是在一个知识分享会议上。你应该专注于你做了什么,特别是结果是什么。量化对公司关键 KPI 的影响会更令人印象深刻。
将细节留到后续问题中
起初不要深入细节,尤其是技术细节。保持你的回答清晰且直截了当。首先简要介绍示例,并专注于影响和结果。如果面试官对你如何取得结果感到好奇,他们会问跟进问题,然后你可以详细说明。如前所述,诚实地讲述你知道什么和不知道什么。如果你假装自己做过某事或详细了解某事,面试官可能会问跟进问题并发现你在撒谎。这是一个很糟糕的信号。
第三部分:练习常见问题
现在你有了一些示例,并且知道了正确的结构,练习以下问题:
-
讲述一下你曾被要求做过从未做过的事情的经历?你学到了什么?
-
讲述一下你曾同时负责多个项目的经历。你是如何组织时间的?结果如何?
-
讲述一下在工作中有重要的事情未按计划进行的经历。你的角色是什么?结果如何?你从这次经历中学到了什么?
-
讲述一下你曾经需要和一个难以相处的人一起工作的经历。你是如何处理与那个人的互动的?
-
讲述一下在问题出现时你的主管不在的经历。你是如何处理这种情况的?你咨询了谁?
最后的备注
你可以在线找到很多其他问题来练习。当我说练习时,我并不是让你写下答案然后阅读,希望在面试中遇到完全一样的问题。相反,要练习用一种固定的结构来回答问题。此外,要在镜子前面或与伙伴一起练习,以便获得反馈。请记住,在面试过程中,你并不是在演讲,而是在与他人交谈。因此,积极倾听,并注意他人的反应是非常重要的。我知道在虚拟面试中可能会更具挑战性,我有一篇文章这里帮助你更好地为虚拟面试做准备。目标是进行一次良好的对话,因此你应该专注于回答问题,而不是提供“完美答案”。
这篇文章就到这里。感谢阅读。这里是我所有博客文章的列表。如果你感兴趣,可以查看一下!
我的快乐之地
个人简介:Zijing Zhu 拥有经济学博士学位,获得数据科学认证,并对生活充满热情。
原文。经授权转载。
相关内容:
-
数据科学面试中你应该知道的 10 个统计概念
-
麦肯锡教给我的 5 个课程,让你成为更优秀的数据科学家
-
数据科学家编码面试终极指南
更多相关内容
为有效的 Tableau 和 Power BI 仪表板准备数据
原文:
www.kdnuggets.com/2022/06/prepare-data-effective-tableau-power-bi-dashboards.html
商业智能(BI)技术如 Power BI 和 Tableau 用于收集、集成、分析和展示商业信息。这些工具可以帮助你分析商业数据并可视化信息,以获得有价值的见解。
创建一个提供见解的仪表板可以是一个快速的过程(特别是当你对所选择的 BI 工具有一定的专业知识后)。你可能已经是专家,但仍会发现当你尝试做以下一项(或多项)时,事情会变得非常棘手和耗时:
-
连接多个数据源
-
玩转数据类型和数据分类
-
创建将数据源混合在一起的数据模型
-
创建一个涉及多个聚合层级的可视化
-
自动化你的仪表板刷新
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
 3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
BI 工具可以在展示数据、创建用户视图,甚至有时执行行级安全方面表现出色。现在,PowerBI 和 Tableau 都提供了针对上述复杂用例的功能。这些功能可以帮助构建一次性的快速分析,但在构建有效、可扩展和稳定的可视化时,面对广泛且要求高的受众就显得不足够。大多数情况下,在完成一个临时分析后,数据分析师需要将其转化为稳定的报告,这就面临着以智能方式自动化工作的挑战。
诀窍?
将数据准备工作与分析工作解耦,并坚持使用 BI 工具进行可视化和格式化。 通过将过程简化为输入和输出,你将为自己未来的心理健康和客户满意度进行投资。解耦意味着每一步都在最合适的工具中完成,然后自动化,最终这些拼图的部分是简单且彼此独立的。
很好,但是怎么做?
我已经列出了分离数据旅程阶段所需的步骤,并使每个步骤在之后简单自动化。请注意,无论你的技术背景如何,你都应该能够遵循这些步骤(从基本的 Excel 文件到复杂的 Python 流程)。你可以随时调整你的方法,以拆解你的过程,并使你未来的自己(或你的备份/替代人员)能够重复/更新/更改它。没有人应该在每次想做小修改时都需要剖析一个变成黑箱的文件!
