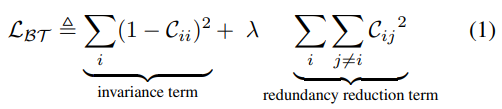概述
机器学习中有四种主要学习方式:
-
监督式学习 (Supervised Learning):这种学习方式通过使用带有标签的数据集进行训练,目的是使机器能够学习到数据之间的关联性,并能够对新的、未见过的数据做出预测或分类。应用领域包括语音识别、图像识别、医学诊断等。监督学习通常需要大量的标注数据,因此获取和维护这些数据集可能非常昂贵和耗时。
-
非监督式学习 (Unsupervised Learning):非监督式学习使用未标注的数据,通过算法来发现数据中的结构和模式。这种学习方式适合于市场细分、社交网络分析、异常检测等任务。自监督学习 (Self-Supervised Learning) 是非监督学习的一种,它通过从数据本身生成伪标签来训练模型。
-
半监督式学习 (Semi-Supervised Learning):这种学习方式结合了监督学习和非监督学习的特点,使用少量的标记数据和大量的未标记数据。这种方法特别适用于标签获取成本较高,但未标记数据容易获得的情况。例如,“Noisy Student”是一种半监督学习方法,通过自我训练和模型蒸馏的方式,利用未标记数据来提高模型性能。
-
强化学习 (Reinforcement Learning):强化学习是一种让机器通过与环境的交互来学习最优行为策略的方法。它通常涉及到一个智能体(agent)在一定的策略下,通过尝试和错误来最大化累积奖励。强化学习在游戏、机器人控制和推荐系统等领域有广泛应用。
每种学习方式都有其特定的应用场景和优缺点,研究人员会根据实际问题和数据的可用性来选择最合适的方法。

由于数据标注的成本较高或特定领域的数据难以获得,因此研究的方向逐渐关注于无监督学习。而本文要介绍的自监督学习就是属于无监督学习的一种,它通过挖掘大量无标签数据本身的信息,人为地制造标签(预文本),这样一来就可以使用监督式学习的方式进行训练,正如其名称所示,通过自己来监督自己。目的是希望模型能够学习到数据中的通用表征,并应用至不同的下游任务里。
训练步骤会分为两部分,首先用这些未标记数据训练一个初步的模型产生出一种通用的表征,接着再根据下游任务使用少量的有标签数据进行微调(这边只需要少量有标签数据是因为模型在第一部分时就已经将参数训练得差不多了)。

自监督学习主要分为五种:生成方法(Generative methods)、预测方法(Predictive methods)、对比方法(Contrastive methods)、引导方法(Booststrapping methods)、额外正则化方法(Simply Extra Regularization methods)。
一、生成方法(Generative methods)
通过训练模型在像素空间的重建能力,可以获得对图像理解的语义信息。换句话说,就是先将图像上的某些像素进行遮蔽(mask),让模型能够还原回原来的图像内容。
