本文详述了如何通过检索增强生成(RAG)技术构建一个能够利用特定文档集合回答问题的AI系统。通过LangChain框架,可以实现超越预训练模型知识范围的定制化问答能力,适用于专业领域的精准信息检索与生成。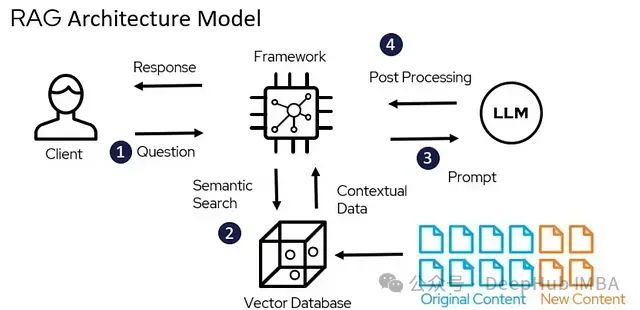
RAG技术概述及其重要性
在深入技术实现前,需要理解RAG技术的核心价值。传统语言模型如GPT-4尽管功能强大,但其知识库受限于训练数据,无法有效访问新增信息或特定领域文档。
RAG技术通过融合两个关键功能模块解决了这一局限:
- 检索系统:从文档集合中精确定位相关信息
- 生成机制:基于检索到的上下文信息生成准确、相关的响应
这种结构设计的优势在于能够构建一个基于特定知识库的AI问答系统,有效降低了幻觉(hallucination)现象,显著提升了回答的事实准确性。
LangChain框架:RAG系统的技术基础
LangChain已成为RAG应用开发的主流框架,其提供了构建完整RAG系统所需的全部核心组件:
- 多格式文档加载器,支持各类文件类型的处理
- 文本分割器,用于将文档切分为可处理的数据块
- 向量存储系统,提供高效的内容索引功能
- 文本嵌入模型,实现文本到向量的转换
- 检索机制,用于查找相关信息
- 链式处理流程,协调整个系统的运行逻辑
凭借这些组件的整合,LangChain极大地简化了RAG系统的构建复杂度,使得即使对AI开发经验有限的开发者也能实现功能完备的RAG应用。
Python代码
1、环境配置与基础设置
首先需要安装必要的库包,包括LangChain核心、社区扩展、向量数据库(FAISS)以及语言模型处理工具:
# filepath: example.py
# 安装所需的库
!pip install langchain langchain-community faiss-cpu sentence-transformers transformers
接下来导入系统所需的各个组件:
# filepath: example.py
# 核心 LangChain 组件
from langchain.llms import HuggingFacePipeline
from langchain.chains import RetrievalQA, LLMChain
from langchain.chains.question_answering import load_qa_chain
from langchain.prompts import PromptTemplate
# LangChain 社区组件
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import HuggingFaceEmbeddings
# Hugging Face 组件
from transformers import pipeline
# 标准库
import os
import urllib.request
import zipfile
2、知识库构建
RAG系统的基础是高质量的知识库。本实现中,我们使用一个包含亚洲各目的地信息的数据集作为示例:
# filepath: example.py
# 下载并提取我们的示例数据集
zip_url = "https://github.com/gakudo-ai/open-datasets/raw/refs/heads/main/asia_documents.zip"
zip_path = "asia_documents.zip"
extract_folder = "asia_txt_files"
print("Downloading sample documents...") # 正在下载示例文档...
urllib.request.urlretrieve(zip_url, zip_path)
print("Extracting files...") # 正在提取文件...
os.makedirs(extract_folder, exist_ok=True)
with zipfile.ZipFile(zip_path, "r") as zip_ref:
zip_ref.extractall(extract_folder)
print(f"Successfully extracted {len(os.listdir(extract_folder))} documents to {extract_folder}") # 成功提取 {len(os.listdir(extract_folder))} 个文档到 {extract_folder}
3、文档处理与分块策略
RAG系统的关键步骤是文档的处理与分块。这一阶段包括:
- 文档加载
- 将文档分割为适当大小的块
- 为每个文本块生成向量表示
# filepath: example.py
# 从文件夹加载所有文本文件
documents = []
for filename in os.listdir(extract_folder):
if filename.endswith(".txt"):
file_path = os.path.join(extract_folder, filename)
loader = TextLoader(file_path)
documents.extend(loader.load())
print(f"Loaded {len(documents)} documents") # 加载了 {len(documents)} 个文档
# 将文档拆分成更小的块,以便更好地检索
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=500, # 每个块的字符数
chunk_overlap=100 # 块之间的重叠以保持上下文
)
docs = text_splitter.split_documents(documents)
print(f"Created {len(docs)} document chunks") # 创建了 {len(docs)} 个文档块
4、向量数据库构建
RAG系统的核心是向量数据库,它实现了基于语义的高效搜索。本实现采用FAISS作为向量存储引擎,结合句子转换模型构建嵌入表示:
# filepath: example.py
# 初始化嵌入模型
embedding_model = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2" # 速度和质量的良好平衡
)
# 从我们的文档块创建一个向量存储
vectorstore = FAISS.from_documents(docs, embedding_model)
# 创建一个检索器接口
retriever = vectorstore.as_retriever(
search_kwargs={"k": 3} # 检索前 3 个最相关的块
)
print("Vector database created successfully!") # 向量数据库创建成功!