了解最终的仪表板需求
从仔细倾听开始。客户和最终用户(或产品负责人)会带来他们的愿望清单和必需品。他们会关注他们想看到的最终效果和格式。作为报告的负责人,你需要记住的是,报告的目的是:
-
分析数据
-
得出结论
-
做出更好的决策
因此,当他们说“我需要 A,并且应该显示 B”时,你的下一个问题不应该是:
-
什么颜色?
-
什么大小?
-
什么类型的图表?
相反,最好找出你的产品负责人为什么想要看到那个指标。问问自己:他们想要达成什么目标?当你了解他们的优先级时,你可以在开始分析他们的数据之前回答一些重要问题,例如:
-
这是一次临时分析吗?
-
我想回答什么问题?
-
我的受众是谁?
-
他们习惯于什么细节级别?
-
这个报告是否有助于促进定期讨论?
-
那次讨论的格式是什么?
-
我如何确保这些讨论围绕解决问题展开?
(而不是关注数字的来源或它们对每个参与者的意义?)
这是信任发挥作用的地方。如果你的客户知道你理解他们的需求并花时间清理和优化他们的数据,他们会相信这些数据反映了他们的现实。最终,这就是每个客户想要的。可以信任的数据。
在这个过程的这个阶段,在经过几次对话后,你应该对所需的工作范围、仪表板的目的以及他们计划如何使用它有了更清晰的了解。这样你就可以开始工作,并且要尽快完成(你可以确定,花在这个阶段的时间越多,愿望清单上会增加更多的附加需求)
访问数据
这是你多任务处理技能受到考验的阶段。确保你提出一个类似这样的清单:
| 数据源 | 所需频率 | 目的 | 访问者 | 状态 | 临时解决方案 |
|---|---|---|---|---|---|
| 数据源 A | 每日更新 | 需要用于主页 KPI:- A - B - C | 团队/人员 | 已请求/票证开放/等待批准/已批准/… | 使用提取数据 |
| 数据源 B | 每周更新 | 需要用于安全层(用户和角色) | 团队/人员 | 使用测试环境/虚拟数据 | |
| 源 C | 每月更新 | 实现实际与目标对比功能所需 | 团队/人员 | 不可用 |
这将大大有助于跟踪你想要什么和不想要什么,同时保护你免受瓶颈困扰。商业中最不愿听到的就是借口,所以提供事实吧。这是我拥有的和我没有的,以及在等待它时我正在使用的。你的产品负责人将会知道如何准确帮助你,因为他们希望你迅速推进到一个完成的解决方案。他们还会知道哪些数据已被提供给你作为替代方案(提取数据、测试/虚拟数据等……),以便你能在没有最终数据的情况下继续工作。
最重要的是,这展示了资源的机智(在最终访问待定时仍能工作)和透明度(他们准确知道为什么某个部分的解决方案尚未构建或在处理非生产数据)。保持合作伙伴的参与和建立信任要求你具备机智和透明度。这将为你在未来阶段节省许多麻烦。
数据摄取(获取)
从快速胜利开始,确保在流程早期有一个简单的演示,并专注于拥有一些数据。获取最原始的数据,而不是那些无人负责的处理过的数据。如果原始数据过大,那么就使用它的一个子集。一个典型的错误是过早地将数据聚合,直到太晚时才意识到需要更多。在演示时,摄取每个数据源的原始子集。
在这一点上(而不是更晚的时候!),记录和文档你所获取的内容,并始终告知客户你已获得足够的数据来构建第一个演示。有些仪表板可能需要二十多个不同的数据源,结合多种方式,这些方式难以记住。在这里,摄取后,你开始建立你的 ERD (如何构建实体关系图),或针对更简单的用例,构建你的数据库图以简单记录你拥有的(或计划拥有的)数据。无需花哨,你可以使用笔和纸、白板、数字白板工具(如 Excalidraw、Microsoft Whiteboard、Visio、Google Draw……)或 markdown (mermaid ERD),只要你理解你拥有的数据以及它们如何合并成最终的平面表格即可。
数据合并
这是你创造最大价值的地方。通过在数据之间建立强有力的关系,你构建了干净且完整的操作数据集,使最终用户的工作更加轻松。理想情况下,他们可以在几秒钟内连接到产品(使用 SQL、Python、Tableau、PowerBI 等),并直接开始分析。这不是一项容易的任务,它取决于你在第一步(理解最终需求)做得有多好。像处理任何棘手任务一样,先将其拆解为步骤,并使用一个 可视化示例:
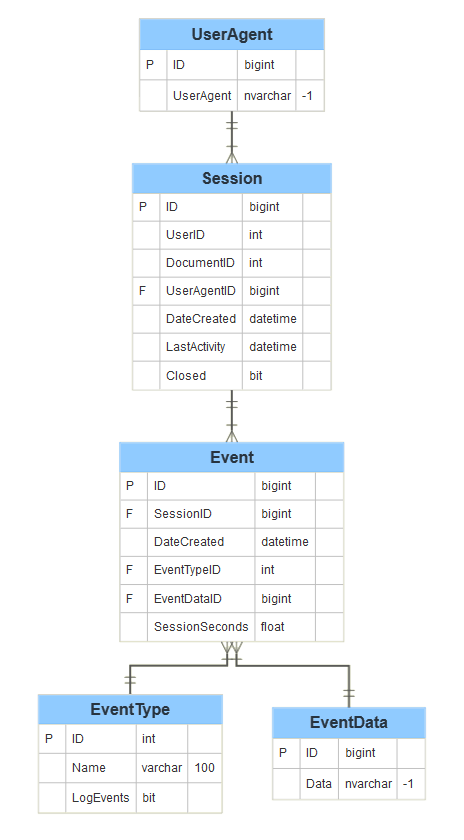{kind=link}

