正在为 OCR 安装宇宙魔方
原文:https://pyimagesearch.com/2017/07/03/installing-tesseract-for-ocr/

今天的博客文章是关于安装和使用用于光学字符识别(OCR)的宇宙魔方库的两部分系列文章的第一部分。
OCR 是将键入的、手写的或印刷的文本转换成机器编码的文本的自动过程,我们可以通过字符串变量来访问和操作这些文本。
本系列的第一部分将着重于在您的机器上安装和配置 Tesseract,然后利用tesseract命令对输入图像应用 OCR。
在下周的博客文章中,我们将发现如何使用 Python“绑定”到宇宙魔方库,从 Python 脚本中直接调用宇宙魔方*。*
*要了解更多关于宇宙魔方以及它如何用于 OCR 的信息,继续阅读。
正在为 OCR 安装宇宙魔方
宇宙魔方最初是由惠普公司在 20 世纪 80 年代开发的,于 2005 年开源。后来,在 2006 年,谷歌采纳了该项目,并一直是赞助商。
宇宙魔方软件适用于许多自然语言,从英语(最初)到旁遮普语到意第绪语。自 2015 年更新以来,它现在支持超过 100 种书面语言,并有代码,因此它也可以很容易地在其他语言上进行培训。
最初是 C 程序,1998 年移植到 C++上。该软件是无头的,可以通过命令行执行。它不附带 GUI,但是有几个其他软件包包装 Tesseract 来提供 GUI 界面。
要阅读更多关于宇宙魔方的内容,请访问项目页面并阅读维基百科文章。
在这篇博文中,我们将:
- 在我们的系统上安装宇宙魔方。
- 验证宇宙魔方安装是否正常工作。
- 在一些样本输入图像上尝试 Tesseract OCR。
完成本教程后,你将掌握在自己的图像上运行宇宙魔方的知识。
步骤 1:安装宇宙魔方
为了使用宇宙魔方库,我们首先需要在我们的系统上安装它。
对于 macOS 用户 ,我们将使用自制软件来安装宇宙魔方:
$ brew install tesseract

Figure 1: Installing Tesseract OCR on macOS.
如果您使用的是 Ubuntu 操作系统 ,只需使用apt-get安装 Tesseract OCR:
$ sudo apt-get install tesseract-ocr

Figure 2: Installing Tesseract OCR on Ubuntu.
对于 窗口 ,请查阅宇宙魔方文档,因为 PyImageSearch 不支持或不推荐计算机视觉开发的窗口。
步骤#2:验证已经安装了 Tesseract
要验证 Tesseract 是否已成功安装在您的计算机上,请执行以下命令:
$ tesseract -v
tesseract 3.05.00
leptonica-1.74.1
libjpeg 8d : libpng 1.6.29 : libtiff 4.0.7 : zlib 1.2.8

Figure 3: Validating that Tesseract has been successfully installed on my machine.
您应该会看到打印到屏幕上的 Tesseract 版本,以及与 Tesseract 兼容的图像文件格式库列表。
如果您得到的是错误消息:
-bash: tesseract: command not found
那么宇宙魔方没有正确安装在你的系统上。回到 步骤#1 并检查错误。此外,您可能需要更新您的PATH变量(仅适用于高级用户)。
步骤 3:测试 Tesseract OCR
为了让宇宙魔方 OCR 获得合理的结果,您需要提供经过干净预处理的图像。
**当使用宇宙魔方时,我建议:
- 使用尽可能高的分辨率和 DPI 作为输入图像。
- 应用阈值将文本从背景中分割出来。
- 确保前景尽可能清晰地从背景中分割出来(即,没有像素化或字符变形)。
- 对输入图像应用文本倾斜校正以确保文本正确对齐。
偏离这些建议会导致不正确的 OCR 结果,我们将在本教程的后面部分了解这一点。
现在,让我们将 OCR 应用于下图:

Figure 4: An example image we are going to apply OCR to using Tesseract.
只需在终端中输入以下命令:
$ tesseract tesseract_inputs/example_01.png stdout
Warning in pixReadMemPng: work-around: writing to a temp file
Testing Tesseract OCR
正确!宇宙魔方正确识别,“测试宇宙魔方 OCR”,并在终端打印出来。
接下来,让我们试试这张图片:

Figure 5: A second example image to apply Optical Character Recognition to using Tesseract.
在您的终端中输入以下内容,注意更改后的输入文件名:
$ tesseract tesseract_inputs/example_02.png stdout
Warning in pixReadMemPng: work-around: writing to a temp file
PyImageSearch

Figure 6: Tesseract is able to correctly OCR our image.
成功!宇宙魔方正确地识别了图像中的文本*“PyImageSearch”*。
现在,让我们尝试 OCR 识别数字而不是字母字符:

Figure 7: Using Tesseract to OCR digits in images.
本例使用命令行digits开关来仅报告数字:
$ tesseract tesseract_inputs/example_03.png stdout digits
Warning in pixReadMemPng: work-around: writing to a temp file
650 3428
宇宙魔方再一次正确地识别了我们的字符串(在这种情况下只有数字)。
在这三种情况下,Tesseract 都能够正确地 OCR 我们所有的图像——你甚至可能认为 Tesseract 是所有 OCR 用例的正确工具。
然而,正如我们将在下一节中发现的,宇宙魔方有许多限制。
OCR 的宇宙魔方的限制
几周前,我在做一个识别信用卡上 16 位数字的项目。
我可以很容易地编写 Python 代码来本地化四组 4 位数中的每一组。
以下是一个 4 位数感兴趣区域的示例:

Figure 8: Localizing a 4-digit grouping of characters on a credit card.
然而,当我尝试将 Tesseract 应用于下图时,结果并不令人满意:

Figure 9: Trying to apply Tesseract to “noisy” images.
$ tesseract tesseract_inputs/example_04.png stdout digits
Warning in pixReadMemPng: work-around: writing to a temp file
5513
注意宇宙魔方是如何报告5513的,但是图像清楚地显示了5678。
不幸的是,这是宇宙魔方局限性的一个很好的例子。虽然我们已经将前景文本从背景中分割出来,但是文本的像素化性质“混淆”了宇宙魔方。也有可能宇宙魔方没有被训练成类似信用卡的字体。
Tesseract 最适合构建文档处理管道,在这种管道中,图像被扫描进来,进行预处理,然后需要应用光学字符识别。
我们应该注意到,Tesseract 是而不是OCR 的现成解决方案,可以在所有(甚至大多数)图像处理和计算机视觉应用程序中工作。
为了实现这一点,你需要应用特征提取技术、机器学习和深度学习。
摘要
今天我们学习了如何在我们的机器上安装和配置 Tesseract,这是将 Tesseract 用于 OCR 的两部分系列的第一部分。然后,我们使用tesseract二进制文件对输入图像进行 OCR。
然而,我们发现,除非我们的图像被干净地分割,否则立方体将给出糟糕的结果。在“嘈杂”的输入图像的情况下,我们可能会通过训练一个定制的机器学习模型来识别我们特定的用例中的字符,从而获得更好的准确性。
宇宙魔方最适合高分辨率输入的情况,其中前景文本 从背景中干净地分割 。
下周我们将学习如何通过 Python 代码访问宇宙魔方,敬请关注。
为了在下一篇关于宇宙魔方的博文发布时得到通知,请务必在下面的表格中输入您的电子邮件地址!***
在系统上安装 Tesseract、PyTesseract 和 Python OCR 包
在本教程中,我们将配置我们的 OCR 开发环境。一旦您的机器配置完毕,我们将开始编写执行 OCR 的 Python 代码,为您开发自己的 OCR 应用程序铺平道路。
要了解如何配置你的开发环境, 继续阅读。
学习目标
在本教程中,您将:
- 了解如何在您的计算机上安装 Tesseract OCR 引擎
- 了解如何创建 Python 虚拟环境(Python 开发中的最佳实践)
- 安装运行本教程中的示例所需的必要 Python 包(并开发您自己的 OCR 项目)
OCR 开发环境配置
在本教程的第一部分,您将学习如何在您的系统上安装 Tesseract OCR 引擎。从这里,您将学习如何创建一个 Python 虚拟环境,然后安装 OpenCV、PyTesseract 和 OCR、计算机视觉和深度学习所需的所有其他必要的 Python 库。
安装说明注释
宇宙魔方 OCR 引擎已经存在了 30 多年。Tesseract OCR 的安装说明相当稳定。因此,我已经包括了这些步骤。
也就是说,让我们在您的系统上安装 Tesseract OCR 引擎!
安装宇宙魔方
在本教程中,你将学习如何在你的机器上安装宇宙魔方。
在 macOS 上安装宇宙魔方
如果您使用家酿包管理器,在 macOS 上安装 Tesseract OCR 引擎相当简单。
如果您的系统上尚未安装 Homebrew,请使用上面的链接进行安装。
从那里,你需要做的就是使用brew命令来安装宇宙魔方:
$ brew install tesseract
如果上面的命令没有出现错误,那么您现在应该已经在 macOS 机器上安装了 Tesseract。
在 Ubuntu 上安装宇宙魔方
在 Ubuntu 18.04 上安装 Tesseract 很容易——我们需要做的就是利用apt-get:
$ sudo apt install tesseract-ocr
apt-get包管理器将自动安装宇宙魔方所需的任何必备库或包。
在 Windows 上安装宇宙魔方
请注意,PyImageSearch 团队和我并不正式支持 Windows,除了使用我们预配置的 Jupyter/Colab 笔记本的客户,这些客户可以在 PyImageSearch 大学找到。这些笔记本电脑可以在所有环境下运行,包括 macOS、Linux 和 Windows。
相反,我们建议使用基于 Unix 的机器,如 Linux/Ubuntu 或 macOS ,这两种机器都更适合开发计算机视觉、深度学习和 OCR 项目。
也就是说,如果你想在 Windows 上安装宇宙魔方,我们建议你遵循官方的 Windows 安装说明,这些说明是由宇宙魔方团队提供的。
验证您的宇宙魔方安装
假设您能够在您的操作系统上安装 Tesseract,您可以使用tesseract命令验证 Tesseract 是否已安装:
$ tesseract -v
tesseract 4.1.1
leptonica-1.79.0
libgif 5.2.1 : libjpeg 9d : libpng 1.6.37 : libtiff 4.1.0 : zlib 1.2.11 : libwebp 1.1.0 : libopenjp2 2.3.1
Found AVX2
Found AVX
Found FMA
Found SSE
您的输出应该与我的相似。
为 OCR 创建 Python 虚拟环境
Python 虚拟环境是 Python 开发的最佳实践,我们建议使用它们来获得更可靠的开发环境。
在我们的pip Install OpenCV教程中可以找到为 Python 虚拟环境安装必要的包,以及创建您的第一个 Python 虚拟环境。我们建议您按照该教程创建您的第一个 Python 虚拟环境。
*### 安装 OpenCV 和 PyTesseract】
既然您已经创建了 Python 虚拟环境并做好了准备,我们可以安装 OpenCV 和 PyTesseract,这是与 Tesseract OCR 引擎接口的 Python 包。
这两者都可以使用以下命令进行安装:
$ workon <name_of_your_env> # required if using virtual envs
$ pip install numpy opencv-contrib-python
$ pip install pytesseract
接下来,我们将安装 OCR、计算机视觉、深度学习和机器学习所需的其他 Python 包。
安装其他计算机视觉、深度学习和机器学习库
现在让我们安装一些其他支持计算机视觉和机器学习/深度学习的软件包,我们将在本教程的剩余部分中用到它们:
$ pip install pillow scipy
$ pip install scikit-learn scikit-image
$ pip install imutils matplotlib
$ pip install requests beautifulsoup4
$ pip install h5py tensorflow textblob
总结
在本教程中,您学习了如何在您的计算机上安装 Tesseract OCR 引擎。您还学习了如何安装执行 OCR、计算机视觉和图像处理所需的 Python 包。
现在您的开发环境已经配置好了,我们将在下一个教程中编写 OCR 代码!*
利用 OpenCV 进行实例分割
原文:https://pyimagesearch.com/2018/11/26/instance-segmentation-with-opencv/

