大模型强化学习简介
概念
人生中充满选择,每次选择就是一次决策,我们正是从一次次决策中,把自己带领到人生的下一段旅程中。在回忆往事时,我们会对生命中某些时刻的决策印象深刻:“唉,当初我要是去那家公司实习就好了,在那里做的技术研究现在带来了巨大的社会价值。”通过这些反思,我们或许能领悟一些道理,变得更加睿智和成熟,以更积极的精神来迎接未来的选择和成长。
在机器学习领域,有一类重要的任务和人生选择很相似,即序贯决策(sequential decision making)任务。决策和预测任务不同,决策往往会带来“后果”,因此决策者需要为未来负责,在未来的时间点做出进一步的决策。预测仅仅产生一个针对输入数据的信号,并期望它和未来可观测到的信号一致,这不会使未来情况发生任何改变。
广泛地讲,强化学习是机器通过与环境交互来实现目标的一种计算方法。
机器和环境的一轮交互是指机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器。
- 这种交互是迭代进行的,机器的目标是最大化在多轮交互过程中获得的累积奖励的期望。强化学习用智能体(agent)这个概念来表示做决策的机器。
- 相比于有监督学习中的“模型”,强化学习中的“智能体”强调机器不但可以感知周围的环境信息,还可以通过做决策来直接改变这个环境,而不只是给出一些预测信号。
智能体
下面我们聊聊这里的智能体
智能体和环境之间具体的交互方式如图所示。在每一轮交互中,智能体感知到环境目前所处的状态,经过自身的计算给出本轮的动作,将其作用到环境中;环境得到智能体的动作后,产生相应的即时奖励信号并发生相应的状态转移。智能体则在下一轮交互中感知到新的环境状态,依次类推。
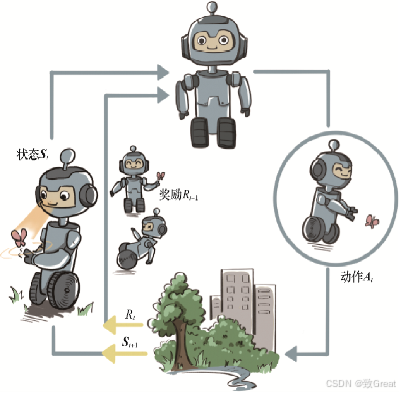
智能体有3种关键要素,即感知、决策和奖励。
- 感知:智能体在某种程度上感知环境的状态,从而知道自己所处的现状。例如,下围棋的智能体感知当前的棋盘情况;无人车感知周围道路的车辆、行人和红绿灯等情况;机器狗通过摄像头感知面前的图像,通过脚底的力学传感器来感知地面的摩擦功率和倾斜度等情况。
- 决策:智能体根据当前的状态计算出达到目标需要采取的动作的过程叫作决策。例如,针对当前的棋盘决定下一颗落子的位置;针对当前的路况,无人车计算出方向盘的角度和刹车、油门的力度;针对当前收集到的视觉和力觉信号,机器狗给出4条腿的齿轮的角速度。策略是智能体最终体现出的智能形式,是不同智能体之间的核心区别。
- 奖励:环境根据状态和智能体采取的动作,产生一个标量信号作为奖励反馈。这个标量信号衡量智能体这一轮动作的好坏。例如,围棋博弈是否胜利;无人车是否安全、平稳且快速地行驶;机器狗是否在前进而没有摔倒。最大化累积奖励期望是智能体提升策略的目标,也是衡量智能体策略好坏的关键指标。
环境
强化学习的智能体是在和一个动态环境的交互中完成序贯决策的。
我们说一个环境是动态的,意思就是它会随着某些因素的变化而不断演变,这在数学和物理中往往用随机过程来刻画。其实,生活中几乎所有的系统都在进行演变,例如一座城市的交通、一片湖中的生态、一场足球比赛、一个星系等。对于一个随机过程,其最关键的要素就是状态以及状态转移的条件概率分布。这就好比一个微粒在水中的布朗运动可以由它的起始位置以及下一刻的位置相对当前位置的条件概率分布来刻画。
如果在环境这样一个自身演变的随机过程中加入一个外来的干扰因素,即智能体的动作,那么环境的下一刻状态的概率分布将由当前状态和智能体的动作来共同决定,用最简单的数学公式表示则是

根据上式可知,智能体决策的动作作用到环境中,使得环境发生相应的状态改变,而智能体接下来则需要在新的状态下进一步给出决策。
由此我们看到,与面向决策任务的智能体进行交互的环境是一个动态的随机过程,其未来状态的分布由当前状态和智能体决策的动作来共同决定,并且每一轮状态转移都伴随着两方面的随机性:一是智能体决策的动作的随机性,二是环境基于当前状态和智能体动作来采样下一刻状态的随机性。通过对环境的动态随机过程的刻画,我们能清楚地感受到,在动态随机过程中学习和在一个固定的数据分布下学习是非常不同的。
目标
在上述动态环境下,智能体和环境每次进行交互时,环境会产生相应的奖励信号,其往往由实数标量来表示。
这个奖励信号一般是诠释当前状态或动作的好坏的及时反馈信号,好比在玩游戏的过程中某一个操作获得的分数值。
整个交互过程的每一轮获得的奖励信号可以进行累加,形成智能体的整体回报(return),好比一盘游戏最后的分数值。根据环境的动态性我们可以知道,即使环境和智能体策略不变,智能体的初始状态也不变,智能体和环境交互产生的结果也很可能是不同的,对应获得的回报也会不同。因此,在强化学习中,我们关注回报的期望,并将其定义为价值(value),这就是强化学习中智能体学习的优化目标。
价值的计算有些复杂,因为需要对交互过程中每一轮智能体采取动作的概率分布和环境相应的状态转移的概率分布做积分运算。
强化学习和有监督学习的学习目标其实是一致的,即在某个数据分布下优化一个分数值的期望。不过,经过后面的分析我们会发现,强化学习和有监督学习的优化途径是不同的。
大模型强化学习简介-数据
有监督学习的任务建立在从给定的数据分布中采样得到的训练数据集上,通过优化在训练数据集中设定的目标函数(如最小化预测误差)来找到模型的最优参数。这里,训练数据集背后的数据分布是完全不变的。
在强化学习中,数据是在智能体与环境交互的过程中得到的。如果智能体不采取某个决策动作,那么该动作对应的数据就永远无法被观测到,所以当前智能体的训练数据来自之前智能体的决策结果。因此,智能体的策略不同,与环境交互所产生的数据分布就不同,
