0# 前言:老朋友,好久不见!
各位观众老爷们,好久不见,甚是想念!最近在疯狂加班,总算挤出时间给大家码了这篇干货满满的文章~ 别催更啦,这就给你们安排上!
说到信息搜集,大家脑海里是不是立马浮现出Web外部打点的那些暴露信息?

But!在内网渗透中,信息搜集的重要性,那可是直接关系到你能不能成功拿下目标的关键因素!毫不夸张地说,信息搜集决定成败!

尤其是想搞持久化渗透,对内网信息的搜集更是重中之重。今天就给大家分享一些内网渗透的信息搜集骚操作,绝对让你眼前一亮!

1# 内网渗透信息搜集新思路:别再啃老黄历啦!
既然是“骚”姿势,那些常规的查系统信息啥的,咱就不浪费口舌了。咱要讲的是那些你可能没听过、没见过的“秘密武器”!

内网渗透,大致可以分为三个阶段:权限提升、权限维持、横向移动。

每个阶段需要搜集的信息和发挥的作用都不一样,下面简单给大家捋一捋:
1.1 权限提升:别让菜鸟教程限制了你的想象力!
权限提升阶段,信息搜集重点关注以下几个方面:
- 本机系统版本: 搞清楚系统是哪个版本的,才能对症下药。
- 本机系统内核版本: 内核版本信息,提权的关键。
- 本机系统出网情况: 能不能连外网,决定了你的攻击方式。
- 本机开启的服务和端口: 看看有哪些服务在跑,有没有可利用的漏洞。
- 本机系统环境变量: 环境变量里可能藏着敏感信息哦。
- 本机运行的应用和进程: 关注高权限的进程,看看能不能从中搞点事情。
- 本机计划任务内容: 计划任务也是提权的好帮手。
- 本机中间件环境利用: 中间件漏洞,yyds!
骚思路: 找到系统上运行的高权限服务,然后想办法拿到它的配置文件或者直接接管,就能通过这个高权限服务来提权啦!
1.2 权限维持:让你的后门坚如磐石!
权限维持阶段,信息搜集要点如下:
- 本机系统内核版本: 再次确认内核版本,方便后续操作。
- 本机系统账号信息: 都有哪些用户,密码强度如何?
- 本机系统用户组信息: 看看有没有可以利用的用户组。
- 本机系统出网情况: 确保你的后门能稳定连接。
- 本机计划任务内容: 安排一个计划任务,定期执行你的后门。
- 本机运行的应用和进程: 找一个合适的进程,把你的后门藏进去。
- 注册表信息利用(Windows): Windows注册表,一个充满秘密的地方。
- WMI利用、映像劫持(Windows): 高级玩法,让你的后门更隐蔽。
- SSH后门利用(Linux): Linux下的SSH后门,yyds!
- 本机中间件环境利用: 再次利用中间件漏洞,巩固你的权限。
骚思路: 上线免杀内存马和C2,然后把进程迁移到系统进程里,再悄悄运行一个潜伏C2来持续控制;或者利用RDP/SSH/VNC这些常用的系统管理服务,插入影子账户和后门,就能“合法”地管理机器啦!
1.3 横向移动:像病毒一样扩散!
横向移动阶段,信息搜集重点关注:
- 本机系统网卡信息: 了解网络环境,才能更好地渗透。
- 本机系统建立的网络连接: 看看本机都连了哪些机器,有没有突破口。
- 抓取本机系统账户对应的密码: 密码是通行证,有了它就能去其他机器溜达了。
- 本机服务和应用对应的密码: 应用程序的密码也很重要。
- 本机服务和应用的配置文件: 配置文件里可能藏着数据库连接信息等敏感信息。
- 对内网网段进行存活探测: 看看有哪些机器还活着。
- 对存活网段内机器进行端口探测和服务探测: 探测端口和服务,寻找可利用的漏洞。
- 抓取内网的流量(tcpdump抓包): 流量里可能藏着账号密码等敏感信息。
骚思路: 通过查看本机建立的网络连接(netstat -an),发现本机调用了内网其他机器的服务(比如Redis),然后翻找本机上的配置文件或者命令行,就能接管Redis服务,再通过恶意利用内网其他机器上开放的服务(比如写入恶意SSH密钥),就能成功横向啦!
2# 内网渗透信息搜集真·骚姿势:前方高能!
上面只是开胃小菜,现在让我们来看看具体的一些内网渗透信息搜集骚操作,保证让你大呼过瘾!

