本文主要描述阿里云大模型开发环境的搭建、训练数据集的制作流程、大模型如何训练数据集以及如何利用已训练完成的模型执行推理。
开发环境搭建
ModelScope社区是阿里云通义千问开源的大模型开发者社区。

如上所示,安装ModelScope社区大模型基础库开发框架的命令行参数,使用清华大学提供的镜像地址
![]()
![]()

如上所示,在JetBrains PyCharm的项目工程终端控制台中,安装深度学习基础库开发框架pytorch
![]()
![]()
如上所示,在JetBrains PyCharm的项目工程终端控制台中,安装深度学习基础库开发框架tensorflow
![]()
![]()
如上所示,在JetBrains PyCharm的项目工程终端控制台中,安装ModelScope社区大模型基础库开发框架
![]()
如上所示,在JetBrains PyCharm的项目工程终端控制台中,安装ModelScope社区大模型多模态领域开发框架
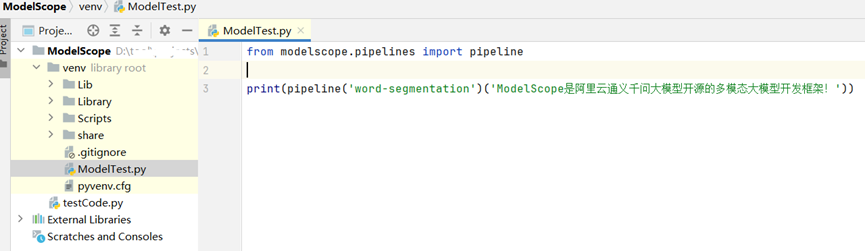
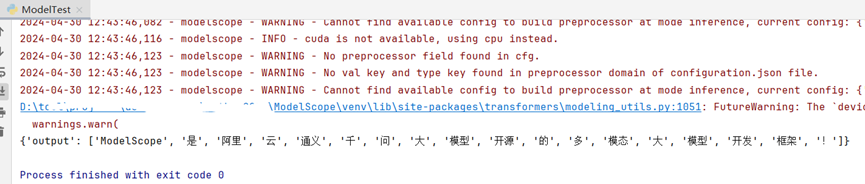
如上所示,在JetBrains PyCharm的项目工程的测试代码中,使用分词器对原文执行分析操作,输出分词列表
运行千问大模型
| https://www.modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct/files |
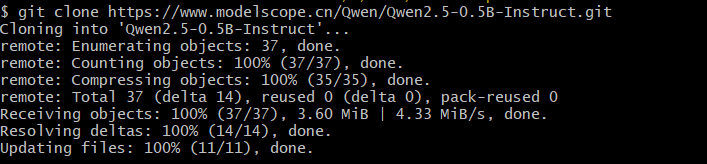
如上所示,从ModelScope社区的模型仓库下载开源的千问大模型到本地

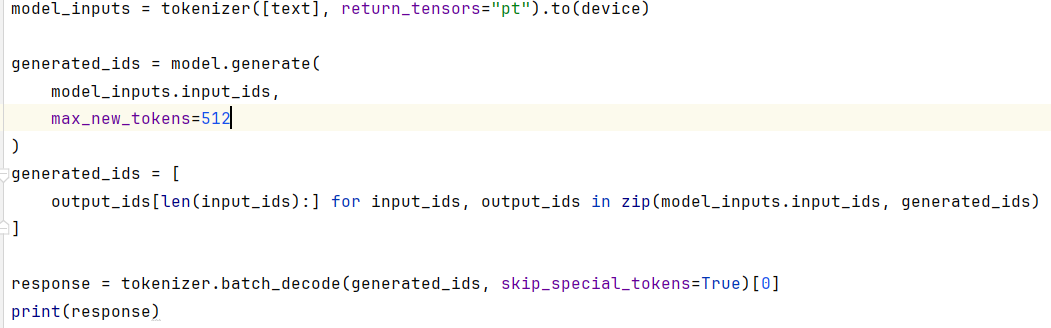
如上所示,在JetBrains PyCharm的项目工程的测试代码中,加载开源的千问大模型,设置本地开发环境使用CPU设备
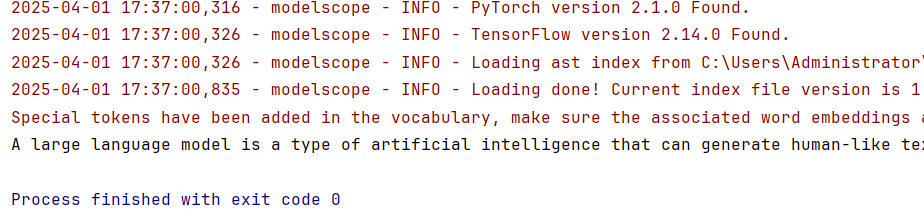
如上所示,在JetBrains PyCharm的项目工程中运行测试代码完成
训练数据集制作
| https://modelscope.cn/datasets/liucong/Chinese-DeepSeek-R1-Distill-data-110k/files |
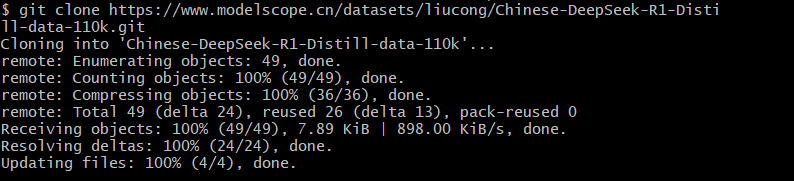
如上所示,从ModelScope社区下载数据集