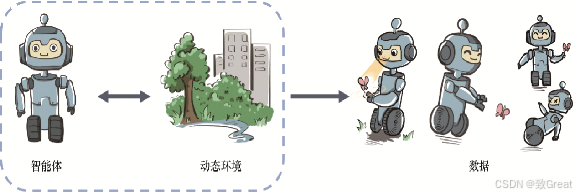
具体而言,强化学习中有一个关于数据分布的概念,叫作占用度量(occupancy measure),其具体的数学定义和性质会在第3章讨论,在这里我们只做简要的陈述:归一化的占用度量用于衡量在一个智能体决策与一个动态环境的交互过程中,采样到一个具体的状态动作对(state-action pair)的概率分布。占用度量有一个很重要的性质:给定两个策略及其与一个动态环境交互得到的两个占用度量,那么当且仅当这两个占用度量相同时,这两个策略相同。也就是说,如果一个智能体的策略有所改变,那么它和环境交互得到的占用度量也会相应改变。
根据占用度量这一重要的性质,我们可以领悟到强化学习本质的思维方式。
强化学习的策略在训练中会不断更新,其对应的数据分布(即占用度量)也会相应地改变。因此,强化学习的一大难点就在于,智能体看到的数据分布是随着智能体的学习而不断发生改变的。
由于奖励建立在状态动作对之上,一个策略对应的价值其实就是一个占用度量下对应的奖励的期望,因此寻找最优策略对应着寻找最优占用度量。
独特性
对于一般的有监督学习任务,我们的目标是找到一个最优的模型函数,使其在训练数据集上最小化一个给定的损失函数。在训练数据独立同分布的假设下,这个优化目标表示最小化模型在整个数据分布上的泛化误差(generalization error),用简要的公式可以概括为:

对于一般的有监督学习任务,我们的目标是找到一个最优的模型函数,使其在训练数据集上最小化一个给定的损失函数。在训练数据独立同分布的假设下,这个优化目标表示最小化模型在整个数据分布上的泛化误差(generalization error),用简要的公式可以概括为:

观察以上两个优化公式,我们可以回顾总结出两者的相似点和不同点。
- 有监督学习和强化学习的优化目标相似,即都是在优化某个数据分布下的一个分数值的期望。
- 二者优化的途径是不同的,有监督学习直接通过优化模型对于数据特征的输出来优化目标,即修改目标函数而数据分布不变;强化学习则通过改变策略来调整智能体和环境交互数据的分布,进而优化目标,即修改数据分布而目标函数不变。
综上所述,一般有监督学习和强化学习的范式之间的区别为:
- 一般的有监督学习关注寻找一个模型,使其在给定数据分布下得到的损失函数的期望最小;
- 强化学习关注寻找一个智能体策略,使其在与动态环境交互的过程中产生最优的数据分布,即最大化该分布下一个给定奖励函数的期望。
大模型强化学习技术-RLHF框架
RLHF框架简介
RLHF(Reinforcement Learning from Human Feedback):即使用强化学习的方法,利用人类反馈信号直接优化语言模型。
RLHF的强化学习训练过程可以分解为三个核心步骤:
- 多种策略产生样本并收集人类反馈
- 训练奖励模型
- 训练强化学习策略,微调 LM
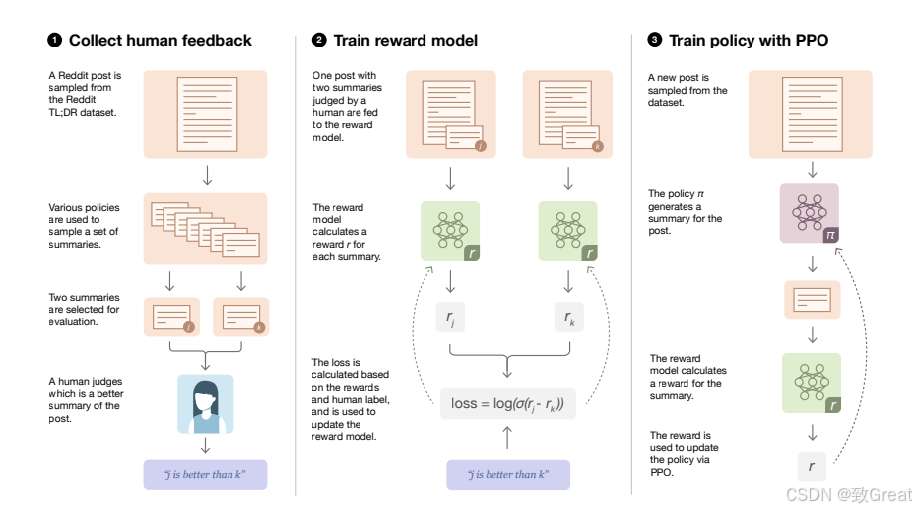
RLHF就是基于人类反馈对语言模型进行强化学习,和一般的Finetune过程乃至Prompt Tuning自然也不同。根据OpenAI的思路,RLHF的训练过程可以分解为三个核心步骤:
- 预训练语言模型(LM)
- 收集数据并训练奖励模型
- 通过强化学习微调 LM
Training language models to follow instructions with human feedback
RLHF原理
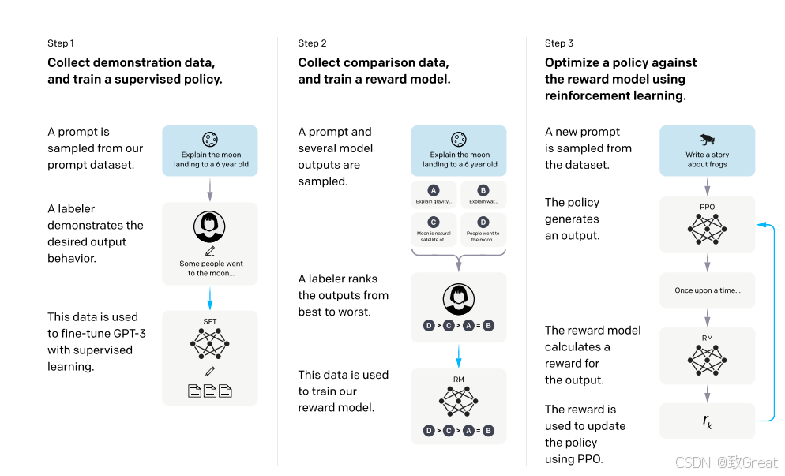
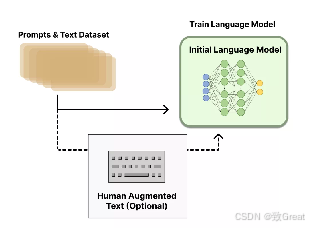
阶段1:预训练语言模型
首先,我们需要选一个经典的预训练语言模型作为初始模型。
- OpenAI 在其第一个RLHF 模型 InstructGPT 中用的小规模参数版本的 GPT-3;
- DeepMind 则使用了2800 亿参数的 Gopher 模型。
这些语言模型往往见过大量的 [Prompt,Text] 对,输入一个prompt(提示),模型往往能输出还不错的一段文本。
预训练模型可以在人工精心撰写的语料上进行微调,但这一步不是必要的。
- OpenAI在人工撰写的优质语料上对预训练模型进行了微调;
- Anthropic将他们的语言模型在“有用、真实、无害”价值观导向的语料上做了一步模型蒸馏。
不过,这种人工撰写的优质语料一般成本是非常高的。
总结一下,这个步骤,可以用如下图所示:
阶段2:奖励模型的训练
一个奖励模型(RM)的目标是刻画模型的输出是否在人类看来表现不错。即,输入 [提示(prompt),模型生成的文本] ,输出一个刻画文本质量的标量数字。
用于训练奖励模型的Prompt数据一般来自于一个预先富集的数据集
- Anthropic的Prompt数据主要来自Amazon Mechanical Turk上面的一个聊天工具;
- OpenAI的Prompt数据则主要来自那些调用GPT API的用户
这些prompts会被丢进初始的语言模型(第一阶段的模型)里来生成文本。
整体流程如图所示:
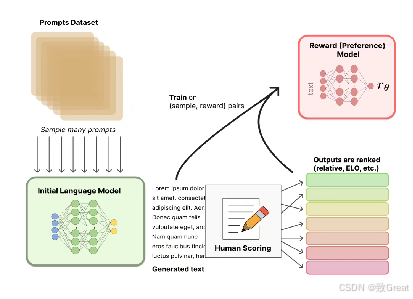
奖励模型可以看做一个判别式的语言模型,因此我们可以用一个预训练语言模型热启,而后在 [x=[prompt,模型回答], y=人类满意度] 构成的标注语料上去微调,也可以直接随机初始化,在语料上直接训练。
如图所示,标注人员的任务则是对初始语言模型生成的文本进行排序(不打分,只告诉好坏)。有人可能会奇怪,为啥不直接让标注人员对文本进行打分呢?
