DeepSeek V3中的Multi-Head Latent Attention (MLA):技术解析与应用
在自然语言处理(NLP)领域,Transformer架构及其衍生模型一直是研究和应用的热点。DeepSeek V3作为一款先进的语言模型,其核心创新之一便是引入了Multi-Head Latent Attention (MLA)机制。本文将深入解析MLA的原理、优势及其在DeepSeek V3中的应用,并通过公式推导和通俗易懂的案例进行说明。
一、MLA的背景与动机
Transformer模型中的多头注意力(Multi-Head Attention, MHA)机制虽然强大,但随着序列长度和模型规模的增加,其计算和存储成本也急剧上升。特别是在处理长文本时,MHA的键值(Key-Value, KV)缓存会占用大量内存,限制了模型的效率和可扩展性。为了解决这一问题,MLA应运而生,旨在通过创新的压缩和解耦机制,降低内存占用并提升计算效率。
二、MLA的核心技术
(一)低秩联合压缩
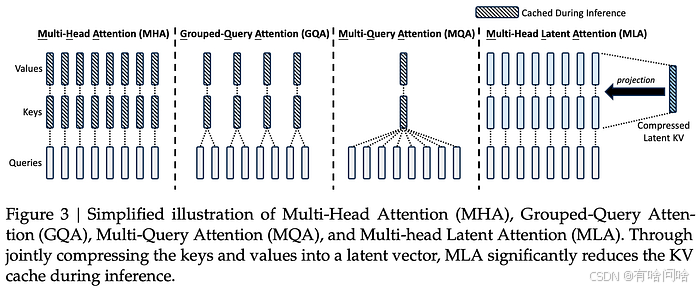
MLA的核心创新之一是低秩联合压缩技术。在传统的MHA中,每个注意力头都会独立生成键和值,导致KV缓存的大小随着头数和序列长度线性增长。MLA通过将多个头的键值对映射到共享的潜在空间,利用低秩矩阵分解实现联合压缩。这一过程类似于将多个高清视频合并成一个经过智能编码的压缩文件,虽然体积显著缩小,但关键信息仍然得以保留。
具体来说,MLA对注意力机制中的键(Key)和值(Value)进行低秩压缩,生成一个压缩的潜在向量,然后通过上投影矩阵将其还原为原始的键和值。这种方式显著减少了KV缓存的大小,同时保持了与标准MHA相当的性能。例如,在DeepSeek-V3中,MLA实现了6倍的KV缓存压缩率,使得模型能够轻松处理数万token的长文本。
公式推导
假设输入序列为 X ∈ R n × d X \in \mathbb{R}^{n \times d} X∈Rn×d,其中 n n n 是序列长度, d d d 是特征维度。MLA首先将输入映射到潜在空间:
Z = f ( X ) ∈ R n × k , k ≪ d Z = f(X) \in \mathbb{R}^{n \times k}, \quad k \ll d Z=f(X)∈Rn×k,k≪d
其中 f ( ⋅ ) f(\cdot) f(⋅) 是一个线性变换,潜在维度 k k k 显著低于原始维度 d d