在本教程中,您将学习如何使用 OpenCV、Python 和深度学习来执行实例分割。
早在 9 月份,我看到微软在他们的 Office 365 平台上发布了一个非常棒的功能——进行视频电话会议的能力,模糊背景,让你的同事只能看到你(而看不到你身后的任何东西)。
这篇文章顶部的 GIF 展示了一个类似的特性,这是我为了今天的教程而实现的。
无论你是在酒店房间接电话,还是在丑陋不堪的办公楼里工作,或者只是不想清理家庭办公室,电话会议模糊功能都可以让与会者专注于你(而不是背景中的混乱)。
对于在家工作并希望保护家庭成员隐私的人来说,这样的功能会特别有帮助(T2)。
想象一下,您的工作站可以清楚地看到您的厨房,您不会希望您的同事看到您的孩子吃晚饭或做作业吧!相反,只需打开模糊功能,一切就搞定了。
为了构建这样一个功能,微软利用了计算机视觉、深度学习,最值得注意的是, 实例分割。
我们在上周的博客文章中介绍了 Mask R-CNN 的实例分割,今天我们将采用我们的 Mask R-CNN 实现,并使用它来构建一个类似 Microsoft Office 365 的视频模糊功能。
要了解如何使用 OpenCV 执行实例分割,继续阅读!
利用 OpenCV 进行实例分割
https://www.youtube.com/embed/puSN8Dg-bdI?feature=oembed
用于对象检测的并集交集(IoU)
原文:https://pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
最后更新于 2022 年 4 月 30 日
目录
并集上的交集(IoU)用于评估对象检测的性能,方法是将基础真实边界框与预测边界框进行比较,IoU 是本教程的主题。
今天这篇博文的灵感来自我收到的一封电子邮件,来自罗切斯特大学的学生杰森。
Jason 有兴趣在他的最后一年项目中使用 HOG +线性 SVM 框架构建一个定制的物体检测器。他非常了解构建目标探测器所需的步骤— ,但他不确定一旦训练完成,如何评估他的探测器 的准确性。
他的教授提到他应该用 ***交集超过并集【IoU】***的方法来进行评估,但杰森不确定如何实施。
我通过电子邮件帮助 Jason 解决了问题:
- 描述什么是并集上的交集。
- 解释为什么我们使用并集上的交集来评估对象检测器。
- 向他提供一些来自我个人库的示例 Python 代码,以在边界框上执行交集并运算。
我的电子邮件真的帮助杰森完成了他最后一年的项目,我相信他会顺利通过。
考虑到这一点,我决定把我对 Jason 的回应变成一篇真正的博文,希望对你也有帮助。
要了解如何使用交集超过并集评估指标来评估您自己的自定义对象检测器,请继续阅读。
- 【2021 年 7 月更新:添加了关于 Union 实现的替代交集的部分,包括在训练深度神经网络对象检测器时可用作损失函数的 IoU 方法。
- **更新 2022 年 4 月:**增加了 TOC,并把帖子链接到一个新的交集 over Union 教程。
- 【2022 年 12 月更新:删除了数据集的链接,因为该数据集不再公开,并刷新了内容。
用于物体检测的并集上的交集
在这篇博文的剩余部分,我将解释什么是联合评估指标的交集,以及为什么我们使用它。
我还将提供 Union 上交集的 Python 实现,您可以在评估自己的自定义对象检测器时使用它。
最后,我们将查看将交集运算评估指标应用于一组地面实况和预测边界框的一些实际结果。
什么是交集大于并集?
并集上的交集是一种评估度量,用于测量特定数据集上的对象检测器的准确性。我们经常在物体检测挑战中看到这种评估指标,例如广受欢迎的 PASCAL VOC 挑战。
你通常会发现用于评估 HOG +线性 SVM 物体检测器和卷积神经网络检测器(R-CNN,fast R-CNN,YOLO 等)性能的交集。);然而,请记住,用于生成预测的实际算法并不重要。
并集上的交集仅仅是一个评估度量。任何提供预测边界框作为输出的算法都可以使用 IoU 进行评估。
更正式地说,为了将交集应用于并集来评估(任意)对象检测器,我们需要:
- 地面真实边界框(即来自测试集的手动标记边界框,其指定了我们的对象在图像中的位置*)。*
- 来自我们模型的预测边界框。
只要我们有这两组边界框,我们就可以在并集上应用交集。
下面,我提供了一个真实边界框与预测边界框的可视化示例:
在上图中,我们可以看到我们的对象检测器已经检测到图像中存在停车标志。
预测的包围盒以红色绘制,而地面真实(即手绘)包围盒以绿色绘制。
因此,计算并集上的交集可以通过以下方式确定:
检查这个等式,你可以看到交集除以并集仅仅是一个比率。
在分子中,我们计算在预测边界框和地面真实边界框之间的重叠区域的 。
分母是联合 的 区域,或者更简单地说,由和预测边界框和真实边界框包围的区域。**
将重叠面积除以并集面积,得到我们的最终分数— 并集上的交集。
你从哪里得到这些真实的例子?
在我们走得太远之前,您可能想知道地面真相的例子从何而来。我之前提到过这些图像是“手动标记的”,但这到底是什么意思呢?
你看,在训练自己的物体检测器(比如 HOG +线性 SVM 方法)的时候,你需要一个数据集。该数据集应(至少)分为两组:
- 一个训练集用于训练你的物体探测器。
- 一个测试装置,用于评估您的物体探测器。
您可能还有一个验证集,用于调整您的模型的超参数。
训练和测试集将包括:
- 真实的图像本身。
- 与图像中的对象相关联的边界框。边界框就是图像中物体的 (x,y)-坐标。
训练集和测试集的边界框由手工标注,因此我们称之为“地面真相”。
您的目标是获取训练图像+包围盒,构造一个对象检测器,然后在测试集上评估其性能。
超过联合分数 > 0.5 的交集通常被认为是“好的”预测。
为什么我们使用交集而不是并集?
如果你以前在职业生涯中执行过任何机器学习,特别是分类,你可能会习惯于预测类别标签,其中你的模型输出单个标签,要么是正确的要么是不正确的。
这种类型的二进制分类使得计算精度简单明了;然而,对于对象检测来说,这并不简单。
在所有现实中,极不可能我们预测的边界框的 (x,y)-坐标将会 精确地匹配*(x,y)*-地面真实边界框的坐标。
由于我们的模型的不同参数(图像金字塔比例、滑动窗口大小、特征提取方法等)。),预测边界框和真实边界框之间的完全和完全匹配是不现实的。
正因为如此,我们需要定义一个评估标准,让奖励预测的边界框与实际情况有很大的重叠:
在上图中,我已经包括了优、劣交集的例子。
如您所见,与地面实况边界框重叠严重的预测边界框比重叠较少的预测边界框得分更高。这使得交集/并集成为评估自定义对象检测器的优秀指标。
我们并不关心 (x,y)-坐标的精确匹配,但是我们确实想要确保我们预测的边界框尽可能地匹配——并集上的交集能够考虑到这一点。
在 Python 中实现 Union 上的交集
既然我们已经理解了什么是并上交集以及为什么我们使用它来评估对象检测模型,那么让我们继续用 Python 来实现它。
不过,在我们开始编写任何代码之前,我想提供我们将使用的五个示例图像:
这些图像是 CALTECH-101 数据集的一部分,用于图像分类和物体检测。
该数据集是公开可用的,但截至 2022 年 12 月,它不再公开。
在 PyImageSearch 大师课程 中,我演示了如何使用 HOG +线性 SVM 框架训练一个自定义对象检测器来检测图像中汽车的存在。
我从下面的自定义对象检测器中提供了真实边界框(绿色)和预测边界框(红色)的可视化效果:
给定这些边界框,我们的任务是定义联合上的交集度量,该度量可用于评估我们的预测有多“好(或坏)”。
也就是说,打开一个新文件,命名为intersection_over_union.py,让我们开始编码:
# import the necessary packages
from collections import namedtuple
import numpy as np
import cv2
# define the `Detection` object
Detection = namedtuple("Detection", ["image_path", "gt", "pred"])
我们从导入所需的 Python 包开始。然后我们定义一个Detection对象,它将存储三个属性:
image_path:驻留在磁盘上的输入图像的路径。gt:地面真实包围盒。- 从我们的模型预测的边界框。
正如我们将在这个例子的后面看到的,我已经从我们各自的五个图像中获得了预测的边界框,并将它们硬编码到这个脚本中,以保持这个例子的简短和简洁。
对于 HOG +线性 SVM 物体检测框架的完整回顾,请参考这篇博文。如果你有兴趣学习更多关于从头开始训练你自己的定制物体探测器的知识,一定要看看的 PyImageSearch 大师课程。
让我们继续定义bb_intersection_over_union函数,顾名思义,它负责计算两个边界框之间的交集:
def bb_intersection_over_union(boxA, boxB):
# determine the (x, y)-coordinates of the intersection rectangle
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
# compute the area of intersection rectangle
interArea = max(0, xB - xA + 1) * max(0, yB - yA + 1)
# compute the area of both the prediction and ground-truth
# rectangles
boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)
boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)
# compute the intersection over union by taking the intersection
# area and dividing it by the sum of prediction + ground-truth
# areas - the interesection area
iou = interArea / float(boxAArea + boxBArea - interArea)
# return the intersection over union value
return iou
这个方法需要两个参数:boxA和boxB,它们被假定为我们的地面实况和预测边界框(这些参数被提供给bb_intersection_over_union的实际顺序并不重要)。
第 11-14 行确定了 (x,y)-相交矩形的坐标,然后我们用它来计算相交的面积(第 17 行)。
现在,interArea变量代表交集并集计算中的分子。
为了计算分母,我们首先需要导出预测边界框和真实边界框的面积(行 21 和 22 )。
然后可以在第 27 行上通过将交集面积除以两个边界框的并集面积来计算交集,注意从分母中减去交集面积(否则交集面积将被加倍计算)。
最后,将 Union score 上的交集返回给第 30 行上的调用函数。
既然我们的联合交集方法已经完成,我们需要为我们的五个示例图像定义地面实况和预测边界框坐标:
# define the list of example detections
examples = [
Detection("image_0002.jpg", [39, 63, 203, 112], [54, 66, 198, 114]),
Detection("image_0016.jpg", [49, 75, 203, 125], [42, 78, 186, 126]),
Detection("image_0075.jpg", [31, 69, 201, 125], [18, 63, 235, 135]),
Detection("image_0090.jpg", [50, 72, 197, 121], [54, 72, 198, 120]),
Detection("image_0120.jpg", [35, 51, 196, 110], [36, 60, 180, 108])]
正如我上面提到的,为了保持这个例子简短,我从我的 HOG +线性 SVM 检测器中手动获得了预测的边界框坐标。这些预测的边界框(和相应的真实边界框)然后被硬编码到这个脚本中。
关于我如何训练这个精确物体探测器的更多信息,请参考 PyImageSearch 大师课程。
我们现在准备评估我们的预测:
# loop over the example detections
for detection in examples:
# load the image
image = cv2.imread(detection.image_path)
# draw the ground-truth bounding box along with the predicted
# bounding box
cv2.rectangle(image, tuple(detection.gt[:2]),
tuple(detection.gt[2:]), (0, 255, 0), 2)
cv2.rectangle(image, tuple(detection.pred[:2]),
tuple(detection.pred[2:]), (0, 0, 255), 2)
# compute the intersection over union and display it
iou = bb_intersection_over_union(detection.gt, detection.pred)
cv2.putText(image, "IoU: {:.4f}".format(iou), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
print("{}: {:.4f}".format(detection.image_path, iou))
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
在的第 41 行,我们开始循环遍历我们的每个examples(它们是Detection对象)。
对于它们中的每一个,我们在行 43 上从磁盘加载各自的image,然后绘制绿色的真实边界框(行 47 和 48 ),接着是红色的预测边界框(行 49 和 50 )。
通过传入地面实况和预测边界框,在行 53 上计算联合度量上的实际交集。
然后,我们在控制台后面的image上写交集并值。
最后,输出图像通过第 59 和 60 行显示在我们的屏幕上。
用并集上的交集将预测检测与实际情况进行比较
要查看联合度量的交集,请确保您已经使用本教程底部的 “下载” 部分下载了源代码+示例图片到这篇博客文章中。
解压缩归档文件后,执行以下命令:
$ python intersection_over_union.py
我们的第一个示例图像在联合分数上有一个交集 0.7980 ,表明两个边界框之间有明显的重叠:
下图也是如此,其交集超过联合分数 0.7899 :
请注意实际边界框(绿色)比预测边界框(红色)宽。这是因为我们的对象检测器是使用 HOG +线性 SVM 框架定义的,这要求我们指定固定大小的滑动窗口(更不用说图像金字塔比例和 HOG 参数本身)。
真实边界框自然会与预测的边界框具有稍微不同的纵横比,但是如果联合分数的交集是 > 0.5 也没关系——正如我们所看到的,这仍然是一个很好的预测。
下一个示例演示了一个稍微“不太好”的预测,其中我们的预测边界框比地面实况边界框“紧密”得多:
其原因是因为我们的 HOG +线性 SVM 检测器可能无法在图像金字塔的较低层“找到”汽车,而是在图像小得多的金字塔顶部附近发射。
以下示例是一个非常好的检测,交集超过联合分数 0.9472 :
请注意预测的边界框是如何与真实边界框几乎完美重叠的。
下面是计算并集交集的最后一个例子:
【Union 实现上的可选交集
本教程提供了 IoU 的 Python 和 NumPy 实现。但是,对于您的特定应用程序和项目,IoU 的其他实现可能更好。
例如,如果你正在使用 TensorFlow、Keras 或 PyTorch 等流行的库/框架训练深度学习模型,那么使用你的深度学习框架实现 IoU应该会提高算法的速度。
下面的列表提供了我建议的交集/并集的替代实现,包括在训练深度神经网络对象检测器时可以用作损失/度量函数的实现:
- TensorFlow 的 MeanIoU 函数,其计算对象检测结果样本的并集上的平均交集。
- TensorFlow 的 GIoULoss 损失度量,最早由 Rezatofighi 等人在 的《并集上的广义交集:包围盒回归的一个度量和一个损失 中引入,就像你训练一个神经网络使均方误差、交叉熵等最小化一样。这种方法充当插入替换损失函数,潜在地导致更高的对象检测精度。
- IoU 的 PyTorch 实现(我没有测试或使用过),但似乎对 PyTorch 社区有所帮助。
- 我们有一个很棒的使用 COCO 评估器的平均精度(mAP)教程,将带您了解如何使用交集/并集来评估 YOLO 性能。了解平均精度(mAP)的理论概念,并使用黄金标准 COCO 评估器评估 YOLOv4 检测器。
当然,您可以随时将我的 IoU Python/NumPy 实现转换成您自己的库、语言等。
黑客快乐!
总结
在这篇博文中,我讨论了用于评估对象检测器的 Union 上的交集度量。该指标可用于评估任何物体检测器,前提是(1)模型为图像中的物体生成预测的 (x,y)-坐标【即边界框】,以及(2)您拥有数据集的真实边界框。
通常,您会看到该指标用于评估 HOG +线性 SVM 和基于 CNN 的物体检测器。
要了解更多关于训练你自己的自定义对象检测器的信息,请参考这篇关于 HOG +线性 SVM 框架的博客文章,以及 PyImageSearch 大师课程 ,在那里我演示了如何从头开始实现自定义对象检测器。如果你想深入研究,可以考虑通过我们的免费课程学习计算机视觉。
最后,在你离开之前,请务必在下面的表格中输入你的电子邮件地址,以便在将来发布 PyImageSearch 博客文章时得到通知——你不会想错过它们的!
大卫·奥斯汀访谈:在 Kaggle 最受欢迎的图像分类比赛中获得第一名和 25,000 美元奖金

在今天的博文中,我采访了大卫·奥斯丁,他和他的队友王为民一起在卡格尔冰山分类挑战赛中获得了 第一名(以及 25,000 美元)。
David 和 Weimin 的获奖解决方案实际上可用于让船只在危险水域中更安全地航行,从而减少对船只和货物的损坏,最重要的是,减少事故、伤害和死亡。
根据 Kaggle 的说法,冰山图像分类挑战:
- 是他们遇到过的最受欢迎的图像分类挑战(以参赛队伍来衡量)
- 并且是的第七届最受欢迎的比赛(跨越所有挑战类型:图像、文本等。)
*比赛结束后不久,大卫给我发来了以下信息:
你好,阿德里安,我是一名 PyImageSearch 大师的成员,你所有书籍的消费者,将于 8 月参加 PyImageConf,并且总体上是一名欣赏你教学的学生。
我只是想与您分享一个成功的故事,因为我刚刚在挪威国家石油公司冰山分类器 Kaggle 竞赛中获得了 3,343 个团队中的第一名(25,000 美元第一名奖金)。
我的许多深度学习和简历知识都是通过您的培训获得的,我从您那里学到的一些具体技术也用在了我的获奖解决方案中(特别是阈值和迷你谷歌网络)。只想说声谢谢,让你知道你的影响很大。
谢谢!大卫
大卫的个人信息对我来说真的很重要,说实话,这让我有点激动。
作为一名教师和教育者,世界上没有比看到读者更好的感觉了:
- 从你的博客文章、书籍和课程中获取你所教授的东西的价值
- 用他们的知识丰富自己的生活,改善他人的生活
在今天的帖子中,我将采访大卫并讨论:
- 冰山图像分类的挑战是什么……为什么它很重要
- David 和 Weimin 在其获奖作品中使用的方法、算法和技术
- 挑战中最困难的方面是什么(以及他们是如何克服的)
- 他对任何想参加追逐赛的人的建议是
我非常为大卫和为民高兴——他们值得所有的祝贺和热烈的掌声。
和我一起接受采访,探索大卫和他的队友伟民是如何赢得 Kaggle 最受欢迎的图像分类比赛的。
大卫·奥斯汀访谈:在 Kaggle 最受欢迎的比赛中获得第一名和 25,000 美元

Figure 1: The goal of the Kaggle Iceberg Classifier challenge is to build an image classifier that classifies input regions of a satellite image as either “iceberg” or “ship” (source).
阿德里安:嗨,大卫!谢谢你同意接受这次采访。祝贺您在 Kaggle 冰山分类器更换中获得第一名,干得好!
大卫:谢谢阿德里安,很高兴与你交谈。
Adrian: 你最初是如何对计算机视觉和深度学习产生兴趣的?
大卫:在过去的两年里,我对深度学习的兴趣一直在稳步增长,因为我看到人们如何使用它来从他们处理的数据中获得令人难以置信的洞察力。我对深度学习的积极研究和实际应用都感兴趣,所以我发现参加 Kaggle 比赛是保持技能敏锐和尝试新技术的好地方。
Adrian: 你参赛前在计算机视觉和机器学习/深度学习方面的背景如何?你参加过以前的 Kaggle 比赛吗?
David: 我第一次接触机器学习可以追溯到大约 10 年前,当时我刚开始学习梯度增强树和随机森林,并将它们应用于分类类型问题。在过去的几年里,我开始更广泛地关注深度学习和计算机视觉。
不到一年前,我开始在业余时间参加 Kaggle 比赛,以此来提高我的技能,这是我的第三次图像分类比赛。

Figure 2: An example of how an iceberg looks. The goal of the Kaggle competition was to recognize such icebergs from satellite imagery (source).
阿德里安:你能告诉我更多关于冰山分类器挑战的事情吗?是什么激励你参加比赛?
当然,冰山分类挑战是一个二进制图像分类问题,参与者被要求对船只和通过卫星图像收集的冰山进行分类。在能源勘探领域,能够识别和避免漂流冰山等威胁尤为重要。
该数据集有几个有趣的方面,这使得它成为一个有趣的挑战。
首先,数据集相对较小,训练集中只有 1604 幅图像,因此从硬件角度来看,进入的障碍相当低,但使用有限的数据集的难度很高。
其次,在观看图像时,对人眼来说,许多图像看起来类似于电视屏幕上“下雪”的样子,只是一堆椒盐噪声,在视觉上根本看不清哪些图像是船只,哪些是冰山:

Figure 3: It’s extremely difficult for the human eye to accurately determine if an input region is an “iceberg” or a “ship” (source).
因此,事实上,人类很难准确预测分类,我认为这将是一个很好的测试,看看计算机视觉和深度学习能做什么。