在当前示例中,我们有五个数据集(UserAgent、Session、Event、EventType、EventData)
使用你的可视化工具(基于前一步骤构建)并确保每个原始数据集都有一个唯一的键,可以用来与其他数据集建立连接(这些可以是来自数据源的自定义 ID,或自动生成的键)。你可能需要清理(注意数据类型!)某些字段,并生成你的键(例如,添加一个连接列)以确保连接正常工作。
请注意,在此示例中,每个 UserAgent 都有一个 ID,每个会话都有自己的 ID,并且还有它关联的 UserAgentID。在会话期间,会发生一个事件(新的 ID)。花一点时间识别出哪些是你的核心数据集,即那些处于你将要报告的同一级别的数据集?这将帮助你建立所有的连接并在需要时进行联接。请参见以下一些场景:
-
UserAgent 层级分析:最终用户希望拥有一个仪表盘,允许他们了解出现了多少个 UserAgent 以及它们的参与情况(每个会话的会话数和事件数……)。你需要以“UserAgent”数据集作为核心,然后将 Sessions 和 Events 作为补充信息,以帮助你回答有关用户的问题。
-
会话分析:最终用户希望拥有一个仪表盘,允许他们了解发生了多少个会话,也许还有一些用户或与这些会话相关的事件的特征。在这里,你的核心数据集将是“Session”,并与“Event”、“EventType”、“EventData”进行联接……
-
事件分析:最终用户希望拥有一个仪表盘,允许他们了解用户会话期间发生的最常见事件。在这里,核心数据集将是“Event”,并与“Event Type”、“Sessions”、“EventData”进行联接……
记住**,**你的仪表板可能需要以上所有内容。你可能需要关注不同的数据集,因此如果你正确完成了第一步,你会知道你需要多个操作表作为产品的一部分。执行你的连接(使用 SQL、Python、数据处理工具或甚至在最初阶段使用 Excel),并定期检查记录数,以防止在连接表时生成虚假行,并创建最简单的操作表版本。
将所有终端用户要求的计算直接添加到模型中(而不是你的可视化工具上)。每次用户需要使用这些计算数据时,他们将直接从数据集中获取,而不是从仪表板导出。这也更具扩展性,并避免了由多个用户构建的不同仪表板之间的数据差异。
现在你有了初步操作数据,回到多任务处理。你可以构建一个快速演示来让终端用户使用,以便给你提供数据准确性的反馈,同时你并行处理下一步。
清理和格式化数据。
首先,快速浏览数据,以了解你使用了什么数据。然后查看(例如,前 10 行和最后 10 行),注意细节。这包括:
-
数据类型(数值、文本、日期、布尔值、数组)。
-
数据格式(小数、整数)。
-
相同数据类型的所有列原始数据格式是否一致(例如,所有日期列是否有相同的日期格式)。
-
是否是数值(定量)和类别(定性)数据。
-
如果是文本数据 -> 它是什么?城市名称?产品代码?
这些都有助于理解数据之间的关系,确定数据需要什么样的准备/处理,并调整可视化技术。记得查找空值、数字/文本、语言之间的不同格式(对于自由文本)和 HTML 标签清理。
通过过滤或快速摘要完成这项工作。所有这些都会避免在可视化过程中繁琐的步骤,如果数据清晰且格式正确,准备可视化只需几次点击。
其次,深入了解细节。根据数据类型,数据清理的方法不同,可能存在不同种类的“异常值”。对特定数据类型要查看的内容总结:
日期
-
检查数据存储的数据类型。如果数据与日期无关,存在例如日期被处理为数值的风险,那么开头的零可能会被删除。
-
保持一致的格式(例如,‘YYYY-MM-DD’)。
-
日期只应在有意义的情况下使用(例如,出生日期不应是未来的)。
文本
-
如果文本很长(例如推文),使用分词方法。
-
确保名称的一致性(例如,数据可能包含 ‘USA’、‘United States of America’ 和 ‘U.S.A.’,这些都是指同一事物)。
数值
-
保持格式一致(例如,保留两位小数,整数应表现为整数,而非小数等)
-
检测异常值(例如通过可视化、Z-score 方法、IQR 方法,异常值可能对指标有显著影响,这就是为什么重要的是要思考它们为何出现以及是否需要删除/修正它们,或者它们是否包含重要且真实的信息,这可能对业务(例如欺诈)至关重要)-> 异常值是一个庞大的话题
-
逗号或句号 -> 保持一致
同样,如果你有分类数据,确保类别有意义,并且没有两个类别适用于同一事物。记得记录你创建/调整的类别,以便数据用户能准确了解其含义
第三,提供列名。
-
在处理/建模时记得使用简单、描述性的列名,避免词间的空格和特殊符号,以免给自己带来不必要的麻烦
-
对于业务使用的最终模型,使用他们所需的列名
-
尽量遵循 命名规范(或按照指南创建自己的规范),记录下来并让你的数据用户熟悉它。在数据集之间保持一致,你将逐渐在你的组织中建立起清晰数据的文化,大家都能理解
如果你理解你的产品负责人的优先事项,像 Power BI 和 Tableau 这样的商业智能技术可以优化和准备数据用于 Tableau 和 PBI 仪表板。一旦你获得数据,你可以进行摄取、组合、清理和格式化。
此时,你可能已经准备好跳到你的 BI 工具(PowerBI、Tableau……)中,将所有这些步骤整合到一个文件中,连接到数百万个原始提取数据。抵制这个冲动,相信解耦的过程!记住,简单是这里的关键词
-
听,听,听。
-
制作作为参考的列表
-
将事情分解成更小的步骤(数据摄取、数据验证、数据清理……)
-
对于数据处理,使用为自动化数据建模而设计的工具
(Python、SQL、可视化 SQL,甚至 Excel,如果这是你熟悉的)
-
最终仪表板要坚持使用可视化工具
别忘了记录你的进展!你将转到下一个有趣的项目,很可能会忘记所有细节。虽然这篇文章没有覆盖这个内容,但可以看看 如何构建自解释的流程 并在截止日期临近时节省时间。
“你的未来自我会感谢你!”
Valeria Perluzzo 是 dyvenia 的分析主管。
更多相关话题
如何准备数据科学面试
原文:
www.kdnuggets.com/2022/12/prepare-data-science-interview.html

