自监督学习(Self-Supervised Learning, SSL)是一种机器学习方法,它通过利用未标注的数据自动生成标签来训练模型。与传统的监督学习需要大量标注数据不同,自监督学习通过从数据本身中提取结构化的知识,消除了对人工标注数据的依赖。通过这一过程,模型能够学习到有用的特征表示,通常可以用于图像分类、语音识别、自然语言处理等各种任务。
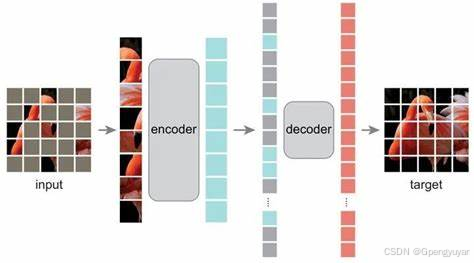
自监督学习的基本思想:
自监督学习的核心是“自我生成标签”。它并不是依赖人工标注数据集,而是通过设计特定的任务,强迫模型从未标注的数据中自己构造目标(标签)进行训练。这些任务通过数据变换、遮挡、预测等方式,使模型能够从数据本身学习出深层的结构和规律。
自监督学习的核心流程:
-
构造伪标签:自监督学习的第一步是从数据本身生成伪标签。伪标签并非人工提供的标签,而是通过对数据进行某些变换或遮挡,构造出需要预测的目标。例如,在图像中遮挡掉一部分区域,让模型预测该区域内容,或在文本中遮挡一个单词,预测这个单词是什么。
-
设计预任务(Pretext Tasks):预任务是自监督学习中的关键。它通过设计一种任务,让模型通过输入数据学习有意义的特征。常见的预任务有图像重建、预测图像变换、上下文预测、对比学习等。
-
特征学习:通过训练模型完成预任务,模型会学习到数据中的内在结构。模型学到的特征并不依赖于人工标签,而是通过数据的关系和结构自发地获得的。
-
迁移学习(Transfer Learning):当模型在自监督任务上训练好后,学到的特征可以迁移到其他下游任务上(如图像分类、目标检测、文本分类等),通常只需要少量标注数据即可进行微调,取得良好的效果。
自监督学习与监督学习的对比:
-
监督学习(Supervised Learning):需要大量标注数据,输入数据与标签一一对应,模型学习从输入到输出的映射关系。
示例:给定带有标签的图像(如猫、狗标签),模型学习从图像像素到类别标签的映射。
-
自监督学习(Self-Supervised Learning):不需要标注数据,模型通过设计任务从未标注数据中提取有用的特征。伪标签由数据本身生成,训练过程不依赖人工标注。
示例:通过图像的局部遮挡或变换,让模型预测被遮挡或变换的部分。最终,模型学习到能够区分图像、识别物体等特征。
自监督学习的主要类型和方法:
自监督学习有多种实现方法,根据任务的不同,可以分为以下几类:
1. 生成型任务(Generative Tasks)
生成型任务要求模型通过输入数据生成某些目标输出。例如:
-
图像重建(Image Reconstruction):例如,**自编码器(Autoencoders)**通过编码-解码过程,学习图像的低维表示,然后重建图像。这个任务的目标是使得重建的图像与输入图像尽可能相似。
-
生成掩码(Masked Image Modeling):例如,**Masked Autoencoders (MAE)**在图像中遮挡掉部分像素,然后让模型预测或重建被遮挡的部分。模型在训练过程中学习如何恢复图像结构。
2. 预测任务(Prediction Tasks)
预测任务通过对输入数据进行变换,构造目标并训练模型进行预测。常见的任务包括:
-
文本掩码(Masked Language Modeling, MLM):在自然语言处理中,BERT模型通过随机遮挡输入文本中的一些单词,然后训练模型去预测被遮挡的单词。例如,“我喜欢吃[mask]”任务,模型的目标是预测被遮挡的单词(如“苹果”)。
-
预测图像变换:如**旋转预测(Rotation Prediction)**任务,模型需要判断输入图像经过多少度旋转(例如,90度、180度、270度等)。这种方法强迫模型学习图像的全局结构,而不仅仅依赖局部特征。
3. 对比学习(Contrastive Learning)
对比学习通过最大化同类样本的相似性,最小化不同类样本的相似性,学习到样本之间的关系。对比学习的目标是学习到数据的深层次结构,而不需要明确的标签。常见方法包括:
-
SimCLR(Simple Contrastive Learning of Representations):该方法通过对同一图像应用不同的数据增强(例如裁剪、旋转、颜色变换等)生成正样本对,同时将不同图像作为负样本对。模型的任务是使得正样本对的特征表示更接近,负样本对的特征表示更远离。
-
BYOL(Bootstrap Your Own Latent):BYOL通过最大化同一图像在不同视图下的相似性来进行训练,但与SimCLR不同,它不使用负样本。这个方法表明,模型可以通过正样本对的对比学习而不需要负样本,从而进一步提高自监督学习的效率。
4. 序列学习任务(Sequence Learning Tasks)
自监督学习在序列数据(如文本、语音、视频等)中的应用也是十分广泛的:
-
下一个单词预测(Next Word Prediction):在自然语言处理任务中,模型通常通过前面的文本序列预测下一个单词。例如,GPT系列模型就是基于这种方式进行训练的。
-
时间序列预测:在视频和语音处理中,模型可以通过已知的时间序列预测未来的帧或样本。这样,模型就能够捕捉到序列中的动态变化。
自监督学习的优势:
- 减少标注数据需求:自监督学习减少了对人工标注数据的需求,尤其在标注数据稀缺且昂贵的领域,自监督学习显得尤为重要。
- 通用特征学习:通过训练模型完成预任务,模型能够学习到数据中的高质量特征,这些特征可以迁移到其他任务中,如分类、检测、生成等。
- 可扩展性:自监督学习能够处理大规模的无标注数据,适应各种不同的任务和数据类型(如图像、文本、音频等)。
自监督学习的挑战:
- 预任务设计:自监督学习的效果高度依赖于预任务的设计。如何设计出有意义且能有效训练模型的任务是一个重要挑战。
- 计算资源需求:自监督学习通常需要大量的计算资源和时间,尤其是在大规模数据集和深度模型的训练中。
- 任务泛化:虽然自监督学习在一些任务上表现出色,但将模型从一个任务迁移到另一个任务时,可能需要进行细致的微调,确保特征能够有效泛化。
总结:
自监督学习是一种非常灵活且高效的机器学习方法,它通过从未标注数据中生成伪标签,使得模型能够在没有人工标注的情况下学习到有意义的特征。这种方法不仅减少了标注数据的需求,还能通过学习数据的内在结构,提取通用的特征,广泛应用于图像、文本、音频等多个领域。