例如,图像修复(Image Inpainting)的方法,使用的是基于自编码器(AutoEncoder)的模型——上下文编码器(Context Encoders),根据图像缺失部分的周围环境生成出合理的假设。这种方法通过学习图像中存在的模式,并利用这些模式来填充缺失或损坏的区域,从而达到恢复图像的目的。
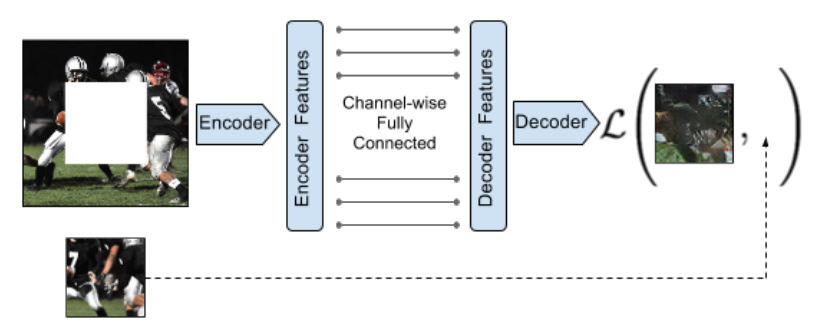
也可以利用自然语言处理(NLP)模型,如BERT和GPT,来执行类似的图像处理任务。首先,将图像转换为一维数据再输入到模型中。下图(a)展示了使用GPT进行训练的方法,该方法是利用图像中的一部分像素来预测下一部分像素;下图(b)则是使用BERT,方法是在一维图像数据中遮蔽(mask)一些像素,让模型预测这些被遮蔽的像素。然后,这些模型就可以应用到下游任务中。更多详细信息可以参考Image GPT官方网站。

二、预测方法(Predictive methods)
由于模型仅基于像素生成高级表示是一项较为困难的任务,并且计算成本也很高,因此研究者们希望采用其他不涉及图像重建的方法。预测性方法(Predictive methods)不需要重建图像,而是通过对图像进行各种变换,然后让模型恢复原状。
其中较为著名的一篇论文是ICCV 2015年的《Unsupervised Visual Representation Learning by Context Prediction》(无监督视觉表示学习通过上下文预测),该论文通过在图像中选取两个区域(patch),并利用其中一个区域预测另一个区域的相对位置。
这种方法的核心思想是利用图像内部的空间上下文信息来训练一个丰富的视觉表示。具体来说,给定一个大型的未标记图像集合,论文中的方法从每张图像中提取随机的图像块对,并训练一个卷积神经网络来预测第二个图像块相对于第一个图像块的位置。这项任务的挑战在于,模型需要能够识别物体及其部分,以便理解它们之间的相对空间位置。研究表明,通过这种方式学习到的特征表示能够捕捉图像间的视觉相似性,例如,这种方法可以从Pascal VOC 2011检测数据集中无监督地发现物体,如猫、人甚至鸟类。
此外,论文还展示了学习到的卷积网络可以在RCNN框架中使用,并且与随机初始化的卷积网络相比,提供了显著的性能提升,在使用Pascal提供的训练集注释的算法中达到了最先进的性能水平。
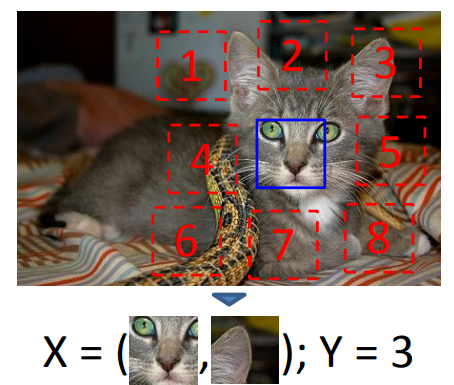
论文 Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles 提出了一种无监督学习方法,用于学习图像表示,其核心思想是通过解决“拼图”问题来训练模型。这种方法与之前提到的利用图像中选定的 patch 的方法有相似之处,但具体实施上存在一些差异。