图片由作者提供
如果你未能准备,你就是在准备失败。这不是我的话,而是本杰明·富兰克林的话。老 Beejey 考虑到他一生中担任的多个职位,可能是面试方面的专家。他的建议对数据科学面试来说再好不过了。
我们的前 3 名课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
 3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
拿破仑·波拿巴采纳了 Beejey 的建议,但在滑铁卢公司面试失败后,意识到过度准备是灵感的敌人。
一如既往,真相总是在两个极端之间。你如何在准备充分与保持个性和自发性之间找到平衡?
我将讨论你需要彻底准备的内容以及你应有意少准备的内容。

图片由作者提供
如何准备(并成功)数据科学面试?
在面试之前,你需要彻底了解几件事情。这些都是需要知识、训练有素和精准的基础内容。只有在充分准备的情况下,你才能做到这一点。
-
研究公司
-
研究职位
-
了解面试过程
-
练习技术技能
-
构建项目组合
每次数据科学职位面试都围绕技术技能展开。然而,所有其他准备阶段同样重要。这些准备将使你高效地练习技术技能,并在面试中使其脱颖而出。
1. 研究公司
这一部分的准备通常被认为是必要的,因为‘它留下了好印象’。你不想留下好印象。你想在面试中表现出色。这两者通常被混淆。做一些事情以留下好印象意味着你在尝试做你认为面试官想听的内容。大家都在说同样的事:面试官喜欢看到你对公司和角色进行了研究。
是的,这是真的。但留下好印象只是结果,而不是彻底研究公司的原因。你这么做的原因是你需要知道一旦你获得工作,你和你的技能如何适应。如果你想在那里适应的话。

图片来源:作者
需要关注的事项
在研究公司时,你应关注公司的:
-
历史
-
产品
-
组织结构
-
雇主
-
财务表现
-
竞争对手
-
新闻
历史。 这包括了解公司成立的时间,它在你所在市场的历史,以及它如何在历史中发生变化(如合并、收购、所有权变更)。
你可能希望了解,因为你可能不想为一家拥有可疑所有者的公司工作。或者你特别喜欢公司如何自然成长为今天的模样?也许你想避开新成立的公司,认为那些历史更久远的公司更能给你安全感。或者初创公司正是你所寻找的。
产品。 通过了解公司销售的产品,你可以获得更多关于公司概况的信息。他们的产品是便宜且低质量的吗?还是以质量闻名?哪些产品是主要的收入来源?你是否已经使用了这些产品,或者对其中一些产品有极大的反感?公司的市场份额是多少?他们的最新产品是什么?
组织结构。 检查公司的组织结构。了解他们的组织架构是多么高层或扁平。查找他们的高管、他们的经验以及就业历史。找出员工人数。熟悉各个部门,并了解每个部门的目的。找出他们在多少个国家和地区运营。
雇主。 查看他们的现任和前任雇员对公司的评价。他们为什么离开?他们为什么留下?此外,在这个阶段,你还应该尝试了解你职位的薪资范围。
财务表现。 不需要查看过去十年的所有财务报告。但要了解最新的总体趋势,如收入、利润和股价。
竞争对手。 这与公司的产品有关。找出他们的产品与谁竞争。与竞争对手相比,他们的表现如何?公司的市场份额是在缩小还是增长?通过了解竞争对手,你还会对公司的行业有更多了解。
新闻。 通过阅读关于公司的新闻,你可以对公司的未来有所了解。他们是否推出了新产品或停产了一些产品?他们是否打算上市?谁想接管公司?公司是否在收购其竞争对手?公司的首席执行官是否采取了你喜欢或不喜欢的政治立场?
让我向你展示,了解上述内容对你来说有多重要,而不仅仅是你留下的印象。希望你能够选择你想工作的雇主。对数据科学家绝望的雇主可能会把你放在那种位置上,所以你需要了解你的谈判能力。
如果你对此有所了解,这意味着你也可以选择你的雇主。如果你被面试的是一个成立了 2 年的初创公司(历史),他们销售市场上最受欢迎的产品,你是(产品与竞争对手)的粉丝,而且你只有一个老板(层级结构),这个老板非常直言不讳并且在为种族不平等问题做些什么(新闻),你可能会非常愿意为这样的公司工作。尤其是当他们为数据科学家提供高于平均水平的薪资(员工)时。
从中,你还可以更清楚地了解公司可能如何利用你的技术专长以及他们使用什么技术。了解这些信息能为你的技术技能准备提供更多方向。
但你如何判断公司的情况是否适合你?
去哪里寻找?
你所需信息的来源是:
-
公司网站
-
公司的社交媒体账号
-
相关媒体渠道
-
LinkedIn
-
论坛和其他网站上(潜在)雇主对公司的评价
2. 研究职位
现在你对公司了解得很清楚了,进一步了解你申请的职位。

作者提供的图片
再次查看职位描述。记录下提到的技术。广告重点关注哪些技能?(你在练习技术技能时会用到。)你的日常工作是什么?你将与哪些团队/部门/分支机构合作?你向谁汇报?
为什么这很重要?例如,如果你是产品开发团队中的数据科学家,你知道你的技术技能准备将需要更具产品导向。
3. 了解面试流程
一旦你对公司的总体情况和你的位置有了感觉,下一步就是了解公司的面试流程。
在这里你会更具体地了解。你需要知道面试中会有什么期待和会见到谁。
面试的内容
数据科学面试通常包括三个阶段:
-
电话筛选/在线评估
-
面对面面试
-
HR 面试