Figure 4: David and Weimin winning solution involved using an ensemble of CNN architectures.
阿德里安:让我们来谈一点技术问题。你能告诉我们一些你在获奖作品中使用的方法、算法和技术吗?
大卫:嗯,总体方法与大多数典型的计算机视觉问题非常相似,因为我们花了相当多的时间预先理解数据。
我最喜欢的早期技术之一是使用无监督学习方法来识别数据中的自然模式,并使用该学习来确定采取什么样的深度学习方法。
在这种情况下,标准的 KNN 算法能够识别出帮助定义我们的模型架构的关键信号。从那时起,我们使用了一个非常广泛的 CNN 架构,它由 100 多个定制的 CNN 和 VGG 式架构组成,然后使用贪婪混合和两级堆叠以及其他图像功能来组合这些模型的结果。
这听起来可能是一个非常复杂的方法,但请记住,这里的目标函数是最小化对数损失误差,在这种情况下,我们只添加了模型,因为它们减少了对数损失而没有过度拟合,所以这是集合许多较弱学习者的力量的另一个很好的例子。
我们结束了第二次训练许多相同的 CNN,但只使用了我们在过程开始时从无监督学习中识别的数据子集,因为这也给了我们性能的改善。

Figure 5: The most difficult aspect of the Kaggle Iceberg challenge for David and his teammate was avoiding overfitting.
Adrian: 这次挑战对你来说最困难的方面是什么,为什么?
大卫:挑战中最困难的部分是确认我们没有过度适应。
图像分类问题的数据集规模相对较小,因此我们总是担心过度拟合可能是一个问题。出于这个原因,我们确保我们所有的模型都使用 4 重交叉验证,这增加了计算成本,但降低了过度拟合的风险。特别是当你处理像对数损失这样的无情损失函数时,你必须时刻警惕过度拟合。
阿德里安:训练你的模特花了多长时间?
David: 即使我们选择使用大量的 CNN,即使在整套模型上使用 4 重交叉验证,培训也只需要 1-2 天。没有交叉验证的单个模型在某些情况下可以训练几分钟。
阿德里安:如果让你选择你在比赛中运用的最重要的技术或技巧,你会选择什么?
David: 毫无疑问,最重要的一步是前期探索性分析,以便更好地理解数据集。
结果发现,除了图像数据之外,还有一个非常重要的信号,有助于消除数据中的大量噪声。
在我看来,任何 CV 或深度学习问题中最容易被忽视的步骤之一是理解数据并利用这些知识做出最佳设计选择所需的前期工作。
随着算法变得越来越容易获得和导入,经常会出现在没有真正理解这些算法是否适合工作,或者是否有工作应该在培训之前或之后完成以适当地处理数据的情况下,就匆忙地向问题“扔算法”的情况。

Figure 6: David used TensorFlow, Keras, and xgboost in the winning Kaggle submission.
阿德里安:你有哪些工具和库可供选择?
**大卫:**我个人认为 Tensorflow 和 Keras 是最有用的,所以当处理深度学习问题时,我倾向于坚持使用它们。
对于堆叠和提升,我使用 xgboost ,这也是因为熟悉和它的已证实的结果。
在这个比赛中我使用了我的dl4cv virtualenv(一个在 内部使用的 Python 虚拟环境,用 Python 进行计算机视觉的深度学习)并在其中加入了 xgboost。
阿德里安:你会给第一次想参加 Kaggle 比赛的人什么建议?
**David:**ka ggle 竞赛的一大优点是竞赛的社区性质。
有一个非常丰富的讨论论坛,如果参与者选择这样做,他们可以分享他们的代码。当你试图学习一般方法以及将代码应用于特定问题的方法时,这真的是非常宝贵的。
当我开始我的第一次比赛时,我花了几个小时阅读论坛和其他高质量的代码,发现这是最好的学习方法之一。
Adrian:PyImageSearch 大师课程和 用 Python 进行计算机视觉深度学习 的书是如何让你为 Kaggle 比赛做准备的?
与参加 Kaggle 竞赛非常相似,PyImageSearch Gurus 是一门边做边学的格式化课程。
对我来说,没有什么能像实际解决问题和遵循高质量的解决方案和代码一样让你为解决问题做好准备,我最欣赏 PyImageSearch 材料的一点是它通过生产级代码带你了解实际解决方案的方式。
我还认为,真正学习和理解深度学习架构的最佳方式之一是阅读一篇论文,然后尝试实现它。
这一策略在整个 ImageNet 捆绑包书中得到了实际实施,而且这一策略也可用于修改和调整架构,就像我们在本次竞赛中所做的那样。
我还从从业者捆绑包书中了解到了 MiniGoogleNet,这是我以前没有遇到过的,并且是在这次比赛中表现良好的一个模型。
Adrian: 你会向其他试图学习计算机视觉+深度学习的开发者、研究人员和学生推荐 PyImageSearch Gurus 或用 Python 进行计算机视觉的深度学习吗?
大卫:绝对是。我会向任何希望在 CV 和深度学习方面建立强大基础的人推荐它,因为你不仅要学习原理,还要学习如何使用最流行和最新的工具和软件将你的知识快速应用到现实世界的问题中。
阿德里安:接下来是什么?
大卫:嗯,我有一大堆项目要做,所以我会忙上一段时间。还有几个其他的 Kaggle 比赛,看起来真的很有趣,所以我也很有可能会参加这些比赛。
Adrian: 如果一个 PyImageSearch 的读者想聊天,和你联系的最佳地点是哪里?
大卫:联系我的最好方式是我的 LinkedIn 个人资料。你也可以在 LinkedIn 上与王为民联系。如果你想亲自聊天,我还将参加 8 月举行的 2018 年 PyImageConf。
你呢?你准备好追随大卫的脚步了吗?

你准备好开始你的计算机视觉+深度学习掌握之旅并跟随大卫·奥斯汀的脚步了吗?
David 是一名长期的 PyImageSearch 读者,他已经阅读了以下两种材料:
- PyImageSearch 大师课程 ,深入治疗计算机视觉和图像处理
- 计算机视觉深度学习用 Python ,当今最全面的计算机视觉+深度学习书籍
我不能保证你会像大卫一样赢得 Kaggle 比赛,但我可以保证这是当今掌握计算机视觉和深度学习的两个最佳资源。
引用亚马逊机器人公司高级系统工程师斯蒂芬·卡尔达拉的话:
我对您创建的[PyImageSearch Gurus]内容非常满意。我会很容易地将其评为大学“硕士项目”水平。更有条理。
和广受欢迎的《机器学习很有趣》一书的作者亚当·盖特基一起!博客系列:
我强烈推荐用 Python 抢一本《计算机视觉深度学习》。它涉及了很多细节,并有大量详细的例子。这是我迄今为止看到的唯一一本既涉及事物如何工作,又涉及如何在现实世界中实际使用它们来解决难题的书。看看吧!
试试 课程 和 书籍 吧——我会在你身边帮助你一步步走下去。
摘要
在今天的博文中,我采访了大卫·奥斯丁,他和他的队友王为民在卡格尔的冰山分类挑战赛中获得了第一名(以及 25000 美元)。
大卫和魏民的辛勤工作将有助于确保通过冰山易发水域的旅行更加安全,危险性更低。
我为大卫和伟民感到无比的高兴和骄傲。请和我一起,在这篇博文的评论区祝贺他们。*
OpenCV、计算机视觉和 scikit 异常检测简介-学习

在本教程中,您将学习如何使用 OpenCV、计算机视觉和 scikit-learn 机器学习库在图像数据集中执行异常/新奇检测。
想象一下,你刚从大学毕业,获得了计算机科学学位。你的研究重点是计算机视觉和机器学习。
你离开学校后的第一份工作是在美国国家公园部。
你的任务?
建立一个能够自动识别公园里的花卉品种的计算机视觉系统。这样的系统可以用来检测可能对公园整体生态系统有害的入侵植物物种。
你马上意识到计算机视觉可以用来识别花卉种类。
但首先你需要:
- 收集公园内各花卉品种的示例图像(即建立数据集)。
- 量化图像数据集,训练机器学习模型识别物种。
- **发现异常/异常植物物种,**通过这种方式,受过训练的植物学家可以检查植物,并确定它是否对公园的环境有害。
第 1 步和第 2 步相当简单,但是第 3 步就难多了。
你应该如何训练一个机器学习模型来自动检测给定的输入图像是否在公园植物外观的“正态分布”之外?
答案在于一类特殊的机器学习算法,包括异常值检测和新奇/异常检测。
在本教程的剩余部分,您将了解这些算法之间的区别,以及如何使用它们来发现您自己的影像数据集中的异常值和异常值。
要了解如何在图像数据集中执行异常/新奇检测,继续阅读!
OpenCV、计算机视觉和 scikit 异常检测简介-学习
在本教程的第一部分,我们将讨论自然发生的标准事件和异常事件之间的区别。
我们还将讨论为什么机器学习算法很难检测到这些类型的事件。
在这里,我们将回顾本教程的示例数据集。
然后,我将向您展示如何:
- 从磁盘加载我们的输入图像。
- 量化它们。
- 训练用于在我们的量化图像上进行异常检测的机器学习模型。
- 从那里,我们将能够检测新输入图像中的异常值/异常。
我们开始吧!
什么是异常值和异常值?为什么它们很难被发现?

Figure 1: Scikit-learn’s definition of an outlier is an important concept for anomaly detection with OpenCV and computer vision (image source).
异常被定义为偏离标准、很少发生、不遵循“模式”其余部分的事件。
异常情况的例子包括:
- 由世界事件引起的股票市场的大幅下跌和上涨
- 工厂里/传送带上的次品
- 实验室中被污染的样本
如果你想一个钟形曲线,异常存在于尾部的远端。
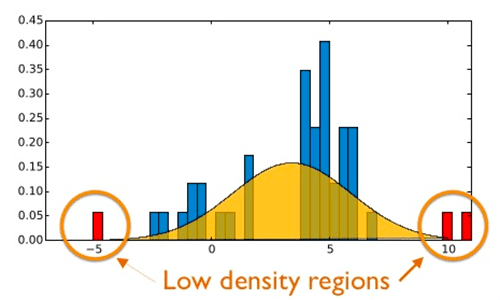
Figure 2: Anomalies exist at either side of a bell curve. In this tutorial we will conduct anomaly detection with OpenCV, computer vision, and scikit-learn (image source).
这些事件会发生,但发生的概率非常小。
从机器学习的角度来看,这使得检测异常变得困难——根据定义,我们有许多“标准”事件的例子,很少有“异常”事件的例子。
因此,我们的数据集中有一个大规模偏斜。
当我们想要检测的异常可能只发生 1%、0.1%或 0.0001%的时候,倾向于以最佳方式处理平衡数据集的机器学习算法应该如何工作?
幸运的是,机器学习研究人员已经研究了这种类型的问题,并设计了处理这项任务的算法。
异常检测算法
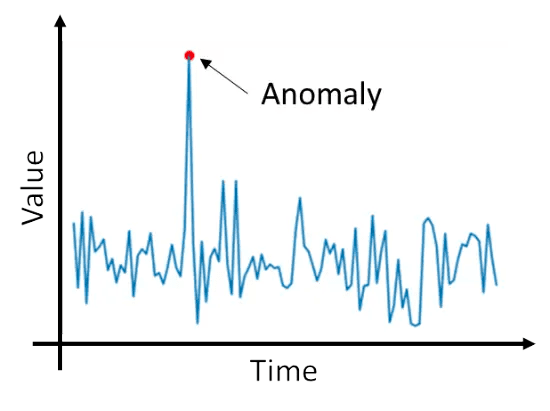
Figure 3: To detect anomalies in time-series data, be on the lookout for spikes as shown. We will use scikit-learn, computer vision, and OpenCV to detect anomalies in this tutorial (image source).
异常检测算法可以分为两个子类:
- 异常值检测:我们的输入数据集包含*标准事件和异常事件的例子。这些算法试图拟合标准事件最集中的训练数据区域,忽略并因此隔离异常事件。这种算法通常以无人监管的方式(即没有标签)进行训练。在应用其他机器学习技术之前,我们有时会使用这些方法来帮助清理和预处理数据集。*
** **新奇检测:**与包括标准和异常事件的例子的离群点检测不同,**新奇检测算法在训练时间内只有标准事件数据点(即没有异常事件)。*在训练过程中,我们为这些算法提供了标准事件的标记示例(监督学习)。在测试/预测时,新异检测算法必须检测输入数据点何时是异常值。
*离群点检测是无监督学习的一种形式。在这里,我们提供了示例数据点的整个数据集,并要求算法将它们分组为内点(标准数据点)和外点(异常)。
新奇检测是监督学习的一种形式,但我们只有标准数据点的标签——由新奇检测算法来预测给定数据点在测试时是内部还是外部。
在这篇博文的剩余部分,我们将重点关注作为异常检测形式的新奇检测。
用于异常检测的隔离林
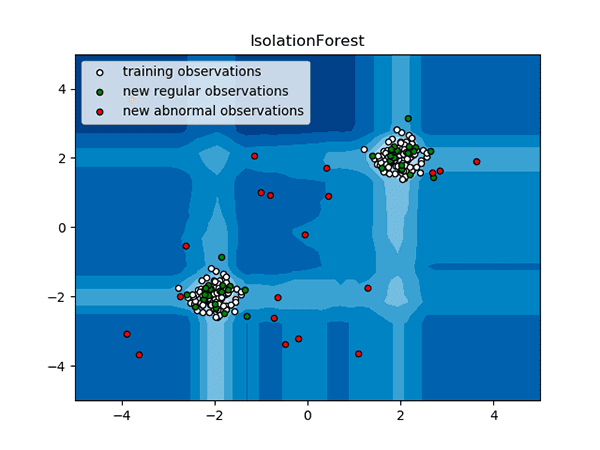
Figure 4: A technique called “Isolation Forests” based on Liu et al.’s 2012 paper is used to conduct anomaly detection with OpenCV, computer vision, and scikit-learn (image source).
我们将使用隔离森林来执行异常检测,基于刘等人 2012 年的论文,基于隔离的异常检测。
隔离林是一种集成算法,由多个决策树组成,用于将输入数据集划分为不同的内联体组。
正如上面的图 4 所示,隔离森林接受一个输入数据集(白点,然后围绕它们建立一个流形。
在测试时,隔离林可以确定输入点是否落在流形内(标准事件;绿点或高密度区域外(异常事件;红点。
回顾隔离林如何构建分区树的集合超出了本文的范围,因此请务必参考刘等人的论文以了解更多细节。
配置您的异常检测开发环境
为了跟随今天的教程,你需要一个安装了以下软件包的 Python 3 虚拟环境 :
幸运的是,这些包都是 pip 可安装的,但是有一些先决条件(包括 Python 虚拟环境)。请务必遵循以下指南,首先使用 OpenCV 设置您的虚拟环境: pip 安装 opencv
一旦 Python 3 虚拟环境准备就绪,pip 安装命令包括:
$ workon <env-name>
$ pip install numpy
$ pip install opencv-contrib-python
$ pip install imutils
$ pip install scikit-learn
***注意:*根据 pip install opencv 安装指南安装virtualenv和virtualenvwrapper后,workon命令变为可用。
项目结构
确保使用教程的 “下载” 部分获取今天帖子的源代码和示例图片。在您将。您将看到以下项目结构:
$ tree --dirsfirst
.
├── examples
│ ├── coast_osun52.jpg
│ ├── forest_cdmc290.jpg
│ └── highway_a836030.jpg
├── forest
│ ├── forest_bost100.jpg
│ ├── forest_bost101.jpg
│ ├── forest_bost102.jpg
│ ├── forest_bost103.jpg
│ ├── forest_bost98.jpg
│ ├── forest_cdmc458.jpg
│ ├── forest_for119.jpg
│ ├── forest_for121.jpg
│ ├── forest_for127.jpg
│ ├── forest_for130.jpg
│ ├── forest_for136.jpg
│ ├── forest_for137.jpg
│ ├── forest_for142.jpg
│ ├── forest_for143.jpg
│ ├── forest_for146.jpg
│ └── forest_for157.jpg
├── pyimagesearch
│ ├── __init__.py
│ └── features.py
├── anomaly_detector.model
├── test_anomaly_detector.py
└── train_anomaly_detector.py
3 directories, 24 files
我们的项目由forest/图像和example/测试图像组成。我们的异常探测器将尝试确定这三个例子中的任何一个与这组森林图像相比是否是异常。
在pyimagesearch模块中有一个名为features.py的文件。这个脚本包含两个函数,负责从磁盘加载我们的图像数据集,并计算每个图像的颜色直方图特征。
我们将分两个阶段运行我们的系统— (1)培训,和(2)测试。
首先,train_anomaly_detector.py脚本计算特征并训练用于异常检测的隔离森林机器学习模型,将结果序列化为anomaly_detector.model。
然后我们将开发test_anomaly_detector.py,它接受一个示例图像并确定它是否是一个异常。
我们的示例图像数据集