如上所示,下载的数据集是文本格式,该数据集是用于监督型机器学习,可以将该数据集按照8:2的比例分成两个数据集,分别用于训练数据集以及测试评估数据集,也可以从整体数据集中随机抽取数据记录用于训练数据集以及测试评估数据集,或者根据实际的业务数据制作训练数据集以及测试评估数据集

如上所示,数据集的字段属性说明,输入的字段是提供给机器学习的输入,思考的字段是输出的强相关内容,输出的字段相当于监督型机器学习的分类输出
模型训练
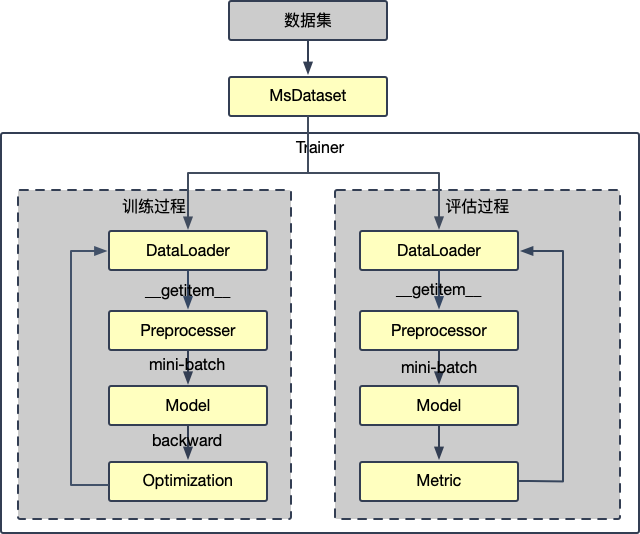
如上所示,ModelScope社区是使用人工智能机器学习开源框架PyTorch,训练器包括训练过程以及评估过程,训练过程中经过多次迭代,不断优化参数,最终输出合适的参数,评估过程中经过多次迭代,最终输出评估的分数

如上所示,使用ModelScope社区的人工智能机器学习框架加载训练数据集以及测试评估数据集

如上所示,ModelScope社区的人工智能机器学习训练器的属性配置

如上所示,使用ModelScope社区的人工智能机器学习训练器执行数据训练

如上所示,使用ModelScope社区的人工智能机器学习训练器执行测试评估,以及保存训练完成的模型到指定的目录中
模型推理

如上所示,使用ModelScope社区的人工智能推理框架pipeline,对已完成训练的大模型执行推理
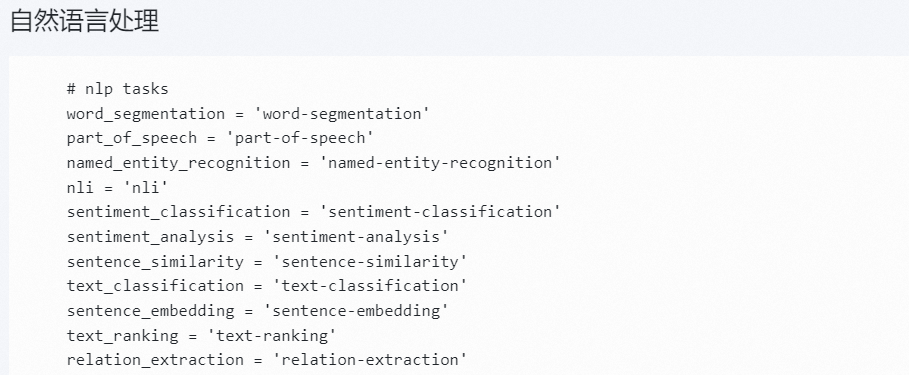
| https://www.modelscope.cn/docs/sdk/pipelines |
如上所示,ModelScope社区提供的pipeline推理框架支持的部分任务列表