原文:KDNuggets
使用 Scikit-Learn 的主成分分析(PCA)
原文:
www.kdnuggets.com/2023/05/principal-component-analysis-pca-scikitlearn.html

图片作者
如果您对无监督学习范式比较熟悉,您可能会接触到降维及用于降维的算法,例如主成分分析(PCA)。机器学习的数据集通常包含大量特征,但如此高维的特征空间并不总是有用的。
我们的前三个课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业生涯。
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
 2. Google 数据分析专业证书 - 提升您的数据分析技能
2. Google 数据分析专业证书 - 提升您的数据分析技能
 3. Google IT 支持专业证书 - 支持您的组织的 IT
3. Google IT 支持专业证书 - 支持您的组织的 IT
一般来说,并非所有特征都是同等重要的,某些特征对数据集的方差占比很大。降维算法的目标是将特征空间的维度减少到原始维度的一个小部分。在这样做的过程中,具有高方差的特征仍然被保留——但位于转换后的特征空间中。而主成分分析(PCA)是最受欢迎的降维算法之一。
在本教程中,我们将学习主成分分析(PCA)的工作原理,并了解如何使用 scikit-learn 库实现它。
主成分分析(PCA)是如何工作的?
在我们继续使用 scikit-learn 实现主成分分析(PCA)之前,了解 PCA 的工作原理是有帮助的。
如前所述,主成分分析是一种降维算法。这意味着它减少了特征空间的维度。但它是如何实现这种降维的呢?
该算法背后的动机是存在某些特征能够捕捉到原始数据集中很大一部分的方差。因此,找到数据集中最大方差的方向是很重要的。这些方向被称为主成分。而 PCA 实质上是将数据集投影到主成分上。
那么我们如何找到主成分呢?
假设数据矩阵 X 的维度为num_observations x num_features,我们对 X 的协方差矩阵执行eigenvalue decomposition。
如果特征均值为零,则协方差矩阵为 X.T X。这里,X.T 是矩阵 X 的转置。如果特征最初不都是零均值,我们可以从每一列的每个条目中减去该列的均值,然后计算协方差矩阵。可以简单地看出,协方差矩阵是一个num_features阶的方阵。

作者图片
前k个主成分是对应于k 个最大特征值的特征向量。
因此,PCA 的步骤可以总结如下:

作者图片
由于协方差矩阵是对称的且半正定的,特征分解采用如下形式:
X.T X = D Λ D.T
其中,D 是特征向量矩阵,Λ 是特征值的对角矩阵。
使用 SVD 的主成分
另一种可以用来计算主成分的矩阵分解技术是奇异值分解(SVD)。
奇异值分解(SVD)定义适用于所有矩阵。给定一个矩阵 X,X 的 SVD 为:X = U Σ V.T。这里,U、Σ 和 V 分别是左奇异向量、奇异值和右奇异向量的矩阵。V.T. 是 V 的转置。
因此,X 的协方差矩阵的 SVD 表示为:

比较这两种矩阵分解的等效性:

我们有以下内容:

计算矩阵的 SVD 有计算效率高的算法。scikit-learn 实现的 PCA 在内部也使用 SVD 来计算主成分。
使用 Scikit-Learn 执行主成分分析 (PCA)
现在我们已经了解了主成分分析的基本概念,让我们继续进行 Scikit-Learn 的实现。
步骤 1 – 加载数据集
为了理解如何实现主成分分析,我们使用一个简单的数据集。在本教程中,我们将使用作为 scikit-learn 的datasets模块一部分的 wine 数据集。
我们从加载和预处理数据集开始:
from sklearn import datasets
wine_data = datasets.load_wine(as_frame=True)
df = wine_data.data
它有 13 个特征和总共 178 条记录。
print(df.shape)
Output >> (178, 13)
print(df.info())
Output >>
<class>RangeIndex: 178 entries, 0 to 177
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 alcohol 178 non-null float64
1 malic_acid 178 non-null float64
2 ash 178 non-null float64
3 alcalinity_of_ash 178 non-null float64
4 magnesium 178 non-null float64
5 total_phenols 178 non-null float64
6 flavanoids 178 non-null float64
7 nonflavanoid_phenols 178 non-null float64
8 proanthocyanins 178 non-null float64
9 color_intensity 178 non-null float64
10 hue 178 non-null float64
11 od280/od315_of_diluted_wines 178 non-null float64
12 proline 178 non-null float64
dtypes: float64(13)
memory usage: 18.2 KB
None</class>
步骤 2 – 预处理数据集
下一步,让我们对数据集进行预处理。特征都在不同的尺度上。为了将它们都转换到一个共同的尺度,我们将使用StandardScaler,它将特征转换为均值为零、方差为一的形式:
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
scaled_df = std_scaler.fit_transform(df)
步骤 3 – 对预处理的数据集进行 PCA
要找到主成分,我们可以使用来自 scikit-learn 的decomposition模块中的 PCA 类。
让我们通过将主成分数量 n_components 传递给构造函数来实例化一个 PCA 对象。
主成分的数量是你希望将特征空间减少到的维度数。在这里,我们将主成分数量设置为 3。
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
pca.fit_transform(scaled_df)
除了调用 fit_transform() 方法,你还可以先调用 fit(),然后再调用 transform() 方法。
请注意,当我们使用 scikit-learn 实现的 PCA 时,诸如计算协方差矩阵、对协方差矩阵进行特征分解或奇异值分解以获得主成分等步骤都被抽象化了。
第 4 步 – 检查 PCA 对象的一些有用属性
我们创建的 PCA 实例 pca 具有多个有用的属性,有助于我们理解其背后的情况。
components_ 属性存储了最大方差的方向(主成分)。
print(pca.components_)
Output >>
[[ 0.1443294 -0.24518758 -0.00205106 -0.23932041 0.14199204 0.39466085
0.4229343 -0.2985331 0.31342949 -0.0886167 0.29671456 0.37616741
0.28675223]
[-0.48365155 -0.22493093 -0.31606881 0.0105905 -0.299634 -0.06503951
0.00335981 -0.02877949 -0.03930172 -0.52999567 0.27923515 0.16449619
-0.36490283]
[-0.20738262 0.08901289 0.6262239 0.61208035 0.13075693 0.14617896
0.1506819 0.17036816 0.14945431 -0.13730621 0.08522192 0.16600459
-0.12674592]]
我们提到主成分是数据集中最大方差的方向。但我们如何衡量在我们选择的主成分数量中捕获了总方差的多少呢?
explained_variance_ratio_ 属性捕获了每个主成分所捕获的总方差比。因此,我们可以将这些比率相加以获得所选数量主成分的总方差。
print(sum(pca.explained_variance_ratio_))
Output >> 0.6652996889318527
在这里,我们看到三个主成分捕获了数据集总方差的超过 66.5%。
第 5 步 – 分析解释方差比的变化
我们可以尝试通过改变主成分数量 n_components 来运行主成分分析。
import numpy as np
nums = np.arange(14)
var_ratio = []
for num in nums:
pca = PCA(n_components=num)
pca.fit(scaled_df)
var_ratio.append(np.sum(pca.explained_variance_ratio_))
为了可视化主成分数量的 explained_variance_ratio_,我们可以绘制如下两个量:
import matplotlib.pyplot as plt
plt.figure(figsize=(4,2),dpi=150)
plt.grid()
plt.plot(nums,var_ratio,marker='o')
plt.xlabel('n_components')
plt.ylabel('Explained variance ratio')
plt.title('n_components vs. Explained Variance Ratio')
当我们使用所有 13 个主成分时,explained_variance_ratio_ 为 1.0,表示我们已经捕获了数据集中的 100% 方差。
在这个例子中,我们看到使用 6 个主成分可以捕获输入数据集中超过 80% 的方差。

结论
希望你已经学会了如何使用 scikit-learn 库中的内置功能执行主成分分析。接下来,你可以尝试在你选择的数据集上实现 PCA。如果你在寻找好的数据集进行实验,可以查看这个数据科学项目数据集网站列表。
进一步阅读
[1] 计算线性代数,fast.ai
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇点上工作。她的兴趣和专业领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正致力于通过撰写教程、操作指南、评论文章等,学习并与开发者社区分享她的知识。
更多相关主题
优先排序数据科学模型以便投入生产
原文:
www.kdnuggets.com/2022/04/prioritizing-data-science-models-production.html

图片来源于 airfocus,在 unsplash.com
很少有企业拥有不受限制的数据科学预算。用于人员、技术、分析环境和平台的资金通常远小于公司对知识的需求。在我曾经工作的公司中,新的分析模型的愿望清单需要将我们的研究人员数量翻倍,这显然是不可能的。
我们的前 3 个课程推荐
 1. Google 网络安全证书 - 快速开启网络安全职业生涯。
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
 3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
Therese Gorski,多个优先级排序工作的领导者,告诉我优先级排序的需求在许多产品管理组织中很常见。它通常是评估许多市场产品创意的更大过程的一部分。她说,因此,将优先级排序过程管理得像其他产品开发投资一样是有用的。
在这篇文章中,我提出了一些标准供公司在分配稀缺资源用于数据科学工作时考虑。我的建议是与每个参与生产、营销、销售、融资、支持或维护公司产品的部门人员讨论这些标准。公司员工的见解应来自所有层级,而不仅仅是领导层。这应当辅以受每个模型影响的外部利益相关者的见解。广泛的意见反馈将有助于最大化客户效用,从而增加他们和你公司的销售额和利润。广泛的意见反馈也将提升你产品的社会价值。
十二项考虑标准
以下表格中的标准受到了 Therese 及其在几家公司工作的同事以及最近文献关于使模型有用的属性和应避免的陷阱的启发。其中一些标准可以在生产前进行权衡;其他标准则涉及已经生产出的模型。
模型属性应在生产前后进行权衡,因为直到训练过程的后期甚至之后,才可能清楚任何模型是否可能变得或保持有用。此外,新模型通常要与长期出售但需要定期且重要投资以维持或更新的旧模型竞争有限的资金。因此,考虑每个模型对业务成功的可能贡献非常重要。这要求在评估投资或继续投资数据科学模型的效用时,权衡多种标准和视角。
考虑到这些因素,以下表格列出了十二个考虑标准。这样的文件可以分发给利益相关者和员工,以便从多方收集对每个标准的评分,然后汇总讨论。



如表格所示,这些十二个标准以声明的形式出现,每个回应者的任务是记录他们对每个模型中每个声明的同意程度。为了简化,我假设同意程度的范围从 1(强烈不同意)到 5(强烈同意)。使用相同的范围通过减少回应的差异性来增加结果的可靠性;它也使每个声明更易于解释。
另一个重要任务是权衡每个标准的重要性。在这里,重点是标准而非模型,Excel 文件包括一个列来指定每个标准的权重。您的业务利益相关者是否希望对每个标准赋予相同的重要性,还是认为某些标准比其他标准更重要,需要更高的权重?这个讨论可能会很有启发性,也可能会引发争议,有三种选项值得考虑。有些人可能认为权重的讨论应该在收集到一致性数据之后进行,这样可以促进标准权重与一致性水平之间的独立性,意味着一个不会影响另一个。其他人可能会持不同意见,先评估每个标准的重要性,然后评估每个模型中每个标准的一致性水平。第三种选择,如表中所示,是在评估一致性水平的同时,询问利益相关者对每个标准应给予多少权重,然后使用所有响应者的结果来共同决定每个标准的权重。使用对您的组织效果更好的选项。如果不确定哪种方法更好,可以对不同的独立随机评估子集尝试不同的方法,或随着时间的推移尝试不同的方法,以帮助决定哪种方法更适合您。
评分模型
一旦这些活动完成并且所有受访者提供了每个模型的评分,就可以开始对每个模型进行评分。每个模型的得分可以从每个受访者那里计算,基于所有人一致同意的标准权重和受访者对每个标准的一致性水平:
受访者 A 的总得分 =  标准权重 * 一致性水平
标准权重 * 一致性水平
总和从 1 到 12,因为每个模型有十二个标准。例如,假设受访者 A 对每个标准都强烈同意,并且每个标准的权重都是 1.0\。那么他的得分将等于 60(即,12 个标准乘以 5 的值,表示对每个标准都强烈同意)。大多数受访者会将他们的分数从 1 到 5 进行变化,使得标准权重非常重要。
一旦从每个受访者那里获得了每个模型的分数,就可以通过将所有受访者的分数相加或平均来获得整体模型得分。这些数据可以在另一张表格中呈现和比较。可以生成模型标准和模型得分的均值、中位数、方差和箱形图,带有和不带有异常值。这将有助于讨论哪些标准最重要,以及采用或保留哪些模型。
标准有效性
提议的标准的有效性也很重要。我试图通过涵盖我与同事讨论的分析模型质量的几个问题,以及最近文献中描述的内容来解决内容有效性。因此,一个标准涉及到所考虑的模型是否可能测量或预测真实感兴趣结果,而不是该结果的代理。评论这个问题时,布赖恩·霍赫雷因,另一位著名的分析领导者提到,没有数据集能够完美捕捉人类行为或自然界的复杂性,所以问题是当数据不完美时,是否以及如何继续建模。Christian (2020)、Hall 等人 (2021) 和 Obermeyer 等人 (2021) 提供了一些在这种情况下如何继续的想法。
模型的复杂性和性能也在表格中被列为重要标准。根据布赖恩的说法,我们需要那些易于理解但足够复杂以准确预测或理解感兴趣结果的模型。其他人也同意这一点(例如,Christian, 2020;Hall 和 Gill (2019))。这些模型应在统计指标上表现良好,并且具有高灵敏度和低虚假发现率。它们还应提供比竞争对手模型更好或更有用的见解。
能够得出因果推断也反映在标准中,因为数据科学家和政策制定者对这一领域的兴趣日益增长。因果关系基于对真实感兴趣结果的测量,如前所述,这依赖于拥有合适的数据和其他资源。当数据、资源或建模过程未能充分捕捉人类本性时,因果推断将受到限制。
还建议考虑模型的透明度、可信度、公平性、偏见和安全性,以及在建模过程中保护数据和研究对象的努力。
在我工作过的地方,模型被开发、维护和更新,以便它们可以作为公司销售或希望销售的产品中的组件。因此,每个模型对公司和客户收入与利润的最终贡献非常重要。对公司声誉的潜在贡献也很重要。这些都很难为任何给定的分析模型估算,因为它们必须考虑到模型的有效使用期,而这很难预测。关于数据科学努力对收入、利润和声誉的大小和时机的贡献,可能会有激烈的讨论。这些讨论会揭示争议;公开和专业地处理这些争议将会建立信任,并对不同的意见有更广泛的理解和尊重。
表中提到的最后两个标准反映了每个模型对员工福祉、士气和满意度的贡献,以及对专业思想领导力的贡献。我们应该建立能够吸引和激励公司全体员工的模型。给予员工参与思想领导力的机会,并允许他们影响模型生产,将培养忠诚度并提供专业成长的机会。
除了列出评估每个标准重要性的标准和建议外,该表还提到了关于每个标准需要考虑的几个问题。我还提供了引用或链接,以便在文献中找到关于这些问题的更多信息。