在这篇 ECCV 2016 的论文中,不是简单地选择两个或几个 patch,而是一次性选择图像中的九个 patch。这些 patch 被随机地从原始图像中裁剪出来,然后以某种顺序排列,形成所谓的“拼图”。接着,模型的任务是识别这些 patch 的组成分布,并预测它们正确的顺序,以便能够重建原始图像的布局。
这个过程可以视为一种自监督学习任务,因为模型的训练目标是基于图像本身的固有结构,而不是依赖于外部的标注信息。通过这种方式,模型被训练来识别图像中的对象部分以及它们的空间排列。这种方法的优势在于,它能够学习到关于对象的语义信息,并且能够捕捉到对象部分之间的空间关系。
论文中提出的“拼图”方法,通过强制模型解决拼图问题,学习到的特征表示能够很好地迁移到其他视觉任务中,如对象检测和分类。实验结果表明,这种方法学习到的特征在多个迁移学习基准测试中超越了当时的最先进方法。


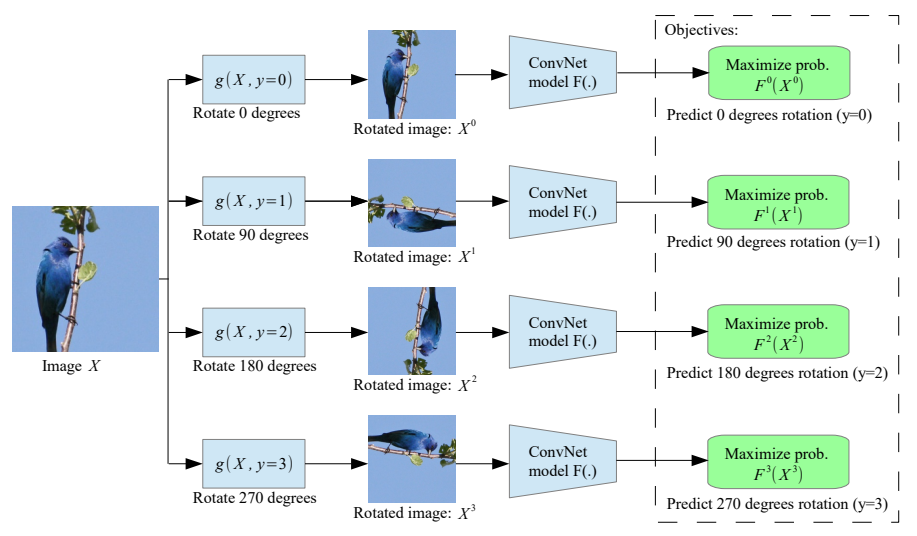
这篇论文《Unsupervised Representation Learning by Predicting Image Rotations》确实是ICLR 2018的一篇会议论文,作者是Spyros Gidaris, Praveer Singh, Nikos Komodakis,他们来自University Paris-Est, LIGM Ecole des Ponts ParisTech。这篇论文提出了一种新颖的无监督表示学习方法,通过训练卷积神经网络(ConvNets)来识别输入图像所应用的2D旋转变换。
这种方法的核心思想是,如果一个模型能够识别出图像被旋转了多少度,那么它必须首先学习到图像中对象的概念,比如它们在图像中的位置、类型和姿态。具体来说,该方法将图像旋转四次,即0°、90°、180°和270°,然后训练ConvNets来识别这四种旋转中的一种。尽管这个任务看起来非常简单,但论文中通过实验表明,它实际上为语义特征学习提供了一个非常强大的监督信号。
论文中提到,这种方法在多个无监督特征学习基准测试中进行了全面评估,并在所有测试中展示了最先进的性能。例如,在PASCAL VOC 2007检测任务中,使用这种方法无监督预训练的AlexNet模型达到了54.4%的mAP(平均精度均值),仅比有监督情况下低2.4个百分点。当将无监督学习到的特征迁移到其他任务,如ImageNet分类、PASCAL分类、PASCAL分割和CIFAR-10分类时,也获得了类似的显著结果。
此外,论文还提供了代码和模型的GitHub链接:https://github.com/gidariss/FeatureLearningRotNet,供有兴趣的研究者进一步研究和使用。
最后则是使用聚类(Cluster)的方式结合CNN,并进行端到端(end to end)的训练,在ImageNet分类和其他迁移学习任务上都获得了很好的结果。
