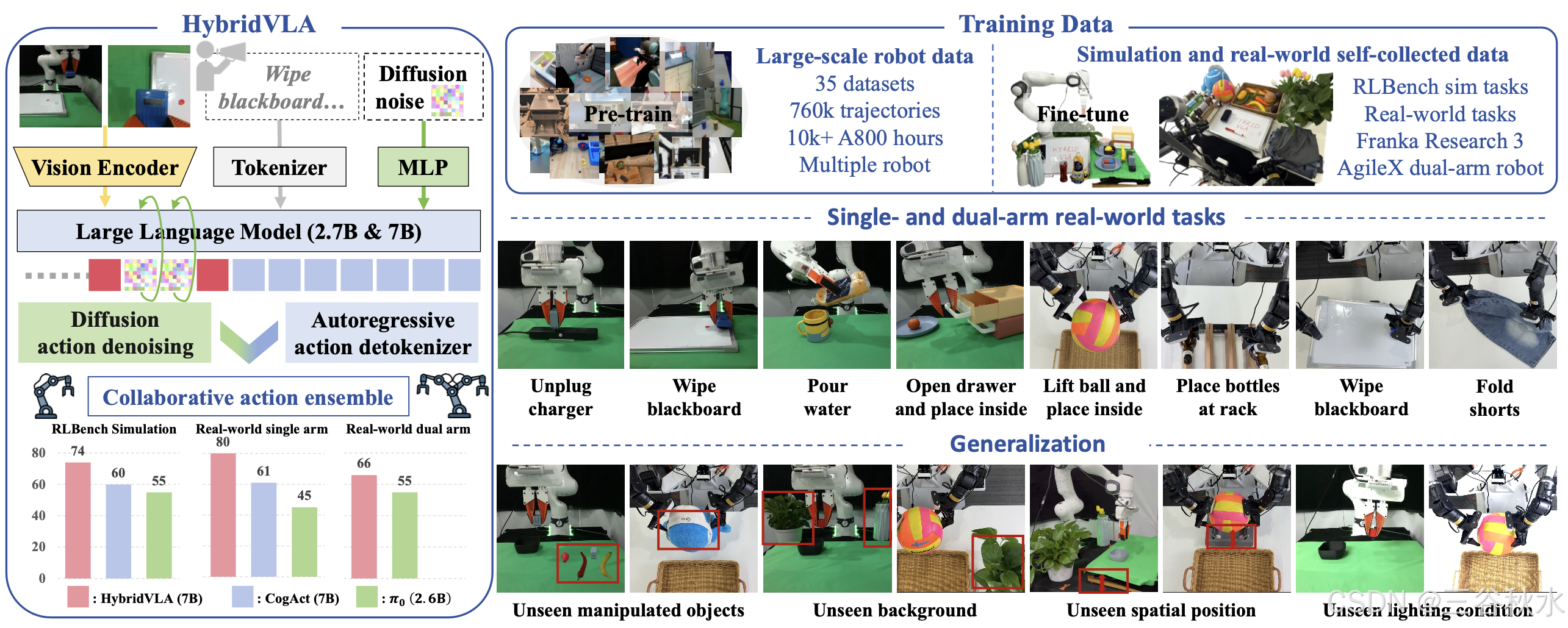
25年3月来自北京大学、北京智源研究院和香港城市大学的论文“HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model”。
用于常识推理的视觉-语言模型 (VLM) 的最新进展导致视觉-语言-动作 (VLA) 模型的发展,使机器人能够执行泛化操作。尽管现有的自回归 VLA 方法利用大规模预训练知识,但它们破坏动作的连续性。同时,一些 VLA 方法结合额外的扩散头来预测连续动作,仅依赖于 VLM 提取的特征,这限制它们的推理能力。本文的 HybridVLA,是一个统一的框架,它将自回归和扩散策略的优势无缝地集成在一个大语言模型中,而不是简单地将它们连接起来。为了弥合生成差距,提出一种协作训练方法,将扩散建模直接注入到下一个 token 预测中。通过这个方法,这两种形式的动作预测不仅相互加强,而且在不同任务中表现出不同的性能。因此,设计一种协同动作集成机制,可以自适应地融合这两个预测,从而实现更强大的控制。
最近,视觉语言模型 (VLM) [3、5、21、51、58、112–114] 在互联网规模的图像文本对上进行预训练后,表现出了卓越的指令遵循和常识推理能力。在此成功的基础上,一些研究将 VLM 扩展为视觉-语言-动作 (VLA) 模型,使其能够生成动作规划 [1、7、18、34] 或预测 SE(3) 姿势 [10、47、56]。VLA 模型使机器人能够解释视觉观察和语言条件,从而生成可泛化的控制动作。因此,有效利用 VLM 的固有能力来开发用于在动态环境中稳定操纵的 VLA 模型至关重要 [55]。
一方面,一些现有的 VLA 方法 [10, 47, 56, 74] 将连续动作量化为离散的 bins,从而取代大语言模型 (LLM) 中的部分词汇。这些自回归方法模仿 VLM 的下一个 token 预测,有效地利用它们的大规模预训练知识,同时保留推理能力。