在 DeepSeek 开源周的第二天,该团队发布了 DeepEP,这是针对 MoE 模型的通信库,能提高 GPU 内核之间的吞吐量并降低延迟。此外该库还支持低精度操作,比如 FP8。
DeepSeek 团队在仓库的 README 中写道:
为了追求极致性能,我们发现并使用了一个在文档描述之外的 PTX 指令:ld.global.nc.L1::no_allocate.L2::256B。
这条指令会导致未定义行为:使用非一致性只读 PTX 修饰符 .nc 访问易失性 GPU 内存。
但是,在 Hopper 架构上,经过测试,使用 .L1::no_allocate 可以保证正确性,并且性能会好得多。

根据博主「karminski-牙医」的解读,no_allocate 这个指令出现在 CUDA PTX ISA 文档的第 214 页,但只是草草说了句用途,并没有详细解释能带来什么提升。
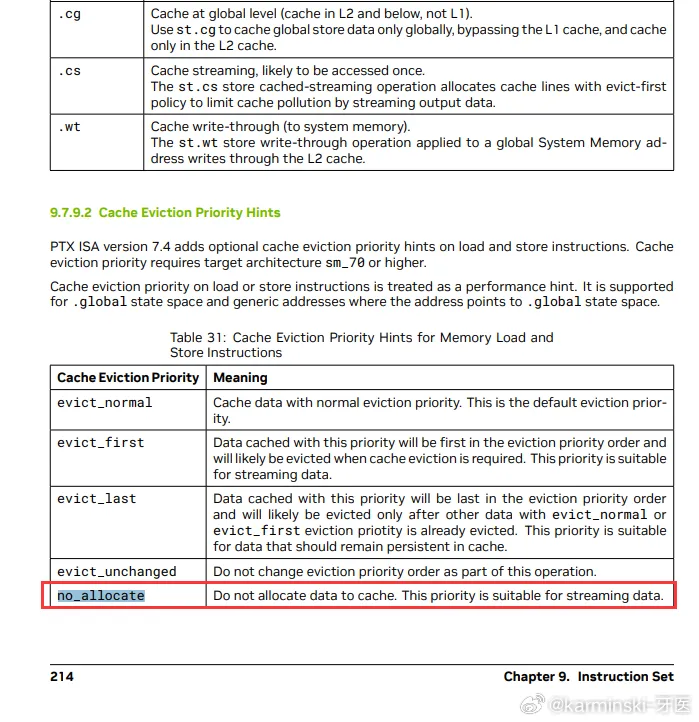
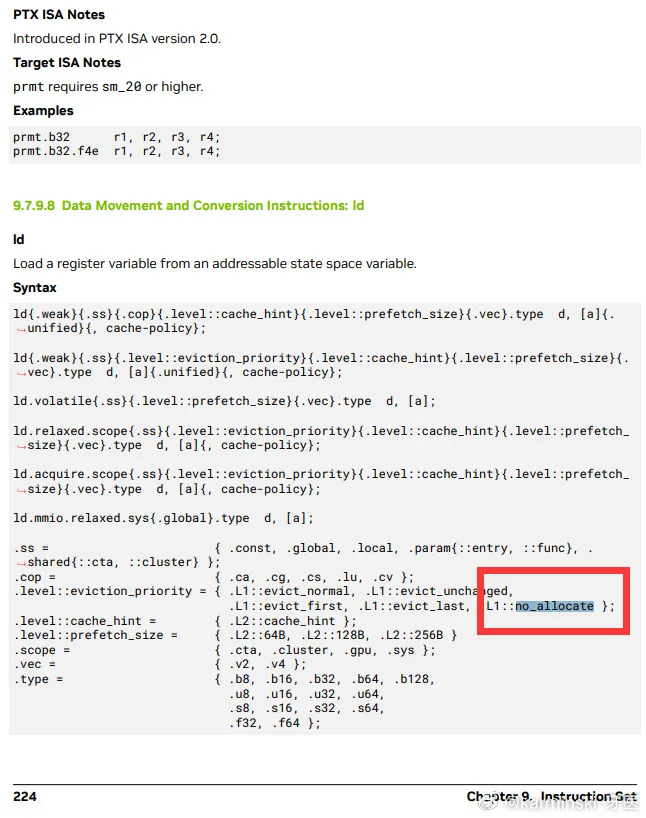
DeepSeek 团队从这么“深”的地方挖掘到了一个不被官方详细介绍的指令——并且带来极致的性能提升,可见他们对 CUDA 的研究程度之深,以及在 GPU 领域的积累。
CUDA PTX ISA 文档:https://docs.nvidia.com/cuda/pdf/ptx_isa_8.7.pdf