这边讨论两篇相关论文,首先是ECCV 2018的Deep Clustering for Unsupervised Learning of Visual Features,使用k-means对大量未标记的数据进行训练得到伪标签(Pseudo-labels),再用监督学习的方式去学习。

第二篇是ICLR 2020的Self-labelling via simultaneous clustering and representation learning,在该篇论文中加入了约束(constraint)——所有样本预测的标签分布要尽可能地平均分配,因为聚类算法得到的伪标签不一定是正确的,可能会产生某个类别占了大多数的情况。

三、对比方法(Contrastive methods)
对比学习(Contrastive Learning)目前在自监督学习中最为广泛运用,其概念为相同类别的图像间的相似度越高越好(即距离尽可能地近),不同类别的图像相似度越低越好(即距离尽可能地远),模型架构主要是使用孪生网络(Siamese Network)。
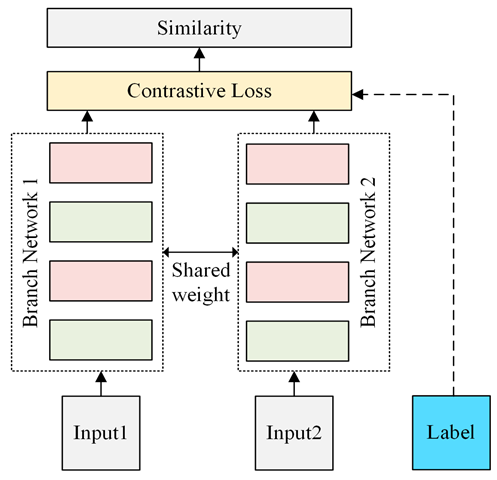
但我们的数据并没有标签,该怎么区分哪些图像是相同类别呢?因此我们先对图像做各种数据增强(data augmentation)后,再让模型去预测经过数据增强后的图像与原图之间的相似度,该结果要越高越好,同时对其他图的预测则是越低越好。

代表作有FAIR提出的MoCov1、MoCov2、MoCov3,Google Brain提出的SimCLRv1、SimCLRv2,这边仅介绍MoCov1及SimCLRv1,若想了解更详细的内容可参考其论文和以下我觉得写得很好的文章:
- 大概是全网最详细的何恺明团队顶作MoCo系列解读!(上)
- 大概是全网最详细的何恺明团队顶作MoCo系列解读…(完结篇)
- MoCo 三部曲
- Self-Supervised Learning 超详细解读(二):SimCLR系列
3.1 MoCov1
主要贡献为提出字典队列(Dictionary as a queue)、动量编码器(Momentum Encoder)、打乱批量归一化(Shuffling BN)
从过往的实验结果中可知,使用更多的负样本(negative samples)来训练能得到更好的结果,但负样本的数量与批量大小(batch size)成正比,而批量大小越大需要越多的运算成本,因此没办法使用太大的批量大小。为了解决难以运用大量负样本的问题,采用了字典队列(Dictionary as a queue)的方式,就是将原本的记忆库(memory bank,用于保存所有数据的表征)改成队列的形式来储存。
字典队列的做法为每个训练周期(epoch)会将一个批量的表征加入队列(enqueue),并移除保存最久的一个批量的表征(dequeue),这样一来这个队列字典的总数不会随着训练周期而变大,不会占用太多的内存及运算成本。
