
VMD-IDBO-LSTM改进蜣螂算法优化多变量时序预测
一、引言
1.1、研究背景和意义
在当今数据驱动的时代,时序预测作为数据分析中的重要分支,其重要性日益凸显。特别是在金融、市场分析、气象预报和工业控制等领域,精确的多变量时序预测不仅能帮助决策者洞察未来趋势,还能有效优化资源配置,提升系统效率。随着数据来源的多样化和数据量的激增,传统预测方法面临越来越大的挑战,因此,探索高效且精确的多变量时序预测方法具有重要的理论和实际应用价值。
1.2、研究现状
近年来,随着机器学习和深度学习技术的发展,时序预测领域取得了显著进展。循环神经网络(RNN)及其变种长短期记忆网络(LSTM)因其在处理序列数据方面的优势,被广泛应用于时序预测任务中。此外,为了提高预测性能,研究者们提出了多种优化方法,如结合注意力机制、优化算法等。然而,尽管现有方法在某些场景下表现出色,但在处理复杂的多变量时序数据时,仍面临模型复杂度高、训练时间长、泛化能力弱等问题。
1.3、存在的问题
当前多变量时序预测方法主要存在以下问题:首先,模型对数据中的非线性关系和复杂依赖关系的捕捉能力有限;其次,模型的训练效率和预测速度有待提高,尤其是在大数据环境下;最后,模型的鲁棒性和泛化能力需要进一步增强,以应对实际数据中的噪声和异常值。
1.4、研究目的与内容
针对现有方法存在的问题,本研究提出了一种新的多变量时序预测模型。该模型结合变分模态分解(VMD)、改进的蜣螂优化算法(IDBO)和长短期记忆网络(LSTM),旨在提高预测精度和效率。具体而言,通过VMD将复杂的多变量时序数据进行分解,简化后续LSTM网络的预测任务;利用IDBO优化LSTM网络的参数,以提升模型的训练速度和预测性能。
二、理论基础
2.1、蜣螂优化算法
蜣螂优化算法(Dung Beetle Optimization Algorithm,DBO)是一种受蜣螂推滚粪球行为启发的新型元启发式优化算法。该算法通过模拟蜣螂在推粪球过程中的方向调整和滚动行为,进行全局搜索和局部开发,从而在解决优化问题时表现出良好的性能。DBO算法具有参数少、易于实现、全局搜索能力强等优点,已被成功应用于多种工程优化问题。
2.2、VMD分解
变分模态分解(Variational Mode Decomposition,VMD)是一种自适应的信号处理技术,用于将复杂信号分解为多个具有不同中心频率和带宽的模态分量。VMD通过迭代搜索变分问题最优解的方式,确保每个模态分量具有最高的紧凑性和独立性,从而有效揭示信号的内部结构。在时序预测领域,VMD常被用于数据预处理,以降低信号噪声,提取关键特征。
2.3、长短期记忆网络
长短期记忆网络(Long Short-Term Memory,LSTM)是一种特殊的循环神经网络,旨在解决传统RNN在处理长序列数据时的梯度消失和梯度爆炸问题。LSTM通过引入记忆单元和门控机制,能够有效捕捉序列数据中的长期依赖关系,广泛应用于语音识别、自然语言处理和时序预测等领域。