2.1 针对文件内容的信息搜集:像福尔摩斯一样搜寻线索!
当你对内网一筹莫展的时候,入口机器上可能就藏着突破口! 仔细翻找本地的文件和建立的网络连接,说不定就能发现惊喜!

这里给大家准备了一份文件内容敏感词字典,拿走不谢!
jdbc:user=password=key=ssh-ldap:mysqli_connectsk-
通过快速遍历机器文件,搜索这些关键词,就能找到突破口! 这段代码我之前分享给过几个朋友,在实战中效果杠杠的!代码示例如下:
这是Python3的代码版本(支持Win和Linux):
#!/usr/bin/env python
# coding=utf-8
import os
import argparse
from tqdm import tqdm
def logo():
logo0 = r'''
_______ ______ _____ ____ __
/ ____(_)___ ____/ / __ / ___/ / __ __ __/ /_
/ /_ / / __ / __ / / / / / / / __/ / __/ / / / / /
/ /_/ / / /_/ / /___/ / / / / / __/ / __/ / / / / /
/___/ /_____/ /_/ / /_/ / /_/ / /_ /_/ /_/_/ /_/
____/__,_/__/
'''
print(logo0)
def search_files(directory, extensions):
files = []
for root, _, filenames in os.walk(directory):
for filename in filenames:
for extension in extensions:
if filename.endswith(extension):
files.append(os.path.join(root, filename))
return files
def search_content(file_path, content):
matching_lines = []
try:
with open(file_path, 'r', encoding='utf-8', errors='ignore') as file:
for line_num, line in enumerate(file, 1):
try:
if content in line:
matching_lines.append((line_num, line))
except UnicodeDecodeError as e:
print(f"[-] Unicode decode error file {file_path}, line {line_num}: {e}")
print()
return matching_lines
except:
print(f"[-] Error file {file_path}")
print()
def write_to_file(output_file, file_path, matching_lines):
with open(output_file, 'a', encoding='utf-8') as f:
f.write(f"[+] File Path: {file_path}
")
f.write(f"[=] Line Rows: {len(matching_lines)}
")
for line_num, line in matching_lines:
f.write(f"[~] In Line {line_num}: {line.strip()}
")
f.write("
")
def main():
parser = argparse.ArgumentParser(description="FindOS-Out")
parser.add_argument("-n", "--name", help="Specify the suffix", required=True)
parser.add_argument("-c", "--content", help="Specify file content", required=True)
parser.add_argument("-o", "--output", help="Specify output file", default="findout.txt")
parser.add_argument("-d", "--directory", help="Target directory", default="./")
args = parser.parse_args()
directory = args.directory
extensions = args.name.split(',')
content = args.content
output_file = args.output
files = search_files(directory, extensions)
for file_path in tqdm(files, desc="Searching files", unit="file"):
matching_lines = search_content(file_path, content)
if matching_lines:
write_to_file(output_file, file_path, matching_lines)
if __name__ == "__main__":
logo()
print("[+] Runing Search..")
main()
print("[+] Out to findout.txt..")

