背景:
通常在问答应用程序中,向用户显示用于生成答案的来源是很重要的。最简单的方法是让链返回在每一代中检索到的文档。
代码实现:
依赖加载
import bs4
from langchain import hub
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
#from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.llms import Ollama
from langchain_community.embeddings import OllamaEmbeddings
模型与embeding 实例化
llm = Ollama(model='llama2')
embeddings = OllamaEmbeddings()
加载、组块和索引博客内容
# 加载、组块和索引博客内容。
#数据下载
bs_strainer = bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={
"parse_only": bs_strainer},
)
docs = loader.load()
实例化数据拆分
#实例化数据拆分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
#数据拆分
splits = text_splitter.split_documents(docs)
#灌入向量数据库chroma
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
构建向量搜索加载提示词
#构建向量搜索
retriever = vectorstore.as_retriever()
#加载提示词
prompt = hub.pull("rlm/rag-prompt")
#llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
#内容格式化
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
构建LCEL
#构建LCEL
rag_chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"]))) #RunnablePassthrough 固定输入格式只抽取 x["context"]
| prompt
| llm
| StrOutputParser()
)
RunnableParallel 使用案例
RunnableParallel 固定输入格,使用案例需要单独执行。
from langchain_core.runnables import (
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
runnable = RunnableParallel(
origin=RunnablePassthrough(),
modified=lambda x: x+1
)
runnable.invoke(1) # {'origin': 1, 'modified': 2}
用于处理函数的相关输出
rag_chain_with_source = RunnableParallel(
{
"context": retriever, "question": RunnablePassthrough()}
).assign(answer=rag_chain_from_docs)#assign 将新字段分配给此可运行程序的dict输出。返回一个新的可运行文件。
RunnableParallel使用案例
RunnableParallel是LCEL的两个主要组成基元之一,与RunnableSequence并列。它同时调用Runnables,为每个Runnables提供相同的输入。 RunnableParallel可以直接实例化,也可以在序列中使用dict文字来实例化。
from langchain_core.runnables import RunnableLambda
def add_one(x: int) -> int:
return x + 1
def mul_two(x: int) -> int:
return x * 2
def mul_three(x: int) -> int:
return x * 3
runnable_1 = RunnableLambda(add_one)
runnable_2 = RunnableLambda(mul_two)
runnable_3 = RunnableLambda(mul_three)
sequence = runnable_1 | {
# this dict is coerced to a RunnableParallel
"mul_two": runnable_2,
"mul_three": runnable_3,
}
sequence.invoke(1)
await sequence.ainvoke(1)
sequence.batch([1, 2, 3])
await sequence.abatch([1, 2, 3])
流式处理最终输出
使用LCEL,进行流式传输最终输出:
for chunk in rag_chain_with_source.stream("What is Task Decomposition"):
print(chunk)
返回

上面只是返回的部分内容
编译返回的流
output = {
}
curr_key = None
for chunk in rag_chain_with_source.stream("What is Task Decomposition"):
for key in chunk:
if key not in output:
output[key] = chunk[key]
else:
output[key] += chunk[key]
if key != curr_key:
print(f"\n\n{
key}: {
chunk[key]}", end="", flush=True)
else:
print(chunk[key], end="", flush=True)
curr_key = key
print(output)
输出

流式处理中间步骤的输出
from operator import itemgetter
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.tracers.log_stream import LogEntry, LogStreamCallbackHandler
这里构建了两个提示词的模版
#给到提示词模版
contextualize_q_system_prompt = """Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is."""
#构建模版
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),#这详见LangChain 入门3
("human", "{question}"),
]
)
contextualize_q_chain = (contextualize_q_prompt | llm | StrOutputParser()).with_config(
tags=["contextualize_q_chain"]
)
qa_system_prompt = """You are an assistant for question-answering tasks. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
Use three sentences maximum and keep the answer concise.\
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
def contextualized_question(input: dict):
if input.get("chat_history"):
return contextualize_q_chain
else:
return input["question"]
#构建LCEL
rag_chain = (
RunnablePassthrough.assign(context=contextualize_q_chain | retriever | format_docs)
| qa_prompt
| llm
)
要流式传输中间步骤,使用astream_log方法。这是一个异步方法,产生JSONPatch操作,当以与接收到的构建RunState相同的顺序应用:
from typing import Any, Dict, List, Optional, TypedDict
class RunState(TypedDict):
id: str
"""ID of the run."""
streamed_output: List[Any]
"""List of output chunks streamed by Runnable.stream()"""
final_output: Optional[Any]
"""Final output of the run, usually the result of aggregating (`+`) streamed_output.
Only available after the run has finished successfully."""
logs: Dict[str, LogEntry]
"""Map of run names to sub-runs. If filters were supplied, this list will
contain only the runs that matched the filters."""
可以流式传输所有步骤(默认),也可以按名称、标记或元数据包括/排除步骤。在这种情况下,将只流式传输作为contextualize_q_chain和最终输出一部分的中间步骤。
#在Jupyter notebook 中使用
import nest_asyncio
nest_asyncio.apply()
from langchain_core.messages import HumanMessage
#空的历史对话
chat_history = []
#提问
question = "What is Task Decomposition?"