-
这是因为研究人员发现不同的标注员,打分的偏好会有很大的差异(比如同样一段精彩的文本,有人认为可以打1.0,但有人认为只能打0.8),而这种差异就会导致出现大量的噪声样本。若改成标注排序,则发现不同的标注员的打分一致性就大大提升了。
-
那具体怎么操作呢?一种比较有效的做法是“pair-wise”,即给定同一个prompt,让两个语言模型同时生成文本,然后比较这两段文本哪个好。最终,这些不同的排序结果会通过某种归一化的方式变成标量信号(即point-wise)丢给模型训练。
一个比较有趣的观测是,奖励模型的大小最好是跟生成模型的大小相近,这样效果会比较好。一种比较直观的解释就是,要理解生成模型的输出内容,这份理解能力所需要的模型参数规模就得恰好是跟生成模型相近才能做到(当然,如果奖励模型规模更大那应该更没问题,但理论上没必要)。
至此,我们有了一个初始的语言模型来生成文本,以及一个奖励模型(RM)来判断模型生成的文本是否优质(迎合人类偏好)。接下来会讲解如何使用强化学习(RL)来基于奖励模型来优化初始的语言模型。
阶段3:基于 RL 进行语言模型优化
我们将初始语言模型的微调任务建模为强化学习(RL)问题,因此需要定义策略(policy)、动作空间(action space)和奖励函数(reward function)等基本要素。
- 策略就是基于该语言模型,接收prompt作为输入,然后输出一系列文本(或文本的概率分布);
- 动作空间就是词表所有token在所有输出位置的排列组合(单个位置通常有50k左右的token候选);
- 观察空间则是可能的输入token序列(即prompt),显然也相当大,为词表所有token在所有输入位置的排列组合;
- 奖励函数(reward)则是基于训好的RM模型计算得到初始reward,再叠加上一个约束项来。
然后我们来看一下最后提到的这个约束项是什么。
-
首先,基于前面提到的预先富集的数据,从里面采样prompt输入,同时丢给初始的语言模型和我们当前训练中的语言模型(policy),得到俩模型的输出文本y1,y2
-
然后用奖励模型RM对y1、y2打分,判断谁更优秀。
显然,打分的差值便可以作为训练策略模型参数的信号,这个信号一般通过KL散度来计算“奖励/惩罚”的大小。y2文本的打分比y1高的越多,奖励就越大,反之惩罚则越大。这个信号就反映了当前模型有没有在围着初始模型“绕圈”,避免模型通过一些“取巧”的方式骗过RM模型获取高额reward。 -
最后,便是根据 Proximal Policy Optimization (PPO) 算法来更新模型参数了。
PPO 算法确定的奖励函数具体计算如下:
将提示 x 输入初始 LM 和当前微调的 LM,分别得到了输出文本 y 1 , y 2 y1, y2 y1,y2,将来自当前策略的文本传递给 RM 得到一个标量的奖励 r θ r_θ rθ 。