图片由 Stephen Dawson 提供,来源于 unsplash.com
限制与讨论
这本简短的模型优先级指南中还有很多未涵盖的内容。我的重点是面向外部的模型,尽管类似的标准也可以用于内部工作。
你可能会认为十几个标准太多了,或者太少——找出适合你公司的标准。你可能会识别出其他重要的标准或需要解决的其他问题。虽然我在表中提供了一些关于需要考虑的问题的想法,但没有说明如何解决这些问题或如何解决有关这些问题的争议。下面列出的参考文献以及表中所列的参考文献可以帮助解决这些问题。我鼓励你查看这些资料。这些作者在他们的领域中非常著名,并提供了许多值得考虑的见解。
模型评分后会发生什么?评分过程和结果应在内部和外部贡献者之间讨论。如果有必要,可以进行调整,也许采用收集、整理和分发评论以进行后续讨论的方法。这可以根据需要重复多次,以达成一致。
但要小心最响亮的声音和最高级别的声音症候群。预期一些情感上的呼吁或观点可能会有意或无意地使标准偏向某些模型而非其他模型,或压制辩论。这些问题应该被广泛讨论。也许是在小组中,也许是个人讨论,但每个人都应该了解不同的观点,以便能够专业地解决利弊。
Hall 等人(2021)和 Obermeyer 等人(2021)提供了关于当模型表现不佳或被认为不太有用时的建议。他们还提出了如何利用人员、流程和技术来改进模型的想法。他们及其他人(例如,Christian, 2020; Melchionna 2022)强烈推荐由人类专家和非专家提供指导,特别是那些代表我们模型覆盖的群体的专家。有关模型问责制和审计流程的指导也在他们的工作中提到。
扩展与最终思考
数据科学家可能会建议其他优先级设定方法。大公司通常会追踪其产品的表现。如果是这样,可能可以收集到足够的关于其产品属性的数据,或者模型的基础数据,然后使用聚类和回归模型,或其他机器学习技术,来帮助设定每个标准的权重。
为了便于数据收集和分析,一些公司通过给每个输入贴上标签,将其产品商品化。这些输入应包括每个产品所采用的所有数据科学模型。公司随后可能会为每个模型和其他输入分配类似零件号的标识。由于模型和其他特性可以在多个产品中使用多年,这有助于识别数据科学团队和其他团队对公司产品的贡献范围。考虑到创建每个输入所需的工作量和资源,有助于在参与产品开发和管理的团队之间分配收入或利润信用。跟踪这些信用随着时间的推移也有助于员工对标准的权重和建模工作的市场价值进行推断,以优先考虑未来的工作。
理想情况下,应该就使用哪些标准、如何对每个标准加权,以及如何在公司内优先排序模型达成共识,或至少形成强大的多数意见。经验表明,这将需要一些时间,因此数据科学路线图应当预留足够的时间,以完成深思熟虑的模型优先级设定过程。第一次使用时,这可能需要三到四个月。预计后续应用会快得多。我已经多次做过这个过程,乐意提供帮助。希望你觉得这个过程有用。
致谢
我要感谢 Therese Gorski 和 Brian Hochrein 对本文的有益评论。他们的见解使文章大为改进。任何剩余的错误均由我承担。
参考文献
-
A. Christian, 对齐问题:机器学习与人类价值(2020),纽约,NY:W.W. Norton & Company
-
A. Géron, 动手实践机器学习:使用 Scikit-Learn、Keras 和 TensorFlow 构建智能系统的概念、工具和技术,第 2**版(2019),Sebostopal,CA:O’Reilly Media, Inc.
-
P. Hall 和 N. Gill, 机器学习可解释性简介:公平性、问责制、透明度和可解释 AI 的应用视角,第 2**版(2019),Sebostopal,CA:O’Reilly Media, Inc.
-
P. Hall, N. Gill 和 B. Cox, 负责任的机器学习(2021),Sebostopal,CA:O’Reilly Media, Inc.
-
D. Husereau, M. Drummond, F. Augustovski 等,《整合健康经济评估报告标准(CHEERS)2022 解释与阐述:ISPOR CHEERS II 良好实践工作组的报告》(2022),价值健康 25:1:10-31。
-
M. Maziarz,经济学中的因果关系哲学:因果推断与政策建议(2020),纽约,NY:Routledge
-
M. Melchionna,世卫组织:是时候消除人工智能中的年龄歧视了(2022 年 2 月 10 日),健康 IT 分析,
healthitanalytics.com/news/who-its-time-to-eliminate-ageism-in-artificial-intelligence -
S.L. Morgan 和 C. Winship,反事实与因果推断:社会研究的方法与原则,第 2 版(2015),英国剑桥:剑桥大学出版社
-
Z. Obermeyer, R. Nissan, M. Stern 等,算法偏见手册(2021 年 6 月),芝加哥,IL:芝加哥大学应用人工智能中心
-
R. Ozminkowski,什么原因导致什么,我们如何知道?(2021 年 9 月 14 日),迈向数据科学,
towardsdatascience.com/what-causes-what-and-how-would-we-know-b736a3d0eefb -
J. Pearl, M. Glymour 和 N.P. Jewell,统计学中的因果推断:入门(2016),英国威斯萨塞克斯,Chichester:John Wiley & Sons
-
J. Pearl 和 D. Mackenzie,为什么之书:因果关系的新科学(2018),纽约,NY:Basic Books
-
B. Schmarzo,《数据、分析与数字化转型的经济学:引导组织数字化转型的定理、法则与赋能》(2020),英国伯明翰:Packt Publishing
-
L. Wee, M.J. Sander, F.J.van Kujik 等,《预测模型的报告标准与批判性评估》,见于临床数据科学基础(2019),编辑:A. Dekker, M. Dumontier, 和 P. Kubben,通过
doi.org/10.1007/978-3-319-99713-1开放获取
Ron Ozminkowski 博士 是一位国际认可的顾问、作家和高管,专注于医疗分析和机器学习,其出版的工作已被全球 90 多个国家的读者阅读。
更多相关话题
成为 Pandas,Python 的数据处理库的专家
 评论
评论
由Julien Kervizic,GrandVision NV 高级企业数据架构师
Pandas 库是 Python 中最流行的数据处理库。它通过其数据框 API 提供了一种简便的数据处理方式,灵感来自 R 的数据框。
 照片由Damian Patkowski拍摄,Unsplash
照片由Damian Patkowski拍摄,Unsplash
了解 Pandas 库
了解 Pandas 的关键之一是理解 Pandas 主要是围绕一系列其他 Python 库的包装器。主要包括 Numpy、SQLAlchemy、Matplotlib 和 openpyxl。
数据框的核心内部模型是一系列 numpy 数组,Pandas 函数如现已弃用的“as_matrix”返回结果在该内部表示中。
Pandas 利用其他库将数据输入和输出到数据框中,例如,通过 read_sql 和 to_sql 函数使用 SQLAlchemy。而 openpyxl 和 xlsx writer 则用于 read_excel 和 to_excel 函数。
Matplotlib 和 Seaborn 用于提供一个简单的接口来绘制数据框中的信息,使用如 df.plot()这样的命令。
Numpy 的 Pandas——高效的 Pandas
经常听到的抱怨之一是 Python 运行缓慢或难以处理大量数据。大多数情况下,这是由于编写的代码效率低下。确实,本地 Python 代码往往比编译代码慢,但像 Pandas 这样的库有效地提供了 Python 代码到编译代码的接口。了解如何正确地与其接口,可以让我们充分发挥 Pandas/Python 的优势。
应用向量化操作
Pandas,像其底层库 Numpy 一样,执行向量化操作比执行循环更高效。这些效率来源于向量化操作通过 C 编译代码而非本地 Python 代码进行,同时利用了向量化操作对整个数据集进行处理的能力。
apply 接口通过使用 CPython 接口进行循环,从而提高了一些效率:
df.apply(lambda x: x['col_a'] * x['col_b'], axis=1)
但大部分性能提升将来自于使用向量化操作本身,无论是直接在 Pandas 中还是通过直接调用其内部的 Numpy 数组。

正如你从上面的图片中可以看到,性能差异可能非常巨大,通过矢量化操作处理(3.53 毫秒)和用 Apply 循环进行加法(27.8 秒)之间的差距。通过直接调用 numpy 的数组和 API,可以获得额外的效率,例如:

Swifter: Swifter 是一个 Python 库,简化了在数据框上对不同类型操作的矢量化,其 API 与 Apply 函数非常相似。
高效数据存储通过 DTYPES
在将数据框加载到内存中时,无论是通过 read_csv、read_excel 还是其他数据框读取函数,SQL 都会进行类型推断,这可能会导致效率低下。这些 API 允许你明确指定每列的类型,从而实现更高效的数据存储。
df.astype({
'testColumn': str, 'testCountCol': float})
Dtypes 是 Numpy 的本地对象,它允许你定义存储某些信息所使用的确切类型和位数。
Numpy 的 dtype np.dtype('int32') 例如表示一个 32 位长的整数。Pandas 默认使用 64 位整数,通过使用 32 位可以节省一半的空间:

memory_usage() 显示了每列所使用的字节数,由于每列只有一个条目(行),因此每个 int64 列的大小为 8 字节,而 int32 为 4 字节。
Pandas 还引入了分类 dtype,允许对频繁出现的值进行高效的内存利用。在下面的例子中,我们可以看到,将字段 posting_date 转换为分类值后,内存利用率降低了 28 倍。

在我们的例子中,只需更改这种数据类型,数据框的总体大小就减少了 3 倍以上:

不仅使用正确的 dtypes 允许你在内存中处理更大的数据集,还使一些计算变得更有效。在下面的例子中,我们可以看到,使用分类类型为 groupby/sum 操作带来了 3 倍的速度提升。

在 Pandas 中,你可以在数据加载时(read_)或作为类型转换(astype)来定义 dtypes。
CyberPandas: CyberPandas 是一种不同的库扩展,支持更多种类的数据类型,包括 ipv4 和 ipv6 数据类型,并高效地存储它们。
处理大数据集的 CHUNKS
Pandas 允许通过块加载数据框,因此可以将数据框作为迭代器进行处理,并能够处理比可用内存更大的数据框。

在读取数据源时定义 chunksize 和使用 get_chunk 方法的组合,使 Pandas 能够将数据作为 迭代器 进行处理。例如,在上述示例中,数据框每次读取 2 行。这些块可以被迭代:
i = 0
for a in df_iter:
# do some processing chunk = df_iter.get_chunk()
i += 1
new_chunk = chunk.apply(lambda x: do_something(x), axis=1)
new_chunk.to_csv("chunk_output_%i.csv" % i )
其输出可以被保存到 CSV 文件中、进行 pickle 操作、导出到数据库等……
通过块设置操作员也允许某些操作通过 多处理 来完成。
Dask: 这是一个建立在 Pandas 之上的框架,考虑了多处理和分布式处理。它利用了内存和磁盘上的 Pandas 数据框块集合。
SQL Alchemy 的 Pandas — 数据库 Pandas
Pandas 也建立在 SQLAlchemy 之上与数据库接口,因此能够从各种 SQL 类型的数据库中下载数据集,并将记录推送到数据库中。直接使用 SQLAlchemy 接口(而不是使用 Pandas API)可以执行 Pandas 中原生不支持的某些操作,如事务或 upserts。
SQL 事务
Pandas 也可以利用 SQL 事务,处理提交和回滚。Pedro Capelastegui 在他的 博客文章 中解释了 Pandas 如何通过 SQLAlchemy 上下文管理器利用事务。
with engine.begin() as conn:
df.to_sql(
tableName,
con=conn,
...
)
使用 SQL 事务的优点在于,如果数据加载失败,事务将会回滚。
SQL 扩展
PandaSQL
Pandas 有一些 SQL 扩展,如 pandasql 这个库允许在数据框上执行 SQL 查询。通过 pandasql,数据框对象可以像数据库表一样直接进行查询。

SQL UPSERTs
Pandas 本身不支持对支持此功能的数据库进行 upsert 导出。存在 Pandas 补丁 以实现此功能。
MatplotLib/Seaborn — 可视化 Pandas
Matplotlib 和 Seaborn 可视化已经集成在一些数据框 API 中,例如通过 .plot 命令。有关接口工作的相当全面的文档可以在 Pandas 网站 上找到。
扩展: 存在不同的扩展,如 Bokeh 和 plotly,以在 Jupyter notebooks 中提供交互式可视化,同时也可以扩展 matplotlib 以处理 3D 图形。
其他扩展
还有很多其他 Pandas 扩展,用于处理非核心功能。其中之一是 tqdm,它提供了进度条功能;另一个是 pretty Pandas,它允许格式化数据框并添加汇总信息。
tqdm
tqdm 是 Python 中的一个进度条扩展,它与 Pandas 互动,允许用户在使用相关函数(progress_map 和 progress_apply)时查看 Pandas 数据框的操作进度:

PrettyPandas
PrettyPandas 是一个库,提供了格式化数据框和添加表格摘要的简便方法:

个人简介:Julien Kervizic 是 GrandVision NV 的高级企业数据架构师。
原文。经授权转载。
相关:
-
Pandas 数据框索引
-
初学者使用 Pandas 的数据可视化与探索
-
Python 数据准备案例文件:基于分组的插补
我们的前 3 个课程推荐
 1. 谷歌网络安全证书 - 快速开启网络安全职业之路。
1. 谷歌网络安全证书 - 快速开启网络安全职业之路。
 2. 谷歌数据分析专业证书 - 提升你的数据分析能力
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
 3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
了解更多主题
数据科学中的概率分布
原文:
www.kdnuggets.com/2020/02/probability-distributions-data-science.html
评论
介绍
拥有扎实的统计学背景对于数据科学家的日常工作极为有益。每当我们开始探索一个新的数据集时,我们首先需要做一个探索性数据分析(EDA),以了解某些特征的主要特点。如果我们能够理解数据分布中是否存在任何模式,我们可以根据我们的案例研究量身定制机器学习模型。这样,我们可以在更短的时间内获得更好的结果(减少优化步骤)。实际上,一些机器学习模型在某些分布假设下效果最佳。因此,了解我们处理的是哪些分布,可以帮助我们识别出最适合的模型。
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速入门网络安全职业
1. 谷歌网络安全证书 - 快速入门网络安全职业
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
 3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
数据的不同类型
每次我们处理一个数据集时,我们的数据集代表了一个样本,来自于一个总体。利用这个样本,我们可以尝试理解其主要模式,从而在没有机会检查整个总体的情况下,对整个总体进行预测。
让我们假设我们想要预测给定一组特征的房价。我们可能会在线找到一个包含旧金山所有房价的数据集(我们的样本),经过一些统计分析后,我们可能能够对美国其他城市的房价做出相当准确的预测(我们的总体)。
数据集由两种主要类型的数据组成:数值型(例如,整数、浮点数)和类别型(例如,名字、笔记本电脑品牌)。
数值数据还可以进一步分为其他两个类别:离散和连续。离散数据只能取某些特定值(例如,学校中的学生数量),而连续数据可以取任何实际或分数值(例如,身高和体重)。
从离散随机变量可以计算出概率质量函数,而从连续随机变量可以推导出概率密度函数。
概率质量函数给出一个变量等于某个值的概率,而概率密度函数的值本身不是概率,因为它们需要在给定范围内积分。
自然界中存在许多不同的概率分布(图 1),在本文中,我将介绍数据科学中最常用的分布。

图 1: 概率分布流程图 [1]
在本文中,我将提供如何创建不同分布的代码片段。如果你对额外资源感兴趣,可以在 这个我的 GitHub 仓库中找到。
首先,我们需要导入所有必要的库:
伯努利分布
伯努利分布是最容易理解的分布之一,可以作为推导更复杂分布的起点。
该分布只有两个可能的结果和一个试验。
一个简单的例子是一次掷硬币的结果。如果硬币是偏向的或不偏向的,那么结果为正面或反面的概率可以分别视为p和**(1 - p)**(互斥事件的概率总和需要等于一)。
在图 2 中,我提供了一个关于偏向硬币的伯努利分布的例子。

图 2: 偏向硬币的伯努利分布
均匀分布
均匀分布可以很容易地从伯努利分布中推导出来。在这种情况下,允许有可能无限多的结果,并且所有事件发生的概率是相同的。
例如,假设掷一个公平的骰子。在这种情况下,有多个可能的事件,每个事件发生的概率相同。

图 3: 公平骰子的掷骰分布
二项分布
二项分布可以被认为是遵循伯努利分布的事件结果的总和。因此,二项分布用于二元结果事件,并且所有连续试验中的成功和失败的概率是相同的。该分布接受两个参数作为输入:事件发生的次数和分配给两个类别之一的概率。
二项分布的一个简单示例是重复掷某个次数的偏向或不偏向硬币。
改变偏向的量会改变分布的外观(图 4)。

图 4: 二项分布变化的事件发生概率
二项分布的主要特征包括:
-
在多次试验中,每次试验彼此独立(一个试验的结果不会影响另一个试验)。
-
每次试验只能有两个可能的结果(例如,赢或输),其概率分别为p和**(1 - p)**。
如果给定成功的概率(p)和试验次数(n),我们可以使用以下公式(见图 5)计算这些 n 次试验中成功的概率(x)。

图 5:二项分布公式 [2]
正态(高斯)分布
正态分布是数据科学中最常用的分布之一。许多发生在我们日常生活中的常见现象都遵循正态分布,例如:经济中的收入分布、学生的平均成绩、人口的平均身高等。此外,小随机变量的和通常也遵循正态分布(中心极限定理)。
“在概率论中,中心极限定理(CLT)表明,在某些情况下,当独立随机变量相加时,其适当标准化的和趋向于正态分布,即使原始变量本身并不服从正态分布。”
— 维基百科

图 6:高斯分布
一些可以帮助我们识别正态分布的特征包括:
-
曲线在中心对称。因此,均值、众数和中位数都相等,使得所有值围绕均值对称分布。
-
分布曲线下的面积等于 1(所有概率的总和必须等于 1)。
可以使用以下公式推导出正态分布(见图 7)。

图 7:正态分布公式 [3]
在使用正态分布时,分布的均值和标准差起着非常重要的作用。如果我们知道它们的值,就可以通过检查概率分布(见图 8)轻松找出预测确切值的概率。实际上,得益于分布的特性,68%的数据位于均值的一个标准差内,95%位于均值的两个标准差内,99.7%位于均值的三个标准差内。

图 8:正态分布 68–95–99.7 规则 [4]
许多机器学习模型被设计为在使用遵循正态分布的数据时表现最佳。以下是一些例子:
-
高斯朴素贝叶斯分类器
-
线性判别分析
-
二次判别分析
-
最小二乘回归模型
此外,在某些情况下,还可以通过应用对数和平方根等变换将非正态数据转换为正态形式。
泊松分布
泊松分布常用于找到某个事件发生的概率,或者在不知道事件发生频率的情况下预测事件发生的次数。此外,泊松分布还可以用于预测在给定时间段内事件发生的次数。
泊松分布,例如,常被保险公司用于进行风险分析(例如,预测在预定时间段内发生的车祸数量)以决定车险定价。
在处理泊松分布时,我们可以对不同事件发生的平均时间有信心,但事件发生的确切时刻在时间上是随机分布的。
泊松分布可以使用以下公式进行建模(图 9),其中λ代表在一个时间段内可以发生的预期事件数量。

图 9:泊松分布公式 [5]
描述泊松过程的主要特征是:
-
事件彼此独立(如果一个事件发生,这不会改变另一个事件发生的概率)。
-
事件可以在定义的时间段内发生任意次数。
-
两个事件不能同时发生。
-
事件发生的平均速率是恒定的。
在图 10 中,展示了在一个时间段内预期事件数量(λ)变化如何改变泊松分布。

图 10:泊松分布变化λ
指数分布
最后,指数分布用于建模不同事件发生之间的时间。
例如,假设我们在一家餐馆工作,我们想预测不同顾客到餐馆的时间间隔。使用指数分布来解决这个问题,可能是一个完美的起点。
指数分布的另一个常见应用是生存分析(例如,设备/机器的预期寿命)。
指数分布由一个参数λ控制。λ值越大,指数曲线衰减得越快(图 11)。

图 11:指数分布
指数分布使用以下公式进行建模(图 12)。

图 12:指数分布公式 [6]
如果你有兴趣调查概率分布如何用来解密随机过程,你可以在这里找到更多信息。
联系方式
如果你想随时了解我的最新文章和项目,请关注我的 Medium并订阅我的邮件列表。以下是我的一些联系方式:
参考书目
[1] 数据科学统计学简介。
Diogo Menezes Borges,《数据科学家的成长历程》。访问网址:medium.com/diogo-menezes-borges/introduction-to-statistics-for-data-science-7bf596237ac6
[2] 二项随机变量,UF 生物统计学开放学习教科书。访问网址:bolt.mph.ufl.edu/6050-6052/unit-3b/binomial-random-variables/
[3] 正态分布或钟形曲线公式。ThoughtCo,Courtney Taylor**。 **访问网址:www.thoughtco.com/normal-distribution-bell-curve-formula-3126278
[4] 解释正态分布的 68–95–99.7 规则。
Michael Galarnyk,Medium。访问网址:towardsdatascience.com/understanding-the-68-95-99-7-rule-for-a-normal-distribution-b7b7cbf760c2
[5] 正态分布、二项分布与泊松分布,Make Me Analyst。访问网址:makemeanalyst.com/wp-content/uploads/2017/05/Poisson-Distribution-Formula.png
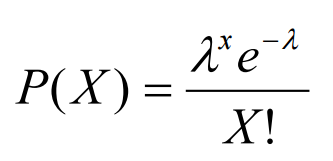{kind=link}
[6] 指数函数公式,&learning。访问网址:www.andlearning.org/exponential-formula/
简介: Pier Paolo Ippolito 是一名数据科学家,拥有南安普顿大学人工智能硕士学位。他对人工智能进展和机器学习应用(如金融和医学)有浓厚的兴趣。可以在 Linkedin 上与他联系。
原文。已获得许可转载。
相关:
-
什么是泊松分布?
-
如何优化你的 Jupyter Notebook
-
入门 R 编程
更多相关主题
概率:Statology 入门

作者提供的图片 | Midjourney & Canva
KDnuggets 的姐妹网站,Statology,拥有大量由专家撰写的统计学相关内容,这些内容在短短几年内积累而成。我们决定通过组织和分享一些精彩的教程,帮助读者了解这个出色的统计、数学、数据科学和编程资源,并与 KDnuggets 社区分享。
我们的前三个课程推荐
 1. Google 网络安全证书 - 快速入门网络安全职业。
1. Google 网络安全证书 - 快速入门网络安全职业。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
 3. Google IT 支持专业证书 - 支持你的组织的 IT
3. Google IT 支持专业证书 - 支持你的组织的 IT
学习统计学可能很困难。它可能让人沮丧。最重要的是,它可能让人困惑。这就是为什么Statology在这里提供帮助。
这个系列集中于介绍概率概念。如果你对概率不熟悉,或需要复习,这些教程系列非常适合你。试试看,并浏览 Statology 上的其他内容。
理论概率:定义 + 示例
概率是统计学中的一个主题,描述了某些事件发生的可能性。当我们谈论概率时,我们通常指的是两种类型之一。
你可以通过以下技巧来记住理论概率和实验概率之间的区别:
-
事件发生的理论概率可以通过数学理论来计算。
-
事件发生的实验概率可以通过直接观察实验结果来计算。
后验概率:定义 + 示例
后验概率是考虑到新信息后某个事件发生的更新概率。
例如,我们可能对某个事件“A”在考虑到刚刚发生的事件“B”之后的概率感兴趣。我们可以使用以下公式来计算这个后验概率:
P(A|B) = P(A) * P(B|A) / P(B)
如何解读赔率比
在统计学中,概率指的是某个事件发生的机会。它的计算方式是:
概率:
P(事件) = (# 可取结果)/ (# 可能结果)
例如,假设我们在一个袋子里有四个红球和一个绿球。如果你闭上眼睛随机抽取一个球,选择到绿球的概率计算为:
P(绿球) = 1 / 5 = 0.2。
大数法则:定义 + 示例
大数法则表示,随着样本大小的增加,样本均值会更接近于期望值。
这最基本的例子涉及掷硬币。每次我们掷硬币时,它正面朝上的概率是 1/2。因此,经过无限次掷硬币,正面出现的期望比例是 1/2 或 0.5。
集合操作:并集、交集、补集和差集
集合是项的集合。
我们用大写字母表示集合,并用花括号定义集合中的项。例如,假设我们有一个叫做“A”的集合,元素为 1, 2, 3。我们可以写作:
A = {1, 2, 3}
本教程解释了概率和统计中最常用的集合操作。
一般乘法规则(解释与示例)
一般乘法规则表示,任何两个事件 A 和 B 同时发生的概率可以计算为:
P(A 和 B) = P(A) * P(B|A)
竖线 | 表示“在给定的情况下”。因此,P(B|A) 可以读作“在 A 发生的情况下 B 发生的概率”。
如果事件 A 和 B 是独立的,那么 P(B|A) 简单等于 P(B),规则可以简化为:
P(A 和 B) = P(A) * P(B)
要获取更多类似的内容,请持续关注 Statology,并订阅他们的每周通讯,以确保您不会错过任何信息。
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的主编,以及 Machine Learning Mastery 的贡献编辑,Matthew 旨在让复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法和探索新兴的人工智能。他的使命是让数据科学社区中的知识民主化。Matthew 从 6 岁开始编程。
{kind=link}
更多相关主题
如何在几秒钟内处理数百万行的 DataFrame
原文:
www.kdnuggets.com/2022/01/process-dataframe-millions-rows-seconds.html

图片由 Jason Blackeye 提供,来源于 Unsplash
数据科学正在经历其复兴时刻。很难跟上所有可能改变数据科学工作方式的新工具。
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
 2. 谷歌数据分析专业证书 - 提升你的数据分析能力
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
 3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 部门
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 部门
我最近在与一位同事的交谈中了解到这个新的数据处理引擎,这位同事也是一名数据科学家。我们讨论了大数据处理,这是该领域创新的前沿,这个新工具就出现了。
尽管 pandas 是 Python 中数据处理的事实标准工具,但它并不适合处理大数据。对于更大的数据集,迟早会遇到内存溢出异常。
研究人员早在很久以前就面临了这个问题,这促使了像 Dask 和 Spark这样的工具的开发,它们试图通过将处理分布到多台机器上来克服“单机”限制。
这个活跃的创新领域也为我们带来了像 Vaex这样的工具,试图通过提高单机处理的内存效率来解决这个问题。
而且问题不仅仅于此。还有另一种大数据处理工具你应该了解……
认识 Terality

图片由 Frank McKenna 提供,来源于 Unsplash
Terality 是一个无服务器数据处理引擎,在云端处理数据。无需管理基础设施,因为 Terality 负责计算资源的扩展。其目标用户是工程师和数据科学家。
我与 Terality 团队交换了几封电子邮件,因为我对他们开发的工具感兴趣。他们迅速回复了。这些是我向团队提出的问题:

我给 Terality 团队发的第 n 封邮件(作者截图)
使用 Terality 进行数据处理的主要步骤是什么?
-
Terality 附带一个 Python 客户端,你可以将其导入到 Jupyter Notebook 中。
-
然后你以**“pandas 方式”**编写代码,Terality 安全地上传你的数据,并处理分布式计算(以及扩展)以计算你的分析。
-
处理完成后,你可以将数据转换回常规的 pandas DataFrame,并在本地继续分析。
幕后发生了什么?
Terality 团队开发了一个专有的数据处理引擎——它不是 Spark 或 Dask 的分支。
目标是避免 Dask 的缺陷,Dask 与 pandas 的语法不同,异步操作,未包含所有 pandas 函数,并且不支持自动扩展。
Terality 的数据处理引擎解决了这些问题。
Terality 是否可以免费使用?
Terality提供一个免费计划,允许你每月处理最多 500 GB 的数据。它还为需求更大的公司和个人提供付费计划。
在本文中,我们将重点关注免费计划,因为它适用于许多数据科学家。
Terality 如何计算数据使用量? (来自 Terality 的文档)
考虑一个总大小为 15GB 的数据集,如操作 df.memory_usage(deep=True).sum() 所返回的那样。
对该数据集执行一个(1)操作,例如 .sum 或 .sort_values,将消耗 Terality 中 15GB 的处理数据。
只有在任务运行成功状态下才会记录可计费使用量。
数据隐私如何?
当用户执行读取操作时,Terality 客户端将数据集复制到 Terality 在 Amazon S3 上的安全云存储中。
Terality 对数据隐私和保护有严格的政策。他们保证不会使用数据,并安全地处理数据。
Terality 不是存储解决方案。他们将在 Terality 客户端会话关闭后的最多 3 天内删除你的数据。
Terality 处理目前发生在 AWS 的法兰克福区域。
数据需要公开吗?
不!
用户需要访问本地计算机上的数据集,Terality 将在幕后处理上传过程。
上传操作也进行了并行处理,因此更快。
Terality 能处理大数据吗?
目前,在 2021 年 11 月, Terality 仍处于测试阶段。它优化了最多 100-200 GB 的数据集。
我询问了团队是否计划增加此功能,他们计划很快开始优化到 Terabytes 级别。
让我们试驾一下

由 尤金·赫斯季亚科夫 拍摄的照片,发布在 Unsplash 上
我惊讶于你可以简单地用 Terality 的包替换 pandas 的导入语句,然后重新运行你的分析。
请注意,一旦你导入了 Terality 的 Python 客户端,数据处理将不再在本地机器上进行,而是在 Terality 的云端数据处理引擎中完成。
现在,让我们安装 Terality 并在实践中尝试一下……
设置
你可以通过运行以下命令来安装 Terality:
pip install --upgrade terality
然后你在 Terality 上创建一个免费账户,并生成一个 API 密钥:

在 Terality 上生成新的 API 密钥(截图由作者提供)
最后一步是输入你的 API 密钥(同时用你的电子邮件替换电子邮件):
terality account configure --email your@email.com
让我们从小处开始……
现在,我们已经安装了 Terality,可以运行一个小示例来熟悉它。
实践表明,使用 Terality 和 pandas 两者结合,你可以充分发挥它们各自的优势——一个用于聚合数据,另一个则在本地分析聚合后的数据
以下命令通过导入 pandas.DataFrame 创建一个 terality.DataFrame:
**import** **pandas** **as** **pd**
**import** **terality** **as** **te**df_pd = pd.DataFrame({
"col1": [1, 2, 2], "col2": [4, 5, 6]})
df_te = te.DataFrame.from_pandas(df_pd)
现在,数据已经在 Terality 的云端,我们可以继续进行分析:
df_te.col1.value_counts()
运行过滤操作和其他熟悉的 pandas 操作:
df_te[(df_te["col1"] >= 2)]
一旦我们完成分析,可以使用以下命令将其转换回 pandas DataFrame:
df_pd_roundtrip = df_te.to_pandas()
我们可以验证 DataFrames 是否相等:
pd.testing.assert_frame_equal(df_pd, df_pd_roundtrip)
让我们搞大点……
我建议你查看 Terality 的快速入门 Jupyter Notebook, 其中介绍了 40 GB Reddit 评论数据集的分析。他们还有一个包含 5 GB 数据集的小型教程。
我点击了 Terality 的 Jupyter Notebook 并处理了 40 GB 的数据集。它在 45 秒内读取了数据,并花费了 35 秒进行排序。与另一个表的合并花费了 1 分钟 17 秒。感觉就像在我的笔记本电脑上处理一个更小的数据集。
然后我尝试在我的笔记本电脑(配备 16 GB 主内存)上用 pandas 加载相同的 40GB 数据集——结果返回了内存不足的异常。
官方 Terality 教程带你分析一个包含 Reddit 评论的 5GB 文件。
结论

照片由 Sven Scheuermeier 拍摄,来源于 Unsplash
我尝试了 Terality,并且我的体验没有遇到重大问题。这让我感到惊讶,因为它们官方仍在测试阶段。另一个好兆头是他们的支持团队非常响应迅速。
当你有一个大型数据集无法在本地机器上处理时,我认为 Terality 的应用场景非常出色——无论是因为内存限制还是处理速度。
使用 Dask(或 Spark)需要启动一个集群,这样的成本远高于使用 Terality 完成分析的成本。
此外,配置这样一个集群是一个繁琐的过程,而使用 Terality 你只需要更改导入语句。
我喜欢的另一点是我可以在本地 JupyterLab 中使用它,因为我有许多扩展、配置、深色模式等。
我期待着团队在接下来的几个月中取得的 Terality 进展。
Roman Orac 是一位机器学习工程师,在改进文档分类和项目推荐系统方面取得了显著成功。Roman 具有管理团队、指导初学者和向非工程师解释复杂概念的经验。
原文。经许可转载。
了解更多相关主题
使用 R 进行过程挖掘:介绍
原文:
www.kdnuggets.com/2017/11/process-mining-r-introduction.html/2
然后,我们可以从这些信息创建一个 igraph 对象,并导出它以使用 Graphviz 渲染,从而得到以下过程图(片段):

我们的前 3 个课程推荐
 1. Google 网络安全证书 - 进军网络安全事业快速通道
1. Google 网络安全证书 - 进军网络安全事业快速通道
 2. Google 数据分析专业证书 - 提升数据分析能力
2. Google 数据分析专业证书 - 提升数据分析能力
 3. Google IT 支持专业证书 - 在 IT 方面支持您的组织
3. Google IT 支持专业证书 - 在 IT 方面支持您的组织
现在,我们可以进一步扩展这个基本框架,并将其与预测性和描述性分析模型合并。一些实验的想法包括:
-
筛选事件日志和流程图,只显示高频行为
-
尝试不同的着色方式,例如不基于频率或性能,而是其他有趣的数据属性
-
扩展框架以包括基本的符合性检查,例如通过突出显示偏差流程
-
将决策挖掘(或概率度量)应用于分流,以预测将遵循哪些路径
现在,我们来应用一个简单的扩展:假设我们对“分析报价请求”活动感兴趣,并希望带入一些与该活动相关的更多信息,例如资源属性,即执行该活动的人员。
因此,我们使用频率计数构建了两个新的数据框,将频率计数作为我们感兴趣的指标:
col.box.blue <- colorRampPalette(c('#DBD8E0', '#014477'))(20)
col.arc.blue <- colorRampPalette(c('#938D8D', '#292929'))(20)
activities.counts <- activities.basic %>%
select(act) %>%
group_by_all %>%
summarize(metric=n()) %>%
ungroup %>%
mutate(fillcolor=col.box.blue[floor(linMap(metric, 1,20))])
edges.counts <- edges.basic %>%
select(a.act, b.act) %>%
group_by_all %>%
summarize(metric=n()) %>%
ungroup %>%
mutate(color=col.arc.blue[floor(linMap(metric, 1,20))],
penwidth=floor(linMap(metric, 1, 5)),
metric.char=as.character(metric))
接下来,我们筛选我们感兴趣的活动的事件日志,计算持续时间,然后为每个执行此活动的资源-活动对计算频率和性能指标。
acts.res <- eventlog %>%
filter(Activity == "Analyze Request for Quotation") %>%
mutate(Duration=Complete-Start) %>%
select(Duration, Resource, Activity) %>%
group_by(Resource, Activity) %>%
summarize(metric.freq=n(), metric.perf=median(Duration)) %>%
ungroup %>%
mutate(color='#75B779',
penwidth=1,
metric.char=formatSeconds(as.numeric(metric.perf)))
在这里使用的一个有用的 igraph 函数是“graph_from_data_frame”。此函数期望一个顶点的数据框(除了第一列以外的所有列自动充当属性),并期望一个边的数据框(除了前两列以外的所有列自动充当属性)。因此,我们构造了最终的顶点(活动)数据框如下所示。填充颜色基于节点是否表示一个活动(我们使用上面设置的颜色)或一个资源(我们使用绿色):
a <- bind_rows(activities.counts %>% select(name=act, metric=metric) %>%
mutate(type='Activity'),
acts.res %>% select(name=Resource, metric=metric.freq) %>%
mutate(type='Resource')) %>%
distinct %>%
rowwise %>%
mutate(fontsize=8,
fontname='Arial',
label=paste(name, metric, sep='\n'),
shape=ifelse(type == 'Activity', 'box', 'ellipse'),
style=ifelse(type == 'Activity', 'rounded,filled', 'solid,filled'),
fillcolor=ifelse(type == 'Activity',
activities.counts[activities.counts$act==name,]$fillcolor, '#75B779'))
And construct a data frame for the edges as well:
e <- bind_rows(edges.counts,
acts.res %>% select(a.act=Resource, b.act=Activity, metric.char, color, penwidth)) %>%
rename(label=metric.char) %>%
mutate(fontsize=8, fontname='Arial')
Finally, we can construct an igraph object as follows:
gh <- graph_from_data_frame(e, vertices=a, directed=T)
导出和绘制此对象后,我们看到所有三个资源都对我们的活动的执行做出了相同的贡献,它们的中位执行时间(显示在绿色弧上)也相似:

当然,我们现在已经有一个强大的框架,可以从中开始创建更丰富的过程图,并嵌入更多注释和信息。
在这篇文章中,我们提供了一个快速的旋风之旅,介绍了如何使用 R 创建丰富的流程图。正如所见,这在典型的流程发现工具不可用的情况下可能非常有用,同时还提供了关于如何将典型的流程挖掘任务与其他与数据挖掘相关的任务进行增强或更容易组合的提示。希望您喜欢阅读这篇文章,并迫不及待地想看看您会如何处理您的事件日志。
更多阅读:
-
vanden Broucke S., Vanthienen J., Baesens B. (2013). Volvo IT 比利时 VINST. 第 3 届业务流程智能挑战赛论文集合,与第 9 届国际业务流程智能研讨会(BPI 2013)共同举办。北京(中国),2013 年 8 月 26 日(编号 3)。亚琛(德国):亚琛工业大学。
ceur-ws.org/Vol-1052/paper3.pdf
个人简介:Seppe vanden Broucke 是比利时鲁汶大学经济与商业学院的助理教授。他的研究兴趣包括商业数据挖掘和分析、机器学习、流程管理和流程挖掘。他的工作已发表在知名国际期刊上,并在顶级会议上做过报告。Seppe 的教学包括高级分析、大数据和信息管理课程。他还经常为行业和企业的听众进行教学。
相关文章:
-
流程挖掘中的隐私、安全性和伦理
-
流程挖掘:数据科学与流程科学的交叉点
-
通过统计模型改进您的流程
关于这个话题的更多内容
生产机器学习监控:异常值、漂移、解释器与统计性能
评论
由亚历杭德罗·索塞多,Seldon 的工程总监

作者提供的图像
“机器学习模型的生命周期只有在生产环境中开始”
在本文中,我们展示了一个端到端的示例,展示了生产中机器学习模型监控的最佳实践、原则、模式和技术。我们将展示如何将标准的微服务监控技术适应于已部署的机器学习模型,以及更高级的范式,包括概念漂移、异常检测和人工智能解释。
我们将从头开始训练一个图像分类机器学习模型,将其作为微服务部署在 Kubernetes 中,并引入广泛的高级监控组件。这些监控组件将包括异常检测器、漂移检测器、AI 解释器和指标服务器——我们将涵盖每个组件的底层架构模式,这些模式考虑了规模的需求,并设计为在数百或数千个异构机器学习模型中高效工作。
你还可以以视频形式查看这篇博客文章,该视频作为 PyCon 香港 2020 的主题演讲——主要的区别在于演讲使用了 Iris Sklearn 模型作为端到端示例,而不是 CIFAR10 Tensorflow 模型。
端到端机器学习监控示例
在本文中,我们展示了一个端到端的实际示例,涵盖了下面部分中概述的每个高级概念。
-
复杂机器学习系统监控介绍
-
CIFAR10 Tensorflow Renset32 模型训练
-
模型打包与部署
-
性能监控
-
事件基础设施监控
-
统计监控
-
异常检测监控
-
概念漂移监控
-
解释性监控
在本教程中,我们将使用以下开源框架:
-
Tensorflow — 广泛使用的机器学习框架。
-
Alibi Explain — 白盒和黑盒机器学习模型解释库。
-
Albi Detect — 先进的机器学习监控算法,用于概念漂移、异常检测和对抗性检测。
-
Seldon Core — 机器学习模型的部署与编排及监控组件。
你可以在 提供的 jupyter notebook 中找到本文的完整代码,这将允许你运行模型监控生命周期中的所有相关步骤。
让我们开始吧。
1. 复杂机器学习系统监控简介
生产机器学习的监控很困难,而且随着模型数量和高级监控组件的增加,复杂性呈指数级增长。这部分是因为生产机器学习系统与传统的软件微服务系统的差异——以下概述了一些关键差异。

作者提供的图像
-
专用硬件 — 优化的机器学习算法实现通常需要访问 GPU、更大的 RAM、专用的 TPU/FPGAs 以及其他动态变化的需求。这导致需要特定的配置,以确保这些专用硬件可以产生准确的使用指标,更重要的是,这些指标可以与相应的底层算法关联。
-
复杂的依赖图 — 工具和基础数据涉及复杂的依赖关系,这些关系可能跨越复杂的图结构。这意味着处理单个数据点可能需要在多个跳跃之间进行状态评估,这可能会引入额外的领域特定抽象层,需要在可靠解读监控状态时考虑。
-
合规要求 — 生产系统,特别是在高度监管的环境中,可能涉及复杂的审计政策、数据要求以及在每个执行阶段收集资源和文档的要求。有时,显示和分析的指标必须根据指定的政策限制给相关人员,这些政策的复杂性可能因用例而异。
-
可重复性 — 除了这些复杂的技术要求外,还需要组件的可重复性,确保运行的组件可以在另一个时间点以相同的结果执行。对于监控系统,重要的是系统在设计时考虑到这一点,以便能够重新运行特定的机器学习执行,以重现特定的指标,无论是用于监控还是审计目的。
生产机器学习的构造涉及多阶段模型生命周期中的广泛复杂性。这包括实验、评分、超参数调整、服务、离线批处理、流处理等。每个阶段可能涉及不同的系统和各种异质工具。因此,确保我们不仅学习如何引入特定于模型的指标进行监控,而且要识别可以用于在规模上有效监控部署模型的更高级别的架构模式,这一点至关重要。这是我们在下面每个部分中将要覆盖的内容。
2. CIFAR10 Tensorflow Resnet32 模型训练