三、改进的VMD-IDBO-LSTM模型
3.1、VMD与LSTM的结合
在本研究中,我们首先利用VMD将原始多变量时序数据进行分解,得到多个模态分量和一个残差分量。VMD的分解过程能够有效分离数据中的不同频率成分,简化后续预测任务。具体而言,我们将每个模态分量视为一个独立的时序序列,并分别输入到LSTM网络中进行预测。LSTM网络在处理这些单一频率成分的数据时,能够更有效地捕捉其动态变化,从而提高预测精度。
3.2、IDBO算法的引入与改进
为了进一步提升LSTM网络的性能,我们引入改进的蜣螂优化算法(IDBO)来优化网络参数。传统的蜣螂优化算法在搜索过程中存在易陷入局部最优的缺点,因此我们提出了一种新的位置更新策略,通过引入混沌搜索和自适应步长机制,增强算法的全局搜索能力和收敛速度。具体而言,混沌搜索能够在初始阶段增加种群的多样性,避免过早收敛;自适应步长机制则根据当前搜索进度动态调整步长,提高搜索效率。
3.3、模型整体架构
改进的VMD-IDBO-LSTM模型整体架构如下:首先,通过VMD将原始多变量时序数据进行分解,得到多个模态分量和一个残差分量;然后,将每个模态分量输入到独立的LSTM网络中进行预测,同时利用IDBO算法优化LSTM网络的参数;最后,将各模态分量的预测结果进行组合,得到最终的预测输出。模型架构如图1所示。
四、实验设计与结果分析
4.1、实验数据与预处理
为了验证改进VMD-IDBO-LSTM模型的有效性,我们选用了多个公开数据集进行实验,包括金融、市场分析、气象预报和工业控制等领域的数据。在实验开始前,我们对原始数据进行标准化处理,以消除不同变量之间的量纲差异。此外,我们还通过滑动窗口法将数据转换为监督学习问题,具体窗口大小根据数据集特性进行选择。
4.2、实验设置
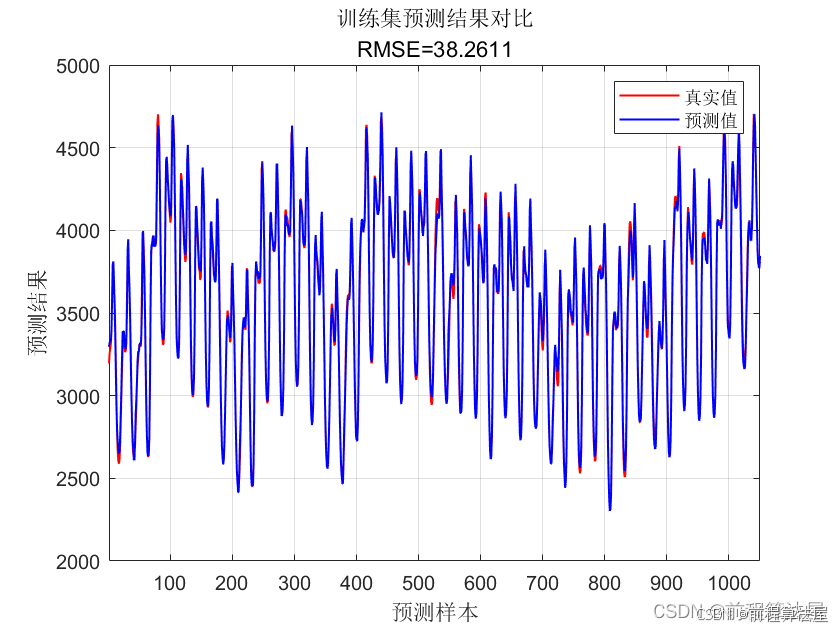
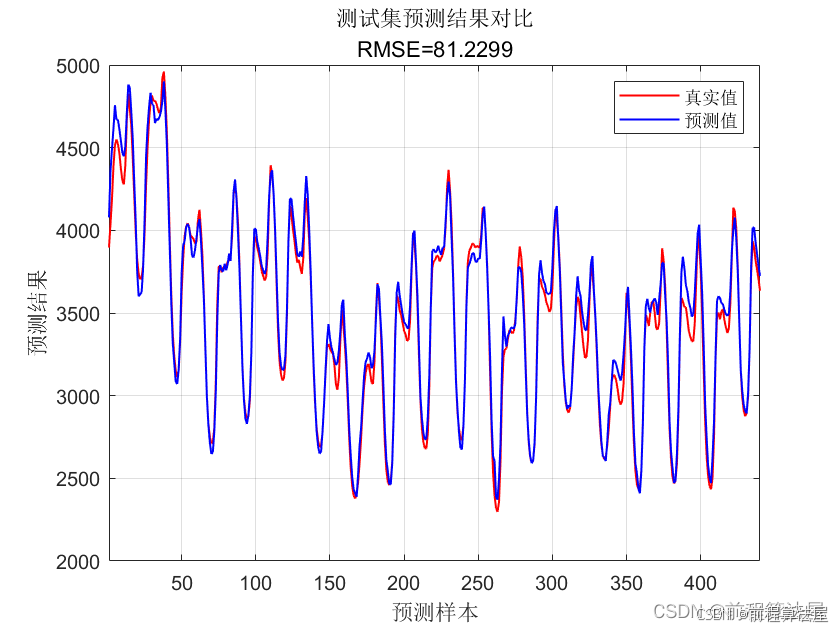
在实验设置方面,我们选择均方误差(MSE)和均方根误差(RMSE)作为评估指标,以量化模型的预测性能。
五、结论与展望
5.1、研究总结
本文提出了一种结合VMD、IDBO和LSTM的改进多变量时序预测模型。实验结果表明,该模型在处理复杂的多变量时序数据时,能够有效提高预测精度和效率。VMD的引入使得模型能够更好地处理数据的非线性关系,而IDBO算法的优化则显著提升了模型的训练速度和预测性能。
5.2、研究限制
尽管改进模型在多个数据集上表现出色,但仍存在一些限制。首先,模型的复杂度相对较高,对于计算资源有限的场景可能不适用;其次,模型对超参数的设置较为敏感,需要通过大量实验进行调整。
5.3、未来研究方向
未来的研究将集中在以下几个方面:首先,探索更高效的模型优化方法,以降低计算复杂度;其次,研究模型在不同应用场景下的适应性,提升其泛化能力;最后,结合其他先进的技术,如注意力机制、图神经网络等,进一步提升模型的预测性能。