这是Python2的代码版本(支持Win和Linux):
import os
import argparse
def logo():
logo0 = '''
_______ ______ _____ ____ __
/ ____(_)___ ____/ / __ / ___/ / __ __ __/ /_
/ /_ / / __ / __ / / / / / / / __/ / __/ / / / / /
/ /_/ / / /_/ / /___/ / / / / / __/ / __/ / / / / /
/___/ /_____/ /_/ / /_/ / /_/ / /_ /_/ /_/_/ /_/
____/__,_/__/
'''
print(logo0)
def search_files(directory, extensions):
files = []
for root, _, filenames in os.walk(directory):
for filename in filenames:
for extension in extensions:
if filename.endswith(extension):
files.append(os.path.join(root, filename))
return files
def search_content(file_path, content):
matching_lines = []
try:
with open(file_path, 'r') as file:
for line_num, line in enumerate(file, 1):
try:
if content in line:
matching_lines.append((line_num, line))
except UnicodeDecodeError as e:
print("[-] Unicode decode error in file %s, line %d: %s" % (file_path, line_num, e))
return matching_lines
except:
print("[-] Error file %s" % (file_path))
def write_to_file(output_file, file_path, matching_lines):
with open(output_file, 'a') as f:
f.write("[+] File Path: %s
" % file_path)
f.write("[=] Line Rows: %d
" % len(matching_lines))
for line_num, line in matching_lines:
f.write("[~] In Line %d: %s
" % (line_num, line.strip()))
f.write("
")
def main():
parser = argparse.ArgumentParser(description="FindOS-Out")
parser.add_argument("-n", "--name", help="Specify the suffix", required=True)
parser.add_argument("-c", "--content", help="Specify file content", required=True)
parser.add_argument("-o", "--output", help="Specify output file", default="findout.txt")
parser.add_argument("-d", "--directory", help="Target directory", default="./")
args = parser.parse_args()
directory = args.directory
extensions = args.name.split(',')
content = args.content
output_file = args.output
files = search_files(directory, extensions)
for file_path in files:
matching_lines = search_content(file_path, content)
if matching_lines:
write_to_file(output_file, file_path, matching_lines)
if __name__ == "__main__":
logo()
print("[+] Runing Search..")
main()
print("[+] Out to findout.txt..")
使用方法如下:
python FindOS-Out.py -n .txt,.ini,.yaml,.php,.jsp,.java,.xml,.sql -c jdbc:mysql -d D:/
python FindOS-Out.py -n .txt,.ini,.yaml,.php,.jsp,.java,.xml,.sql -c jdbc:mysql -o output.txt -d /
为啥要用Python写呢?
因为DMZ的入口机器(通常是Linux服务器)都默认装了Python3和Python2,我们可以直接利用环境来跑脚本,而且代码不需要额外的pip包,简单又好用!

2.2 针对数据库的信息搜集:大海捞针,一招制敌!
连上MySQL数据库后,怎么快速找到包含user字段的库和表呢?
SELECT
TABLE_SCHEMA AS database_name,
TABLE_NAME AS table_name,
COLUMN_NAME AS column_name
FROM
INFORMATION_SCHEMA.COLUMNS
WHERE
COLUMN_NAME LIKE '%user%';