Figure 5: We will use a subset of the 8Scenes dataset to detect anomalies among pictures of forests using scikit-learn, OpenCV, and computer vision.
本教程的示例数据集包括 16 幅森林图像(每一幅都显示在上面的 图 5 中)。
这些示例图像是 Oliva 和 Torralba 的论文 中的 8 个场景数据集的子集,该论文对场景的形状进行建模:空间包络 的整体表示。
我们将获取这个数据集,并在此基础上训练一个异常检测算法。
当呈现新的输入图像时,我们的异常检测算法将返回两个值之一:
- 是的,那是一片森林
-1: “不,看起来不像森林。肯定是离群值。”
因此,您可以将该模型视为“森林”与“非森林”检测器。
该模型是在森林图像上训练的,现在必须决定新的输入图像是否符合“森林流形”或者是否确实是异常/异常值。
为了评估我们的异常检测算法,我们有 3 个测试图像:

Figure 6: Three testing images are included in today’s Python + computer vision anomaly detection project.
正如你所看到的,这些图像中只有一个是森林,另外两个分别是高速公路和海滩的例子。
如果我们的异常检测管道工作正常,我们的模型应该为森林图像返回1 (inlier),为两个非森林图像返回-1。
实现我们的特征提取和数据集加载器辅助函数
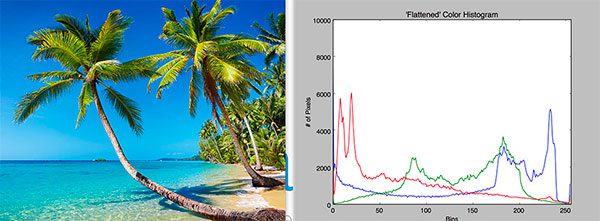
Figure 7: Color histograms characterize the color distribution of an image. Color will be the basis of our anomaly detection introduction using OpenCV, computer vision, and scikit-learn.
在我们可以训练机器学习模型来检测异常和异常值之前,我们必须首先定义一个过程来量化和表征我们输入图像的内容。
为了完成这项任务,我们将使用颜色直方图。
颜色直方图是表征图像颜色分布的简单而有效的方法。
由于我们在这里的任务是描述森林和非森林图像的特征,我们可以假设森林图像比非森林图像包含更多的绿色阴影。
让我们看看如何使用 OpenCV 实现颜色直方图提取。
打开pyimagesearch模块中的features.py文件,插入以下代码:
# import the necessary packages
from imutils import paths
import numpy as np
import cv2
def quantify_image(image, bins=(4, 6, 3)):
# compute a 3D color histogram over the image and normalize it
hist = cv2.calcHist([image], [0, 1, 2], None, bins,
[0, 180, 0, 256, 0, 256])
hist = cv2.normalize(hist, hist).flatten()
# return the histogram
return hist
2-4 线导入我们的套餐。我们将使用我的imutils包中的paths来列出输入目录中的所有图像。OpenCV 将用于计算和归一化直方图。NumPy 用于数组操作。
既然导入已经处理好了,让我们定义一下quantify_image函数。该函数接受两个参数:
image:OpenCV 加载的图像。bins:绘制直方图时,x-轴充当我们的“仓”在这种情况下,我们的default指定了4色调箱、6饱和度箱和3值箱。这里有一个简单的例子——如果我们只使用 2 个(等间距)面元,那么我们将计算一个像素在范围*【0,128】或【128,255】*内的次数。然后在 y 轴上绘制合并到 x 轴值的像素数。
注:**要了解包括 HSV、RGB、Lab 和灰度在内的直方图和色彩空间的更多信息,请务必参考实用 Python 和 OpenCV 和 PyImageSearch 大师。
第 8-10 行计算颜色直方图并归一化。归一化允许我们计算百分比,而不是原始频率计数,在一些图像比其他图像大或小的情况下有所帮助。
第 13 行将归一化直方图返回给调用者。
我们的下一个函数处理:
- 接受包含图像数据集的目录的路径。
- 在图像路径上循环,同时使用我们的
quantify_image方法量化它们。
现在让我们来看看这个方法:
def load_dataset(datasetPath, bins):
# grab the paths to all images in our dataset directory, then
# initialize our lists of images
imagePaths = list(paths.list_images(datasetPath))
data = []
# loop over the image paths
for imagePath in imagePaths:
# load the image and convert it to the HSV color space
image = cv2.imread(imagePath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# quantify the image and update the data list
features = quantify_image(image, bins)
data.append(features)
# return our data list as a NumPy array
return np.array(data)
我们的load_dataset函数接受两个参数:
- 到我们的图像数据集的路径。
bins:颜色直方图的箱数。参考上面的解释。容器被传递给quantify_image功能。
第 18 行抓取datasetPath中的所有图像路径。
第 19 行初始化一个列表来保存我们的特性data。
从那里,线 22 开始在imagePaths上循环。在循环中,我们加载一幅图像,并将其转换到 HSV 颜色空间(第 24 行和第 25 行)。然后我们量化image,并将结果features添加到data列表中(第 28 行和第 29 行)。
最后, Line 32 将我们的data列表作为 NumPy 数组返回给调用者。
使用 scikit-learn 实施我们的异常检测培训脚本
实现了助手函数后,我们现在可以继续训练异常检测模型。
正如本教程前面提到的,我们将使用隔离森林来帮助确定异常/新奇数据点。
打开train_anomaly_detector.py文件,让我们开始工作:
# import the necessary packages
from pyimagesearch.features import load_dataset
from sklearn.ensemble import IsolationForest
import argparse
import pickle
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to dataset of images")
ap.add_argument("-m", "--model", required=True,
help="path to output anomaly detection model")
args = vars(ap.parse_args())
2-6 号线处理我们的进口。这个脚本使用了我们定制的load_dataset函数和 scikit-learn 的隔离森林实现。我们将把生成的模型序列化为 pickle 文件。
第 8-13 行解析我们的命令行参数包括:
- 到我们的图像数据集的路径。
--model:输出异常检测模型的路径。
此时,我们已经准备好加载数据集并训练我们的隔离森林模型:
# load and quantify our image dataset
print("[INFO] preparing dataset...")
data = load_dataset(args["dataset"], bins=(3, 3, 3))
# train the anomaly detection model
print("[INFO] fitting anomaly detection model...")
model = IsolationForest(n_estimators=100, contamination=0.01,
random_state=42)
model.fit(data)
第 17 行加载并量化图像数据集。
第 21 行和第 22 行用以下参数初始化我们的IsolationForest模型:
n_estimators:集合中基本估计量(即树)的数量。contamination:数据集中离群点的比例。random_state:再现性的随机数发生器种子值。可以使用任意整数;42常用于机器学习领域,因为它与书中的一个笑话、银河系漫游指南T5 有关。
确保参考 scikit-learn 文档中隔离林的其他可选参数。
第 23 行在直方图data顶部训练异常检测器。
既然我们的模型已经定型,剩下的几行将异常检测器序列化到磁盘上的 pickle 文件中:
# serialize the anomaly detection model to disk
f = open(args["model"], "wb")
f.write(pickle.dumps(model))
f.close()
训练我们的异常探测器
既然我们已经实现了我们的异常检测训练脚本,让我们把它投入工作。
首先确保您已经使用了本教程的 【下载】 部分来下载源代码和示例图像。
从那里,打开一个终端并执行以下命令:
$ python train_anomaly_detector.py --dataset forest --model anomaly_detector.model
[INFO] preparing dataset...
[INFO] fitting anomaly detection model...
要验证异常检测器是否已序列化到磁盘,请检查工作项目目录的内容:
$ ls *.model
anomaly_detector.model
创建异常检测器测试脚本
在这一点上,我们已经训练了我们的异常检测模型— ,但是我们如何使用实际的来检测新数据点中的异常?
要回答这个问题,让我们看看test_anomaly_detector.py脚本。
在高层次上,这个脚本:
- 加载上一步训练的异常检测模型。
- 加载、预处理和量化查询图像。
- 使用我们的异常检测器进行预测,以确定查询图像是内部图像还是外部图像(即异常)。
- 显示结果。
继续打开test_anomaly_detector.py并插入以下代码:
# import the necessary packages
from pyimagesearch.features import quantify_image
import argparse
import pickle
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained anomaly detection model")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
2-5 号线办理我们的进口业务。注意,我们导入自定义的quantify_image函数来计算输入图像的特征。我们还导入pickle来加载我们的异常检测模型。OpenCV 将用于加载、预处理和显示图像。
我们的脚本需要两个命令行参数:
--model:驻留在磁盘上的序列化异常检测器。--image:输入图像的路径(即我们的查询)。
让我们加载我们的异常检测器并量化我们的输入图像:
# load the anomaly detection model
print("[INFO] loading anomaly detection model...")
model = pickle.loads(open(args["model"], "rb").read())
# load the input image, convert it to the HSV color space, and
# quantify the image in the *same manner* as we did during training
image = cv2.imread(args["image"])
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
features = quantify_image(hsv, bins=(3, 3, 3))
17 号线装载我们预先训练的异常探测器。
第 21-23 行加载、预处理和量化我们的输入image。我们的预处理步骤必须与我们的训练脚本相同(即从 BGR 转换到 HSV 色彩空间)。
此时,我们准备好进行异常预测并显示结果:
# use the anomaly detector model and extracted features to determine
# if the example image is an anomaly or not
preds = model.predict([features])[0]
label = "anomaly" if preds == -1 else "normal"
color = (0, 0, 255) if preds == -1 else (0, 255, 0)
# draw the predicted label text on the original image
cv2.putText(image, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, color, 2)
# display the image
cv2.imshow("Output", image)
cv2.waitKey(0)
第 27 行对输入图像features进行预测。我们的异常检测模型将为“正常”数据点返回1,为“异常”数据点返回-1。
第 28 行给我们的预测分配一个"anomaly"或"normal"标签。
第 32-37 行然后在查询图像上标注label并显示在屏幕上,直到按下任何键。
使用计算机视觉和 scikit-learn 检测图像数据集中的异常
要查看我们的异常检测模型,请确保您已使用本教程的 【下载】 部分下载源代码、示例图像数据集和预训练模型。
在那里,您可以使用以下命令来测试异常检测器:
$ python test_anomaly_detector.py --model anomaly_detector.model \
--image examples/forest_cdmc290.jpg
[INFO] loading anomaly detection model...

Figure 8: This image is clearly not an anomaly as it is a green forest. Our intro to anomaly detection method with computer vision and Python has passed the first test.
这里你可以看到我们的异常检测器已经正确地将森林标记为内层。
现在让我们来看看这个模型如何处理一幅公路的图像,它当然不是森林:
$ python test_anomaly_detector.py --model anomaly_detector.model \
--image examples/highway_a836030.jpg
[INFO] loading anomaly detection model...