将两个模型的生成文本进行比较计算差异的惩罚项,在来自 OpenAI、Anthropic 和 DeepMind 的多篇论文中设计为输出词分布序列之间的 Kullback–Leibler (KL) divergence 散度的缩放,即 r = r θ − λ r K L r=r_θ−λr_KL r=rθ−λrKL,这一项被用于惩罚 RL 策略在每个训练批次中生成大幅偏离初始模型,以确保模型输出合理连贯的文本。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值。
此外,OpenAI 在 InstructGPT 上实验了在 PPO 添加新的预训练梯度,可以预见到奖励函数的公式会随着 RLHF 研究的进展而继续进化。
通过以上过程不难想到,完全可以迭代式的更新奖励模型(RM)和策略模型(policy),让奖励模型对模型输出质量的刻画愈加精确,策略模型的输出则愈能与初始模型拉开差距,使得输出文本变得越来越符合人的认知。Anthropic论文中叫做"Iterated Online RLHF",下面是论文的流程图,通过迭代式优化
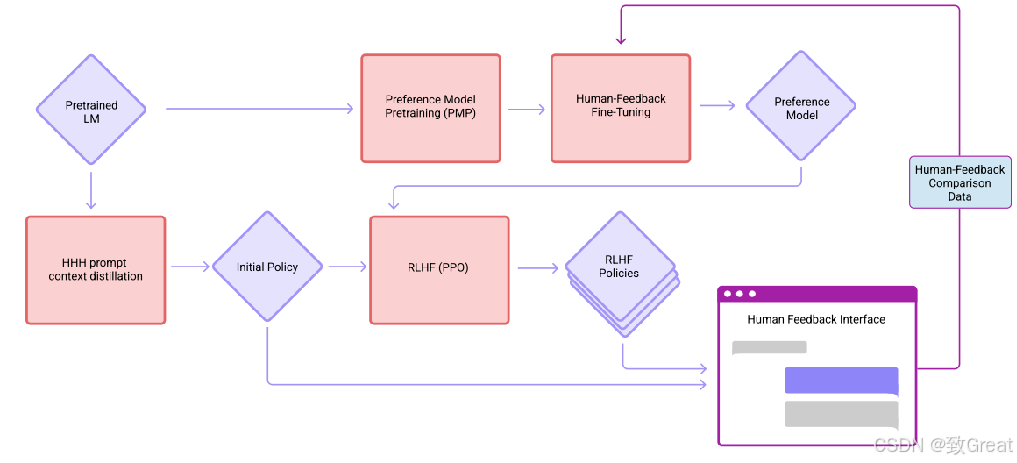
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
大模型强化学习技术-奖励模型设计与提效
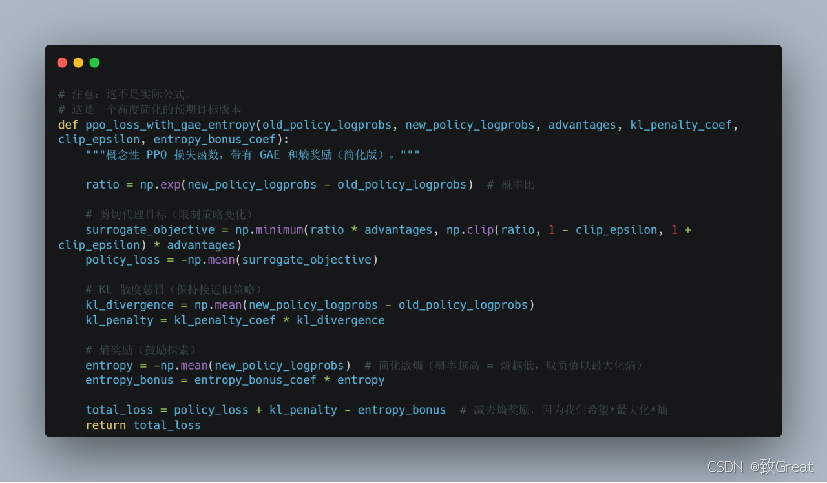
下面提到强化学习算法,这里只阐述概念,先不走原理的展开,数学公式看不过来了
PPO(Proximal Policy Optimization):近端策略优化
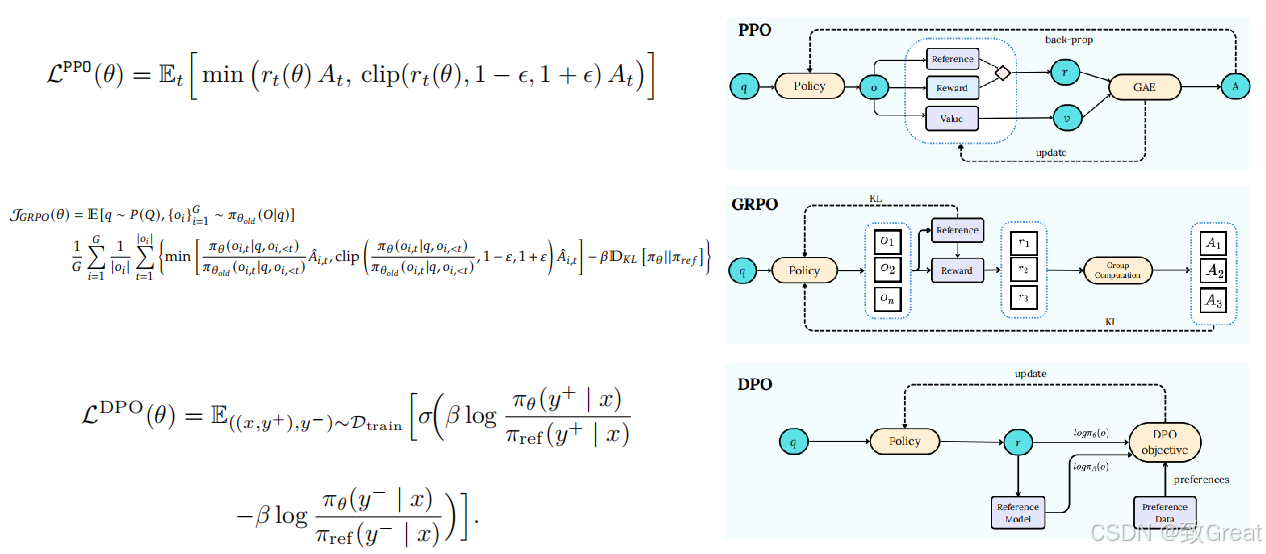
PPO 是一种强大且可靠的强化学习算法,通常是 RLHF 的起点。
谨慎的改进步骤: PPO 就像是教你的 LLM 一步步走路,确保它在每次更新时不会摔倒。它对 LLM 的“走路方式”(策略)进行温和的调整。
PPO 的关键角色:
- 策略(LLM):我们正在训练的 LLM,用于生成更好的文本。
- 奖励模型:根据人类偏好对文本打分的 AI 裁判。
- 价值函数(辅助教练):另一个 AI 模型,充当“辅助教练”。它估计每个状态的“好坏”(当前文本生成的前景如何)。这有助于 PPO 进行更智能的更新。
PPO 训练 —— 五步之舞:
- 生成文本(Rollout):LLM(策略)为不同的提示生成大量文本样本。
- 获取分数(奖励模型):奖励模型对每个文本样本进行打分。
- 计算优势(GAE —— “好多少”分数):这就是 GAE 的作用!它是一种巧妙的方法,用于计算每个单词选择的优劣,考虑奖励和价值函数的预测。(关于 GAE 的更多内容见下文!)
