最近看了下一些比较经典的多模态大模型实现思路,本着动手实践的态度,从零到一实现了一个多模态大模型,并命名为Reyes(睿视),R:睿,eyes:眼。
Reyes的参数量为8B,视觉编码器使用的是InternViT-300M-448px-V2_5,语言模型侧使用的是Qwen2.5-7B-Instruct,与NVLM-1.0等相关多模态大模型一样,Reyes也通过一个两层MLP投影层连接视觉编码器与语言模型。最终,Reyes-8B(0.447分)以更小的参数量在MMMU-benchmark得分超越llava1.5-13B(0.367分)。
-
模型权重开源地址:https://modelscope.cn/models/yujunhuinlp/Reyes-8B
-
github:https://github.com/yujunhuics/Reyes
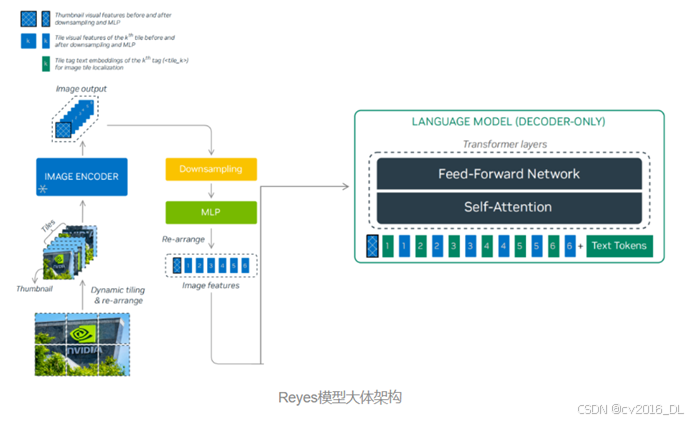
Reyes模型架构
-
视觉编码器:InternViT-300M-448px-V2_5(https://modelscope.cn/models/OpenGVLab/InternViT-300M-448px-V2_5)
-
LLM侧:Qwen2.5-7B-Instruct(https://modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct)
模型实现:ReyesModel
class ReyesModel(PreTrainedModel):
config_class = ReyesConfig
main_input_name = 'pixel_values'
_supports_flash_attn_2 = True
_no_split_modules = ['InternVisionModel', 'Qwen2DecoderLayer']
def __init__(self, config: ReyesConfig, vision_model=None, language_model=None, use_flash_attn=True):
super().__init__(config)
assert version_cmp(transformers.__version__, '4.44.2', 'ge')
image_size = config.force_image_size or config.vision_config.image_size
patch_size = config.vision_config.patch_size
self.patch_size = patch_size
self.select_layer = config.select_layer
self.llm_arch_name = config.llm_config.architectures[0]
self.template = config.template
self.num_image_token = int((image_size // patch_size) ** 2 * (config.downsample_ratio ** 2))
self.downsample_ratio = config.downsample_ratio
self.ps_version = config.ps_version
use_flash_attn = use_flash_attn if has_flash_attn elseFalse
config.vision_config.use_flash_attn = Trueif use_flash_attn elseFalse
config.llm_config._attn_implementation = 'flash_attention_2'if use_flash_attn else'eager'
logger.info(f'num_image_token: {self.num_image_token}')
logger.info(f'ps_version: {self.ps_version}')
if vision_model isnotNone:
self.vision_model = vision_model
else:
self.vision_model = InternVisionModel(config.vision_config)
if language_model isnotNone:
self.language_model = language_model
else:
if config.llm_config.architectures[0] == 'Qwen2ForCausalLM':
self.language_model = Qwen2ForCausalLM(config.llm_config)
# self.language_model = AutoLigerKernelForCausalLM(config.llm_config)
else:
raise NotImplementedError(f'{config.llm_config.architectures[0]} is not implemented.')
vit_hidden_size = config.vision_config.hidden_size
llm_intermediate_size = config.llm_config.intermediate_size
llm_hidden_size = config.llm_config.hidden_size
self.mlp1 = nn.Sequential(
nn.LayerNorm(vit_hidden_size * int(1 / self.downsample_ratio) ** 2),
nn.Linear(vit_hidden_size * int(1 / self.downsample_ratio) ** 2, llm_intermediate_size, bias=False),
nn.GELU(),
nn.Linear(llm_intermediate_size, llm_hidden_size, bias=False)
)
self.img_context_token_id = None
self.conv_template = get_conv_template(self.template)
self.system_message = self.conv_template.system_message
if config.use_backbone_lora:
self.wrap_backbone_lora(r=config.use_backbone_lora, lora_alpha=2 * config.use_backbone_lora)
if config.use_llm_lora:
self.wrap_llm_lora(r=config.use_llm_lora, lora_alpha=2 * config.use_llm_lora)
def wrap_backbone_lora(self, r=128, lora_alpha=256, lora_dropout=0.05):
lora_config = LoraConfig(
r=r,
target_modules=['attn.qkv', 'attn.proj', 'mlp.fc1', 'mlp.fc2'],
lora_alpha=lora_alpha,
lora_dropo