Figure 9: A highway is an anomaly compared to our set of forest images and has been marked as such in the top-left corner. This tutorial presents an intro to anomaly detection with OpenCV, computer vision, and scikit-learn.
我们的异常检测器正确地将该图像标记为异常值/异常值。
作为最后的测试,让我们向异常探测器提供一个海滩/海岸的图像:
$ python test_anomaly_detector.py --model anomaly_detector.model \
--image examples/coast_osun52.jpg
[INFO] loading anomaly detection model...
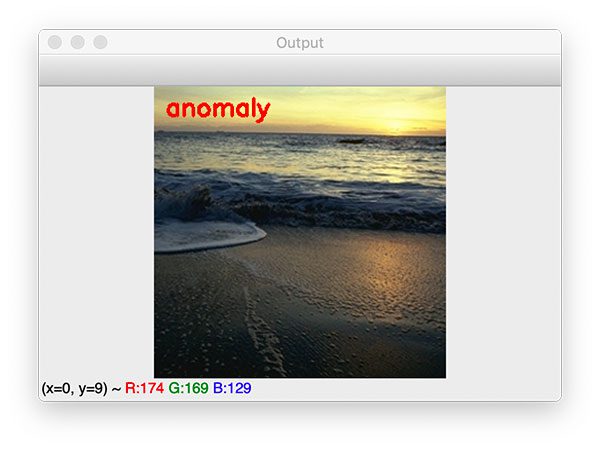
Figure 10: A coastal landscape is marked as an anomaly against a set of forest images using Python, OpenCV, scikit-learn, and computer vision anomaly detection techniques.
我们的异常检测器再次正确地将图像识别为异常值/异常。
摘要
在本教程中,您学习了如何使用计算机视觉和 scikit-learn 机器学习库在图像数据集中执行异常和异常值检测。
为了执行异常检测,我们:
- 收集了森林图像的示例图像数据集。
- 使用颜色直方图和 OpenCV 库量化图像数据集。
- 根据我们的量化图像训练了一个隔离森林。
- 使用隔离林检测图像异常值和异常。
除了隔离森林,您还应该研究单类支持向量机、椭圆包络和局部异常因子算法,因为它们也可以用于异常值/异常检测。
但是深度学习呢?
深度学习也可以用来执行异常检测吗?
我将在以后的教程中回答这个问题。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*
生成对抗网络简介
原文:https://pyimagesearch.com/2021/09/13/intro-to-generative-adversarial-networks-gans/
这篇文章涵盖了高层次的生成对抗网络(GAN)的直觉,各种 GAN 变体,以及解决现实世界问题的应用。
这是 GAN 教程系列的第一篇文章:
- 生成对抗网络(GANs)简介(本帖)
- 入门:DCGAN for Fashion-MNIST
- GAN 训练挑战:针对彩色图像的 DCGAN
【GANs 如何工作
GANs 是一种生成模型,它观察许多样本分布,生成更多相同分布的样本。其他生成模型包括变分自动编码器()和自回归模型。
氮化镓架构
在基本的 GAN 架构中有两个网络:发生器模型和鉴别器模型。GANs 得名于单词**“对抗性的”**,因为这两个网络同时接受训练并相互竞争,就像在国际象棋这样的零和游戏中一样。
生成器模型生成新图像。生成器的目标是生成看起来如此真实的图像,以至于骗过鉴别器。在用于图像合成的最简单 GAN 架构中,输入通常是随机噪声,输出是生成的图像。
鉴别器只是一个你应该已经熟悉的二值图像分类器。它的工作是分类一幅图像是真是假。
注: 在更复杂的 GANs 中,我们可以用图像或文本作为鉴别器的条件,用于图像到图像的翻译或文本到图像的生成。
将所有这些放在一起,下面是一个基本的 GAN 架构的样子:生成器生成假图像;我们将真实图像(训练数据集)和伪图像分批次输入鉴别器。鉴别器然后判断一幅图像是真的还是假的。
训练甘斯
极大极小游戏:G 对 D
大多数深度学习模型(例如,图像分类)都基于优化:找到成本函数的低值。gan 是不同的,因为两个网络:生成器和鉴别器,每个都有自己的成本和相反的目标:
- 生成器试图欺骗鉴别者,让他们认为假图像是真的
- 鉴别器试图正确地分类真实和伪造的图像
下面的最小最大游戏数学函数说明了训练中的这种对抗性动态。如果你不理解数学,不要太担心,我会在未来的 DCGAN 帖子中对 G 损失和 D 损失进行编码时进行更详细的解释。
发生器和鉴别器在训练期间都随着时间而改进。生成器在产生类似训练数据的图像方面变得越来越好,而鉴别器在区分真假图像方面变得越来越好。
训练 GANs 是为了在游戏中找到一个平衡当:
- 生成器生成的数据看起来几乎与训练数据相同。
- 鉴别器不再能够区分伪图像和真实图像。
艺术家与批评家
模仿杰作是学习艺术的一个好方法——“艺术家如何在世界知名的博物馆里临摹杰作”作为一个模仿杰作的人类艺术家,我会找到我喜欢的艺术品作为灵感,并尽可能多地复制它:轮廓、颜色、构图和笔触,等等。然后一位评论家看了看复制品,告诉我它是否像真正的杰作。
GANs 培训与此过程类似。我们可以把生成者想象成艺术家,把鉴别者想象成批评家。请注意人类艺术家和机器(GANs)艺术家之间的类比差异:生成器无法访问或看到它试图复制的杰作。相反,它只依靠鉴别器的反馈来改善它生成的图像。
评估指标
好的 GAN 模型应该具有好的图像质量**——例如,不模糊并且类似于训练图像;以及多样性:生成了各种各样的图像,这些图像近似于训练数据集的分布。**
**要评估 GAN 模型,您可以在训练期间直观地检查生成的图像,或者通过生成器模型进行推断。如果您想对您的 GANs 进行定量评估,这里有两个流行的评估指标:
- **Inception Score,**捕获生成图像的 质量 和 多样性
- 弗雷歇初始距离比较真实图像和虚假图像,而不仅仅是孤立地评估生成的图像
GAN 变体
自 Ian Goodfellow 等人在 2014 年发表最初的 GANs 论文以来,出现了许多 GAN 变体。它们倾向于相互建立,要么解决特定的培训问题,要么创建新的 GANs 架构,以便更好地控制 GANs 或获得更好的图像。
以下是一些具有突破性的变体,为未来 GAN 的发展奠定了基础。这绝不是所有 GAN 变体的完整列表。
DCGAN (深度卷积生成对抗网络的无监督表示学习)是第一个在其网络架构中使用卷积神经网络(CNN)的 GAN 提案。今天的大多数 GAN 变体多少都是基于 DCGAN 的。因此,DCGAN 很可能是你的第一个 GAN 教程,学习 GAN 的“Hello-World”。
WGAN(wasser stein GAN)和 WGAN-GP (被创建来解决 GAN 训练挑战,例如模式崩溃——当生成器重复产生相同的图像或(训练图像的)一个小的子集。WGAN-GP 通过使用梯度惩罚而不是训练稳定性的权重削减来改进 WGAN。
cGAN (条件生成对抗网)首先引入了基于条件生成图像的概念,条件可以是图像类标签、图像或文本,如在更复杂的 GANs 中。 Pix2Pix 和 CycleGAN 都是条件 GAN,使用图像作为图像到图像转换的条件。
pix 2 pixhd利用条件 GANs 进行高分辨率图像合成和语义操纵】理清多种输入条件的影响,如论文示例中所述:为服装设计控制生成的服装图像的颜色、纹理和形状。此外,它还可以生成逼真的 2k 高分辨率图像。
****萨根 (自我注意生成对抗网络)提高图像合成质量:通过将自我注意模块(来自 NLP 模型的概念)应用于 CNN,使用来自所有特征位置的线索生成细节。谷歌 DeepMind 扩大了 SAGAN 的规模,以制造 BigGAN。
BigGAN (高保真自然图像合成的大规模 GAN 训练)可以创建高分辨率和高保真的图像。
ProGAN、StyleGAN 和 StyleGAN2 都能创建高分辨率图像。
ProGAN (为提高质量、稳定性和变化性而进行的 GANs 渐进增长)使网络渐进增长。
NVIDIA Research 推出的 StyleGAN (一种基于风格的生成式对抗网络生成器架构),使用带有自适应实例规范化(AdaIN)的 ProGAN plus 图像风格转移,能够控制生成图像的风格。
【StyleGAN 2】(StyleGAN 的图像质量分析与改进)在原始 StyleGAN 的基础上,在归一化、渐进生长和正则化技术等方面进行了多项改进。
氮化镓应用
gan 用途广泛,可用于多种应用。
图像合成
图像合成可能很有趣,并提供实际用途,如机器学习(ML)培训中的图像增强或帮助创建艺术品和设计资产。
GANs 可以用来创造在之前从未存在过的图像**,这也许是 GANs 最出名的地方。他们可以创造看不见的新面孔,猫的形象和艺术品,等等。我在下面附上了几张高保真图片,它们是我从 StyleGAN2 支持的网站上生成的。去这些链接,自己实验,看看你从实验中得到了什么图像。**
Zalando Research 使用 GANs 生成基于颜色、形状和纹理的时装设计(解开 GANs 中的多个条件输入)。
脸书研究公司的 Fashion++超越了创造时尚的范畴,提出了改变时尚的建议:“什么是时尚?”
GANs 还可以帮助训练强化剂。比如英伟达的 GameGAN 模拟游戏环境。
图像到图像的翻译
图像到图像转换是一项计算机视觉任务,它将输入图像转换到另一个领域(例如,颜色或风格),同时保留原始图像内容。这也许是在艺术和设计中使用 GANs 的最重要的任务之一。
Pix2Pix (使用条件对抗网络的图像到图像翻译)是一个条件 GAN,它可能是最著名的图像到图像翻译 GAN。然而,Pix2Pix 的一个主要缺点是它需要成对的训练图像数据集。
CycleGAN 基于 Pix2Pix 构建,只需要不成对的图像,在现实世界中更容易获得。它可以把苹果的图像转换成橘子,把白天转换成黑夜,把马转换成斑马……好的。这些可能不是真实世界的用例;从那时起,艺术和设计领域出现了许多其他的图像到图像的 GANs。
现在你可以把自己的自拍翻译成漫画、绘画、漫画,或者任何你能想象到的其他风格。例如,我可以使用白盒卡通将我的自拍变成卡通版本:
彩色化不仅可以应用于黑白照片,还可以应用于艺术作品或设计资产。在艺术品制作或 UI/UX 设计过程中,我们从轮廓开始,然后着色。自动上色有助于为艺术家和设计师提供灵感。
文本到图像
我们已经看到了 GANs 的很多图像到图像的翻译例子。我们还可以使用单词作为条件来生成图像,这比使用类别标签作为条件要灵活和直观得多。
近年来,自然语言处理和计算机视觉的结合已经成为一个热门的研究领域。这里有几个例子: StyleCLIP 和驯服高分辨率图像合成的变形金刚。
超越影像
GANs 不仅可以用于图像,还可以用于音乐和视频。比如 Magenta 项目的 GANSynth 会做音乐。这里有一个有趣的视频动作转移的例子,叫做“现在每个人都跳舞”( YouTube | Paper )。我一直喜欢看这个迷人的视频,专业舞者的舞步被转移到业余舞者身上。
https://www.youtube.com/embed/PCBTZh41Ris?feature=oembed******
PyTorch 简介:使用 PyTorch 训练您的第一个神经网络
在本教程中,您将学习如何使用 PyTorch 深度学习库来训练您的第一个神经网络。
本教程是 PyTorch 深度学习基础知识五部分系列的第二部分:
- py torch 是什么?
- PyTorch 简介:使用 PyTorch 训练你的第一个神经网络(今天的教程)
- PyTorch:训练你的第一个卷积神经网络(下周教程)
- 使用预训练网络的 PyTorch 图像分类
- 使用预训练网络的 PyTorch 对象检测
本指南结束时,您将学会:
- 如何用 PyTorch 定义一个基本的神经网络架构
- 如何定义你的损失函数和优化器
- 如何正确地调零你的梯度,执行反向传播,并更新你的模型参数 —大多数刚接触 PyTorch 的深度学习实践者都会在这一步犯错误
要学习如何用 PyTorch 训练你的第一个神经网络, 继续阅读。
PyTorch 简介:使用 py torch 训练你的第一个神经网络
在本指南中,您将熟悉 PyTorch 中的常见程序,包括:
- 定义您的神经网络架构
- 初始化优化器和损失函数
- 循环你的训练次数
- 在每个时期内循环数据批次
- 对当前一批数据进行预测和计算损失
- 归零你的梯度
- 执行反向传播
- 告诉优化器更新网络的梯度
- 告诉 PyTorch 用 GPU 训练你的网络(当然,如果你的机器上有 GPU 的话)
我们将首先回顾我们的项目目录结构,然后配置我们的开发环境。
从这里,我们将实现两个 Python 脚本:
- 第一个脚本将是我们简单的前馈神经网络架构,用 Python 和 PyTorch 库实现
- 然后,第二个脚本将加载我们的示例数据集,并演示如何训练我们刚刚使用 PyTorch 实现的网络架构
随着我们的两个 Python 脚本的实现,我们将继续训练我们的网络。我们将讨论我们的结果来结束本教程。
我们开始吧!
配置您的开发环境
要遵循本指南,您需要在系统上安装 PyTorch 深度学习库和 scikit-machine 学习包。
幸运的是,PyTorch 和 scikit-learn 都非常容易使用 pip 安装:
$ pip install torch torchvision
$ pip install scikit-image
如果您需要帮助配置 PyTorch 的开发环境,我强烈推荐您 阅读 PyTorch 文档——py torch 的文档非常全面,可以让您快速上手并运行。
**### 在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码***?***
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 **,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!**无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
要跟随本教程,请务必访问本指南的 “下载” 部分以检索源代码。
然后,您将看到下面的目录结构。
$ tree . --dirsfirst
.
├── pyimagesearch
│ └── mlp.py
└── train.py
1 directory, 2 files
文件将存储我们的基本多层感知器(MLP)的实现。
然后我们将实现train.py,它将用于在一个示例数据集上训练我们的 MLP。
用 PyTorch 实现我们的神经网络
您现在已经准备好用 PyTorch 实现您的第一个神经网络了!
这个网络是一个非常简单的前馈神经网络,称为多层感知器(MLP) (意味着它有一个或多个隐藏层)。在下周的教程中,您将学习如何构建更高级的神经网络架构。
要开始构建我们的 PyTorch 神经网络,打开项目目录结构的pyimagesearch模块中的mlp.py文件,让我们开始工作:
# import the necessary packages
from collections import OrderedDict
import torch.nn as nn
def get_training_model(inFeatures=4, hiddenDim=8, nbClasses=3):
# construct a shallow, sequential neural network
mlpModel = nn.Sequential(OrderedDict([
("hidden_layer_1", nn.Linear(inFeatures, hiddenDim)),
("activation_1", nn.ReLU()),
("output_layer", nn.Linear(hiddenDim, nbClasses))
]))
# return the sequential model
return mlpModel
第 2 行和第 3 行导入我们需要的 Python 包:
OrderedDict:一个字典对象,记住对象被添加的顺序——我们使用这个有序字典为网络中的每一层提供人类可读的名称- PyTorch 的神经网络实现
然后我们定义了接受三个参数的get_training_model函数( Line 5 ):
- 神经网络的输入节点数
- 网络隐藏层中的节点数
- 输出节点的数量(即输出预测的维度)
根据提供的默认值,您可以看到我们正在构建一个 4-8-3 神经网络,这意味着输入层有 4 个节点,隐藏层有 8 个节点,神经网络的输出将由 3 个值组成。
然后,通过首先初始化一个nn.Sequential对象(非常类似于 Keras/TensorFlow 的Sequential类),在第 7-11 行上构建实际的神经网络架构。
在Sequential类中,我们构建了一个OrderedDict,其中字典中的每个条目都包含两个值:
- 一个包含人类可读的层名称的字符串(当使用 PyTorch 调试神经网络架构时,这个名称非常有用)
- PyTorch 层定义本身
Linear类是我们的全连接层定义,这意味着该层中的每个输入连接到每个输出。Linear类接受两个必需的参数:
- 层的输入的数量
- 输出的数量
在线 8 上,我们定义了hidden_layer_1,它由一个接受inFeatures (4)输入然后产生hiddenDim (8)输出的全连接层组成。
从那里,我们应用一个 ReLU 激活函数(第 9 行),接着是另一个Linear层,作为我们的输出(第 10 行)。
**注意,第二个Linear定义包含与之前的 Linear层输出相同的*数量的输入——这不是偶然的!*前一层的输出尺寸必须匹配下一层的输入尺寸,否则 PyTorch 将出错(然后您将有一个相当繁琐的任务,自己调试层尺寸)。
PyTorch 在这方面没有宽容(相对于 Keras/TensorFlow),所以在指定你的图层尺寸时要格外小心。
然后,将生成的 PyTorch 神经网络返回给调用函数。
创建我们的 PyTorch 培训脚本
随着我们的神经网络架构的实现,我们可以继续使用 PyTorch 来训练模型。
为了完成这项任务,我们需要实施一个培训脚本,该脚本:
- 创建我们的神经网络架构的一个实例
- 构建我们的数据集
- 确定我们是否在 GPU 上训练我们的模型
- 定义一个训练循环(我们脚本中最难的部分)
打开train.py,让我们开始吧:
# import the necessary packages
from pyimagesearch import mlp
from torch.optim import SGD
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
import torch.nn as nn
import torch
第 2-7 行导入我们需要的 Python 包,包括:
- 我们对多层感知器架构的定义,在 PyTorch 中实现
SGD:我们将用来训练我们的模型的随机梯度下降优化器make_blobs:建立示例数据的合成数据集train_test_split:将我们的数据集分成训练和测试部分nn: PyTorch 的神经网络功能torch:基地 PyTorch 图书馆
当训练一个神经网络时,我们通过批数据来完成(正如你之前所学的)。下面的函数next_batch为我们的训练循环产生这样的批次:
def next_batch(inputs, targets, batchSize):
# loop over the dataset
for i in range(0, inputs.shape[0], batchSize):
# yield a tuple of the current batched data and labels
yield (inputs[i:i + batchSize], targets[i:i + batchSize])
next_batch函数接受三个参数:
inputs:我们对神经网络的输入数据targets:我们的目标输出值(即,我们希望我们的神经网络准确预测的值)batchSize:数据批量的大小
然后我们在batchSize块中循环输入数据(第 11 行),并将它们交给调用函数(第 13 行)。
接下来,我们要处理一些重要的初始化:
# specify our batch size, number of epochs, and learning rate
BATCH_SIZE = 64
EPOCHS = 10
LR = 1e-2
# determine the device we will be using for training
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print("[INFO] training using {}...".format(DEVICE))
当使用 PyTorch 训练我们的神经网络时,我们将使用 64 的批量大小,训练 10 个时期,并使用 1e-2 的学习速率(第 16-18 行)。
我们将我们的训练设备(CPU 或 GPU)设置在**第 21 行。**GPU 当然会加快训练速度,但是在这个例子中不是必需的。
接下来,我们需要一个示例数据集来训练我们的神经网络。在本系列的下一篇教程中,我们将学习如何从磁盘加载图像并对图像数据训练神经网络,但现在,让我们使用 scikit-learn 的 make_blobs 函数为我们创建一个合成数据集:
# generate a 3-class classification problem with 1000 data points,
# where each data point is a 4D feature vector
print("[INFO] preparing data...")
(X, y) = make_blobs(n_samples=1000, n_features=4, centers=3,
cluster_std=2.5, random_state=95)
# create training and testing splits, and convert them to PyTorch
# tensors
(trainX, testX, trainY, testY) = train_test_split(X, y,
test_size=0.15, random_state=95)
trainX = torch.from_numpy(trainX).float()
testX = torch.from_numpy(testX).float()
trainY = torch.from_numpy(trainY).float()
testY = torch.from_numpy(testY).float()
第 27 行和第 28 行构建我们的数据集,包括:
- 三级标签(
centers=3) - 神经网络的四个总特征/输入(
n_features=4) - 总共 1000 个数据点(
n_samples=1000)
从本质上来说,make_blobs函数正在生成聚集数据点的高斯斑点。对于 2D 数据,make_blobs函数将创建如下所示的数据:
注意这里有三组数据。我们在做同样的事情,但是我们有四维而不是二维(这意味着我们不容易想象它)。
一旦我们的数据生成,我们应用train_test_split函数(第 32 行和第 33 行)来创建我们的训练分割,85%用于训练,15%用于评估。
从那里,训练和测试数据从 NumPy 数组转换为 PyTorch 张量,然后转换为浮点数据类型(第 34-37 行)。
现在让我们实例化我们的 PyTorch 神经网络架构:
# initialize our model and display its architecture
mlp = mlp.get_training_model().to(DEVICE)
print(mlp)
# initialize optimizer and loss function
opt = SGD(mlp.parameters(), lr=LR)
lossFunc = nn.CrossEntropyLoss()
第 40 行初始化我们的 MLP,并将其推送到我们用于训练的任何东西DEVICE(CPU 或 GPU)。
第 44 行定义了我们的 SGD 优化器,它接受两个参数:
- 通过简单调用
mlp.parameters()获得的 MLP 模型参数 - 学习率