- 优化 LLM(策略更新):我们更新 LLM 的策略,以最大化一个特殊的 PPO 目标函数。这个目标函数现在有三个关键部分:
- 鼓励更高奖励:它推动 LLM 生成能够获得更高分数的文本。
- 限制策略变化(剪切代理目标):它防止策略在一次更新中变化过大,确保稳定性。
- KL 散度惩罚:如果新策略与旧策略偏离太远,它会增加惩罚,进一步增强稳定性。
- 熵奖励:它还包括一个熵奖励。简单来说,熵衡量 LLM 文本生成的“随机性”或“多样性”。增加熵奖励可以鼓励 LLM 更多地探索,而不是总是生成相同、可预测的响应。它有助于防止 LLM 过早变得“过于确定”,从而错过可能更好的策略。
- 更新价值函数(辅助教练更新):训练价值函数成为一个更好的“辅助教练”——更准确地预测不同文本生成的“好坏”。
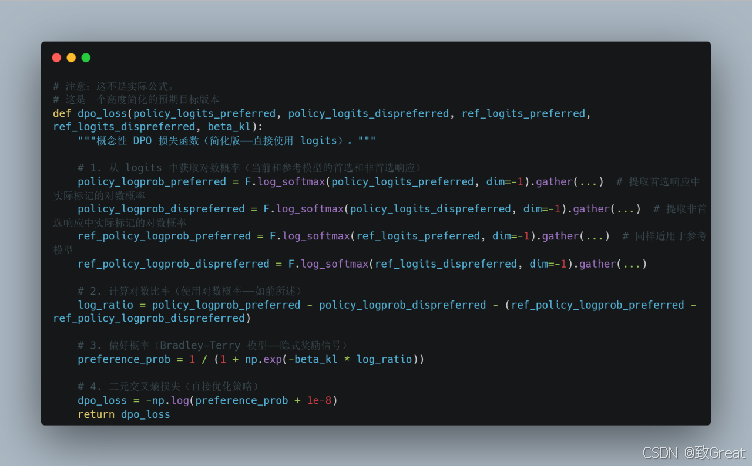
DPO (Direct Preference Optimization):直接偏好优化
DPO是“新晋成员” ——一种更简单、更高效的方式来进行偏好学习,跳过了RL的复杂性。
直截了当:DPO 就像是直接告诉 LLM:“响应 A 比响应 B 更好。多生成像 A 这样的响应,少生成像 B 这样的响应!”它省略了 RL 中用于策略优化的奖励模型这一中间环节。
DPO —— 没有 RL 循环,只有偏好
DPO 避免了 PPO 的迭代 RL 循环。它直接基于人类偏好数据利用一个巧妙的损失函数对 LLM 进行优化。
DPO 训练流程(简化版,强调简洁性)
-
偏好数据仍然是关键 :
与 PPO 一样,DPO 仍然从相同的关键部分开始:人类偏好数据(成对的响应,带有标签,指示哪个响应更受青睐)。人类反馈仍然是基础! -
直接策略更新(分类式损失——直接使用 logits!)
这是 DPO 的魔法所在。DPO 使用一个特殊的损失函数直接比较两个模型的 logits(概率之前的原始输出分数):- 当前模型(正在训练中) :
我们将首选响应(响应 A)和非首选响应(响应 B)都输入到我们正在训练的当前 LLM 中,得到两者的 logits。 - 参考模型(旧版本) :
我们还将响应 A 和响应 B 输入到一个参考模型中。这通常是 LLM 的旧版本(比如我们开始时的 SFT 模型)。我们也会从参考模型中得到 logits。
DPO的损失函数直接使用这两个模型的 logits 来计算损失 ,这与分类任务中使用的二元交叉熵损失非常相似。增加首选响应的 logits(和概率),让当前模型在未来更有可能生成像响应 A 这样的响应。
- 减少非首选响应的 logits(和概率) :
让当前模型在未来更不可能生成像响应 B 这样的响应。 - 保持接近参考模型(隐式 KL 控制) :
损失函数还隐式鼓励当前模型在行为上保持与参考模型的接近(使用参考模型的 logits),这有助于稳定性,类似于 PPO 的 KL 惩罚,但直接嵌入在损失函数中! - DPO 的损失函数就像一个“偏好指南针” :
直接根据首选和非首选响应的相对 logits 指导 LLM 的权重,而无需显式预训练奖励。
- 当前模型(正在训练中) :
GRPO(Group Relative Policy Optimization):群体相对策略优化
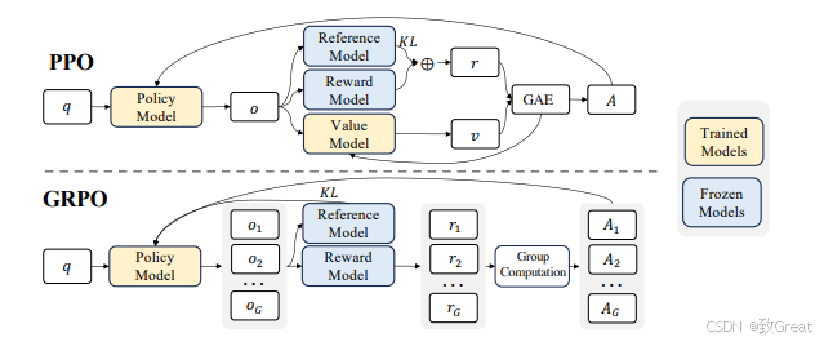
GRPO 是 DeepSeek AI 对 PPO 的一种聪明的改进,旨在更加高效,尤其是在复杂的推理任务中。
GRPO —— 更精简、更快速的 PPO
GRPO 就像是 PPO 的精简版表亲。它保留了 PPO 的核心思想,但去掉了独立的价值函数(辅助教练),使其更轻量、更快速。
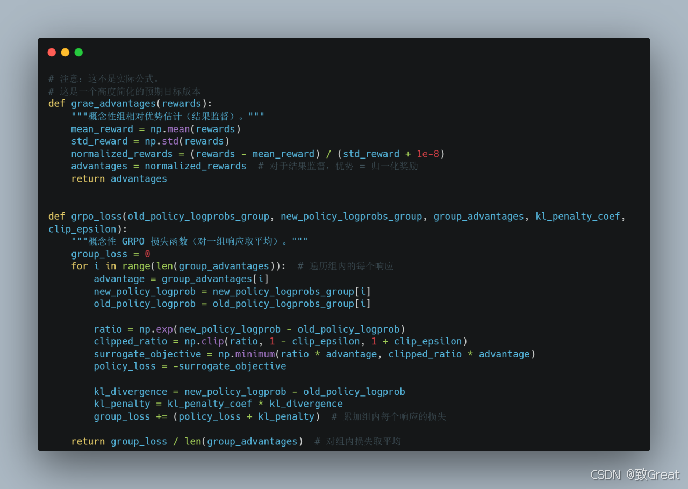
GRPO 的诀窍:基于组的优势估计(GRAE)
GRPO 的魔法成分在于它如何估计优势。它不是使用辅助教练,而是使用一组由 LLM 生成的相同提示的响应来估计每个响应相对于组内其他响应的“好坏”。
GRPO 训练流程(简化版):
- 生成一组响应:对于每个提示,从 LLM 中生成多个响应的一组。
- 对组进行打分(奖励模型):获取组内所有响应的奖励分数。
- 计算组内相对优势(GRAE —— 组内比较):通过比较每个响应的奖励与组内平均奖励来计算优势。在组内对奖励进行归一化以得到优势。
- 优化策略(使用 GRAE 的 PPO 风格目标函数):使用一个 PPO 风格的目标函数更新 LLM 的策略,但使用这些组内相对优势。
群体相对策略优化 (GRPO,Group Relative Policy Optimization)是一种强化学习 (RL) 算法,专门用于增强大型语言模型 (LLM) 中的推理能力。与严重依赖外部评估模型(价值函数)指导学习的传统 RL 方法不同,GRPO 通过评估彼此相关的响应组来优化模型。这种方法可以提高训练效率,使 GRPO 成为需要复杂问题解决和长链思维的推理任务的理想选择。
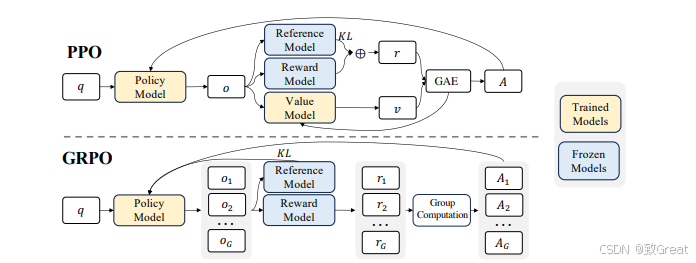
GRPO 的本质思路:通过在同一个问题上生成多条回答,把它们彼此之间做“相对比较”,来代替传统 PPO 中的“价值模型”。