连上Oracle数据库后,怎么快速找到包含user字段的库和表呢?
SELECT
owner AS database_name,
table_name,
column_name
FROM
all_tab_columns
WHERE
column_name LIKE '%USER%'
ORDER BY
owner, table_name, column_name;
注意:Oracle数据库查询区分大小写,MySQL不区分大小写,查询Oracle时要注意大小写!
2.3 针对Win的信息搜集:玩转Windows,不在话下!
常规命令就不贴了,网上搜一大堆。
查看启动程序信息:
wmic startup get command,caption
查看连接过的Wifi名称:
netsh wlan show profiles
查看指定Wifi的密码:
netsh wlan show profile name="wifi名称" key=clear
远程桌面连接记录:
cmdkey /l
探测网段存活(Ping):
for /l %i in (1,1,255) do @ping 192.168.123.%i -w 1 -n 1|find /i "ttl="
关闭防火墙:
netsh firewall set opmode disable //Windows Server 2003 及之前的版本
netsh advfirewall set allprofiles state off //Windows Server 2003 及之后的版本
常见中间件及其配置目录(仅供参考):
| 中间件 | 目录1 | 目录2 |
|---|---|---|
| MySQL | C:ProgramDataMySQLMySQL Server X.Y | C:Program FilesMySQLMySQL Server X.Y |
| SQL Server | C:Program FilesMicrosoft SQL ServerMSSQLXX.MSSQLSERVERMSSQL | 无 |
| Oracle Database | C:apporacleproduct .2.0dbhome_1database | 无 |
| PostgreSQL | C:Program FilesPostgreSQLXXdata | 无 |
| Redis | C:Program FilesRedis | 无 |
| Apache | C:Program FilesApache GroupApacheX.Xconf | C:Program Files (x86)Apache Software FoundationApacheX.Xconf |
| Nginx | C: ginxconf | C:Program FilesNginxconf |
| Tomcat | C:Program FilesApache Software FoundationTomcatX.Xconf | 无 |
提权后,别忘了用户信息搜集:
C:UsersXXXDesktop //用户桌面内容
C:Users
816Downloads //用户下载内容
C:Users
816Documents //用户文档内容
C:Users
816AppDataLocal //用户软件信息【仅个人安装选项】
2.4 针对Linux的信息搜集:玩转Linux,如鱼得水!
常规命令就不贴了,网上搜一大堆。
查看目前谁在登录,当前在干什么:
w
最后登录用户的列表:
last
查看用户敏感信息:
//列出所有的超级用户账户
grep -v -E "^#" /etc/passwd | awk -F: '$3 == 0 { print $1}'
//查看是否存在空口令用户
awk -F: 'length($2)==0 {print $1}' /etc/shadow
//查看远程登录的账号
awk '/$1|$6/{print $1}' /etc/shadow
查看其他用户的历史命令文件:
cat /home/user/.bash_history
cat /root/.bash_history
列出iptables的配置规则:
iptables -L
查找当前可读可写可执行的目录到res.txt:
find / -type d -perm /u=rwx -user $(whoami) > res.txt
搜索包含SSH密钥的文件(一般在 /home 下,但找不到可以全目录):
grep -ir "BEGIN DSA PRIVATE KEY" /home/*
grep -ir "BEGIN DSA PRIVATE KEY" /*
grep -ir "BEGIN RSA PRIVATE KEY" /home/*
grep -ir "BEGIN RSA PRIVATE KEY" /*
grep -ir "BEGIN OPENSSH PRIVATE KEY" /home/*