最后,我们初始化我们的分类交叉熵损失函数,这是使用 > 2 类执行分类时使用的标准损失方法。
**我们现在到达最重要的代码块,训练循环。与 Keras/TensorFlow 允许你简单地调用model.fit来训练你的模型不同,PyTorch 要求你手工实现你的训练循环。
手动实现训练循环有好处也有坏处。
一方面,你可以对训练过程进行完全的控制,这使得实现定制训练循环变得更加容易。
但另一方面,手工实现训练循环需要更多的代码,最糟糕的是,这更容易搬起石头砸自己的脚(这对初露头角的深度学习实践者来说尤其如此)。
我的建议:你会想要多次阅读对以下代码块*的解释,以便你理解训练循环的复杂性。您将 尤其是 想要密切关注我们如何将梯度归零,执行反向传播,然后更新模型参数— 如果不按照正确的顺序执行,将会导致错误的结果!*
*让我们回顾一下我们的培训循环:
# create a template to summarize current training progress
trainTemplate = "epoch: {} test loss: {:.3f} test accuracy: {:.3f}"
# loop through the epochs
for epoch in range(0, EPOCHS):
# initialize tracker variables and set our model to trainable
print("[INFO] epoch: {}...".format(epoch + 1))
trainLoss = 0
trainAcc = 0
samples = 0
mlp.train()
# loop over the current batch of data
for (batchX, batchY) in next_batch(trainX, trainY, BATCH_SIZE):
# flash data to the current device, run it through our
# model, and calculate loss
(batchX, batchY) = (batchX.to(DEVICE), batchY.to(DEVICE))
predictions = mlp(batchX)
loss = lossFunc(predictions, batchY.long())
# zero the gradients accumulated from the previous steps,
# perform backpropagation, and update model parameters
opt.zero_grad()
loss.backward()
opt.step()
# update training loss, accuracy, and the number of samples
# visited
trainLoss += loss.item() * batchY.size(0)
trainAcc += (predictions.max(1)[1] == batchY).sum().item()
samples += batchY.size(0)
# display model progress on the current training batch
trainTemplate = "epoch: {} train loss: {:.3f} train accuracy: {:.3f}"
print(trainTemplate.format(epoch + 1, (trainLoss / samples),
(trainAcc / samples)))
第 48 行初始化trainTemplate,这是一个字符串,允许我们方便地显示纪元编号,以及每一步的损失和精度。
然后我们在第 51 行**上循环我们想要的训练时期数。**紧接着在这个for循环里面我们:
- 显示纪元编号,这对调试很有用(行 53 )
- 初始化我们的训练损失和精确度(第 54 行和第 55 行)
- 初始化训练循环当前迭代中使用的数据点总数(行 56 )
- 将 PyTorch 模型置于训练模式(第 57 行)
调用 PyTorch 模型的train()方法需要在反向传播过程中更新模型参数。
在我们的下一个代码块中,您将看到我们将模型置于eval()模式,这样我们就可以在测试集上评估损失和准确性。如果我们忘记在下一个训练循环的顶部调用train(),那么我们的模型参数将不会被更新。
外部的for循环(第 51 行)在我们的历元数上循环。第 60 行然后开始一个内部for循环,遍历训练集中的每一批。几乎你用 PyTorch 编写的每一个训练程序都将包含一个外循环(在一定数量的时期内)和一个内循环(在数据批次内)。
在内部循环(即批处理循环)中,我们继续:
- 将
batchX和batchY数据移动到我们的 CPU 或 GPU(取决于我们的DEVICE) - 通过神经系统传递
batchX数据,并对其进行预测 - 使用我们的损失函数,通过将输出
predictions与我们的地面实况类标签进行比较来计算我们的损失
现在我们已经有了loss,我们可以更新我们的模型参数了— 这是 PyTorch 训练程序中最重要的一步,也是大多数初学者经常出错的一步。
为了更新我们模型的参数,我们必须按照指定的的确切顺序调用行 69-71 :
opt.zero_grad():将模型前一批次/步骤累积的梯度归零loss.backward():执行反向传播opt.step():基于反向传播的结果更新我们的神经网络中的权重
再次强调,你 必须 应用归零渐变,执行一个向后的过程,然后按照我已经指出的 的确切顺序 更新模型参数。
正如我提到的,PyTorch 让你对你的训练循环有很多的控制……但它也让很容易搬起石头砸自己的脚。每一个深度学习实践者,无论是深度学习领域的新手还是经验丰富的专家,都曾经搞砸过这些步骤。
最常见的错误是忘记将梯度归零。如果您不将梯度归零,那么您将在多个批次和多个时期累积梯度。这将打乱你的反向传播,并导致错误的体重更新。
说真的,别把这些步骤搞砸了。把它们写在便利贴上,如果需要的话,可以把它们放在你的显示器上。
在我们将权重更新到我们的模型后,我们在第 75-77 行上计算我们的训练损失、训练精度和检查的样本数量(即,批中数据点的数量)。
然后我们应用我们的trainTemplate来显示我们的纪元编号、训练损失和训练精度。请注意我们如何将损失和准确度除以批次中的样本总数,以获得平均值。
此时,我们已经在一个时期的所有数据点上训练了我们的 PyTorch 模型——现在我们需要在我们的测试集上评估它:
# initialize tracker variables for testing, then set our model to
# evaluation mode
testLoss = 0
testAcc = 0
samples = 0
mlp.eval()
# initialize a no-gradient context
with torch.no_grad():
# loop over the current batch of test data
for (batchX, batchY) in next_batch(testX, testY, BATCH_SIZE):
# flash the data to the current device
(batchX, batchY) = (batchX.to(DEVICE), batchY.to(DEVICE))
# run data through our model and calculate loss
predictions = mlp(batchX)
loss = lossFunc(predictions, batchY.long())
# update test loss, accuracy, and the number of
# samples visited
testLoss += loss.item() * batchY.size(0)
testAcc += (predictions.max(1)[1] == batchY).sum().item()
samples += batchY.size(0)
# display model progress on the current test batch
testTemplate = "epoch: {} test loss: {:.3f} test accuracy: {:.3f}"
print(testTemplate.format(epoch + 1, (testLoss / samples),
(testAcc / samples)))
print("")
类似于我们如何初始化我们的训练损失、训练精度和一批中的样本数量,我们在第 86-88 行对我们的测试集做同样的事情。这里,我们初始化变量来存储我们的测试损失、测试精度和测试集中的样本数。
我们还将我们的模型放入第 89 行**的eval()模型中。**我们被要求在我们需要计算测试或验证集的损失/精确度时,将我们的模型置于评估模式。
但是eval()模式实际上做什么呢? 您将评估模式视为关闭特定图层功能的开关,例如停止应用丢弃,或允许应用批量归一化的累积状态。
**其次,你通常将eval()与torch.no_grad()上下文结合使用,意味着在评估模式下关闭(第 92 行)。
从那里,我们循环测试集中的所有批次(第 94 行),类似于我们在前面的代码块中循环训练批次的方式。
对于每一批(行 96 ),我们使用我们的模型进行预测,然后计算损耗(行 99 和 100 )。
然后我们更新我们的testLoss、testAcc和数量samples ( 行 104-106 )。
最后,我们在我们的终端(行 109-112 )上显示我们的纪元编号、测试损失和测试精度。
总的来说,我们训练循环的评估部分是 与训练部分非常相似的 ,没有微小的 但是非常显著的 变化:
- 我们使用
eval()将模型置于评估模式 - 我们使用
torch.no_grad()上下文来确保不执行毕业计算
从那里,我们可以使用我们的模型进行预测,并计算测试集的准确性/损失。
PyTorch 培训结果
我们现在准备用 PyTorch 训练我们的神经网络!
请务必访问本教程的 “下载” 部分来检索源代码。
要启动 PyTorch 培训流程,只需执行train.py脚本:
$ python train.py
[INFO] training on cuda...
[INFO] preparing data...
Sequential(
(hidden_layer_1): Linear(in_features=4, out_features=8, bias=True)
(activation_1): ReLU()
(output_layer): Linear(in_features=8, out_features=3, bias=True)
)
[INFO] training in epoch: 1...
epoch: 1 train loss: 0.971 train accuracy: 0.580
epoch: 1 test loss: 0.737 test accuracy: 0.827
[INFO] training in epoch: 2...
epoch: 2 train loss: 0.644 train accuracy: 0.861
epoch: 2 test loss: 0.590 test accuracy: 0.893
[INFO] training in epoch: 3...
epoch: 3 train loss: 0.511 train accuracy: 0.916
epoch: 3 test loss: 0.495 test accuracy: 0.900
[INFO] training in epoch: 4...
epoch: 4 train loss: 0.425 train accuracy: 0.941
epoch: 4 test loss: 0.423 test accuracy: 0.933
[INFO] training in epoch: 5...
epoch: 5 train loss: 0.359 train accuracy: 0.961
epoch: 5 test loss: 0.364 test accuracy: 0.953
[INFO] training in epoch: 6...
epoch: 6 train loss: 0.302 train accuracy: 0.975
epoch: 6 test loss: 0.310 test accuracy: 0.960
[INFO] training in epoch: 7...
epoch: 7 train loss: 0.252 train accuracy: 0.984
epoch: 7 test loss: 0.259 test accuracy: 0.967
[INFO] training in epoch: 8...
epoch: 8 train loss: 0.209 train accuracy: 0.987
epoch: 8 test loss: 0.215 test accuracy: 0.980
[INFO] training in epoch: 9...
epoch: 9 train loss: 0.174 train accuracy: 0.988
epoch: 9 test loss: 0.180 test accuracy: 0.980
[INFO] training in epoch: 10...
epoch: 10 train loss: 0.147 train accuracy: 0.991
epoch: 10 test loss: 0.153 test accuracy: 0.980
我们的前几行输出显示了简单的 4-8-3 MLP 架构,这意味着有四个输入到神经网络,一个隐藏层有八个节点*,最后一个输出层有三个节点。*
然后我们训练我们的网络总共十个纪元。在训练过程结束时,我们在训练集上获得了 99.1%的准确率,在测试集上获得了 98%的准确率。
因此,我们可以得出结论,我们的神经网络在做出准确预测方面做得很好。
恭喜你用 PyTorch 训练了你的第一个神经网络!
如何在我自己的自定义数据集上训练 PyTorch 模型?
本教程向您展示了如何在 scikit-learn 的make_blobs函数生成的示例数据集上训练 PyTorch 神经网络。
虽然这是学习 PyTorch 基础知识的一个很好的例子,但是从真实场景的角度来看,它并不十分有趣。
下周,您将学习如何在手写字符数据集上训练 PyTorch 模型,它有许多实际应用,包括手写识别、OCR、等等!
敬请关注下周的教程,了解更多关于 PyTorch 和图像分类的知识。
总结
在本教程中,您学习了如何使用 PyTorch 深度学习库训练您的第一个神经网络。这个例子很简单,但是展示了 PyTorch 框架的基本原理。
我认为 PyTorch 库的深度学习实践者最大的错误是忘记和/或混淆了以下步骤:
- 将先前步骤的梯度归零(
opt.zero_grad()) - 执行反向传播(
loss.backward()) - 更新模型参数(
opt.step())
不按照这个顺序执行这些步骤*在使用 PyTorch 时肯定会搬起石头砸自己的脚,更糟糕的是,如果你混淆了这些步骤,PyTorch 不会报错, 所以你可能甚至不知道自己打中了自己!*
PyTorch 库超级强大,*但是你需要习惯这样一个事实:用 PyTorch 训练神经网络就像卸下你自行车的训练轮——如果你混淆了重要的步骤,没有安全网可以抓住你(不像 Keras/TensorFlow,它允许你将整个训练过程封装到一个单独的model.fit调用中)。
这并不是说 Keras/TensorFlow 比 PyTorch“更好”,这只是你需要知道的两个深度学习库之间的差异。
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!*****
PyTorch 分布式培训简介
原文:https://pyimagesearch.com/2021/10/18/introduction-to-distributed-training-in-pytorch/
在本教程中,您将学习使用 PyTorch 进行分布式培训的基础知识。
这是计算机视觉和深度学习从业者中级 PyTorch 技术 3 部分教程的最后一课:
- py torch中的图像数据加载器(第一课)
- py torch:Transfer 学习与图像分类 (上周教程)
- py torch 分布式培训简介(今天的课程)
当我第一次了解 PyTorch 时,我对它相当冷漠。作为一个在深度学习期间一直使用 TensorFlow 的人,我还没有准备好离开 TensorFlow 创造的舒适区,尝试一些新的东西。
由于命运的安排,由于一些不可避免的情况,我不得不最终潜入 PyTorch。虽然说实话,我的开始很艰难。已经习惯于躲在 TensorFlow 的抽象后面,PyTorch 的冗长本质提醒了我为什么离开 Java 而选择 Python。
然而,过了一会儿,PyTorch 的美丽开始显露出来。它之所以更冗长,是因为它让你对自己的行为有更多的控制。PyTorch 让您对自己的每一步都有更明确的把握,给您更多的自由。也许 Java 也有同样的意图,但我永远不会知道,因为那艘船已经起航了!
分布式训练为您提供了几种方法来利用您拥有的每一点计算能力,并使您的模型训练更加有效。PyTorch 的一个显著特点是它支持分布式训练。
今天我们就来学习一下数据并行包,可以实现单机,多 GPU 并行。完成本教程后,读者将会:
- 清晰理解 PyTorch 的数据并行性
- 一种实现数据并行的设想
- 在遍历 PyTorch 的冗长代码时,对自己的目标有一个清晰的认识
学习如何在 PyTorch 中使用数据并行训练, 继续阅读即可。
py torch 分布式培训简介
py torch 的数据并行训练是什么?
想象一下,有一台配有 4 个 RTX 2060 图形处理器的计算机。你被赋予了一项任务,你必须处理几千兆字节的数据。小菜一碟,对吧?如果你没有办法将所有的计算能力结合在一起会怎么样?这将是非常令人沮丧的,就像我们有 10 亿美元,但每个月只能花 5 美元一样!
如果我们没有办法一起使用我们所有的资源,那将是不理想的。谢天谢地, PyTorch 有我们撑腰!图 1 展示了 PyTorch 如何以简单而高效的方式在单个系统中利用多个 GPU。
这被称为数据并行训练,在这里你使用一个带有多个 GPU 的主机系统来提高效率,同时处理大量的数据。
这个过程非常简单。一旦调用了nn.DataParallel,就会在每个 GPU 上创建单独的模型实例。然后,数据被分成相等的部分,每个模型实例一个。最后,每个实例创建自己的渐变,然后在所有可用的实例中进行平均和反向传播。
事不宜迟,让我们直接进入代码,看看分布式培训是如何运行的!
配置您的开发环境
要遵循这个指南,首先需要在系统中安装 PyTorch。要访问 PyTorch 自己的视觉计算模型,您还需要在您的系统中安装 Torchvision。我们也在使用imutils包进行数据处理。最后,我们将使用matplotlib来绘制我们的结果!
幸运的是,上面提到的所有包都是 pip-installable!
$ pip install torch
$ pip install torchvision
$ pip install imutils
$ pip install matplotlib
在配置开发环境时遇到了问题?
说了这么多,你是:
- 时间紧迫?
- 了解你雇主的行政锁定系统?
- 想要跳过与命令行、包管理器和虚拟环境斗争的麻烦吗?
- 准备好在您的 Windows、macOS 或 Linux 系统上运行代码***?***
*那今天就加入 PyImageSearch 大学吧!
获得本教程的 Jupyter 笔记本和其他 PyImageSearch 指南,这些指南是 预先配置的 **,可以在您的网络浏览器中运行在 Google Colab 的生态系统上!**无需安装。
最棒的是,这些 Jupyter 笔记本可以在 Windows、macOS 和 Linux 上运行!
项目结构
在进入项目之前,让我们回顾一下项目结构。
$ tree -d .
.
├── distributed_inference.py
├── output
│ ├── food_classifier.pth
│ └── model_training.png
├── prepare_dataset.py
├── pyimagesearch
│ ├── config.py
│ ├── create_dataloaders.py
│ └── food_classifier.py
├── results.png
└── train_distributed.py
2 directories, 9 files
首先也是最重要的,是pyimagesearch目录。它包含:
config.py:包含在整个项目中使用的几个重要参数和路径- 包含一个函数,可以帮助我们加载、处理和操作数据集
food_classifier.py:驻留在这个脚本中的主模型架构
我们将使用的其他脚本在父目录中。它们是:
train_distributed.py:定义数据流程,训练我们的模型distributed_inference.py:将用于评估我们训练好的模型的个别测试数据
最后,我们有我们的output文件夹,它将存放所有其他脚本产生的所有结果(图、模型)。
配置先决条件
为了开始我们的实现,让我们从config.py开始,这个脚本将包含端到端训练和推理管道的配置。这些值将在整个项目中使用。
# import the necessary packages
import torch
import os
# define path to the original dataset
DATA_PATH = "Food-11"
# define base path to store our modified dataset
BASE_PATH = "dataset"
# define paths to separate train, validation, and test splits
TRAIN = os.path.join(BASE_PATH, "training")
VAL = os.path.join(BASE_PATH, "validation")
TEST = os.path.join(BASE_PATH, "evaluation")
我们定义了一个到原始数据集的路径(行 6 )和一个基本路径(行 9 )来存储修改后的数据集。在第 12-14 行上,我们使用os.path.join函数为修改后的数据集定义了单独的训练、验证和测试路径。
# initialize the list of class label names
CLASSES = ["Bread", "Dairy_product", "Dessert", "Egg", "Fried_food",
"Meat", "Noodles/Pasta", "Rice", "Seafood", "Soup",
"Vegetable/Fruit"]
# specify ImageNet mean and standard deviation and image size
MEAN = [0.485, 0.456, 0.406]
STD = [0.229, 0.224, 0.225]
IMAGE_SIZE = 224
在第 17-19 行,我们定义了我们的目标类。我们正在选择 11 个类,我们的数据集将被分组到这些类中。在第 22-24 行上,我们为我们的 ImageNet 输入指定平均值、标准偏差和图像大小值。请注意,平均值和标准偏差各有 3 个值。每个值分别代表通道方向、高度方向、和宽度方向的平均值和标准偏差。图像尺寸被设置为224 × 224 以匹配 ImageNet 模型的可接受的通用输入尺寸。
# set the device to be used for training and evaluation
DEVICE = torch.device("cuda")