动量编码器(Momentum Encoder)是指下图 © 中关键编码器(key encoder)的参数θ_k的更新方式改为查询编码器(query encoder)参数θ_q的移动平均,目的是为了让队列字典中的数据保持一致性,公式如下
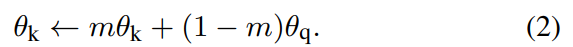
在提出动量编码器之前的参数更新是使用下图 (b) 的更新方法,对于样本x_q做数据增强得到正样本、从记忆库中抽取出k个作为负样本后,再去计算对比损失(Contrastive loss)并更新θ_q和这些负样本的键值(key value,即k值),这边并不会去做关键编码器参数θ_k的反向传播。这样的做法会导致某些键值在很多次迭代后才被采样并更新,但查询编码器每次都会更新,以至于抽取出的样本与当前的查询编码器没有一致性。
打乱批量归一化(Shuffling BN)是针对数据泄露(Data Leakage)的解决方法,因为模型能通过每个批量间计算的平均值和方差找到一些信息而导致数据泄露的现象。因此在训练前会先将样本的顺序打乱,提取特征后再恢复原本的顺序。

3.2 SimCLRv1
主要贡献为提出数据增强组合(Data augmentation combination)的想法、增加投影头(Projection head)、归一化温度缩放交叉熵损失函数(NT-Xent loss function)
其思路非常简单,首先抽取一些图像组成一个批量,将批量里的图像做不同的数据增强,其中包括随机裁剪(random crop)、颜色失真(color distortion)、高斯模糊(Gaussian blur),接着进行对比学习(Contrastive Learning),即区分是否为相同的图像。
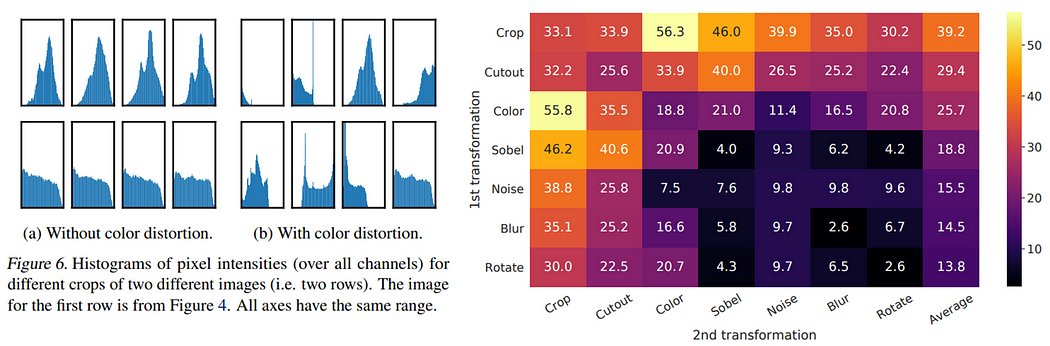
对于数据增强,论文提到只单纯用随机裁剪没有太大效果,需要结合颜色失真,这是因为随机裁剪后的图像与原图像在像素值的分布差异不大(下图左)。同时也实验了使用两种数据增强组合的结果会更好(下图右)。
SimCLRv1的整体流程如下图所示,由编码器(Encoder)得到的表征会再经过投影头(Projection head)映射到较低维的空间中,得到新的表征z_i、z_j。该投影头是一个两层的多层感知机(MLP),只在自监督学习训练时使用,其作用为去除编码器中数据增强后的信息,仅关注于原始数据的信息。
当要在下游任务上进行微调(Fine-tune)时就不会使用到投影头,会另外接一层非线性分类器(Non-Linear Classifier)。

归一化温度缩放交叉熵损失函数(NT-Xent loss function)的计算方式分为三个步骤:
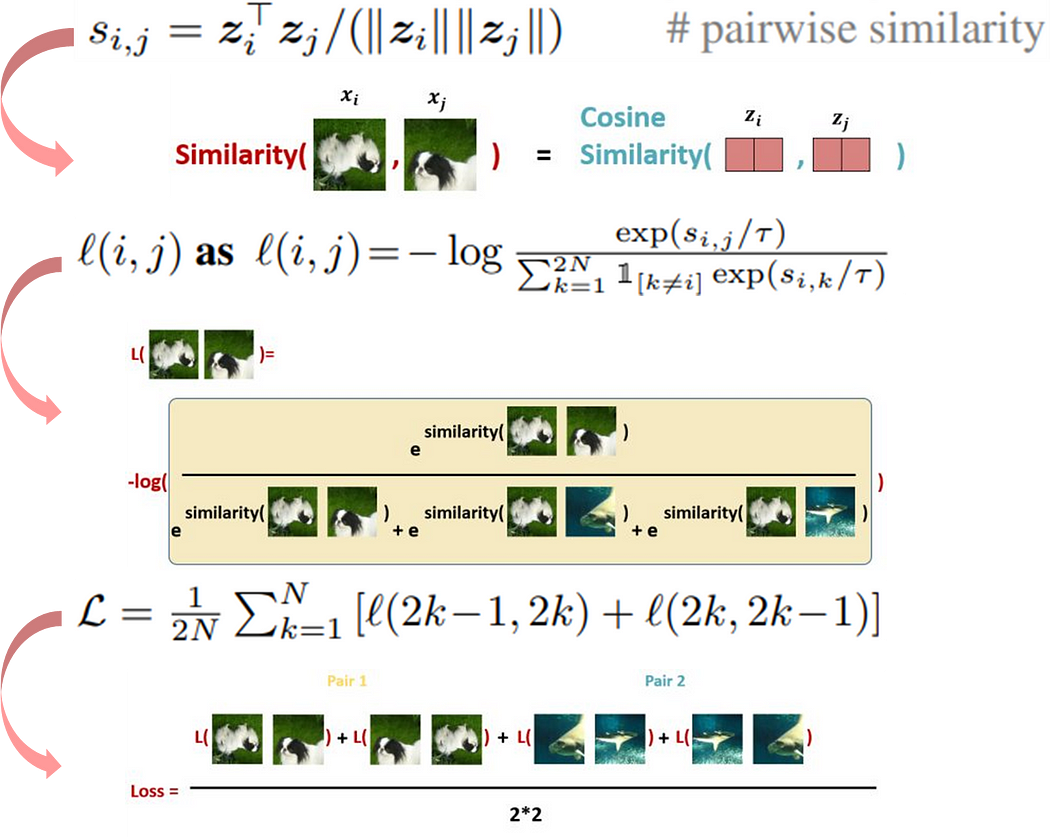
- 计算一组正样本对(pair)间的相似度,并且每一个批量中的所有正样本对都要计算(每次只计算一个批量是为了降低运算量)。