来自开源的CIFAR10 数据集的图像
我们将使用直观的CIFAR10 数据集。这个数据集包含的图像可以被分类为 10 个类别之一。模型将以形状为 32x32x3 的数组作为输入,并以一个包含 10 个概率的数组作为输出,表示该图像属于哪个类别。
我们能够从 Tensorflow 数据集中加载数据——即:
10 个类别包括:cifar_classes = [“airplane”, “automobile”, “bird”, “cat”, “deer”, “dog”, “frog”, “horse”, “ship”, “truck”]。
为了训练和部署我们的机器学习模型,我们将遵循下图所示的传统机器学习工作流程。我们将训练一个模型,然后可以将其导出和部署。

我们将使用 Tensorflow 来训练这个模型,利用Residual Network,这无疑是最具突破性的架构之一,因为它使得训练多达数百甚至上千层的网络成为可能,并且性能良好。在这个教程中,我们将使用 Resnet32 实现,幸运的是,我们可以通过 Alibi Detect 包提供的工具使用它。
使用我的 GPU,这个模型训练了大约 5 小时,幸运的是,我们可以使用通过 Alibi Detect fetch_tf_model工具检索的预训练模型。
如果你仍然想训练 CIFAR10 resnet32 tensorflow 模型,你可以使用 Alibi Detect 包提供的辅助工具,如下所述,或者直接导入原始网络并自行训练。
我们现在可以在“未见数据”上测试训练好的模型。我们可以使用一个被分类为卡车的 CIFAR10 数据点来测试它。我们可以通过 Matplotlib 绘制数据点来查看。

我们现在可以通过模型处理该数据点,你可以想象它应该被预测为“卡车”。
我们可以通过找到概率最高的索引来确定预测的类别,在这种情况下,它是index 9,概率为 99%。从类别名称(例如cifar_classes[ np.argmax( X_curr_pred )])可以看出,第 9 类是“卡车”。
3. 打包与部署模型
我们将使用 Seldon Core 将模型部署到 Kubernetes 中,它提供了多种选项将我们的模型转换为一个完全成熟的微服务,暴露 REST、GRPC 和 Kafka 接口。
我们在使用 Seldon Core 部署模型时的选项包括 1) 使用语言封装来部署我们的 Python、Java、R 等代码类,或 2) 使用预打包模型服务器直接部署模型工件。在本教程中,我们将使用Tensorflow 预打包模型服务器来部署我们之前使用的 Resnet32 模型。
这种方法将使我们能够利用 Kubernetes 的云原生架构,它通过水平可扩展的基础设施支持大规模微服务系统。在本教程中,我们将深入了解和利用应用于机器学习的云原生和微服务模式。
下面的图表总结了部署模型工件或代码本身的选项,以及我们可以选择部署单个模型或构建复杂的推理图的能力。

顺便提一下,您可以使用KIND(Kubernetes in Docker)或Minikube等开发环境在 Kubernetes 上进行设置,然后按照此示例的笔记本或Seldon 文档中的说明进行操作。您需要确保安装 Seldon,并配置相应的 Ingress 提供者,如 Istio 或 Ambassador,以便发送 REST 请求。
为了简化教程,我们已经上传了训练好的 Tensorflow Resnet32 模型,可以在这个公共 Google 桶中找到:gs://seldon-models/tfserving/cifar10/resnet32。如果您已经训练了自己的模型,可以将其上传到您选择的桶中,可以是 Google 桶、Azure、S3 或本地 Minio。对于 Google,您可以使用下面的gsutil命令行进行操作:
我们可以使用 Seldon 通过自定义资源定义配置文件部署模型。下面是将模型工件转换为完全成熟的微服务的脚本。
现在我们可以看到模型已经部署并正在运行。
$ kubectl get pods | grep cifarcifar10-default-0-resnet32-6dc5f5777-sq765 2/2 Running 0 4m50s
现在我们可以通过发送相同的卡车图像来测试已部署的模型,看看我们是否仍然得到相同的预测。

数据点通过plt.imshow(X_curr[0])显示
我们可以通过发送如下所述的 REST 请求来实现,然后打印结果。
上述代码的输出是对 Seldon Core 提供的 URL 的 POST 请求的 JSON 响应。我们可以看到预测正确地结果为“卡车”类别。
{
'predictions': [[1.26448288e-06, 4.88144e-09, 1.51532642e-09, 8.49054249e-09, 5.51306611e-10, 1.16171261e-09, 5.77286274e-10, 2.88394716e-07, 0.00061489339, 0.999383569]]}
Prediction: truck
4. 性能监控
我们将涵盖的第一个监控支柱是传统的性能监控,这是你在微服务和基础设施领域中会找到的传统和标准监控功能。当然,在我们的案例中,我们将其应用于已部署的机器学习模型。
一些机器学习监控的高级原则包括:
-
监控运行中的 ML 服务性能
-
识别潜在瓶颈或运行时警告
-
调试和诊断 ML 服务的意外性能
为此,我们将介绍在生产系统中常用的前两个核心框架:
-
Elasticsearch 用于日志——一个文档键值存储系统,通常用于存储容器的日志,这些日志可以用于通过堆栈跟踪或信息日志诊断错误。在机器学习的情况下,我们不仅用它来存储日志,还用来存储机器学习模型的预处理输入和输出,以便进一步处理。
-
Prometheus 用于指标——一个时间序列存储系统,通常用于存储实时指标数据,然后可以利用像 Grafana 这样的工具进行可视化。
Seldon Core 为任何已部署的模型提供了开箱即用的 Prometheus 和 Elasticsearch 集成。在本教程中,我们将参考 Elasticsearch,但为了简化对几个高级监控概念的直观理解,我们将主要使用 Prometheus 进行指标和 Grafana 进行可视化。
在下图中,你可以看到导出的微服务如何使任何容器化的模型能够导出指标和日志。指标由 Prometheus 抓取,日志由模型转发到 Elasticsearch(通过我们在下一部分中介绍的事件基础设施进行)。值得明确的是,Seldon Core 还支持使用 Jaeger 的 Open Tracing 指标,显示了 Seldon Core 模型图中所有微服务跳跃的延迟。

作者提供的图片
一些由 Seldon Core 模型暴露的性能监控指标示例,也可以通过进一步集成添加:
-
每秒请求数
-
每个请求的延迟
-
CPU/内存/数据利用率
-
自定义应用指标
在本教程中,你可以使用Seldon Core Analytics 包来设置 Prometheus 和 Grafana,该包会设置一切,以便实时收集指标,然后在仪表板上进行可视化。
我们现在可以可视化部署模型相对于其特定基础设施的利用率指标。使用 Seldon 部署模型时,你需要考虑多个属性,以确保模型的最佳处理。这包括分配的 CPU、内存和为应用程序保留的文件系统存储,还包括相应的配置,用于相对于分配的资源和预期请求运行进程和线程。

图片来源:作者
同样,我们也能够监控模型本身的使用情况——每个 Seldon 模型都暴露模型使用指标,如每秒请求数、每个请求的延迟、模型的成功/错误代码等。这些指标很重要,因为它们能够映射到底层机器学习模型的更高级/专用概念。大的延迟峰值可以根据模型的底层需求进行诊断和解释。模型显示的错误也被抽象成简单的 HTTP 错误代码,这有助于将先进的机器学习组件标准化为微服务模式,从而使 DevOps / IT 管理人员更容易大规模管理。

图片来源:作者
5. 监控的事件基础设施
为了能够利用更高级的监控技术,我们将首先简要介绍事件基础设施,这使得 Seldon 可以使用先进的机器学习算法进行异步数据监控,并在可扩展的架构中运行。
Seldon Core 利用KNative Eventing来使机器学习模型能够将模型的输入和输出转发到更高级的机器学习监控组件,如异常检测器、概念漂移检测器等。

我们不会详细介绍 KNative 引入的事件基础设施,但如果你感兴趣,Seldon Core 文档中有多个实际示例,展示了如何利用 KNative 事件基础设施将有效负载转发到进一步的组件如 Elasticsearch,以及 Seldon 模型如何连接到处理事件。
对于本教程,我们需要使模型能够将所有处理过的负载输入和输出转发到 KNative Eventing 代理,这将使所有其他高级监控组件能够订阅这些事件。
下面的代码向部署配置中添加了一个“logger”属性,用于指定代理位置。
6. 统计监控
性能指标对于微服务的常规监控是有用的,然而对于机器学习的专业领域,有一些广为人知和广泛使用的指标在模型生命周期的训练阶段之外都至关重要。更常见的指标包括准确率、精确度、召回率,但也包括像均方根误差、KL 散度等更多指标。
本文的核心主题不仅仅是指定如何计算这些指标,因为通过一些 Flask 包装魔法使单个微服务暴露这些指标并不是一项艰巨的任务。关键在于识别可以在数百或数千个模型中引入的可扩展架构模式。这意味着我们需要对接口和模式进行一定程度的标准化,以便将模型映射到相关基础设施中。
一些高级原则围绕更专业的机器学习指标,如下所示:
-
针对统计机器学习性能的监控
-
基准测试多个不同模型或不同版本
-
针对数据类型和输入/输出格式的专业化
-
有状态的异步“反馈”提供(如“注释”或“修正”)
鉴于这些需求,Seldon Core 引入了一套架构模式,允许我们引入“可扩展指标服务器”的概念。这些指标服务器包含现成的处理模型处理数据的方法,通过订阅相应的事件主题,最终暴露出如下一些指标:
-
原始指标:真正例、假负例、假正例、真正负例
-
基本指标:准确率、精确度、召回率、特异性
-
专业指标:KL 散度、均方根误差等
-
按类别、特征和其他元数据的细分

作者提供的图像
从架构的角度来看,这可以通过上面的图示更加直观地展示。这展示了如何通过模型提交单个数据点,然后由任何相应的指标服务器处理。指标服务器还可以在提供“正确/注释”标签后处理这些标签,这些标签可以与 Seldon Core 在每个请求中添加的唯一预测 ID 关联。通过从 Elasticsearch 存储中提取相关数据来计算和暴露专业指标。
目前,Seldon Core 提供了一套开箱即用的 Metrics Servers:
-
BinaryClassification — 处理以二元分类形式出现的数据(例如 0 或 1),以暴露原始指标以显示基本统计指标(准确率、精确度、召回率和特异性)。
-
MultiClassOneHot — 处理以 one hot 预测形式出现的数据用于分类任务(例如[0, 0, 1]或[0, 0.2, 0.8]),然后可以暴露原始指标以显示基本统计指标。
-
MultiClassNumeric — 处理分类任务中以数值数据点形式出现的数据(例如 1,或[1]),然后可以暴露原始指标以显示基本统计指标。
在这个示例中,我们将能够部署一个类型为“MulticlassOneHot”的 Metric Server——你可以在下面总结的代码中看到使用的参数,但完整的 YAML 文件可以在 jupyter notebook 中找到。
一旦我们部署了我们的指标服务器,现在我们只需通过相同的微服务端点向我们的 CIFAR10 模型发送请求和反馈。为了简化工作流程,我们将不发送异步反馈(这会与 elasticsearch 数据进行比较),而是发送“自包含”的反馈请求,其中包含推断“响应”和推断“真实值”。
以下函数为我们提供了一种发送大量反馈请求的方法,以获得我们用例的大致准确率(正确预测与错误预测的数量)。
现在我们可以首先发送反馈以获得 90%的准确率,然后为了确保我们的图表看起来漂亮,我们可以发送另一批请求,这将导致 40%的准确率。
这基本上赋予我们实时可视化 MetricsServer 计算的指标的能力。

作者提供的图片
从上面的仪表板中,我们可以对通过这种架构模式能够获得的指标类型有一个高层次的直觉。上述状态统计指标特别需要异步提供额外的元数据,然而,即使指标本身的计算方法可能非常不同,我们可以看到基础设施和架构要求可以被抽象和标准化,以便这些指标能够以更可扩展的方式处理。
随着我们深入研究更高级的统计监控技术,我们将继续看到这种模式。
7. 异常检测监控
对于更高级的监控技术,我们将利用 Alibi Detect 库,特别是它提供的一些高级异常检测算法。Seldon Core 为我们提供了一种将异常检测器作为架构模式进行部署的方法,还为我们提供了一个经过优化的预打包服务器,以服务 Alibi Detect 异常检测模型。
异常检测的一些关键原则包括:
-
检测数据实例中的异常
-
当出现异常值时进行标记/警报
-
识别可能有助于诊断异常值的潜在元数据
-
启用对已识别异常值的深入分析
-
启用检测器的持续/自动化再训练
对于异常值检测器,尤其重要的是允许计算在模型之外进行,因为这些计算通常比较重,并且可能需要更多专业化的组件。已部署的异常值检测器可能会带来与机器学习模型类似的复杂性,因此在这些高级组件中覆盖相同的合规性、治理和血统概念是很重要的。
下图展示了模型如何通过事件基础设施转发请求。异常值检测器随后处理数据点,以计算其是否为异常值。该组件能够将异常值数据异步存储在相应的请求条目中,或者它能够将指标暴露给 Prometheus,这也是我们在本节中将要可视化的内容。