作者提供的图片
电话筛选涉及到你未来的团队成员或老板了解你。你会讲解你的简历,谈论你的教育背景、工作经历以及职业兴趣。这个阶段通常包括几个行为问题,可能还会有一两个一般性的技术问题,以确保你是这个职位的合适人选。
一些公司还喜欢通过在线评估来测试你的技术和编程知识。通常需要 30 到 90 分钟。
面对面面试的次数取决于公司。无论如何,这通常是面试过程中的最严峻环节。你将会被各种行为和技术问题轰炸,还有可能会有编程测试,甚至可能会有家庭作业。根据公司情况,这也可能包括与高管的面试。
如果你能挺过这些,最后阶段通常只是形式上的。
HR 面试只是为了对雇主在其他面试阶段了解到的关于你的信息做最后确认。预计会有一些非常简单的行为问题,偶尔也会有技术问题。这个阶段主要是讨论薪资、福利以及其他与你的雇佣相关的细节。
面试的相关人员
相关人员?不是那个乐队。在这里你要找出谁将会是面试官。如果你知道他们的名字,可以进行调研。
在 LinkedIn 上查找他们的工作经历。用谷歌搜索他们。试着找到他们的社交媒体账户。别担心,他们也会偷偷关注你。
从你了解到的情况,你可以对他们有一定的了解。这可以帮助你知道在面试中期待什么,以及如何适应面试官。例如,如果面试官没有技术背景,你可以尝试不要在回答中使用过多的技术术语。也许这正是他们想测试的:你如何向非技术人员解释技术问题?此外,你也可以通过提及你们都喜爱的足球队来建立联系。
但要保持一些尊严。不要试图讨好面试官。
4. 练习技术技能
没办法告诉你面试中会问到的具体问题。但我可以告诉你会遇到哪些类型的问题。
我和我的团队在 2021 年为我们的数据科学面试指南进行了这个分析。可以放心地说,在这期间没有发生显著变化,所学内容没有过时。
我们的研究发现,数据科学家最常见的问题类型是编码。其他经常出现的主题包括建模、算法和统计。

图片作者
数据科学中最常见的编程语言是
-
SQL
-
Python,
-
R
你应该将编程练习集中在这三种语言上。但这也是你通过研究公司、职位和面试过程而受益的地方。
你应该知道数据科学家在特定公司使用哪些编程语言。也许这三种语言都同等重要?也许他们只使用其中一种语言。如果你知道这一点,你可以集中精力在它上面,而不是浪费时间在他们甚至不使用的编程语言上。或者,你可以扩展你的准备,因为你知道公司会希望你使用额外的编程语言。
如果你在谷歌上搜索“数据科学面试问题”,你会找到许多资源,其中包含更多或更少的通用问题。最常见的情况下,这将是四个最流行类别中的问题。
随意阅读这些内容,理解他们的答案并解码。你还可以在如 Glassdoor、Quora 或 reddit 等网站上找到一些实际的问题。
这可能是一个好的开始,但通常不够。
这个部分的名字中有“练习”是有原因的。回答技术问题需要练习,尤其是编程方面。
由于编程是最受欢迎的主题,我建议你解决尽可能多的编程挑战。这不仅会提高你对重要编程概念的掌握,还会提升你的速度。你会习惯于问题的提问方式。通过练习,你还可以发展自己的系统化解题方法。
一些好的资源用于 数据科学面试问题 是:
5. 项目作品集
尽管面试可能会让人感到不知所措,但它们只能给出候选人的技能和整体适应性的大致估计。
再次强调,你不是为了取悦面试官而创建作品集。拥有数据科学项目的作品集是一个好主意,因为这是你将所有数据科学技能应用于实际问题的终极考验。
当你构建你的作品集时,你会将你的技术技能准备提升到一个全新的水平。
当然,并不是每个项目都值得展示在你的作品集里。当你选择做哪些项目时,最好选择那些涉及以下方面的项目:

作者提供的图片
-
使用实际数据(APIs 和其他技术)
-
使用数据库存储数据,最好是云数据库
-
构建模型
-
部署模型/使用可视化工具创建图形
-
发布你的工作以获取反馈(reddit,GitHub)
做那些需要所有这些技能的项目将意味着你掌握了所有必要的数据科学技能。
在面试前检查你的作品集。删除一些你以前的初学者项目。只保留那些你认为能充分展示你当前技能的项目。
如果你的作品集很庞大,根据你面试的职位进行调整。选择几个最适合职位描述的项目。
什么不该准备(并且成功)?
现在,让我们看看你应该有意少准备什么,以便在面试中表现得最好。
我说的少准备是什么意思?我并不是指完全不准备。我是说,你应该只准备一些一般性的指导方针。对预期的情况和该说些什么有一个大致的了解。
但不要再进一步了!面试的这一部分严重依赖于你和面试官之间的互动,取决于面试的方向,这是不可预测的。你无法预先设定这些!
所以尽量放松,注意你周围的环境,针对你听到和看到的做出反应。这是你能拥有的最佳‘准备’。
面试官提问
当然,你是‘允许’思考不同的场景以及你应该问面试官的问题。如果你在面试前发现自己有一些好的问题,可以记住它们并在面试时提问。
如果你没有准备好问题,不要慌张。首先,说没有愚蠢的问题是不对的。是的,有愚蠢的问题。(当我说愚蠢时,我指的是为了提问而提问。)所以,没有提前准备好问题总比准备一些愚蠢的问题要好。
其次,问题会在与你的面试官对话过程中自然地出现。如果面试官提到一个数据库,这时你可以问他们使用的是哪个数据库和 SQL 方言。他们说你将成为数据科学团队的一员,你可以问他们团队有多少成员,谁会是你的上司。
你能看到它是多么自然吗?问题的要点在于不要假装专注。专注会导致你有问题要问。记住,尽管它被称为面试,它实际上是一场对话。在对话中,每个参与者都在提问和回答问题之间转换。
行为问题
我之前提到过,面试中除了技术问题,还会有行为问题。
你也不应该详细准备这些问题。这些问题没有正确答案,答案应该来自于你的经验,你对情况的处理,以及你的思考。简而言之,来自于你的个性。
面试官想了解你。让他们了解你。留出一些自发性、沉默和思考的空间。不要害怕停顿,也不要害怕两周前没有准备好每一个词。
是的,提前考虑一下你如何与团队成员解决冲突,或者想到一个显示你在压力下如何反应的例子,这是好的。但只需从一般的角度考虑,以便你对故事有一个大致的了解。不要把你想说的一切都背下来。
你对这些问题的回答不应该是机械的。此外,与普遍看法相反,面试官欣赏那些在回答前花时间思考的人。当然,有些面试官不这样做。但是,你愿意为一家不允许你思考的公司工作吗?作为数据科学家?我也不愿意。
摘要
数据科学面试准备 本身并不复杂,特别是考虑到可以帮助你的资源数量。使其相对困难的是,正确完成准备工作需要时间。
这需要你在充分准备和展示个人风格之间找到平衡。
尝试在下次面试中应用这些一般性的建议,看看效果如何。
Nate Rosidi 是一名数据科学家和产品战略专家。他还是一名兼职教授,教授分析课程,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题为面试做准备。可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
相关主题
Presto 为数据科学家 – SQL 适用于任何数据
原文:
www.kdnuggets.com/2018/04/presto-data-scientists-sql.html
 评论
评论
由 Kamil Bajda-Pawlikowski,Starburst Data 的 CTO 提供。
最初由 Facebook 开发,Presto 是一个开源、分布式 ANSI SQL 查询引擎,它能够快速分析各种数据源,数据规模从吉字节到拍字节不等。对于数据科学家来说,这对于在几秒钟内返回大数据查询结果非常理想,通过支持仪表板、报告和临时分析,加快数据科学发现的迭代过程。
Presto 被从零开始设计和构建,目的是成为一个快速的 SQL 查询引擎。它遵循经典的 MPP SQL 引擎设计,其中查询处理在机器集群上并行进行。因此,高度并发的查询以交互速度执行。然而,它有一个显著的偏离传统并行数据库管理系统的教科书配方——计算和存储的分离。Presto 的架构完全抽象化了它可以连接的数据源。连接器 API 允许为文件系统和对象存储、NoSQL 存储、关系数据库系统以及自定义服务构建插件。只要数据科学家能够将数据映射到表格、列和行等关系概念中,就可以创建一个 Presto 连接器。
实际上,Presto 配备了大量现有的连接器,包括 HDFS、S3、Cassandra、Accumulo、MongoDB、MySQL、PostgreSQL 和其他数据存储。此外,在 Presto 的单个安装中,用户可以注册多个目录,并运行访问多个连接器的数据的查询。此外,虽然许多数据科学项目和生产应用程序需要执行 ETL,但使用 Presto,你可以直接查询数据所在的位置。
例如,想象一下将来自 RDBMS 的客户数据与 Kafka 中的最新事件关联,并回到 Hadoop 或 S3 查看这些数据如何与过去的趋势相关。这确实是“SQL-on-Anything”。

Presto 将许多最流行的大数据源与各种分析、商业智能、仪表板和可视化应用程序连接起来。
与大量 SQL-on-Hadoop 引擎不同,Presto 在大数据查询和分析中不依赖于 Hadoop。它几乎可以部署在任何地方,无论是在公共云、虚拟机集群还是本地专用集群。如果 Hadoop 在其中,数据科学家可以放心。Presto 仅通过连接到 Hive Metastore 允许用户与 Hive、Spark 和其他 Hadoop 生态系统工具共享相同的数据。一个不依赖于 Hadoop 的额外好处是供应商中立的方法,以及对包括 Avro、ORC、Parquet、RCFile、Text 等常见文件格式的原生支持。
在过去几年里,Presto 在 各种规模的企业 中经历了前所未有的增长,从快速发展的互联网公司到《财富》500 强。除了 Facebook,早期采用者还包括 Airbnb、Dropbox、Groupon 和 Netflix 等。Presto 路线图的加速以及成功的概念验证也导致了在 Bloomberg、Comcast、FINRA、LinkedIn 和 Lyft 以及 Slack、Twitter、Uber 和 Yahoo! Japan 的生产部署。
确实,上个月在 圣荷西的 Strata Data Conference 上,几位领先的 Presto 采用者 讨论了他们的部署 并展示了互动速度、卓越的查询并发性 和出色的可扩展性。
除了快速的 ANSI SQL 和对多种数据源的访问外,Presto 还为数据科学家提供了什么?考虑易用性、简单的部署和通过 Superset、Redash、Jupyter 和众多支持 JDBC 和 ODBC 的分析工具的访问。考虑到 Presto 与数据科学生态系统的良好集成,它支持包括 C、Go、Java、Python、R 和 Ruby on Rails 在内的流行编程语言。
此外,Presto 具有大量的 内置分析函数,包括 lambda 表达式和函数、窗口函数、正则表达式,甚至地理空间函数——被 Uber 公共地广泛使用。除了标准 SQL 数据类型,数据科学家还可以处理复杂类型,如映射、数组、结构体和 JSON。
如果这引起了你的兴趣,我鼓励你下载免费的开源 Presto 并分享你的故事。对许多数据科学家来说,这可以迅速成为快速查询大数据和互动分析的游戏规则改变者。
相关:
我们的前三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
 3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 事务
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 事务
更多相关内容
机器学习中的主要监督学习算法
原文:
www.kdnuggets.com/2022/06/primary-supervised-learning-algorithms-used-machine-learning.html