- 计算正样本对的相似度概率,分子为正样本对的相似度、分母为所有正样本对和负样本对的相似度之和。值得注意的是对于同一个正样本对需要交换顺序再计算一次。公式中的N表示为一个批量所拥有的图像张数,经过数据增强后会有2N张图像。
- 将每一个批量中的所有正样本对计算出来的损失加总取平均。
四、 引导方法(Booststrapping methods)
由于对比方法需要选取负样本,且其数据特性不能太简单,也不能太难,因此如何选择负样本是一个困难的问题。
负样本的主要贡献在于避免发生模型坍塌(model collapse)的现象,若训练数据只有正样本,模型会倾向于得到平凡解(trivial solution)。这句话的意思是指不论输入什么样的图像,模型的两个分支皆输出一模一样的表征以得到最高的相似度。
那有没有办法是不使用负样本的呢?以下来介绍两篇相关论文:BYOL、SimSiam。
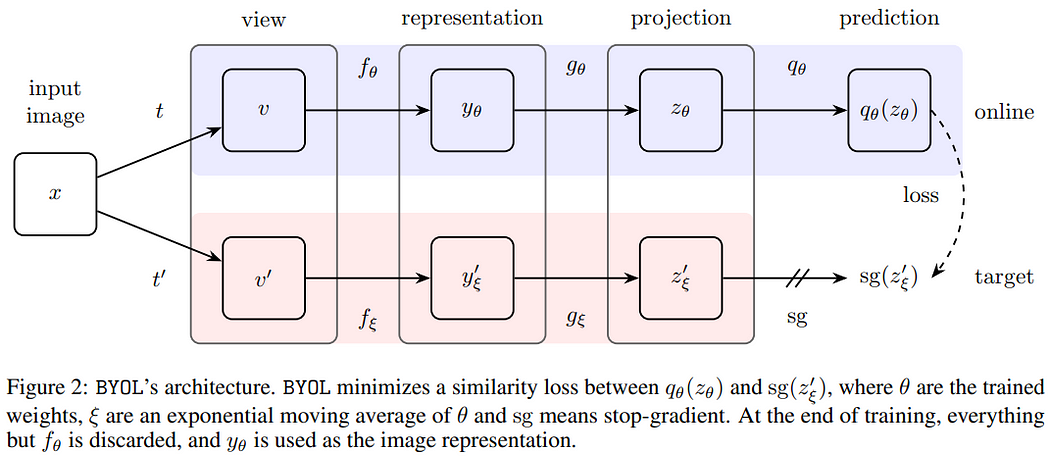
4.1 BYOL(Bootstrap your own latent)
主要贡献为新增预测器(predictor)、使用指数移动平均(exponential moving average)、批量归一化(batch normalization)、L2损失(L2 loss)
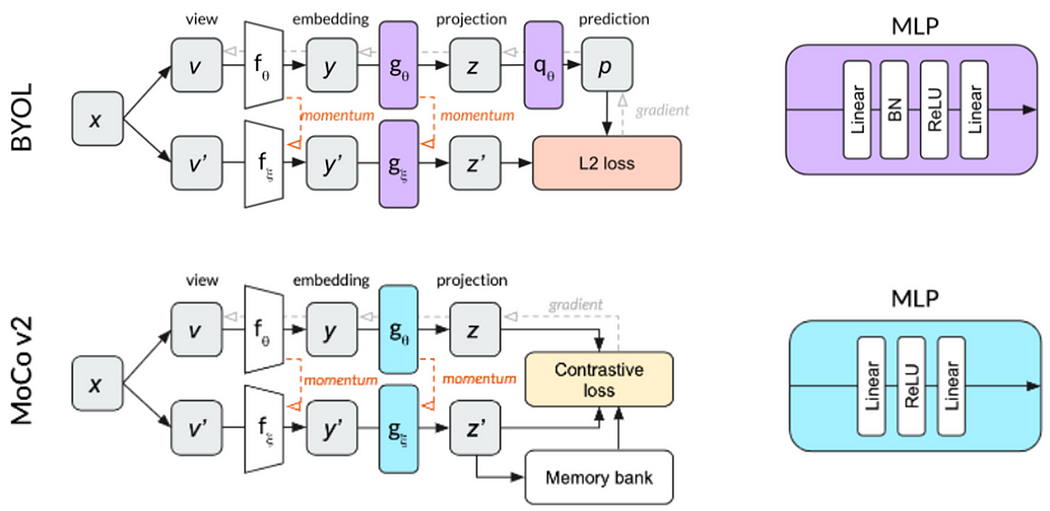
BYOL的模型架构与MoCov2类似,MoCov2是基于MoCov1融合SimCLRv1的做法,加入投影头(Projection head)以及更多的数据增强(增加了模糊增强,blur augmentation)。
整体流程如下:
- 先将图像x做两种不同的数据增强t, t′,分别送入不同的分支,其中一个分支称为在线分支(online,该分支多加了预测层),另一个称为目标分支(target)。
- 各自经过视图(得到数据增强后的结果v, v′)、表征(经过编码器f_θ, f_ξ得到表征y_θ, y′_ξ)、投影(经过投影头g_θ, g_ξ映射到较低维的空间)。
- 在在线分支会再经过一层预测(为一个两层的MLP),接着与目标分支的输出z′_ξ计算损失。BYOL的损失函数使用L2损失(下式1),另外也跟SimCLRv1一样会交换顺序再计算一次(下式2)。
- 与MoCo相同,损失只会反向传播给在线分支(下式3),而目标分支的参数是由在线分支参数θ的指数移动平均(下式4)的方式来更新,下图中的sg指停止梯度传播(stop-gradient)。
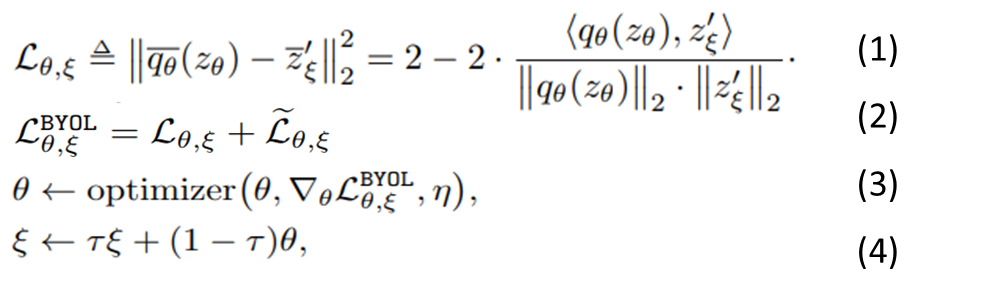
这样的设计方式能防止模型坍塌的关键在于新增预测器和停止梯度传播并使用指数移动平均来更新目标分支,让两个分支的架构及参数不完全相同,模型较难往平凡解的方向走。
除此之外,还有一个大功臣——在投影头中加入了批量归一化。看下图BYOL和MoCov2的比较,BYOL的投影头、预测器都使用相同的MLP架构,而MLP中多新增了批量归一化。