# specify training hyperparameters
LOCAL_BATCH_SIZE = 128
PRED_BATCH_SIZE = 4
EPOCHS = 20
LR = 0.0001
# define paths to store training plot and trained model
PLOT_PATH = os.path.join("output", "model_training.png")
MODEL_PATH = os.path.join("output", "food_classifier.pth")
由于今天的任务涉及演示用于训练的多个图形处理单元,我们将设置torch.device到cuda ( 第 27 行)。cuda是 NVIDIA 开发的一个巧妙的应用编程接口(API),使CUDA(**Compute Unified Device Architecture)**的 GPU 被允许用于通用处理。此外,由于 GPU 比 CPU 拥有更多的带宽和内核,因此它们在训练机器学习模型方面速度更快。
在的第 30-33 行,我们设置了几个超参数,如LOCAL_BATCH_SIZE(训练期间的批量)、PRED_BATCH_SIZE(推断期间的批量)、时期和学习率。然后,在第 36 行和第 37 行,我们定义路径来存储我们的训练图和训练模型。前者将评估它相对于模型度量的表现,而后者将被调用到推理模块。
对于我们的下一个任务,我们将进入create_dataloaders.py脚本。
# import the necessary packages
from . import config
from torch.utils.data import DataLoader
from torchvision import datasets
import os
def get_dataloader(rootDir, transforms, bs, shuffle=True):
# create a dataset and use it to create a data loader
ds = datasets.ImageFolder(root=rootDir,
transform=transforms)
loader = DataLoader(ds, batch_size=bs, shuffle=shuffle,
num_workers=os.cpu_count(),
pin_memory=True if config.DEVICE == "cuda" else False)
# return a tuple of the dataset and the data loader
return (ds, loader)
在第 7 行的上,我们定义了一个名为get_dataloader的函数,它将根目录、PyTorch 的转换实例和批处理大小作为外部参数。
在的第 9 行和第 10 行,我们使用torchvision.datasets.ImageFolder来映射给定目录中的所有条目,以拥有__getitem__和__len__方法。这些方法在这里有非常重要的作用。
首先,它们有助于在从索引到数据样本的类似地图的结构中表示数据集。
其次,新映射的数据集现在可以通过一个torch.utils.data.DataLoader实例(第 11-13 行)传递,它可以并行加载多个数据样本。
最后,我们返回数据集和DataLoader实例(第 16 行)。
为分布式训练准备数据集
对于今天的教程,我们使用的是 Food-11 数据集。如果你想快速下载 Food-11 数据集,请参考 Adrian 关于使用 Keras 创建的微调模型的这篇精彩博文!
尽管数据集已经有了一个训练、测试和验证分割,但我们将以一种更易于理解的方式来组织它。
在其原始形式中,数据集的格式如图图 3 所示:
每个文件名的格式都是class_index_imageNumber.jpg。例如,文件0_10.jpg指的是属于Bread标签的图像。来自所有类别的图像被分组在一起。在我们的自定义数据集中,我们将按标签排列图像,并将它们放在各自带有标签名称的文件夹中。因此,在数据准备之后,我们的数据集结构将看起来像图 4 :
每个标签式文件夹将包含属于这些标签的相应图像。这样做是因为许多现代框架和函数在处理输入时更喜欢这样的文件夹结构。
所以,让我们跳进我们的prepare_dataset.py脚本,并编码出来!
# USAGE
# python prepare_dataset.py
# import the necessary packages
from pyimagesearch import config
from imutils import paths
import shutil
import os
def copy_images(rootDir, destiDir):
# get a list of the all the images present in the directory
imagePaths = list(paths.list_images(rootDir))
print(f"[INFO] total images found: {
len(imagePaths)}...")
我们首先定义一个函数copy_images ( 第 10 行),它有两个参数:图像所在的根目录和自定义数据集将被复制到的目标目录。然后,在的第 12 行,我们使用paths.list_images函数生成根目录中所有图像的列表。这将在以后复制文件时使用。
# loop over the image paths
for imagePath in imagePaths:
# extract class label from the filename
filename = imagePath.split(os.path.sep)[-1]
label = config.CLASSES[int(filename.split("_")[0])].strip()
# construct the path to the output directory
dirPath = os.path.sep.join([destiDir, label])
# if the output directory does not exist, create it
if not os.path.exists(dirPath):
os.makedirs(dirPath)
# construct the path to the output image file and copy it
p = os.path.sep.join([dirPath, filename])
shutil.copy2(imagePath, p)
我们开始遍历第 16 行的图像列表。首先,我们通过分隔前面的路径名(第 18 行)挑出文件的确切名称,然后我们通过filename.split("_")[0])识别文件的标签,并将其作为索引馈送给config.CLASSES。在第一次循环中,该函数创建目录路径(第 25 行和第 26 行)。最后,我们构建当前图像的路径,并使用 shutil 包将图像复制到目标路径。
# calculate the total number of images in the destination
# directory and print it
currentTotal = list(paths.list_images(destiDir))
print(f"[INFO] total images copied to {
destiDir}: "
f"{
len(currentTotal)}...")
# copy over the images to their respective directories
print("[INFO] copying images...")
copy_images(os.path.join(config.DATA_PATH, "training"), config.TRAIN)
copy_images(os.path.join(config.DATA_PATH, "validation"), config.VAL)
copy_images(os.path.join(config.DATA_PATH, "evaluation"), config.TEST)
我们对第 34 行和第 35 行进行健全性检查,看看是否所有的文件都被复制了。这就结束了copy_images功能。我们调用行 40-42 上的函数,并创建我们修改后的训练、测试、和验证数据集!
创建 PyTorch 分类器
既然我们的数据集创建已经完成,是时候进入food_classifier.py脚本并定义我们的分类器了。
# import the necessary packages
from torch.cuda.amp import autocast
from torch import nn
class FoodClassifier(nn.Module):
def __init__(self, baseModel, numClasses):
super(FoodClassifier, self).__init__()
# initialize the base model and the classification layer
self.baseModel = baseModel
self.classifier = nn.Linear(baseModel.classifier.in_features,
numClasses)
# set the classifier of our base model to produce outputs
# from the last convolution block
self.baseModel.classifier = nn.Identity()
我们首先定义我们的自定义nn.Module类(第 5 行)。这通常是在架构更复杂时完成的,在定义我们的模型时允许更大的灵活性。在类内部,我们的第一项工作是定义__init__函数来初始化对象的状态。
第 7 行上的super方法将允许访问基类的方法。然后,在第行第 10 行,我们将基本模型初始化为构造函数(__init__)中传递的baseModel参数。然后我们创建一个单独的分类输出层(第 11 行),带有 11 个输出,每个输出代表我们之前定义的一个类。最后,由于我们使用了自己的分类层,我们用nn.Identity替换了baseModel的内置分类层,这只是一个占位符层。因此,baseModel的内置分类器将正好反映其分类层之前的卷积模块的输出。
# we decorate the *forward()* method with *autocast()* to enable
# mixed-precision training in a distributed manner
@autocast()
def forward(self, x):
# pass the inputs through the base model and then obtain the
# classifier outputs
features = self.baseModel(x)
logits = self.classifier(features)
# return the classifier outputs
return logits
在第 21 行上,我们定义了自定义模型的forward()道次,但在此之前,我们用@autocast()修饰模型。这个 decorator 函数在训练期间支持混合精度,由于数据类型的智能分配,这实质上使您的训练更快。我已经把链接到了 TensorFlow 的一个博客,里面详细解释了混合精度。最后,在第 24 行和第 25 行上,我们获得baseModel输出,并将其通过自定义classifier层以获得最终输出。
使用分布式训练来训练 PyTorch 分类器
我们的下一个目的地是train_distributed.py,在那里我们将进行模型训练,并学习如何使用多个 GPU!
# USAGE
# python train_distributed.py
# import the necessary packages
from pyimagesearch.food_classifier import FoodClassifier
from pyimagesearch import config
from pyimagesearch import create_dataloaders
from sklearn.metrics import classification_report
from torchvision.models import densenet121
from torchvision import transforms
from tqdm import tqdm
from torch import nn
from torch import optim
import matplotlib.pyplot as plt
import numpy as np
import torch
import time
# determine the number of GPUs we have
NUM_GPU = torch.cuda.device_count()
print(f"[INFO] number of GPUs found: {
NUM_GPU}...")
# determine the batch size based on the number of GPUs
BATCH_SIZE = config.LOCAL_BATCH_SIZE * NUM_GPU
print(f"[INFO] using a batch size of {
BATCH_SIZE}...")
torch.cuda.device_count()函数(第 20 行)将列出我们系统中兼容 CUDA 的 GPU 数量。这将用于确定我们的全局批量大小(行 24 ),即config.LOCAL_BATCH_SIZE * NUM_GPU。这是因为如果我们的全局批量大小是B ,并且我们有N 兼容 CUDA 的 GPU,那么每个 GPU 都会处理批量大小B/N的数据。例如,对于全局批量12 和2 兼容 CUDA 的 GPU,每个 GPU 都会评估批量6 的数据。
# define augmentation pipelines
trainTansform = transforms.Compose([
transforms.RandomResizedCrop(config.IMAGE_SIZE),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(90),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
testTransform = transforms.Compose([
transforms.Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
# create data loaders
(trainDS, trainLoader) = create_dataloaders.get_dataloader(config.TRAIN,
transforms=trainTansform, bs=BATCH_SIZE)
(valDS, valLoader) = create_dataloaders.get_dataloader(config.VAL,
transforms=testTransform, bs=BATCH_SIZE, shuffle=False)
(testDS, testLoader) = create_dataloaders.get_dataloader(config.TEST,
transforms=testTransform, bs=BATCH_SIZE, shuffle=False)
接下来,我们使用 PyTorch 的一个非常方便的函数,称为torchvision.transforms。它不仅有助于构建复杂的转换管道,而且还赋予我们对选择使用的转换的许多控制权。
注意第 28-34 行,我们为我们的训练集图像使用了几个数据增强,如RandomHorizontalFlip、RandomRotation等。我们还使用此函数将均值和标准差归一化值添加到我们的数据集。
我们再次使用torchvision.transforms进行测试转换(第 35-39 行,但是我们没有添加额外的扩充。相反,我们通过在create_dataloaders脚本中创建的get_dataloader函数传递这些实例,并分别获得训练、验证和测试数据集和数据加载器(第 42-47 行)。
# load up the DenseNet121 model
baseModel = densenet121(pretrained=True)
# loop over the modules of the model and if the module is batch norm,
# set it to non-trainable
for module, param in zip(baseModel.modules(), baseModel.parameters()):
if isinstance(module, nn.BatchNorm2d):
param.requires_grad = False
# initialize our custom model and flash it to the current device
model = FoodClassifier(baseModel, len(trainDS.classes))
model = model.to(config.DEVICE)
我们选择densenet121作为我们的基础模型来覆盖我们模型架构的大部分( Line 50 )。然后我们在densenet121层上循环,并将batch_norm层设置为不可训练(行 54-56 )。这样做是为了避免由于批次大小不同而导致的批次标准化不稳定的问题。一旦完成,我们将densenet121发送给FoodClassifier类,并初始化我们的定制模型( Line 59 )。最后,我们将模型加载到我们的设备上(第 60 行)。
# if we have more than one GPU then parallelize the model
if NUM_GPU > 1:
model = nn.DataParallel(model)
# initialize loss function, optimizer, and gradient scaler
lossFunc = nn.CrossEntropyLoss()
opt = optim.Adam(model.parameters(), lr=config.LR * NUM_GPU)
scaler = torch.cuda.amp.GradScaler(enabled=True)
# initialize a learning-rate (LR) scheduler to decay the it by a factor
# of 0.1 after every 10 epochs
lrScheduler = optim.lr_scheduler.StepLR(opt, step_size=10, gamma=0.1)
# calculate steps per epoch for training and validation set
trainSteps = len(trainDS) // BATCH_SIZE
valSteps = len(valDS) // BATCH_SIZE
# initialize a dictionary to store training history
H = {
"train_loss": [], "train_acc": [], "val_loss": [],
"val_acc": []}
首先,我们使用一个条件语句来检查我们的系统是否适合 PyTorch 数据并行(行 63 和 64 )。如果条件为真,我们通过nn.DataParallel模块传递我们的模型,并将我们的模型并行化。然后,在第 67-69 行,我们定义我们的损失函数,优化器,并创建一个 PyTorch 渐变缩放器实例。梯度缩放器是一个非常有用的工具,有助于将混合精度引入梯度计算。然后,我们初始化一个学习率调度器,使其每 10 个历元衰减一个因子的值(行 73 )。
在第 76 行和第 77 行,我们为训练和验证批次计算每个时期的步骤。第 80行和第 81 行的H变量将是我们的训练历史字典,包含训练损失、训练精度、验证损失和验证精度等值。
# loop over epochs
print("[INFO] training the network...")
startTime = time.time()
for e in tqdm(range(config.EPOCHS)):
# set the model in training mode
model.train()
# initialize the total training and validation loss
totalTrainLoss = 0
totalValLoss = 0
# initialize the number of correct predictions in the training
# and validation step
trainCorrect = 0
valCorrect = 0
# loop over the training set
for (x, y) in trainLoader:
with torch.cuda.amp.autocast(enabled=True):
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# perform a forward pass and calculate the training loss
pred = model(x)
loss = lossFunc(pred, y)
# calculate the gradients
scaler.scale(loss).backward()
scaler.step(opt)
scaler.update()
opt.zero_grad()
# add the loss to the total training loss so far and
# calculate the number of correct predictions
totalTrainLoss += loss.item()
trainCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
# update our LR scheduler
lrScheduler.step()
为了评估我们的模型训练的速度有多快,我们对训练过程进行计时( Line 85 )。为了开始我们的模型训练,我们开始在第 87 行循环我们的纪元。我们首先将 PyTorch 定制模型设置为训练模式(第 89 行),并初始化训练和验证损失以及正确预测(第 92-98 行)。
然后,我们使用 train dataloader ( Line 101 )循环我们的训练集。一旦进入训练集循环,我们首先启用混合精度(行 102 )并将输入(数据和标签)加载到 CUDA 设备(行 104 )。最后,在第 107 行和第 108 行,我们让我们的模型执行向前传递,并使用我们的损失函数计算损失。
scaler.scale(loss).backward函数自动为我们计算梯度(第 111 行),然后我们将其插入模型权重并更新模型(第 111-113 行)。最后,我们在完成一遍后使用opt.zero_grad重置梯度,因为backward函数不断累积梯度(我们每次只需要逐步梯度)。
第 118-120 行更新我们的损失并校正预测值,同时在一次完整的训练通过后更新我们的 LR 调度器(第 123 行)。
# switch off autograd
with torch.no_grad():
# set the model in evaluation mode
model.eval()