作者提供的图像
在本示例中,我们将使用Alibi Detect 变分自编码器异常值检测器技术。异常值检测器在一批未标记但正常(内点)数据上进行训练。VAE 检测器尝试重建其接收到的输入数据,如果输入数据无法被很好地重建,则会被标记为异常值。
Alibi Detect 提供了允许我们从零开始导出异常值检测器的工具。我们可以使用fetch_detector函数来获取它。
如果你想训练异常值检测器,可以通过简单地利用OutlierVAE类及其相应的编码器和解码器来实现。
为了测试异常值检测器,我们可以拍摄相同的卡车图像,并观察如果在图像中逐渐添加噪声,异常值检测器的表现如何。我们还可以使用 Alibi Detect 可视化函数plot_feature_outlier_image来绘制这些结果。
我们可以创建一组修改过的图像,并通过以下代码将其传递给异常值检测器。
我们现在在变量all_X_mask中拥有一组修改过的样本,每个样本都带有逐渐增加的噪声。我们现在可以将这 10 个样本全部通过异常值检测器进行检测。
在查看结果时,我们可以看到前 3 个数据点没有被标记为异常值,而其余的数据点被标记为异常值——我们可以通过打印值print(od_preds[“data”][“is_outlier”])来查看这一点。该命令会显示如下数组,其中 0 表示非异常值,1 表示异常值。
array([0, 0, 0, 1, 1, 1, 1, 1, 1, 1])
我们现在可以可视化异常值实例级别的评分如何与阈值映射,这反映了上述数组中的结果。

同样,我们可以深入了解异常值检测器评分通道的直观感受,以及重建的图像,这应能清晰地展示其内部操作方式。

我们现在可以将异常值检测器投入生产。我们将利用与指标服务器类似的架构模式,即 Alibi Detect Seldon Core 服务器,它将监听数据的推理输入/输出。每个通过模型的数据点,相关的异常值检测器将能够处理它。
主要步骤是首先确保我们上面训练的异常值检测器已上传到 Google 桶等对象存储中。我们已经将其上传到 gs://seldon-models/alibi-detect/od/OutlierVAE/cifar10,但如果你愿意,可以上传并使用自己的模型。
一旦我们部署了异常值检测器,我们将能够发送大量请求,其中许多将是异常值,其他的则不是。
我们现在可以在仪表盘上可视化一些异常值——每个数据点都会有一个新的入口,并包括它是否为异常值。

图片由作者提供
8. 漂移监测
随着时间的推移,实际生产环境中的数据可能会发生变化。虽然这种变化不是剧烈的,但可以通过数据分布的漂移来识别,尤其是在模型预测输出方面。
漂移检测的关键原则包括:
-
识别数据分布中的漂移,以及模型输入和输出数据之间关系的漂移。
-
标记出找到的漂移以及发现漂移时的相关数据点
-
允许深入查看用于计算漂移的数据
在漂移检测的概念中,与异常值检测用例相比,我们面临进一步的复杂性。主要是需要对每个漂移预测进行批量输入,而不是单个数据点。下图展示了与异常值检测器模式类似的工作流程,主要区别在于它保持一个滚动窗口或滑动窗口来进行处理。

图片由作者提供
在这个例子中,我们将再次使用 Alibi Detect 库,它为我们提供了 Kolmogorov-Smirnov 数据漂移检测器用于 CIFAR-10。
对于这种技术,将能够使用 KSDrift 类来创建和训练漂移检测器,这还需要一个使用“未训练自编码器 (UAE)”的预处理步骤。
为了测试异常检测器,我们将生成一组带有损坏数据的检测器。Alibi Detect 提供了一套很好的工具,我们可以用来以逐渐增加的方式生成图像的损坏/噪声。在这种情况下,我们将使用以下噪声:[‘gaussian_noise’, ‘motion_blur’, ‘brightness’, ‘pixelate’]。这些将使用下面的代码生成。
以下是一个来自创建的损坏数据集的数据点,其中包含上述不同类型的逐渐增加的损坏图像。

我们现在可以尝试运行一些数据点以计算是否检测到漂移。初始批次将由来自原始数据集的数据点组成。
这会如预期输出:漂移?没有!
类似地,我们可以在损坏的数据集上运行它。
我们可以看到所有请求都被标记为漂移,如预期的那样:
Corruption type: gaussian_noise
Drift? Yes!
Corruption type: motion_blur
Drift? Yes!
Corruption type: brightness
Drift? Yes!
Corruption type: pixelate
Drift? Yes!
部署漂移检测器
现在我们可以按照上述架构模式部署我们的漂移检测器。与异常检测器类似,我们首先必须确保我们训练的漂移检测器可以上传到对象存储。我们目前可以使用我们准备好的 Google 存储桶 gs://seldon-models/alibi-detect/cd/ks/drift 进行部署。
这将具有类似的结构,主要区别是我们还将指定 Alibi Detect 服务器使用的所需批量大小,以便在运行模型之前作为缓冲。在这种情况下,我们选择批量大小为 1000。
现在我们已经部署了异常检测器,首先尝试从正常数据集中发送 1000 个请求。
接下来我们可以发送损坏的数据,这将在发送 10k 数据点后导致检测到漂移。
我们可以在 Grafana 仪表盘上可视化检测到的不同漂移点。

作者提供的图像
9. 可解释性监控
人工智能可解释性技术对于理解复杂的黑箱机器学习模型的行为至关重要。当前的重点是提供对可解释组件可以大规模部署的架构模式的直观理解和实际示例。模型可解释性的关键原则包括:
-
对模型行为进行人类可解释的洞察
-
引入特定用例的可解释性功能
-
识别关键指标,例如信任评分或统计性能阈值
-
启用使用一些更复杂的机器学习技术
关于可解释性有广泛的不同技术,但理解不同类型的解释器的高层主题很重要。这些包括:
-
范围(本地 vs 全局)
-
模型类型(黑箱 vs 白箱)
-
任务(分类、回归等)
-
数据类型(表格、图像、文本等)
-
洞察(特征归因、对比事实、影响训练实例等)
作为接口的解释器在数据流模式上有相似之处。即许多解释器需要与模型处理的数据进行互动,并且能够与模型本身进行互动——对于黑箱技术,这包括输入/输出,而对于白箱技术,则包括模型本身的内部。

图片由作者提供
从架构的角度来看,这主要涉及一个独立的微服务,该服务不仅接收推断请求,还能够与相关模型互动,通过发送相关数据“反向工程”模型。这在上面的图示中有所展示,但一旦我们深入到示例中,这将变得更加直观。
对于这个示例,我们将使用 Alibi Explain 框架,并使用Anchor Explanation技术。该本地解释技术告诉我们在特定数据点中具有最高预测能力的特征。
我们可以简单地通过指定数据集的结构以及一个允许解释器与模型的预测功能互动的lambda来创建我们的 Anchor 解释器。
我们能够识别模型中在此案例中预测图像的锚点。

我们可以通过显示解释本身的输出锚点来可视化锚点。
我们可以看到图像的锚点包括卡车的挡风玻璃和轮子。

在这里,您可以看到解释器与我们部署的模型互动。在部署解释器时,我们将遵循相同的原则,但与使用在本地运行模型的lambda不同,这将是一个调用远程模型微服务的函数。
我们将采用类似的方法,只需将上面的图像上传到对象存储桶。与之前的示例类似,我们提供了一个存储桶,路径为gs://seldon-models/tfserving/cifar10/explainer-py36–0.5.2。我们现在可以部署一个解释器,该解释器可以作为 Seldon 部署的 CRD 部分进行部署。
我们可以通过运行kubectl get pods | grep cifar来检查解释器是否正在运行,这应当会输出两个正在运行的 pod:
cifar10-default-0-resnet32-6dc5f5777-sq765 2/2 Running 0 18m
cifar10-default-explainer-56cd6c76cd-mwjcp 1/1 Running 0 5m3s
类似于我们向模型发送请求的方式,我们也能够向解释器路径发送请求。在这里,解释器将与模型本身互动,并打印出反向工程的解释。
我们可以看到解释的输出与我们上面看到的一样。

最后,我们还可以看到一些来自解释器本身的与指标相关的组件,这些组件可以通过仪表板进行可视化。
Coverage: 0.2475
Precision: 1.0
与其他基于微服务的机器学习组件类似,解释器也可以暴露这些和其他更专业的性能或高级监控指标。
结束语
在总结之前,需要指出的是将这些高级机器学习概念抽象为标准化架构模式的重要性。这样做的原因主要是为了使机器学习系统具备规模化的能力,同时也便于在整个技术栈中进行高级组件的集成。
上述提到的所有高级架构不仅适用于各个高级组件,而且还可以启用我们可以称之为“集成模式”的功能——即将高级组件连接到其他高级组件的输出上。

作者提供的图片
还需要确保结构化和标准化的架构模式,使开发人员能够提供监控组件,这些组件也是高级机器学习模型,具备与之管理风险所需的治理、合规性和追溯相同的水平。
这些模式通过 Seldon Core 项目不断被优化和发展,前沿的异常检测、概念漂移、可解释性等算法也在不断改进——如果你对进一步讨论感兴趣,请随时联系。此教程中的所有示例都是开源的,欢迎提出建议。
如果你对机器学习模型的可扩展部署策略的更多实际示例感兴趣,你可以查看:
个人简介:Alejandro Saucedo 是 Seldon 的工程总监、The Institute for Ethical AI 的首席科学家,以及 ACM 委员会成员。
原文。经许可转载。
相关:
-
可解释性、可说明性与机器学习——数据科学家需要了解的内容
-
使用 TensorFlow Serving 部署训练好的模型到生产环境
-
AI 不仅仅是一个模型:实现完整工作流成功的四个步骤
我们的三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
 3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
相关主题
生产就绪的机器学习 NLP API,使用 FastAPI 和 spaCy
原文:
www.kdnuggets.com/2021/04/production-ready-machine-learning-nlp-api-fastapi-spacy.html
评论
作者:Julien Salinas,全栈开发者,NLPCloud.io 的创始人兼首席技术官