在Understanding Self-Supervised and Contrastive Learning with “Bootstrap Your Own Latent” (BYOL)一文中实验了各种批量归一化的消融研究(ablation study),发现若不使用批量归一化就相当于随机的结果,并猜测使用批量归一化是一种隐性的对比学习。意思是指这样的操作就是将批量中的每个图像与批量的图像平均做比较,而批量中的其他图像为当前图像的负样本。
基于这个观点,原文作者发表了一篇研究BYOL works even without batch statistics来解释。作者认为批量归一化之所以有效是因为能让模型有合适的初始化参数,以至于使得训练更稳定,并实验使用组归一化(Group normalization)和权重标准化(weight standardization)也能有相同效果。

4.2 SimSiam(Simple Siamese)
主要贡献为使结构更加简洁,不需要使用负样本对(negative sample pairs)、大批量(large batches)、动量编码器(momentum encoders)
SimSiam由FAIR提出,其模型架构与BYOL非常相似,去除了使用指数移动平均的更新方式,直接使用孪生网络(Siamese network),即两分支的编码器f共享参数,如下图和伪代码可以看出整体结构更简洁。
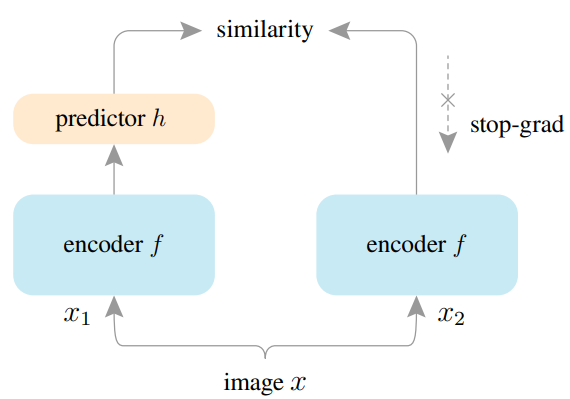
架构图

作者做了一系列的消融研究来分析让模型免于坍塌的原因,例如:有无使用停止梯度传播(stop-gradient)、预测器(Predictor)、批量大小(64~4096)、批量归一化(Batch Normalization)、相似性函数(Similarity Function)、分支结构对称与否(Symmetrization/Asymmetrization/Asymmetrization 2x),大多不可避免影响准确度,除了拿掉停止梯度传播或预测器之外,其他操作并不会造成模型坍塌的现象。
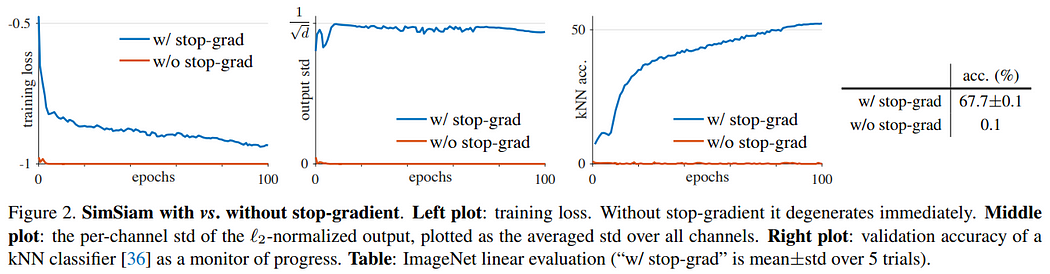
作者认为最关键的原因在于停止梯度传播,相当于引入了额外的变量,让SimSiam的实现类似于期望最大化(Expectation-Maximization, EM)算法,并针对这个假设做实验来验证。
在该假设下的损失函数(下式5)中F_θ为编码器f、τ为数据增强、η为引入的额外变量(下标x是指图像x,这边可以将η_x想象成是停止梯度传播分支的表征),接着针对该损失函数进行优化(下式6),期望能最小化两分支编码器输出的距离的期望值。
首先固定η求解θ(下式7),再固定θ去求解η(下式8),反复迭代进行训练,目标是得到下式11的结果(将η_x代入至下式5、6,并找出最佳参数θ)。由于η_x是图像x的表征,因此可写成如下式9的样子,下式10是指使用不同的数据增强。