grep -ir "BEGIN OPENSSH PRIVATE KEY" /*
常见配置文件路径:
```
/apache/apache/conf/httpd.conf
/apache/apache2/conf/httpd.conf
/apache/php/php.ini
/bin/php.ini
/etc/apache/apache.conf
/etc/apache/httpd.conf
/etc/apache2/apache.conf
/etc/apache2/httpd.conf
/etc/apache2/sites-available/default
/etc/apache2/vhosts.d/00_default_vhost.conf
/etc/httpd/conf.d/httpd.conf
/etc/httpd/conf.d/php.conf
/etc/httpd/conf/httpd.conf
/etc/httpd/php.ini
/etc/init.d/httpd
/etc/php.ini
/etc/php/apache/php.ini
/etc/php/apache2/php.ini
/etc/php/cgi/php.ini
/etc/php/php.ini
/etc/php/php4/php.ini
/etc/php4.4/fcgi/php.ini
/etc/php4/apache/php.ini
/etc/php4/apache2/php.ini
/etc/php4/cgi/php.ini
/etc/php5/apache/php.ini
/etc/php5/apache2/php.ini
/etc/php5/cgi/php.ini
/etc/phpmyadmin/config.inc.php
/home/apache/conf/httpd.conf
/home/apache2/conf/httpd.conf
/home/bin/stable/apache/php.ini
/home2/bin/stable/apache/php.ini
/NetServer/bin/stable/apache/php.ini
/opt/www/conf/httpd.conf
/opt/xampp/etc/php.ini
/PHP/php.ini

黑客/网络安全学习包


资料目录
-
成长路线图&学习规划
-
配套视频教程
-
SRC&黑客文籍
-
护网行动资料
-
黑客必读书单
-
面试题合集
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
*************************************CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享*************************************
1.成长路线图&学习规划
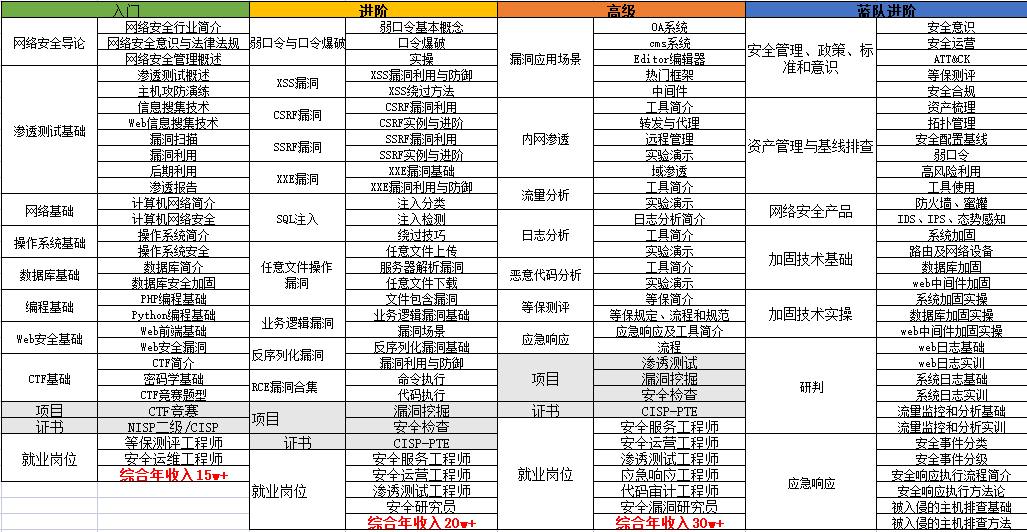
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
*************************************CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享*************************************
2.视频教程
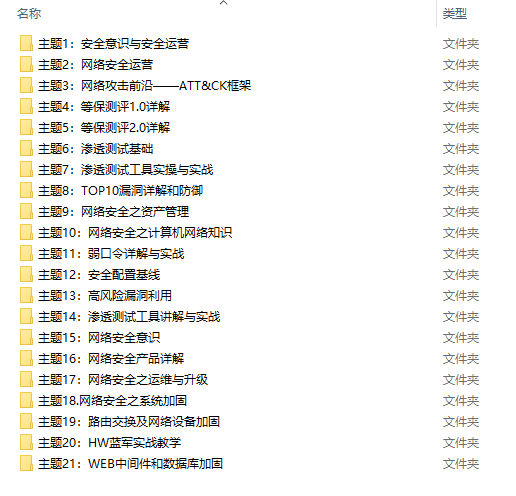
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
*************************************CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享*************************************
3.SRC&黑客文籍
大家最喜欢也是最关心的SRC技术文籍&黑客技术也有收录
SRC技术文籍:

黑客资料由于是敏感资源,这里不能直接展示哦!
4.护网行动资料
其中关于HW护网行动,也准备了对应的资料,这些内容可相当于比赛的金手指!
5.黑客必读书单
**

**
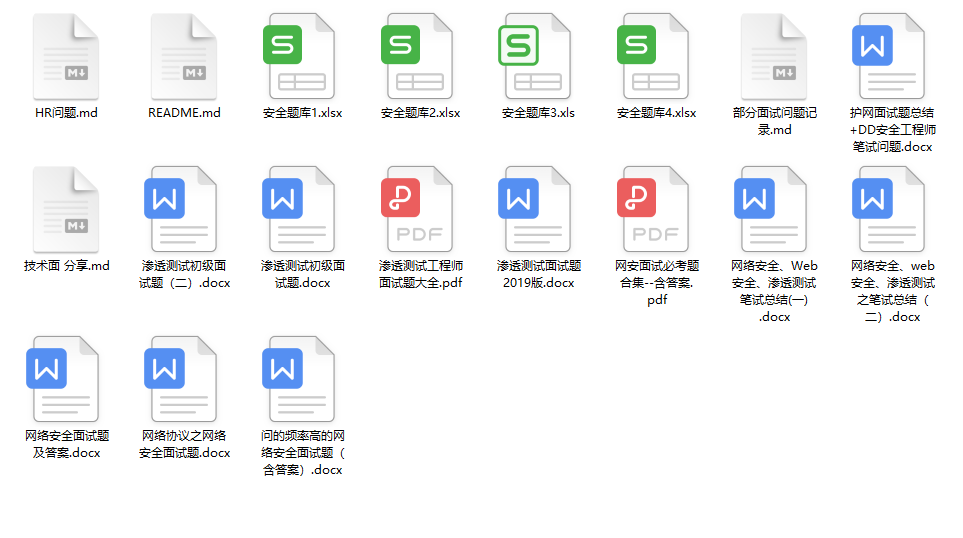
6.面试题合集
当你自学到这里,你就要开始思考找工作的事情了,而工作绕不开的就是真题和面试题。
更多内容为防止和谐,可以扫描获取~

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
*************************************CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享*********************************