尽管此类方法能够实现泛化的操纵技能 [47],但量化过程会破坏动作姿势的连续性 [97]。另一方面,一些 VLA 方法 [33, 54, 60, 100] 结合策略头(例如 MLP 或 LSTM [25])以将 LLM 输出嵌入转换为连续动作姿势。然而,这些回归方法忽略策略头的可扩展性,未能结合概率动作表示 [14, 52]。
基于扩散模型在内容生成方面的成功 [28, 31, 32, 73, 80],扩散策略最近被引入到机器人模仿学习中 [14, 45, 71, 79, 104, 110]。与回归确定性策略头不同,π 0[8]、CogACT [52] 和 DiVLA [97] 在 VLM 之后加入扩散头,利用概率噪声去噪进行动作预测。虽然基于扩散的 VLA 方法可以实现精确操作,但扩散头独立于 VLM 运行,仅依赖 VLM 提取的特征作为输入条件。因此,它无法充分利用 VLM 的推理能力。鉴于这些优点和局限性,出现一个问题:“如何才能优雅地构建一个统一的 VLA 模型,无缝地整合自回归和扩散策略的优势,而不是简单地将它们连接起来?”
本文的 HybridVLA 将扩散建模无缝集成到单个 LLM 中的自回归下一个 token 预测中,如图所示。
现有的基于扩散 VLA 方法 [8, 52, 97] 在 VLM 之后附加一个单独的扩散头,使用 VLM 提取的特征作为扩散过程的条件。然而,这些方法未能充分利用 VLM 源自互联网规模预训练的固有推理能力。相比之下,HybridVLA 为单个 LLM 配备扩散和自回归动作生成功能。
问题陈述。在时间 t,每个演示都包含图像观测 o_t、语言描述 l_t 和当前机器人状态 r_t。模型 π 旨在预测控制机械臂的动作 a,可以表述为:π : (o_t, l_t, r_t) → a_t+1。
按照 [47, 52],动作 a 表示末端执行器姿势,分别使用 7 自由度和 14 自由度进行单臂和双臂控制。每个 7 自由度动作包括 3 自由度(相对平移偏移:[∆x, ∆y, ∆z])、3 自由度(旋转:欧拉角)和 1 自由度(夹持器状态:打开/关闭)。