# loop over the validation set
for (x, y) in valLoader:
with torch.cuda.amp.autocast(enabled=True):
# send the input to the device
(x, y) = (x.to(config.DEVICE), y.to(config.DEVICE))
# make the predictions and calculate the validation
# loss
pred = model(x)
totalValLoss += lossFunc(pred, y).item()
# calculate the number of correct predictions
valCorrect += (pred.argmax(1) == y).type(
torch.float).sum().item()
# calculate the average training and validation loss
avgTrainLoss = totalTrainLoss / trainSteps
avgValLoss = totalValLoss / valSteps
# calculate the training and validation accuracy
trainCorrect = trainCorrect / len(trainDS)
valCorrect = valCorrect / len(valDS)
在我们的评估过程中,我们将使用torch.no_grad关闭 PyTorch 的自动渐变,并将我们的模型切换到评估模式(第 126-128 行)。然后,在训练步骤中,我们循环验证数据加载器,并在将数据加载到我们的 CUDA 设备之前启用混合精度(第 131-134 行)。接下来,我们获得验证数据集的预测,并更新验证损失值(第 138 和 139 行)。
一旦脱离循环,我们计算训练和验证损失和预测的分批平均值(行 146-151 )。
# update our training history
H["train_loss"].append(avgTrainLoss)
H["train_acc"].append(trainCorrect)
H["val_loss"].append(avgValLoss)
H["val_acc"].append(valCorrect)
# print the model training and validation information
print("[INFO] EPOCH: {}/{}".format(e + 1, config.EPOCHS))
print("Train loss: {:.6f}, Train accuracy: {:.4f}".format(
avgTrainLoss, trainCorrect))
print("Val loss: {:.6f}, Val accuracy: {:.4f}".format(
avgValLoss, valCorrect))
# display the total time needed to perform the training
endTime = time.time()
print("[INFO] total time taken to train the model: {:.2f}s".format(
endTime - startTime))
在我们的纪元循环结束之前,我们将所有损失和预测值记录到我们的历史字典H ( 第 154-157 行)中。
一旦在循环之外,我们使用行 167 上的time.time()函数记录时间,看看我们的模型执行得有多快。
# evaluate the network
print("[INFO] evaluating network...")
with torch.no_grad():
# set the model in evaluation mode
model.eval()
# initialize a list to store our predictions
preds = []
# loop over the test set
for (x, _) in testLoader:
# send the input to the device
x = x.to(config.DEVICE)
# make the predictions and add them to the list
pred = model(x)
preds.extend(pred.argmax(axis=1).cpu().numpy())
# generate a classification report
print(classification_report(testDS.targets, preds,
target_names=testDS.classes))
现在是时候在测试数据上测试我们新训练的模型了。再次关闭自动梯度计算,我们将模型设置为评估模式(第 173-175 行)。
接下来,我们在行 178 上初始化一个名为preds的空列表,它将存储测试数据的模型预测。最后,我们遵循同样的程序,将数据加载到我们的设备中,获得批量测试数据的预测,并将值存储在preds列表中(第 181-187 行)。
在几个方便的工具中,scikit-learnclassification_report为我们提供了评估我们的模型的工具,其中classification_report提供了我们的模型给出的预测的完整的分类概述(第 190 和 191 行)。
[INFO] evaluating network...
precision recall f1-score support
Bread 0.92 0.88 0.90 368
Dairy_product 0.87 0.84 0.86 148
Dessert 0.87 0.92 0.89 500
Egg 0.94 0.92 0.93 335
Fried_food 0.95 0.91 0.93 287
Meat 0.93 0.95 0.94 432
Noodles 0.97 0.99 0.98 147
Rice 0.99 0.95 0.97 96
Seafood 0.95 0.93 0.94 303
Soup 0.96 0.98 0.97 500
Vegetable 0.96 0.97 0.96 231
accuracy 0.93 3347
macro avg 0.94 0.93 0.93 3347
weighted avg 0.93 0.93 0.93 3347
我们的模型的完整分类报告应该是这样的,让我们对我们的模型比其他模型预测得更好/更差的类别有一个全面的了解。
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(H["train_loss"], label="train_loss")
plt.plot(H["val_loss"], label="val_loss")
plt.plot(H["train_acc"], label="train_acc")
plt.plot(H["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on Dataset")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.PLOT_PATH)
# serialize the model state to disk
torch.save(model.module.state_dict(), config.MODEL_PATH)
我们训练脚本的最后一步是绘制模型历史字典中的值(行 194-204 ),并将模型状态保存在我们预定义的路径中(行 207 )。
使用 PyTorch 进行分布式训练
在执行训练脚本之前,我们需要运行prepare_dataset.py脚本。
$ python prepare_dataset.py
[INFO] copying images...
[INFO] total images found: 9866...
[INFO] total images copied to dataset/training: 9866...
[INFO] total images found: 3430...
[INFO] total images copied to dataset/validation: 3430...
[INFO] total images found: 3347...
[INFO] total images copied to dataset/evaluation: 3347...
一旦这个脚本运行完毕,我们就可以继续执行train_distributed.py脚本了。
$ python train_distributed.py
[INFO] number of GPUs found: 4...
[INFO] using a batch size of 512...
[INFO] training the network...
0%| | 0/20 [00:00<?, ?it/s][INFO] EPOCH: 1/20
Train loss: 1.267870, Train accuracy: 0.6176
Val loss: 0.838317, Val accuracy: 0.7586
5%|███▏ | 1/20 [00:37<11:47, 37.22s/it][INFO] EPOCH: 2/20
Train loss: 0.669389, Train accuracy: 0.7974
Val loss: 0.580541, Val accuracy: 0.8394
10%|██████▍ | 2/20 [01:03<09:16, 30.91s/it][INFO] EPOCH: 3/20
Train loss: 0.545763, Train accuracy: 0.8305
Val loss: 0.516144, Val accuracy: 0.8580
15%|█████████▌ | 3/20 [01:30<08:14, 29.10s/it][INFO] EPOCH: 4/20
Train loss: 0.472342, Train accuracy: 0.8547
Val loss: 0.482138, Val accuracy: 0.8682
...
85%|█████████████████████████████████████████████████████▌ | 17/20 [07:40<01:19, 26.50s/it][INFO] EPOCH: 18/20
Train loss: 0.226185, Train accuracy: 0.9338
Val loss: 0.323659, Val accuracy: 0.9099
90%|████████████████████████████████████████████████████████▋ | 18/20 [08:06<00:52, 26.32s/it][INFO] EPOCH: 19/20
Train loss: 0.227704, Train accuracy: 0.9331
Val loss: 0.313711, Val accuracy: 0.9140
95%|███████████████████████████████████████████████████████████▊ | 19/20 [08:33<00:26, 26.46s/it][INFO] EPOCH: 20/20
Train loss: 0.228238, Train accuracy: 0.9332
Val loss: 0.318986, Val accuracy: 0.9105
100%|███████████████████████████████████████████████████████████████| 20/20 [09:00<00:00, 27.02s/it]
[INFO] total time taken to train the model: 540.37s
经过 20 个时期后,平均训练精度达到了 0.9332 ,而验证精度达到了值得称赞的 0.9105 。让我们先来看看图 5 中的度量图!
通过观察整个过程中训练和验证指标的发展,我们可以有把握地说,我们的模型没有过度拟合。
数据分布式训练推理
虽然我们已经在测试集上评估了模型,但是我们将创建一个单独的脚本distributed_inference.py,其中我们将逐个单独评估测试图像,而不是一次评估一整批。
# USAGE
# python distributed_inference.py
# import the necessary packages
from pyimagesearch.food_classifier import FoodClassifier
from pyimagesearch import config
from pyimagesearch import create_dataloaders
from torchvision import models
from torchvision import transforms
import matplotlib.pyplot as plt
from torch import nn
import torch
# determine the number of GPUs we have
NUM_GPU = torch.cuda.device_count()
print(f"[INFO] number of GPUs found: {
NUM_GPU}...")
# determine the batch size based on the number of GPUs
BATCH_SIZE = config.PRED_BATCH_SIZE * NUM_GPU
print(f"[INFO] using a batch size of {
BATCH_SIZE}...")
# define augmentation pipeline
testTransform = transforms.Compose([
transforms.Resize((config.IMAGE_SIZE, config.IMAGE_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=config.MEAN, std=config.STD)
])
在初始化迭代器之前,我们设置了这些脚本的初始需求。这些包括设置由 CUDA GPUs 数量决定的批量大小(第 15-19 行)和为我们的测试数据集初始化一个torchvision.transforms实例(第 23-27 行)。
# calculate the inverse mean and standard deviation
invMean = [-m/s for (m, s) in zip(config.MEAN, config.STD)]
invStd = [1/s for s in config.STD]
# define our denormalization transform
deNormalize = transforms.Normalize(mean=invMean, std=invStd)
# create test data loader
(testDS, testLoader) = create_dataloaders.get_dataloader(config.TEST,
transforms=testTransform, bs=BATCH_SIZE, shuffle=True)
# load up the DenseNet121 model
baseModel = models.densenet121(pretrained=True)
# initialize our food classifier
model = FoodClassifier(baseModel, len(testDS.classes))
# load the model state
model.load_state_dict(torch.load(config.MODEL_PATH))
理解我们为什么计算第 30 和 31 行的反均值和反标准差值很重要。这是因为我们的torchvision.transforms实例在数据集被插入模型之前对其进行了规范化。所以,为了把图像变回原来的形式,我们要预先计算这些值。我们很快就会看到这些是如何使用的!
用这些值,我们创建一个torchvision.transforms.Normalize实例供以后使用(第 34 行)。接下来,我们在第 37 和 38 行的上使用create_dataloaders方法创建我们的测试数据集和数据加载器。
注意,我们已经在train_distributed.py中保存了训练好的模型状态。接下来,我们将像在训练脚本中一样初始化模型(第 41-44 行),并使用model.load_state_dict函数将训练好的模型权重插入到初始化的模型(第 47 行)。
# if we have more than one GPU then parallelize the model
if NUM_GPU > 1:
model = nn.DataParallel(model)
# move the model to the device and set it in evaluation mode
model.to(config.DEVICE)
model.eval()
# grab a batch of test data
batch = next(iter(testLoader))
(images, labels) = (batch[0], batch[1])
# initialize a figure
fig = plt.figure("Results", figsize=(10, 10 * NUM_GPU))
我们使用nn.DataParallel重复并行化模型,并将模型设置为评估模式(第 50-55 行)。因为我们将处理单个数据点,所以我们不需要遍历整个测试数据集。相反,我们将使用next(iter(loader)) ( 第 58 行和第 59 行)抓取一批测试数据。您可以运行此功能(直到发生器用完批次)来随机化批次选择。
# switch off autograd
with torch.no_grad():
# send the images to the device
images = images.to(config.DEVICE)
# make the predictions
preds = model(images)
# loop over all the batch
for i in range(0, BATCH_SIZE):
# initialize a subplot
ax = plt.subplot(BATCH_SIZE, 1, i + 1)
# grab the image, de-normalize it, scale the raw pixel
# intensities to the range [0, 255], and change the channel
# ordering from channels first to channels last
image = images[i]
image = deNormalize(image).cpu().numpy()
image = (image * 255).astype("uint8")
image = image.transpose((1, 2, 0))
# grab the ground truth label
idx = labels[i].cpu().numpy()
gtLabel = testDS.classes[idx]
# grab the predicted label
pred = preds[i].argmax().cpu().numpy()
predLabel = testDS.classes[pred]
# add the results and image to the plot
info = "Ground Truth: {}, Predicted: {}".format(gtLabel,
predLabel)
plt.imshow(image)
plt.title(info)
plt.axis("off")
# show the plot
plt.tight_layout()
plt.show()
同样,由于我们不打算改变模型的权重,我们关闭了自动渐变功能( Line 65 ),并将测试图像刷新到我们的设备中。最后,在第 70 行,我们直接对批量图像进行模型预测。
在批处理的图像中循环,我们选择单个图像,反规格化它们,放大它们的值并改变它们的尺寸顺序(第 80-83 行)。如果我们显示图像,改变尺寸是必要的,因为 PyTorch 选择将其模块设计为接受通道优先输入。也就是说,我们刚从torchvision.transforms出来的图像现在是Channels * Height * Width。为了显示它,我们必须以Height * Width * Channels的形式重新排列维度。
我们使用图像的单独标签,通过使用testDS.classes ( 第 86 行和第 87 行)来获得类的名称。接下来,我们得到单个图像的预测类别(第 90 行和第 91 行)。最后,我们比较单个图像的真实和预测标签(行 94-98 )。
这就结束了我们的数据并行训练的推理脚本!
数据并行训练模型的 PyTorch 可视化
让我们看看我们的推理脚本distributed_inference.py绘制的一些结果。
由于我们已经在推理脚本中采用了 4 个的批次大小,我们的绘图将显示当前批次的图片。
发送给我们的推理脚本的那批数据包含:牡蛎壳的图像(图 6 )、薯条的图像(图 7 )、包含肉的图像(图 8 )和巧克力蛋糕的图像(图 9 )。
这里我们看到 **3 个预测是正确的,共 4 个。**这一点,加上我们完整的测试集分数,告诉我们使用 PyTorch 的数据并行非常有效!
总结
在今天的教程中,我们领略了 PyTorch 的大量分布式训练程序。就内部工作而言,nn.DataParallel可能不是其他分布式培训程序中最有效或最快的,但它肯定是一个很好的起点!它很容易理解,只需要一行代码就可以实现。正如我之前提到的,其他过程需要更多的代码,但是它们是为了更有效地处理事情而创建的。
nn.DataParallel的一些非常明显的问题是:
- 创建整个模型实例本身的冗余
- 当模型变得太大而不适合时无法工作
- 当可用的 GPU 不同时,无法自适应地调整训练
尤其是在处理大型架构时,模型并行是首选,在这种情况下,您可以在 GPU 之间划分模型层。
也就是说,如果你的系统中有多个 GPU,那么使用nn.DataParallel充分利用你的系统所能提供的每一点计算能力。
我希望本教程对你有足够的帮助,为你从整体上掌握分布式培训的好奇心铺平道路!
引用信息
Chakraborty,d .“py torch 分布式培训简介”, PyImageSearch ,2021,https://PyImageSearch . com/2021/10/18/Introduction-to-Distributed-Training-in-py torch/
@article{Chakraborty_2021_Distributed, author = {Devjyoti Chakraborty}, title = {Introduction to Distributed Training in {PyTorch}}, journal = {PyImageSearch}, year = {2021}, note = {https://pyimagesearch.com/2021/10/18/introduction-to-distributed-training-in-pytorch/}, }
要下载这篇文章的源代码(并在未来教程在 PyImageSearch 上发布时得到通知),只需在下面的表格中输入您的电子邮件地址!***