GRPO 目标函数:群体相对策略优化 (GRPO) 中的目标函数定义了模型如何学习改进其策略,从而提高其生成高质量响应的能力。
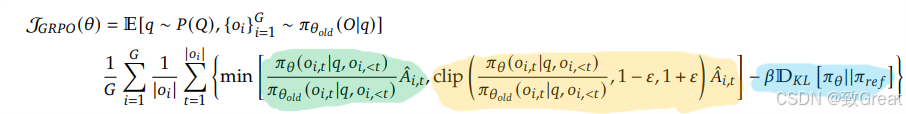
这个函数主要由三部分组成:
-
重要性采样比 (Policy Ratio):衡量新旧策略之间的变化。
-
裁剪的目标函数 (Clipped Objective):限制策略更新幅度,以避免剧烈变化导致模型崩溃。
-
KL 散度正则项 (KL Divergence Regularization):确保新策略不会偏离参考策略太远,以保持稳定性。
通过例子理解 GRPO 目标函数:GRPO(群体相对策略优化)目标函数就像一个配方,通过比较模型自身的响应并逐步改进,让模型能够更好地生成答案。让我们将其分解成一个易于理解的解释:
目标:想象一下,你正在教一群学生解决一道数学题。你不会直接告诉他们谁答对了谁答错了,而是比较所有学生的答案,找出谁答得最好(以及原因)。然后,你通过奖励更好的方法和改进较弱的方法来帮助学生学习。这正是 GRPO 所做的——只不过它教的是 AI 模型,而不是学生。
步骤1:从训练数据集 P(Q) 中选择一个查询 (q)

步骤2:生成一组响应(G)

步骤 3:计算每个响应的奖励,奖励是通过量化模型的响应质量来指导模型的学习。
GRPO 中的奖励类型:
- 准确性奖励:基于响应的正确性(例如,解决数学问题)。
- 格式奖励:确保响应符合结构指南(例如,标签中包含的推理)。
- 语言一致性奖励:惩罚语言混合或不连贯的格式。
根据每个回复的优劣程度为其分配奖励 (ri) 。例如,奖励可能取决于:
- 准确性:答案正确吗?
- 格式:回复是否结构良好?

步骤 4:比较答案(团体优势),计算每个响应相对于该组的优势 (Ai) :
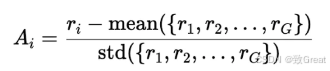
- 群体均值(Group Mean): 群体的平均奖励。
- 标准差(Standard Deviation): 奖励的分布情况,表示奖励值的分散程度。

简单讲,计算该组的平均分数,每个回答的分数都会与组平均分数进行比较。
步骤 5:使用裁剪更新策略,避免大幅度的不稳定更新。如果新策略与旧策略的比率超出范围,则会被裁剪以防止过度修正。
步骤 6:使用 KL 散度惩罚偏差,例如如果模型开始生成格式差异极大的输出,KL 散度项会对其进行抑制。
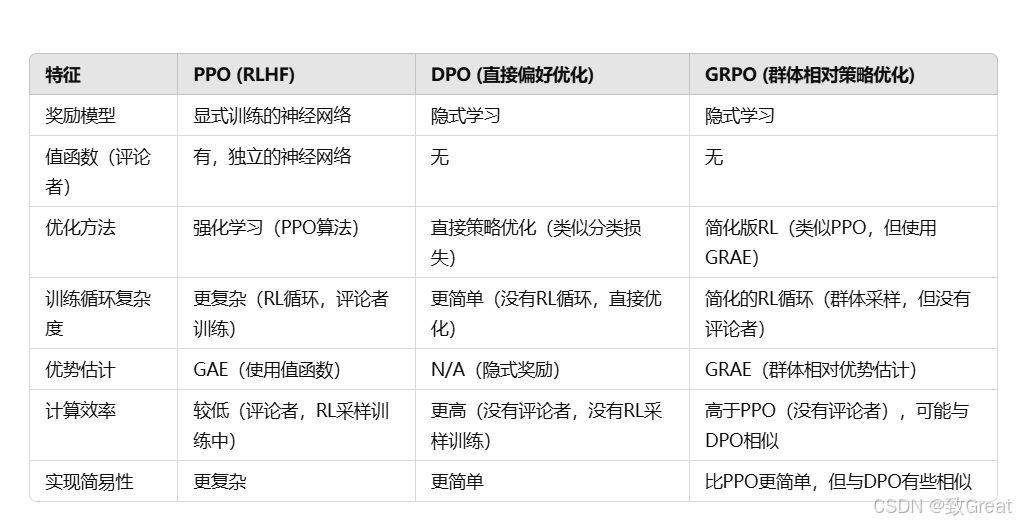
用表格总结一下它们的关键区别:
下面有一些论文的对比图片
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
大模型强化学习技术-ORM和PRM区别
在大模型的训练中,常采用RLHF(Reinforcement Learning from Human Feedback)即基于人类反馈的强化学习,是一种将人类反馈融入强化学习过程的技术方法,该技术的最重要的一部份就是奖励模型。
奖励模型也叫打分模型,是一种通过量化方式对模型输出结果进行质量评估并打分,以引模型学习优化或输出给用户结果前做质量评估,判断是否需要重新给用户预测。
训练奖励模型时,先利用已有的监督微调模型进行预测得到多个结果,再让用户对这些结果打分或排序以制作出反映用户偏好的数据集,最后基于该数据集单独训练奖励模型。Reward Model 有两种主流的形式:
- ORM(Outcome Reward Model)是在生成模型中,对生成结果整体打分评估。
- PRM(Process Reward Model)是在生成过程中,分步骤对每一步进行打分的更细粒度奖励模型。
ORM(Outcome Reward Model)原理
训练数据集的准备
如下表所示,包含3列,分别对应问题,接受的回答,拒绝的回答。

训练时,同一个问题的两个回答会在一个batch中同时送入到网络中做推理,如batch_size=4,一个batch如下:
- 人口最多的国家?印度
- 面积最多的国家?俄罗斯
- 人口最多的国家?中国
- 面积最多的国家?加拿大
奖励模型的模型结构
在有限的资源中,可能无法加载多个大模型,常用的方法是在基座模型的基础上,使用LOAR分支(训练模型也用LOAR分支),并且后面接上一个regression head。预测只把最后一个token作为输入,以batch为例,一个batch会有4个预测分数,对应两组chosen_reward和reject_reward,一组中chosen_reward和reject_reward会计算一个loss。
损失函数
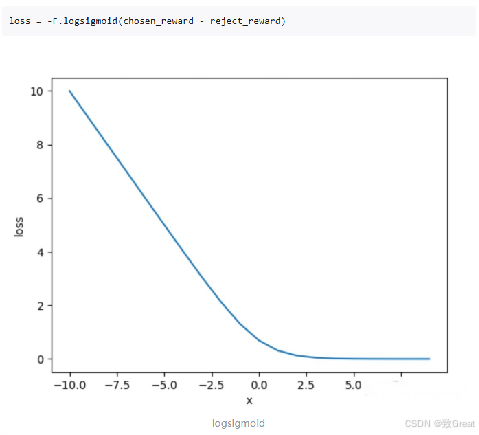
PRM(Process Reward Model)原理
OpenAI o1 有采用长思维链,不再是直接得出结果,而是通过反复思考,一步一步得出最终答案,流程大致如下:
提出一个数学问题:
一个圆柱形水桶,底面半径是 3 分米,高是 8 分米,现在要给这个水桶的内外表面都涂上防锈漆,每平方分米需要用防锈漆 5 克,请问一共需要多少克防锈漆?