五、简单额外正则化方法(Simply Extra Regularization methods)
除了引导方法外,简单额外正则化方法也能够在不使用负样本的情况下,取得优秀的结果。概念为从表征本身挖掘更多的信息去学习,在训练过程中加上一些正则化,让正样本经过数据增强后的两个表征间越相似越好。
以下来介绍两篇相关论文:SwAV、Barlow Twins。
5.1 SwAV(Swapping Assignments between Views)
主要贡献为提出原型(Prototypes)、多裁剪策略(Multi-crop strategy)
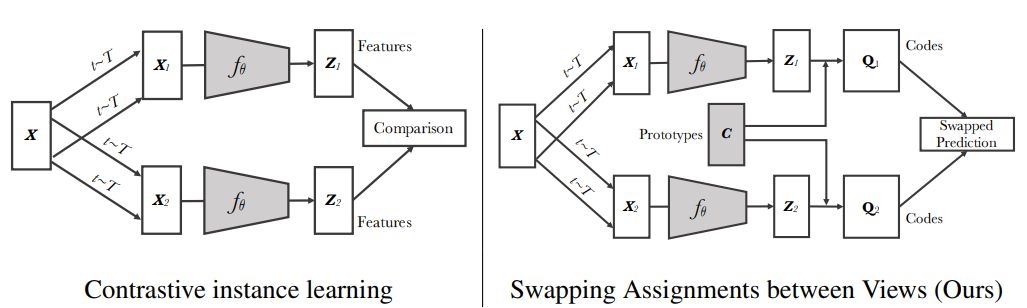
在对比学习的基础上结合聚类(clustering),不直接比较表征,而是比较不同视角(View)下的聚类结果(clustering assignments),并且该结果可以互相交换预测(Swapping)。
两者的差异如下图,在SwAV的做法中会将表征z_i与原型C做内积后再进行softmax,计算出相似程度得到代码Q,接着交叉预测不同视角的代码,其中原型为聚类中心。
损失函数定义为交叉预测结果之和
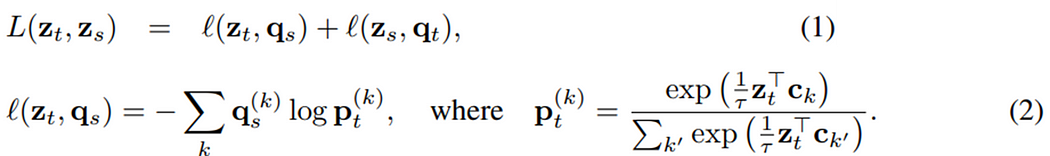
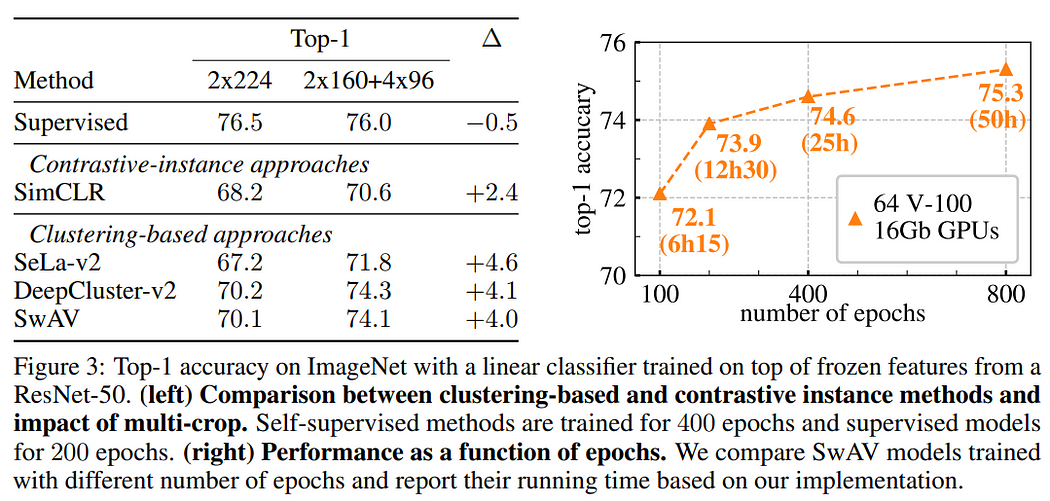
此外,提出了新的数据增强方法——多裁剪(Multi-crop),由2个较大的裁剪和V个较小的裁剪组成(例如:2个160分辨率+4个96分辨率),能够学习更局部的特征、提升正样本的数量,也不会增加计算量。由下图的实验结果可得知采用多裁剪能增加4%的准确率,而且不只是在SwAV有效,对于其他的自监督学习(SSL)方法也有很大的帮助。
以下是各个孪生架构的比较图,可以看出这些模型的结构都非常相似。
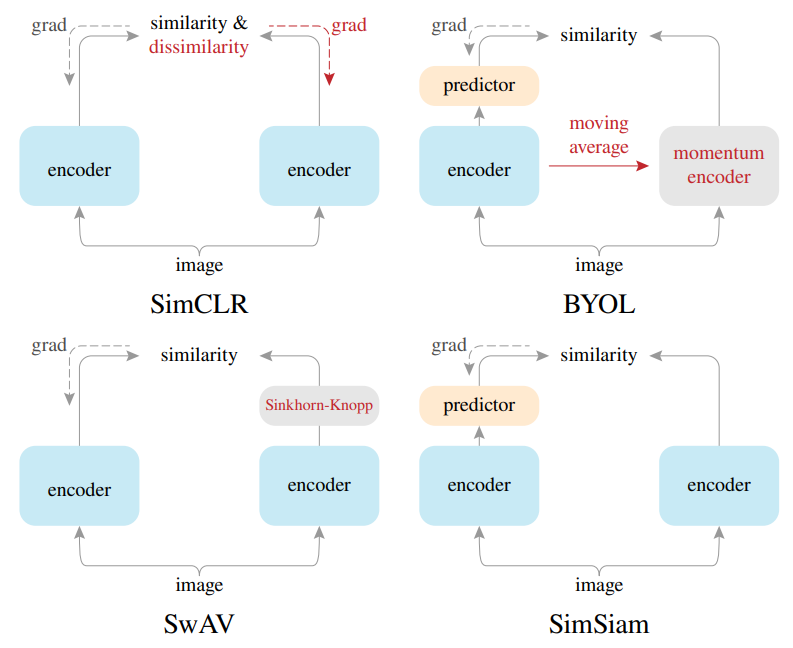
5.2 Barlow Twins
主要贡献为提出交叉相关矩阵(cross-correlation matrix)
前半部与对比学习相同,后半部则是对批量中的所有图像提取的表征(即下图的嵌入向量Embeddings)去计算交叉相关矩阵,并期望该矩阵近似单位矩阵(identity matrix),也就是对角线上的值为1,其余的值为0。如此一来,可以表示为相同样本在不同数据增强下所得到的表征非常相近,而不同样本则会越远。
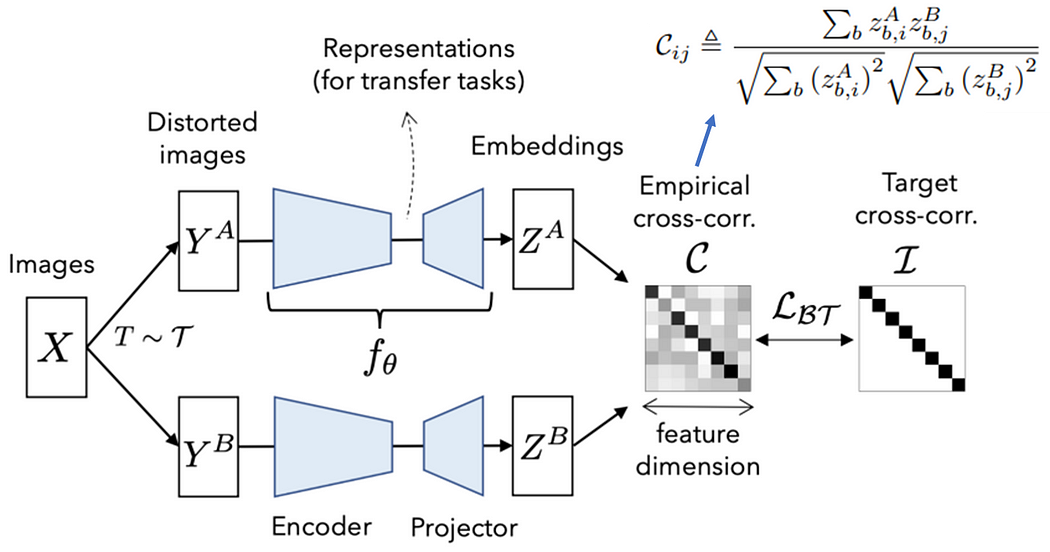
损失函数定义如下:
- 不变性项(invariance term)为让对角线上的元素尽可能地为1
- 冗余减少项(redundancy reduction term)为让不在对角线上的元素尽可能地为0
- λ用于调节这两项的权衡(trade-off)