什么是监督学习?
我们的前三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
 2. 谷歌数据分析专业证书 - 提升您的数据分析技能
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
 3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
监督学习是机器学习的一个子集,其中机器学习模型在已标记(输入)数据上进行训练。结果是,监督模型能够尽可能准确地预测进一步的结果(输出)。
监督学习背后的概念可以通过实际场景来解释,例如教师第一次辅导孩子学习新主题。
为了简化,假设教师想要教孩子成功识别猫和狗的图像。教师将通过不断展示猫或狗的图像,并告知孩子这些图像是狗还是猫,来开始辅导过程。
猫和狗的图像可以被视为已标记的数据,因为孩子/机器学习模型在训练过程中将被告知哪些数据属于哪个类别。
监督学习用于什么?监督学习可以用于回归和分类问题。分类模型允许算法确定给定数据属于哪个组。例子包括真假、狗/猫等。
虽然回归模型能够根据之前的数据预测数值,例如预测某员工的薪资或房地产的售价。
在本教程中,我们将列出一些最常见的监督学习算法,并提供这些算法的实际教程。
请注意,这些教程使用 Python 编写。所有使用的数据集都可以在 Kaggle 上找到,因此无需下载任何大型数据集。
线性回归
线性回归是一种监督学习算法,根据给定的输入值预测输出值。线性回归用于目标(输出)变量返回连续值的情况。
线性算法主要有两种类型,简单和多重线性回归。
简单线性回归仅使用一个独立(输入)变量。例如,根据一个孩子的身高预测其年龄。
另一方面,多重线性回归可以使用多个独立变量来预测最终结果。例如,根据房产的位置、大小、需求等预测房地产价格。
以下是线性回归公式

在我们的 Python 示例中,我们将使用线性回归根据给定的 x 值预测 y 值。
我们给定的数据集将仅包含两列;x 和 y。注意,y 结果将返回连续值。
要查找使用的数据集,请查看Kaggle 上的随机线性回归数据集。以下是该数据集的截图。

Python 中的线性回归模型示例
1. 导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import linear_model
from sklearn.model_selection import train_test_split
import os
2. 读取和采样我们的数据集
为了简化数据集,我们取了 50 行数据的样本,并将数据值四舍五入到 2 位有效数字。
注意,在完成此步骤之前,您应导入给定的数据集。
df = pd.read_csv("../input/random-linear-regression/train.csv")
df=df.sample(50)
df=round(df,2)
3. 过滤空值和无限值
如果我们的数据集中包含空值和无限值,可能会出现不必要的错误。因此,我们将使用 clean_dataset 函数清除数据集中这些值。
def clean_dataset(df):
assert isinstance(df, pd.DataFrame), "df needs to be a pd.DataFrame"
df.dropna(inplace=True)
indices_to_keep = ~df.isin([np.nan, np.inf, -np.inf]).any(1)
return df[indices_to_keep].astype(np.float64)
df=clean_dataset(df)
4. 选择我们的依赖值和独立值
注意,我们将数据转换为 DataFrame 格式。dataframe 数据类型是一个二维结构,将数据排列成行和列。
5. 拆分数据集
我们将把数据集分为训练集和测试集。我们选择测试数据集的大小为总数据集的 20%。
注意,通过设置 random_state=1,每次模型运行时将发生相同的数据分割,从而得到完全相同的训练集和测试集。
这在你想进一步调整模型时可能会很有用。
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=1)
6. 建立线性回归模型
使用导入的线性回归模型,我们可以在模型中自由使用线性回归算法,而无需考虑获得的 x 和 y 训练变量。
lm=linear_model.LinearRegression()
lm.fit(x_train,y_train)
7. 以散点图方式绘制我们的数据
df.plot(kind="scatter", x="x", y="y")
8. 绘制我们的线性回归线
plt.plot(X,lm.predict(X), color="red")

蓝色点表示我们的数据点,而红色线是由模型绘制的最佳拟合线。线性模型算法将始终尝试绘制最佳拟合线,以尽可能准确地预测结果。
逻辑回归
类似于线性回归,逻辑回归用于根据定义的输入变量预测输出值,但这两种算法的主要区别在于逻辑回归算法的输出应为分类(离散)变量。
对于我们的 Python 示例,我们将使用逻辑回归将给定的花分类为两种不同的类别/物种。我们的数据集将包括不同花卉物种的多个特征。
我们模型的主要目的是将给定的花识别为鸢尾花-石斛(Iris-setosa)、鸢尾花-变色(Iris-versicolor)或鸢尾花-维吉尼卡(Iris-virginica)。
要查找使用的数据集,请查看 Kaggle 上的鸢尾数据集?—?逻辑回归。下面是给定数据集的截图。

使用 Python 的逻辑回归模型示例
1. 导入必要的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
2. 导入数据集
data = pd.read_csv('../input/iris-dataset-logistic-regression/iris.csv')
3. 选择自变量和因变量
对于我们的自变量(x),我们将包括所有可用的列,除了类型列。至于我们的因变量(y),我们只会包括类型列。
X = data[['x0','x1','x2','x3','x4']]
y = data[['type']]
4. 划分数据集
我们将把数据集分为两部分,80%用于训练数据集,20%用于测试数据集。
X_train,X_test,y_train,y_test = train_test_split(X,y, test_size=0.2, random_state=1)
5. 运行逻辑回归模型
我们将从 linear_model 库中导入整个逻辑回归算法。然后,我们可以将 X 和 y 的训练数据适配到逻辑模型中。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(random_state = 0)
model.fit(X_train, y_train)
6. 评估模型的性能
print(lm.score(x_test, y_test))
返回的值为0.9845128775509371,这表明我们的模型表现优异。
请注意,随着测试得分的提高,模型的性能也会提高。
7. 绘制图表
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(range(len(X_test)), pred,'o',c='r')
输出图表:

在逻辑图中,红色点表示给定的数据点。点被清晰地分为 3 个类别:维吉尼卡、变色和石斛花物种。
使用这种技术,逻辑回归模型可以根据花卉在图上的位置轻松地对花的类型进行分类。
支持向量机
支持向量机(SVM)算法是由弗拉基米尔· Vapnik 创造的另一种著名的监督机器学习模型,能够处理分类和回归问题。尽管如此,它更常用于分类问题而非回归问题。
SVM 算法能够将给定的数据点分成不同的组。这是通过让我们的算法绘制数据,然后画出最合适的线来将数据分成多个类别来完成的。
如下图所示,绘制的线将数据集完美地分成了两个不同的组,蓝色和绿色。

SVM 模型可以根据绘图的维度绘制线条或超平面。线条只能处理二维数据集,即只有两列的数据集。
由于可能会使用多个特征来预测给定的数据集,因此需要更高的维度。当我们的数据集结果超过 2 维时,支持向量机模型会绘制出更合适的超平面。
在我们的支持向量机 Python 示例中,我们将对 3 种不同的花卉类型进行物种分类。我们的自变量将包括某种花卉的所有给定特征,而因变量将是该花卉所属的指定物种。
我们的花卉物种包括Iris-setosa、Iris-versicolor和Iris-virginica。
要查找使用的数据集,请查看Kaggle 上的 Iris Flower Dataset。下面是给定数据集的截图。

使用 Python 的支持向量机模型示例
1. 导入必要的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
2. 阅读给定的数据集
注意,在进行此步骤之前,您应该导入给定的数据集。
data = pd.read_csv(‘../input/iris-flower-dataset/IRIS.csv’)
3. 将数据列拆分为因变量和自变量
我们将 X 值作为自变量,其中包含除物种列之外的所有列。
对于我们的因变量,y 变量将仅包含物种列,这是我们的模型应该预测的。
X = data.drop(‘species’, axis=1)
y = data[‘species’]
4. 将数据集拆分为训练数据集和测试数据集
我们将数据集分为两部分,其中 80%的数据用于训练数据集,20%的数据用于测试数据集。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
5. 导入 SVM 并运行模型
我们整体导入了支持向量机算法。然后我们使用从前面步骤中获得的 X 和 y 训练数据集运行了它。
from sklearn.svm import SVC
model = SVC( )
model.fit(X_train, y_train)
6. 测试我们模型的性能
model.score(X_test, y_test)
为了评估我们模型的性能,我们将使用评分函数。在其中,我们将把在第四步中创建的 X 和 y 测试值传递给评分方法。
返回的值是0.9666666666667,这表明我们的模型表现良好。
注意,测试分数的增加也意味着模型性能的提升。
其他流行的监督机器学习算法
尽管线性、逻辑回归和支持向量机算法相当可靠,我们还会提到一些值得一提的监督机器学习算法。
1. 决策树

决策树算法 是一种监督机器学习模型,利用类似树的结构进行决策。决策树通常用于分类问题,在这种问题中,模型可以决定数据集中给定项所属的类别。
请注意,使用的树形结构是倒置树。
2. 随机森林

被认为是一种更复杂的算法,随机森林算法通过构建大量决策树来实现其最终目标。
意味着同时构建多个决策树,每个树返回自己的结果,然后将结果结合以获得更好的结果。
对于分类问题,随机森林模型会生成多个决策树,并根据大多数树预测的分类组来分类给定对象。
这样,模型可以修正由单棵树造成的任何过拟合。虽然随机森林算法也可以用于回归,但可能会导致较差的结果。
3. k-最近邻

k-最近邻(KNN)算法是一种监督机器学习方法,将所有给定数据分组为不同的组。
这种分组是基于不同个体之间的共同特征。KNN 算法可以用于分类和回归问题。
KNN 问题的一个例子是将动物图像分类为不同的组。
结论
回顾我们在本文中学到的内容,我们首先定义了监督机器学习以及它可以解决的两种问题类型。
接下来我们解释了分类和回归问题,并给出了每种问题类型的输出数据类型的一些示例。
然后我们解释了什么是线性回归,它是如何工作的,并提供了一个用 Python 编写的具体例子,该例子试图根据独立的 X 变量预测 Y 值。
我们还解释了一个与线性回归模型类似的模型,即逻辑回归模型。我们说明了什么是逻辑回归,并给出了一个分类模型的例子,该模型将给定的图像分类为特定的花卉品种。
对于我们的最后一个算法,我们使用了支持向量机算法,我们也用它来预测三种不同花卉的花卉品种。
在我们文章的结尾,我们简要介绍了其他知名的监督机器学习算法,如决策树、随机森林和 K 最近邻算法。
无论你是出于学校、工作还是娱乐阅读这篇文章,我们认为从这些基本算法入手可能是开始你新的机器学习热情的好方法。
如果你感兴趣并希望了解更多关于机器学习的世界,我们建议你进一步了解这些算法的工作原理以及如何调整这些模型以进一步提升其性能。别忘了,还有许多其他监督算法等着你去学习。
Kevin Vu 负责管理 Exxact Corp 博客,并与许多才华横溢的作者合作,这些作者撰写有关深度学习的不同方面的文章。
原文。经许可转载。