模型思考的步骤:
1、定义xxx。
2、提出公式xxx。
3、计算xxx。
4、等待xxx。
5、最终答案xxx。
上面模型在思考过程中的步骤,也称动作Action,PRM的作用可以对这些动作打分,引导模型生成到获得收益最大的路径(也就是正确的解题步骤和正确的答案)
训练数据集的准备
OpenAI也公开发布了这部分数据集,详见github:PRM800K。准备一些问题,通过要求大模型,按照一步一步的格式输出结果,并且每个问题,需要多次预测,再给标注人员做标注每个步骤的得分,当前步骤清晰正确的给高分,反之给低分;如果没有给出正确答案,需要删除或人工修正。

模型训练时的输入,把所有step拼接在一起:
- sample1:a=5-2,b=a+1,b?<step1_start> a=5-2=3<step1_end> <step2_start> b=3+1=4<step2_end>
- sample2:a=5-2,b=a+1,b?<step1_start> a=5-2=3<step1_end> <step2_start> b=3+1=3<step2_end>
推理时在每个<stepx_end>位置token预测出每个步骤的得分。
模型结构与ORM类似
损失函数:PRM-LOSS
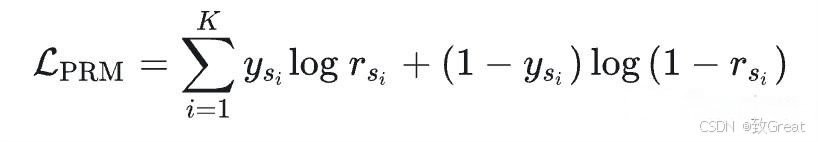
K K K表示k步, y s i y_si ysi为预测真实标签, r s i r_si rsi预测标签。
大模型强化学习技术-推理能力增强
下面是论文LLM Post-Training: A Deep Dive into Reasoning Large Language Models一些关键要点
大型语言模型(LLMs)后训练方法的分类,分为微调、强化学习和测试时扩展方法。我们总结了最近的LLM模型中使用的关键技术,如GPT-4 、LLaMA 3.3 和Deepseek R1 。
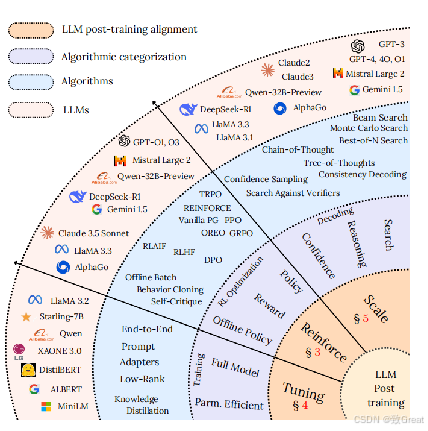
LLM Post-Training: A Deep Dive into Reasoning Large Language Models
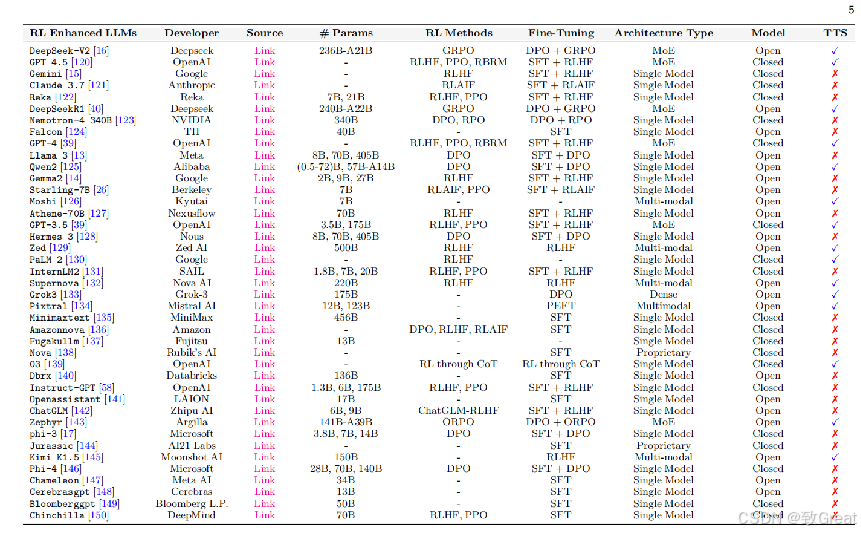
增强型强化学习大型语言模型(LLMs)概述,其中符号“141B-A39B”表示一种专家混合(MoE)架构,该模型总参数量为1410亿,其中在推理过程中实际使用的参数为390亿。
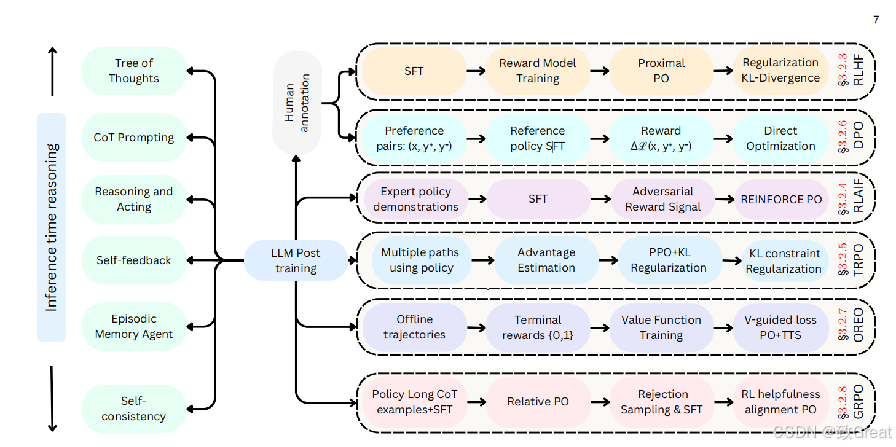
大型语言模型(LLMs)推理方法概述,展示了通过链式思维(CoT)提示、自我反馈和情节记忆等方法提升推理能力的路径。该图强调了多种基于强化学习的优化技术,包括GRPO、RLHF、DPO和RLAIF,用于通过奖励机制和基于偏好的学习来微调推理模型。
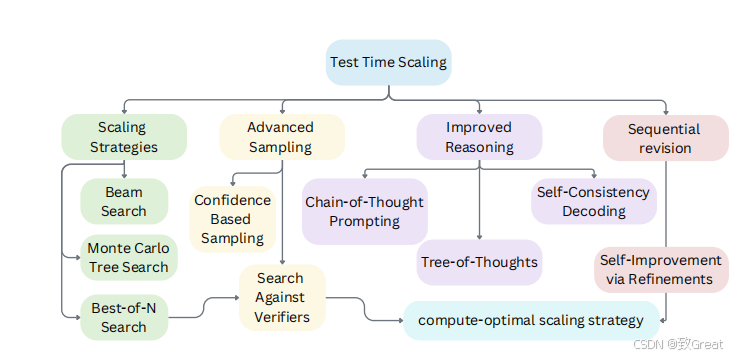
测试时扩展(Test-time Scaling)方法概述:并行扩展、顺序扩展和基于搜索的方法。图中还展示了它们如何整合到计算最优策略中。
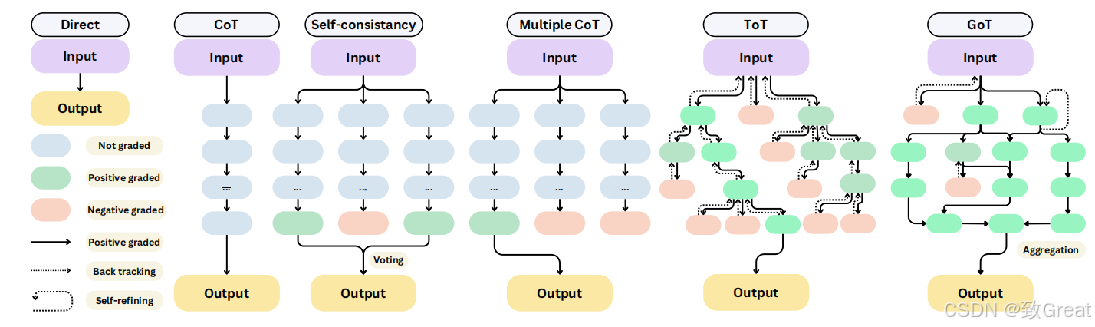