5、语言模型配置
本实现使用GPT2作为基础模型,但实际应用中可替换为更高性能的模型如Llama-2或Mistral:
# filepath: example.py
# 使用 Hugging Face 模型创建一个文本生成管道
llm_pipeline = pipeline(
"text-generation",
model="gpt2", # 你可以用其他模型替换它,例如 "mistralai/Mistral-7B-v0.1"
device=0 if "cuda" in [str(x) for x in pipeline.available_devices] else -1, # 如果可用,则使用 GPU
max_new_tokens=200 # 控制响应长度
)
# 将管道包装在 LangChain 的接口中
llm = HuggingFacePipeline(pipeline=llm_pipeline)
print("Language model loaded successfully!") # 语言模型加载成功!
6、提示模板设计
RAG系统的输出质量很大程度上取决于提示模板的设计。以下是针对问答任务的专业提示模板:
# filepath: example.py
# 定义一个用于问答的提示模板
prompt_template = """
Answer the question based only on the following context:
Context:
{context}
Question: {query}
Helpful Answer:"""
prompt = PromptTemplate(
input_variables=["query", "context"],
template=prompt_template
)
print("Prompt template created!") # 提示模板已创建!
7、RAG流程集成
将所有组件连接起来,构建完整的RAG处理流程:
# filepath: example.py
# 创建一个结合了检索器和语言模型的链
retrieval_qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # "stuff" 只是将所有检索到的文档放入提示中
retriever=retriever,
return_source_documents=True, # 在响应中包含源文档
chain_type_kwargs={"prompt": prompt} # 使用我们的自定义提示
)
print("RAG pipeline assembled and ready to use!") # RAG 管道已组装好并可以使用!
8、系统测试与应用
通过针对亚洲主题的问题测试RAG系统的表现:
# filepath: example.py
# 帮助清晰显示响应的函数
def ask_question(question):
print(f"Question: {question}\n")
# 从我们的 RAG 系统获取响应
result = retrieval_qa({"query": question})
print("Answer:") # 回答:
print(result["result"])
print("\nSources:") # 来源:
for i, doc in enumerate(result["source_documents"]):
print(f"Source {i+1}: {doc.metadata.get('source', 'Unknown')}") # 来源 {i+1}: {doc.metadata.get('source', 'Unknown')}
print("\n" + "-"*50 + "\n")
# 尝试一些问题
ask_question("What are some popular dishes in Japanese cuisine?")
ask_question("What is Vietnam known for?")
ask_question("Which countries in Asia are worth visiting?")
基础系统已经完成了,我们还可以在多方面进行优化空间
系统优化策略
1、高性能语言模型应用
虽然GPT-2适用于演示目的,但在生产环境中应考虑使用更强大的模型以提升响应质量:
# filepath: example.py
# 使用更强大的模型的示例
llm_pipeline = pipeline(
"text-generation",
model="mistralai/Mistral-7B-v0.1", # 更强大的开源模型
device=0,
max_new_tokens=300
)
2、检索策略优化
可通过多种技术优化默认的相似性搜索机制:
# filepath: example.py
# 创建一个带有 MMR(最大边际相关性)的检索器
# 这有助于确保检索到的文档的多样性
retriever = vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": 5, "fetch_k": 10, "lambda_mult": 0.5}
)
# 或者尝试混合搜索(结合语义和关键词搜索)
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# 创建一个压缩器,仅提取文档的相关部分
compressor = LLMChainExtractor.from_llm(llm)
# 创建一个压缩检索器
compression_retriever = ContextualCompressionRetriever(
base_retriever=retriever,
base_compressor=compressor
)
3、文档分块策略优化
文档分块方式对检索质量有重大影响:
# filepath: example.py
# 尝试不同的分块策略
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", ". ", " ", ""] # 尝试在段落/句子边界处分割
)
常见问题及解决方案
1、检索质量问题
当系统检索到不相关信息时,可采取以下措施:
- 使用更高质量的嵌入模型,如
all-mpnet-base-v2替代all-MiniLM-L6-v2 - 调整文本块大小和重叠参数
- 增加检索文档数量
- 实现检索结果的重排序机制
2、响应质量问题
当系统响应不准确或偏离主题时:
- 应用更强大的语言模型
- 优化提示模板中的指令表述
- 尝试不同的链式策略,如使用
refine替代stuff - 在提示中加入示例以实现少样本学习
3、性能效率问题
当系统响应速度较慢时:
- 使用更轻量级的嵌入模型
- 减小文本块大小和检索文档数量
- 对语言模型进行量化处理(4位或8位精度)
- 采用更高效的向量存储解决方案,如Chroma或Qdrant
总结
通过本文所述方法,已成功构建了一个能够基于特定文档集合回答问题的完整RAG系统。尽管示例使用了有关亚洲目的地的小型数据集,但同样的技术架构适用于任何规模的文档集合。
RAG技术的后续发展可考虑以下方向:
- 规模扩展:应用于更大规模的专业文档集合
- 模型优化:测试不同的嵌入模型和语言模型组合
- 功能增强:实现引用追踪、来源验证或多步骤推理
- 部署优化:从本地测试环境转向生产级部署
检索增强生成技术代表了当前AI应用的一个最具实用价值的方向,它使开发者能够创建将大型语言模型的通用能力与特定领域知识相结合的系统。通过构建这样的基础系统,已为更复杂的AI应用奠定了技术基础,这些应用将能够深度理解并有效利用专业领域的知识资源。
https://avoid.overfit.cn/post/4c0590a63b77428f9a12d98231bf9dd4