FastAPI 是一个新的 Python API 框架,今天越来越多地被用于生产环境中。我们在 NLP Cloud 的底层使用 FastAPI。NLP Cloud 是一个基于 spaCy 和 HuggingFace transformers 的 API,提供命名实体识别(NER)、情感分析、文本分类、摘要等服务。FastAPI 帮助我们快速构建了一个快速且稳健的机器学习 API,服务于 NLP 模型。
让我告诉你我们为什么做出这样的选择,并展示如何基于 FastAPI 和 spaCy 实现一个用于命名实体识别(NER)的 API。
为什么选择 FastAPI?
直到最近,我一直使用 Django Rest Framework 来构建 Python API。但 FastAPI 提供了几个有趣的功能:
-
它非常快速
-
它文档齐全
-
它易于使用
-
它会自动为你生成 API 架构(如 OpenAPI)
-
它在底层使用 Pydantic 进行类型验证。对于像我这样习惯静态类型的 Go 开发者来说,能够利用这样的类型提示非常酷。它使代码更清晰,减少了错误的可能性。
FastAPI 的性能使其成为机器学习 API 的一个优秀候选者。考虑到我们在 NLP Cloud 中服务了许多基于 spaCy 和 transformers 的高要求 NLP 模型,FastAPI 是一个很好的解决方案。
设置 FastAPI
你可以选择自己安装 FastAPI 和 Uvicorn(FastAPI 前面的 ASGI 服务器):
pip install fastapi[all]
如你所见,FastAPI 在一个 ASGI 服务器后面运行,这意味着它可以原生处理使用 asyncio 的异步 Python 请求。
然后你可以用类似这样的方式运行你的应用:
uvicorn main:app
另一个选择是使用 Sebastián Ramírez(FastAPI 的创始人)慷慨提供的 Docker 镜像。这些镜像已维护,并且开箱即用。
例如,Uvicorn + Gunicorn + FastAPI 镜像将 Gunicorn 添加到堆栈中,以处理并行进程。基本上,Uvicorn 处理单个 Python 进程中的多个并行请求,而 Gunicorn 处理多个并行 Python 进程。
如果你按照镜像文档正确操作,应用程序应该会自动通过 docker run 启动。
这些图像是可定制的。例如,你可以调整 Gunicorn 创建的并行进程数量。根据你的 API 需求调整这些参数非常重要。如果你的 API 服务一个需要几个 GB 内存的机器学习模型,你可能想要减少 Gunicorn 的默认并发,否则你的应用程序将快速消耗过多内存。
简单的 FastAPI + spaCy NER API
假设你想创建一个使用spaCy进行命名实体识别(NER)的 API 端点。基本上,NER 是从句子中提取实体如名字、公司、职位等。有关 NER 的更多细节,如果需要的话。
这个端点将接受一个句子作为输入,并返回一个实体列表。每个实体由实体第一个字符的位置、实体的最后位置、实体的类型以及实体文本本身组成。
端点将以 POST 请求的方式进行查询:
curl "http://127.0.0.1/entities" \
-X POST \
-d '{"text":"John Doe is a Go Developer at Google"}'
它将返回类似这样的内容:
[
{
"end": 8,
"start": 0,
"text": "John Doe",
"type": "PERSON"
},
{
"end": 25,
"start": 13,
"text": "Go Developer",
"type": "POSITION"
},
{
"end": 35,
"start": 30,
"text": "Google",
"type": "ORG"
},
]
下面是我们如何操作:
import spacy
from fastapi import FastAPI
from pydantic import BaseModel
from typing import List
model = spacy.load("en_core_web_lg")
app = FastAPI()
class UserRequestIn(BaseModel):
text: str
class EntityOut(BaseModel):
start: int
end: int
type: str
text: str
class EntitiesOut(BaseModel):
entities: List[EntityOut]
@app.post("/entities", response_model=EntitiesOut)
def read_entities(user_request_in: UserRequestIn):
doc = model(user_request_in.text)
return {
"entities": [
{
"start": ent.start_char,
"end": ent.end_char,
"type": ent.label_,
"text": ent.text,
} for ent in doc.ents
]
}
首要的是我们正在加载 spaCy 模型。对于我们的示例,我们使用了一个大型的 spaCy 预训练英文模型。大型模型占用更多内存和磁盘空间,但由于在更大的数据集上进行训练,因此提供了更好的准确性。
model = spacy.load("en_core_web_lg")
稍后,我们将通过以下方式使用这个 spaCy 模型进行 NER:
doc = model(user_request_in.text)
# [...]
doc.ents
第二个令人惊叹的 FastAPI 特性是使用 Pydantic 强制数据验证的能力。基本上,你需要提前声明用户输入的格式和 API 响应的格式。如果你是 Go 开发者,你会发现这与使用结构体进行 JSON 解组非常相似。例如,我们这样声明返回实体的格式:
class EntityOut(BaseModel):
start: int
end: int
type: str
text: str
请注意,start和end是句子中的位置,因此它们是整数,而type和text是字符串。如果 API 尝试返回一个未实现此格式的实体(例如,如果start不是整数),FastAPI 将抛出错误。
如你所见,将一个验证类嵌套到另一个类中是可能的。这里我们返回的是一个实体列表,因此我们需要声明以下内容:
class EntitiesOut(BaseModel):
entities: List[EntityOut]
一些简单类型如int和str是内置的,但更复杂的类型如List需要显式导入。
为了简洁起见,响应验证可以在装饰器中实现:
@app.post("/entities", response_model=EntitiesOut)
更高级的数据验证
使用 FastAPI 和 Pydantic 可以做许多更高级的验证。例如,如果你需要用户输入的最小长度为 10 个字符,你可以这样做:
from pydantic import BaseModel, constr
class UserRequestIn(BaseModel):
text: constr(min_length=10)
现在,如果 Pydantic 验证通过,但你后来发现数据有问题,因此想要返回 HTTP 400 代码,该怎么办?
只需引发一个HTTPException:
from fastapi import HTTPException
raise HTTPException(
status_code=400, detail="Your request is malformed")
这只是几个例子,你可以做更多!只需查看 FastAPI 和 Pydantic 文档即可。
根路径
在反向代理后运行这样的 API 是很常见的。例如,我们在 NLPCloud.io 背后使用的是 Traefik 反向代理。
在反向代理后运行时,一个棘手的事情是你的子应用程序(这里是 API)并不一定知道整个 URL 路径。实际上,这很好,因为它表明你的 API 与应用程序的其余部分是松散耦合的。
例如,我们希望 API 认为端点 URL 是 /entities,但实际的 URL 可能是类似 /api/v1/entities 的东西。这里是如何通过设置根路径来实现:
app = FastAPI(root_path="/api/v1")
如果你手动启动 Uvicorn,你也可以通过传递额外的参数来实现:
uvicorn main:app --root-path /api/v1
结论
如你所见,使用 FastAPI 创建 API 非常简单,而 Pydantic 的验证使得代码非常表达清晰(从而减少了对文档的需求)并且更不容易出错。
FastAPI 提供了出色的性能,并且可以直接使用 asyncio 进行异步请求,这对于需求高的机器学习模型非常有利。上面的示例关于使用 spaCy 和 FastAPI 的命名实体提取几乎可以认为是生产就绪的(当然,API 代码只是完整集群应用程序的一小部分)。到目前为止,FastAPI 从未成为我们 NLPCloud.io 基础设施的瓶颈。
如果你有任何问题,请随时提问!
简历: Julien Salinas 是一位全栈工程师,精通 Python/Django、Go、Vue.js、Linux 和 Docker。他是 NLPCloud.io 的创始人和首席技术官,该 API 帮助开发人员和数据科学家轻松地在生产环境中使用 NLP。他喜欢山脉、滑雪、拳击……同时也是两个男孩的父亲。
原文。经许可转载。
相关:
-
如何将 Transformers 应用于任何长度的文本
-
如何在 Kubernetes 中部署 Flask API 并与其他微服务连接
-
机器学习项目为何会失败?
我们的前三个课程推荐
 1. Google 网络安全证书 - 快速开启网络安全职业生涯。
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
 3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
主题更多内容
为什么数据科学家的专业协会是个糟糕的主意
原文:
www.kdnuggets.com/2018/07/professional-association-data-scientists-bad-idea.html
 评论
评论
由 安东尼·托卡尔,Verge Labs。
数据科学家这两个词,当它们组合在一起,并放在简历或 LinkedIn 资料下方时,显著地带来了大量的工作机会、随机的连接请求和猎头的关注。
我们的前三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升您的数据分析技能
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
 3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
这并不是什么秘密,这个职业的入门门槛非常低——在 Udemy 或 Coursera 上拿到一个证书就可以了!大家也都知道数据科学很难——毕竟,扎实的统计基础和无偏的编程技能不容易获得,更不用说需要再加上一些商业头脑了。这些似乎不太匹配…
进入数据科学专业协会。由于对认证候选人信誉的保证,公司现在可以放心,知道他们的数据科学家是真正的专家。
 在大多数情况下,您在法律上不能雇佣不是专业机构成员的会计师或精算师,而且您也不愿意这样做。例如,特许会计师协会、精算师协会以及无数其他组织都有严格的资格标准,并要求会员遵守专业和道德标准。数据科学专业协会可以提供同样的保证。
在大多数情况下,您在法律上不能雇佣不是专业机构成员的会计师或精算师,而且您也不愿意这样做。例如,特许会计师协会、精算师协会以及无数其他组织都有严格的资格标准,并要求会员遵守专业和道德标准。数据科学专业协会可以提供同样的保证。
只是有 一个问题。 很少有值得信赖的数据科学家会加入这样的组织。
考虑一下成为优秀数据科学家的条件:
大多数数据科学课程的重点是最后一点。确实,有一些课程也关注沟通,但事实是数据科学是一门应用学科,最好的学习方式是实践。以上原因就是为什么有志的数据科学家被鼓励在线分享他们的工作(通过博客、GitHub、Kaggle 等)——这是比学位或认证更强的信号。
对技术的关注也有其他限制:
-
谁将管理这样的程序?即使是该领域的专家也在许多方面有过时的知识,而且,即使如此,公认的“独角兽”也很少。
-
它能跟上吗?创新的速度非常快,最好的教育项目不断被修订。
-
它会扼杀创新吗?数据科学是一个年轻的领域,由背景各异的从业者组成。遵循单一的课程可能会限制某些领域和应用达到其潜力的能力。
上述段落的假设是,技术资格是该机构的要求。当然,还有其他行业团体没有这样的要求,但很少有人能争辩说,加入这样的团体能提供太多信号。该领域过于庞大,任何运营者都不可能在没有标准化测试的情况下,客观地认证成员,因此我们倾向于将这一机制作为基础支柱。
你可以辩称,上述原因只是该职业年轻的一个特征。随着数据科学的成熟,许多今天常用的方法将被视为标准实践。某些领域的创新速度无疑会趋于平稳。但未来的“数据科学家”将拥有与今天的数据科学家截然不同的技能。我们现在称之为数据科学的领域将分裂成各种子领域,每个子领域都有其自身的标准和原型。也许其中一些可能适合于机构代表。今天——不那么适合。简介: 安东尼·托卡尔是 Verge Labs 的总监,并且是悉尼数据科学社区若干见面会的组织者。
原创。经许可转载。
相关:
更多相关主题
使用 timeit 和 cProfile 进行 Python 代码性能分析
原文:
www.kdnuggets.com/profiling-python-code-using-timeit-and-cprofile

作者提供的图片
作为一名软件开发人员,你在职业生涯中可能会多次听到 “过早优化是万恶之源” 的名言。虽然对于小项目来说,优化可能不是非常有用(或绝对必要),但性能分析通常是有帮助的。
我们的前 3 个课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析能力
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
 3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
完成模块编码后,进行性能分析是一种良好的实践,可以测量每个部分执行所需的时间。这有助于识别代码异味并指导优化以提高代码质量。所以在优化之前一定要进行性能分析!
要迈出第一步,本指南将帮助你开始使用 Python 中的内置 timeit 和 cProfile 模块进行性能分析。你将学习如何使用命令行界面和在 Python 脚本中等效的调用方式。
如何使用 timeit 性能分析 Python 代码
timeit 模块是 Python 标准库的一部分,提供了一些方便的函数,可以用来计时短代码片段。
让我们以反转 Python 列表的简单示例为例。我们将测量使用以下方法获取列表反转副本的执行时间:
-
reversed()函数,以及 -
列表切片。
>>> nums=[6,9,2,3,7]
>>> list(reversed(nums))
[7, 3, 2, 9, 6]
>>> nums[::-1]
[7, 3, 2, 9, 6]
在命令行中运行 timeit
你可以使用以下语法在命令行中运行 timeit:
$ python -m timeit -s 'setup-code' -n 'number' -r 'repeat' 'stmt'
你需要提供要测量执行时间的语句 stmt。
你可以在需要时指定 setup 代码——使用短选项 -s 或长选项 --setup。setup 代码只会运行一次。
执行语句的次数:短选项 -n 或长选项 --number 是可选的。重复此循环的次数:短选项 -r 或长选项 --repeat 也是可选的。
让我们在示例中查看上述内容:
这里创建列表是 setup 代码,反转列表是要计时的语句:
$ python -m timeit -s 'nums=[6,9,2,3,7]' 'list(reversed(nums))'
500000 loops, best of 5: 695 nsec per loop
当你没有指定repeat的值时,使用默认值 5。当你没有指定number时,代码将运行足够多的次数,以达到至少0.2 秒的总时间。
此示例明确设置了执行语句的次数:
$ python -m timeit -s 'nums=[6,9,2,3,7]' -n 100Bu000 'list(reversed(nums))'
100000 loops, best of 5: 540 nsec per loop
repeat的默认值是 5,但我们可以将其设置为任何合适的值:
$ python3 -m timeit -s 'nums=[6,9,2,3,7]' -r 3 'list(reversed(nums))'
500000 loops, best of 3: 663 nsec per loop
让我们也来测量列表切片方法的时间:
$ python3 -m timeit -s 'nums=[6,9,2,3,7]' 'nums[::-1]'
1000000 loops, best of 5: 142 nsec per loop
列表切片方法似乎更快(所有示例均在 Ubuntu 22.04 上的 Python 3.10 中)。
在 Python 脚本中运行 timeit
这是在 Python 脚本中运行 timeit 的等效方法:
import timeit
setup = 'nums=[9,2,3,7,6]'
number = 100000
stmt1 = 'list(reversed(nums))'
stmt2 = 'nums[::-1]'
t1 = timeit.timeit(setup=setup,stmt=stmt1,number=number)
t2 = timeit.timeit(setup=setup,stmt=stmt2,number=number)
print(f"Using reversed() fn.: {
t1}")
print(f"Using list slicing: {
t2}")
timeit()可调用对象返回stmt执行number次的执行时间。注意,我们可以明确指定运行次数,或者让number取默认值 1000000。
Output >>
Using reversed() fn.: 0.08982690000000002
Using list slicing: 0.015550800000000004
这将执行语句——而不重复计时器函数——指定的number次,并返回执行时间。通常也可以使用time.repeat()并取最小时间,如下所示:
import timeit
setup = 'nums=[9,2,3,7,6]'
number = 100000
stmt1 = 'list(reversed(nums))'
stmt2 = 'nums[::-1]'
t1 = min(timeit.repeat(setup=setup,stmt=stmt1,number=number))
t2 = min(timeit.repeat(setup=setup,stmt=stmt2,number=number))
print(f"Using reversed() fn.: {
t1}")
print(f"Using list slicing: {
t2}")
这将重复运行代码number次,重复repeat次,并返回最小执行时间。这里我们有 5 次重复,每次 100000 次。
Output >>
Using reversed() fn.: 0.055375300000000016
Using list slicing: 0.015101400000000043
如何使用 cProfile 分析 Python 脚本
我们已经看到 timeit 可以用来测量短代码片段的执行时间。然而,在实际应用中,分析整个 Python 脚本更有帮助。
这将给我们所有函数和方法调用的执行时间——包括内置函数和方法。因此,我们可以更好地了解更昂贵的函数调用,并识别优化机会。例如:可能存在一个过慢的 API 调用。或者一个函数可能有一个可以用更 Pythonic 的推导式替换的循环。
让我们学习如何使用 cProfile 模块(也属于 Python 标准库)来分析 Python 脚本。
考虑以下 Python 脚本:
# main.py
import time
def func(num):
for i in range(num):
print(i)
def another_func(num):
time.sleep(num)
print(f"Slept for {
num} seconds")
def useful_func(nums, target):
if target in nums:
return nums.index(target)
if __name__ == "__main__":
func(1000)
another_func(20)
useful_func([2, 8, 12, 4], 12)
这里有三个函数:
-
func()循环遍历数字范围并打印出来。 -
包含对
sleep()函数调用的another func()。 -
useful_func()返回列表中目标数字的索引(如果目标在列表中)。
上述列出的函数将在每次运行 main.py 脚本时被调用。
在命令行运行 cProfile
使用命令行运行 cProfile:
python3 -m file-name.py
这里我们将文件命名为 main.py:
python3 -m main.py
运行此代码应该会得到以下输出:
Output >>
0
...
999
Slept for 20 seconds
以及以下配置文件:

这里,ncalls指的是函数调用的次数,percall指的是每次函数调用的时间。如果ncalls的值大于 1,则percall是所有调用的平均时间。
脚本的执行时间被 another_func 所主导,该函数使用内置的 sleep 函数调用(休眠 20 秒)。我们也看到 print 函数调用的开销相当大。
在 Python 脚本中使用 cProfile
尽管在命令行运行 cProfile 工作得很好,你也可以将性能分析功能添加到 Python 脚本中。你可以使用 cProfile 结合 pstats 模块 来进行性能分析和访问统计信息。
作为处理资源设置和拆除的最佳实践,使用 with 语句并创建一个作为上下文管理器的 profile 对象:
# main.py
import pstats
import time
import cProfile
def func(num):
for i in range(num):
print(i)
def another_func(num):
time.sleep(num)
print(f"Slept for {
num} seconds")
def useful_func(nums, target):
if target in nums:
return nums.index(target)
if __name__ == "__main__":
with cProfile.Profile() as profile:
func(1000)
another_func(20)
useful_func([2, 8, 12, 4], 12)
profile_result = pstats.Stats(profile)
profile_result.print_stats()
让我们更深入地查看生成的输出文件:

当你分析一个大型脚本时,按执行时间排序结果 会很有帮助。为此,你可以在 profile 对象上调用 sort_stats 方法,并根据执行时间进行排序:
...
if __name__ == "__main__":
with cProfile.Profile() as profile:
func(1000)
another_func(20)
useful_func([2, 8, 12, 4], 12)
profile_result = pstats.Stats(profile)
profile_result.sort_stats(pstats.SortKey.TIME)
profile_result.print_stats()
现在运行脚本时,你应该能看到按时间排序的结果:

结论
我希望这份指南能帮助你开始使用 Python 进行性能分析。始终记住,优化不应以牺牲可读性为代价。如果你有兴趣了解其他性能分析工具,包括第三方 Python 包,请查看这篇关于 Python 性能分析器的文章。
Bala Priya C 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交集处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和咖啡!目前,她正在学习并通过撰写教程、操作指南、意见文章等与开发者社区分享她的知识。
更多相关主题
数据科学编程最佳实践
原文:
www.kdnuggets.com/2018/08/programming-best-practices-data-science.html
 评论
评论
作者:Srini Kadamati,Dataquest.io
数据科学生命周期通常包含以下组件:
-
数据检索
-
数据清理
-
数据探索和可视化
-
统计或预测建模
我们的前 3 个课程推荐
 1. 谷歌网络安全证书 - 快速踏上网络安全职业生涯之路。
1. 谷歌网络安全证书 - 快速踏上网络安全职业生涯之路。
 2. 谷歌数据分析专业证书 - 提升你的数据分析水平
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
 3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
虽然这些组件有助于理解不同的阶段,但它们并没有帮助我们深入编程工作流程。
通常,整个数据科学生命周期最终变成了任意的笔记本单元格混合体,这些单元格位于 Jupyter Notebook 中或是一个混乱的脚本中。此外,大多数数据科学问题要求我们在数据检索、数据清理、数据探索、数据可视化和统计/预测建模之间切换。
但还有更好的方法!在这篇文章中,我将深入探讨大多数人在进行数据科学编程工作时切换的两种思维方式:原型思维和生产思维。
| 原型思维优先考虑: | 生产思维优先考虑: |
|---|---|
| 小片段代码的迭代速度 | 整个管道的迭代速度 |
| 较少抽象(直接修改代码和数据对象) | 更多抽象(改为修改参数值) |
| 代码结构较少(模块化较少) | 代码结构更多(模块化更多) |
| 帮助你和他人理解代码和数据 | 帮助计算机自动运行代码 |
我个人使用JupyterLab来完成整个过程(原型设计和生产化)。我推荐至少在原型设计阶段使用 JupyterLab**。
Lending Club 数据
为了更具体地理解原型设计思维和生产思维之间的区别,让我们使用一些真实数据。我们将使用来自点对点借贷网站Lending Club的借贷数据。与银行不同,Lending Club 并不直接借出资金。Lending Club 实际上是一个市场,供借款人向寻求贷款的个人提供贷款(如家庭维修、婚礼费用等)。我们可以利用这些数据构建模型,预测给定的贷款申请是否会成功。我们不会在这篇文章中深入探讨构建预测机器学习管道,但在我们的机器学习项目演练课程中有涉及。
Lending Club 提供详细的历史数据,涵盖已完成的贷款(Lending Club 批准的贷款申请,并找到贷方)和被拒绝的贷款(Lending Club 拒绝的贷款申请,资金未发生变动)。请前往他们的data download page并在DOWLNOAD LOAN DATA下选择2007-2011。

原型思维
在原型思维中,我们关注的是快速迭代,尝试理解数据的一些属性和真相。创建一个新的 Jupyter notebook,并添加一个 Markdown 单元格来解释:
-
您对 Lending Club 进行的任何研究,以更好地了解该平台
-
有关您下载的数据集的任何信息
首先,让我们将 CSV 文件读入 pandas。
import pandas as pd
loans_2007 = pd.read_csv('LoanStats3a.csv')
loans_2007.head(2)
我们得到两部分输出,首先是一个警告。
/home/srinify/anaconda3/envs/dq2/lib/python3.6/site-packages/IPython/core/interactiveshell.py:2785: DtypeWarning: Columns (0,1,2,3,4,7,13,18,24,25,27,28,29,30,31,32,34,36,37,38,39,40,41,42,43,44,46,47,49,50,51,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,123,124,125,126,127,128,129,130,131,132,133,134,135,136,142,143,144) have mixed types. Specify dtype option on import or set low_memory=False.
interactivity=interactivity, compiler=compiler, result=result)
然后是数据框的前 5 行,我们在这里避免展示(因为内容较长)。
我们还得到了以下数据框输出:
| 注释由 Prospectus 提供 (链接) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| d | member_id | loan_amnt | funded_amnt | funded_amnt_inv | term | int_rate | installment | grade | sub_grade | emp_title | emp_length | home_ownership | annual_inc | verification_status | issue_d | loan_status | pymnt_plan | url | desc | purpose | title | zip_code | addr_state | dti | delinq_2yrs | earliest_cr_line | inq_last_6mths | mths_since_last_delinq | mths_since_last_record | open_acc | pub_rec | revol_bal | revol_util | total_acc | initial_list_status | out_prncp | out_prncp_inv | total_pymnt | total_pymnt_inv | total_rec_prncp | total_rec_int | total_rec_late_fee | recoveries | collection_recovery_fee | last_pymnt_d | last_pymnt_amnt | next_pymnt_d | last_credit_pull_d | collections_12_mths_ex_med | mths_since_last_major_derog | policy_code | application_type | annual_inc_joint | dti_joint | verification_status_joint | acc_now_delinq | tot_coll_amt | tot_cur_bal | open_acc_6m | open_act_il | open_il_12m | open_il_24m | mths_since_rcnt_il | total_bal_il | il_util | open_rv_12m | open_rv_24m | max_bal_bc | all_util | total_rev_hi_lim | inq_fi | total_cu_tl | inq_last_12m | acc_open_past_24mths | avg_cur_bal | bc_open_to_buy | bc_util | chargeoff_within_12_mths | delinq_amnt | mo_sin_old_il_acct | mo_sin_old_rev_tl_op | mo_sin_rcnt_rev_tl_op | mo_sin_rcnt_tl | mort_acc | mths_since_recent_bc | mths_since_recent_bc_dlq | mths_since_recent_inq | mths_since_recent_revol_delinq | num_accts_ever_120_pd | num_actv_bc_tl | num_actv_rev_tl | num_bc_sats | num_bc_tl | num_il_tl | num_op_rev_tl | num_rev_accts | num_rev_tl_bal_gt_0 | num_sats | num_tl_120dpd_2m | num_tl_30dpd | num_tl_90g_dpd_24m | num_tl_op_past_12m | pct_tl_nvr_dlq | percent_bc_gt_75 | pub_rec_bankruptcies | tax_liens | tot_hi_cred_lim | total_bal_ex_mort | total_bc_limit | total_il_high_credit_limit | revol_bal_joint | sec_app_earliest_cr_line | sec_app_inq_last_6mths | sec_app_mort_acc | sec_app_open_acc | sec_app_revol_util | sec_app_open_act_il | sec_app_num_rev_accts | sec_app_chargeoff_within_12_mths | sec_app_collections_12_mths_ex_med | sec_app_mths_since_last_major_derog | hardship_flag | hardship_type | hardship_reason | hardship_status | deferral_term | hardship_amount | hardship_start_date | hardship_end_date | payment_plan_start_date | hardship_length | hardship_dpd | hardship_loan_status | orig_projected_additional_accrued_interest | hardship_payoff_balance_amount | hardship_last_payment_amount | disbursement_method | debt_settlement_flag | debt_settlement_flag_date | settlement_status | settlement_date | settlement_amount | settlement_percentage | settlement_term |
警告提示我们,如果在调用pandas.read_csv()时将low_memory参数设置为False,pandas 对每列的类型推断将会得到改善。
第二个输出更有问题,因为 DataFrame 存储数据的方式存在问题。JupyterLab 内置了一个终端环境,我们可以打开它并使用 bash 命令 head 来观察原始文件的前两行:
head -2 LoanStats3a.csv
虽然第二行包含我们期望的 CSV 文件中的列名,但看起来第一行在 pandas 尝试解析文件时使 DataFrame 的格式出现了问题:
Notes offered by Prospectus (https://www.lendingclub.com/info/prospectus.action)
添加一个 Markdown 单元格,详细描述你的观察结果,并添加一个代码单元格,考虑这些观察结果。
import pandas as pd
loans_2007 = pd.read_csv('LoanStats3a.csv', skiprows=1, low_memory=False)
从 Lending Club 下载页面 阅读数据字典,以了解哪些列不包含对特征有用的信息。desc 和 url 列似乎立即符合这个标准。
loans_2007 = loans_2007.drop(['desc', 'url'],axis=1)
下一步是删除任何具有超过 50% 缺失行的列。使用一个单元格来探索哪些列符合该标准,另一个单元格实际删除这些列。
loans_2007.isnull().sum()/len(loans_2007)
loans_2007 = loans_2007.dropna(thresh=half_count, axis=1)
因为我们使用 Jupyter notebook 来跟踪我们的想法和代码,我们依赖于环境(通过 IPython 内核)来跟踪状态的变化。这使我们可以自由格式化,移动单元格,重复运行相同的代码等。
通常,原型思维模式下的代码应专注于:
-
可理解性
-
Markdown 单元格用以描述我们的观察和假设
-
实际逻辑的小段代码
-
许多可视化和计数
-
-
最小化抽象
- 大多数代码不应该放在函数中(应该感觉更面向对象)
假设我们花了一个小时来探索数据并编写描述数据清洗的 markdown 单元格。然后我们可以切换到生产思维模式,使代码更加健壮。
生产思维
在生产思维模式下,我们要专注于编写可以泛化到更多情况的代码。在我们的例子中,我们希望我们的数据清洗代码适用于 Lending Club 的任何数据集(来自其他时间段)。将代码泛化的最佳方法是将其转化为数据管道。数据管道是使用来自 函数式编程 的原则设计的,其中数据在函数内部被修改,然后在函数之间传递。
这是使用单个函数封装数据清洗代码的管道的第一次迭代:
import pandas as pd
def import_clean(file_list):
frames = []
for file in file_list:
loans = pd.read_csv(file, skiprows=1, low_memory=False)
loans = loans.drop(['desc', 'url'], axis=1)
half_count = len(loans)/2
loans = loans.dropna(thresh=half_count, axis=1)
loans = loans.drop_duplicates()
# Drop first group of features
loans = loans.drop(["funded_amnt", "funded_amnt_inv", "grade", "sub_grade", "emp_title", "issue_d"], axis=1)
# Drop second group of features
loans = loans.drop(["zip_code", "out_prncp", "out_prncp_inv", "total_pymnt", "total_pymnt_inv", "total_rec_prncp"], axis=1)
# Drop third group of features
loans = loans.drop(["total_rec_int", "total_rec_late_fee", "recoveries", "collection_recovery_fee", "last_pymnt_d", "last_pymnt_amnt"], axis=1)
frames.append(loans)
return frames
frames = import_clean(['LoanStats3a.csv'])
在上述代码中,我们将之前的代码抽象为一个单独的函数。该函数的输入是文件名列表,输出是 DataFrame 对象列表。
通常,生产思维模式应专注于:
-
健康的抽象
-
代码应该进行泛化,以兼容类似的数据源
-
代码不应过于泛化,以至于难以理解
-
-
管道稳定性
- 可靠性应与其运行的频率匹配(每日?每周?每月?)
思维模式切换
假设我们尝试对来自 Lending Club 的所有数据集运行函数,而 Python 返回了错误。一些潜在的错误来源包括:
-
一些文件中列名的方差
-
由于 50% 的缺失值阈值,丢弃的列的方差
-
基于 pandas 类型推断的不同列类型
在这些情况下,我们应该实际切换回我们的原型笔记本并进一步调查。当我们确定需要让我们的管道更灵活并考虑数据中的特定变化时,我们可以将其重新纳入管道逻辑中。
这是一个示例,我们调整了函数以适应不同的丢弃阈值:
import pandas as pd
def import_clean(file_list, threshold=0.5):
frames = []
for file in file_list:
loans = pd.read_csv(file, skiprows=1, low_memory=False)
loans = loans.drop(['desc', 'url'], axis=1)
threshold_count = len(loans)*threshold
loans = loans.dropna(thresh=half_count, axis=1)
loans = loans.drop_duplicates()
# Drop first group of features
loans = loans.drop(["funded_amnt", "funded_amnt_inv", "grade", "sub_grade", "emp_title", "issue_d"], axis=1)
# Drop second group of features
loans = loans.drop(["zip_code", "out_prncp", "out_prncp_inv", "total_pymnt", "total_pymnt_inv", "total_rec_prncp"], axis=1)
# Drop third group of features
loans = loans.drop(["total_rec_int", "total_rec_late_fee", "recoveries", "collection_recovery_fee", "last_pymnt_d", "last_pymnt_amnt"], axis=1)
frames.append(loans)
return frames
frames = import_clean(['LoanStats3a.csv'], threshold=0.7)
默认值仍然是0.5,但如果需要,我们可以将其覆盖为0.7。
这里有几种方式可以使管道更加灵活,按优先级递减:
-
使用可选、位置性和必需的参数
-
在函数内使用 if / then 语句以及布尔输入值
-
使用新的数据结构(字典、列表等)来表示特定数据集的自定义操作
这个管道可以扩展到数据科学工作流程的所有阶段。这里有一些示例代码,预览了它的样子。
import pandas as pd
def import_clean(file_list, threshold=0.5):
## Code
def visualize(df_list):
# Find the most important features and generate pairwise scatter plots
# Display visualizations and write to file.
plt.savefig("scatter_plots.png")
def combine(df_list):
# Combine dataframes and generate train and test sets
# Drop features all dataframes don't share
# Return both train and test dataframes
return train,test
def train(train_df):
# Train model
return model
def validate(train_df, test-df):
# K-fold cross validation
# Return metrics dictionary
return metrics_dict
frames = import_clean(['LoanStats3a.csv', 'LoanStats2012.csv'], threshold=0.7)
visualize(frames)
train_df, test_df = combine(frames)
model = train(train_df)
metrics = test(train_df, test_df)
print(metrics)
下一步
如果你有兴趣深化理解和进一步实践,我推荐以下步骤:
-
学习如何将管道转换为可以作为模块或从命令行运行的独立脚本:
docs.python.org/3/library/**main**.html -
学习如何使用 Luigi 构建可以在云中运行的更复杂的管道: 在 Python 和 Luigi 中构建数据管道
-
了解更多关于数据工程的内容: Dataquest 上的数据工程帖子
生物:Srini Kadamati 是 Dataquest.io 的内容总监。
原文。转载已获许可。
相关:
-
Swiftapply – 自动高效的 pandas apply 操作
-
与机器学习算法相关的数据结构
-
Python 函数式编程简介