这张图比较了LLMs中的推理策略,从直接提示(Direct Prompting)开始,它将输入直接映射到输出,未涉及推理过程,到更结构化的方法。链式思维(CoT)引入了逐步推理,而自一致性(CoT-SC)生成多个CoT路径并选择最常见的答案。多个CoT独立地探索多样化的推理路径。思维树(ToT)将推理结构化为树形,支持回溯和优化,而思维图(GoT)通过动态汇聚和连接思维来扩展这一方法。图例解释了关键机制,如评分、回溯和自我优化,这些机制对于优化推理效率至关重要。
参考资料
- (六)大模型RLHF:PPO原理与源码解读 - jasonzhangxianrong - 博客园
- 大模型RLHF中PPO的直观理解 - Machine Learning Pod
- 初探强化学习
- 从零实现ChatGPT—RLHF技术笔记 - ChatGPT网站
- ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT - CSDN博客
- LLM(七):RLHF——当语言模型遇上强化学习 - 知乎
- 抱抱脸:ChatGPT背后的算法——RLHF | 附12篇RLHF必刷论文 - 知乎
- 2204.05862
- The Full Story of Large Language Models and RLHF
- Fine-Tuning Language Models from Human Preferences
- Illustrating Reinforcement Learning from Human Feedback (RLHF)
- 2009.01325
- ChatGPT 背后的“功臣”——RLHF 技术详解
- opendilab/awesome-RLHF: A curated list of reinforcement learning with human feedback resources (continually updated)
- 什么是 RLHF?– 基于人类反馈的强化学习简介 – AWS
- RLHF是什么?ChatGPT 背后的 “功臣” - CodeNews
- RLHF及其替代方法在大模型训练中的应用
- 大模型入门(六)—— RLHF微调大模型 - CSDN博客
- 【LLM第三篇】名词解释:RLHF——chatgpt的功臣 - CSDN博客
- 关于模型训练中的RLHF,这些基础知识得懂!
- 什么是人类反馈的强化学习 (RLHF)?| IBM
- 大模型入门(七)—— RLHF中的PPO算法理解 - 微笑sun - 博客园
- 详解基于人类反馈的强化学习 (RLHF)算法原理InstructGPT:让人工智能更听话的技术 - 掘金
- RLHF 基础 | 记忆笔书
- 详解大模型RLHF过程(配代码解读) - 知乎
- 李宏毅深度强化学习笔记(一)Proximal Policy Optimization (PPO) - 51CTO博客
- ChatGPT会取代搜索引擎吗 - 知乎
- 推理类大模型的后训练增强实践分析 - 幕布
- 【LLM训练系列03】关于大模型训练常见概念讲解 - 腾讯云开发者社区
- 【论文】大语言模型推理最新综述 - 腾讯新闻
- 大模型+强化学习的基本综述 - CSDN博客
- 「大模型+强化学习」最新综述!港中文深圳130余篇论文:详解四条主流技术路线 - 腾讯云开发者社区
- 大推理模型技术全面综述:背景、数据、模型、学习、评估、趋势 - 知乎
- 迈向大型推理模型:大语言模型强化推理综述 - 知乎