#LCEL架子提问和历史信息
ai_msg = rag_chain.invoke({
"question": question, "chat_history": chat_history})
#提问后返回添加到历史信息中
chat_history.extend([HumanMessage(content=question), ai_msg])
#第二次提问
second_question = "What are common ways of doing it?"
ct = 0
#选择 contextualize_q_chain 的输出
async for jsonpatch_op in rag_chain.astream_log(
{
"question": second_question, "chat_history": chat_history},
include_tags=["contextualize_q_chain"],
):
print(jsonpatch_op)
print("\n" + "-" * 30 + "\n")
ct += 1
if ct > 20:
break
部分样例
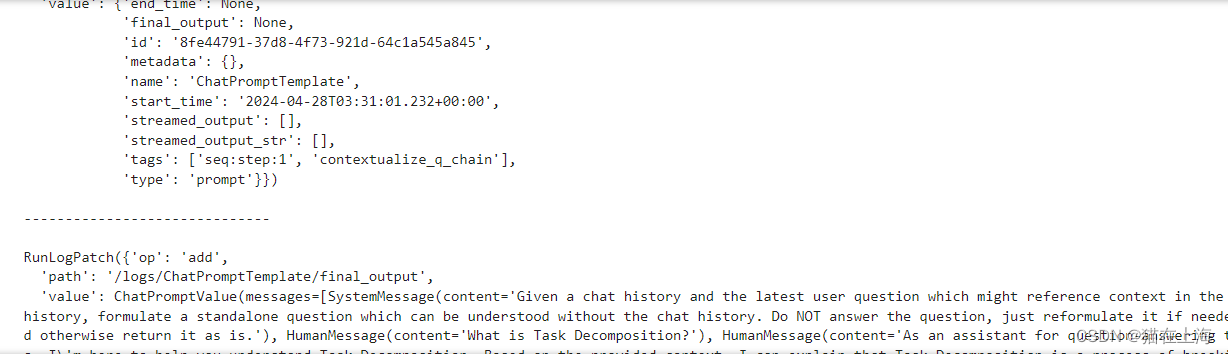
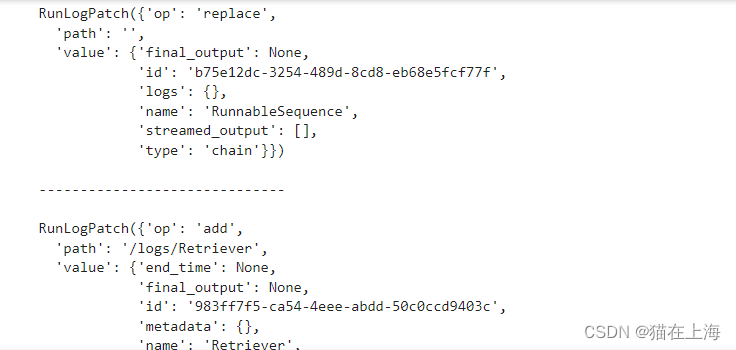
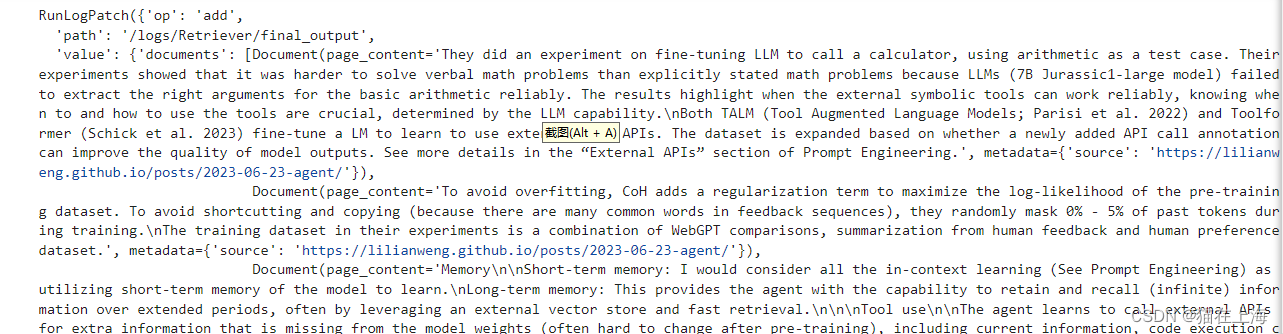
如果我们想获得检索到的文档,可以根据名称“Retriever”进行筛选:
ct = 0
async for jsonpatch_op in rag_chain.astream_log(
{
"question": second_question, "chat_history": chat_history},
include_names=["Retriever"],
with_streamed_output_list=False,
):
print(jsonpatch_op)
print("\n" + "-" * 30 + "\n")
ct += 1
if ct > 20:
break
返回的部分样例
以上是本文的全部内容,感谢阅读。