HybridVLA 架构
HybridVLA 的架构和工作流程。其有两种模型大小,分别使用 2.7B 和 7B 大语言模型 (LLM)。HybridVLA 沿用 [47] 的 Prismatic VLM [44] 的基本架构,并利用其互联网规模的预训练参数。首先介绍两个基本组件——视觉编码器和 LLM,如图所示。
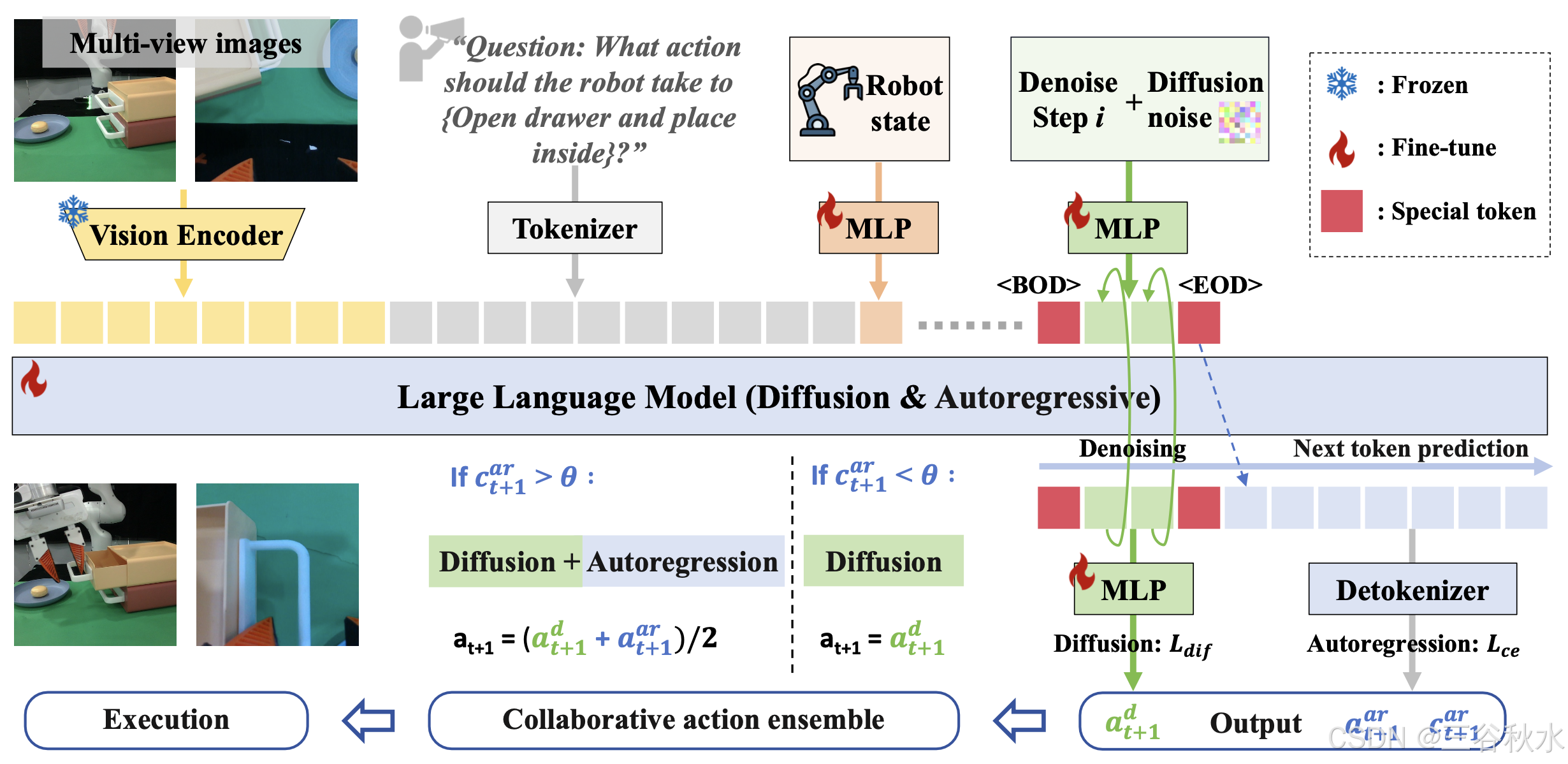
视觉编码器。HybridVLA 利用强大的视觉编码器组合(例如 DINOv2 [70] 和 SigLIP [111])来捕获丰富的语义特征 f_d 和 f_s。B 和 N 分别表示批量大小和 token 维度。这些特征沿通道维度连接起来形成 f_v,然后通过投影层将其投影到 LLM 的词嵌入中。HybridVLA (2.7B) 仅使用 CLIP [77] 模型作为其视觉编码器。在处理多视图图像时,共享视觉编码器提取特征,然后沿 token 维度连接起来。
LLM。HybridVLA 采用 7B LLAMA-2 [93] 作为 LLM,负责多模态理解和推理。使用预训练的 token化器将语言提示编码到嵌入空间 f_l 中,然后与视觉 token 连接并输入到 LLM 中。输出 token 以两种方式处理。首先,通过去噪过程生成基于扩散的动作 (ad_t+1),其中 MLP 将 token 映射到动作空间。其次,去 token 化器 [47] 执行基于自回归的动作 (aar_t+1) 生成,它还计算动作 token 的平均置信度 (c^ar_t+1),作为协作动作集成的指导因素。对于 HybridVLA (2.7B),工作流程与 HybridVLA (7B) 相同,但使用 2.7B Phi- 2 [39] 作为 LLM。
协作训练方案
在单个 LLM 中直接结合扩散和自回归姿势预测会带来诸如下一个 token 预测不稳定和不一致等挑战。因此,本文提出一种协作训练方案,其中包括 token 序列公式设计、混合目标和结构化训练阶段。
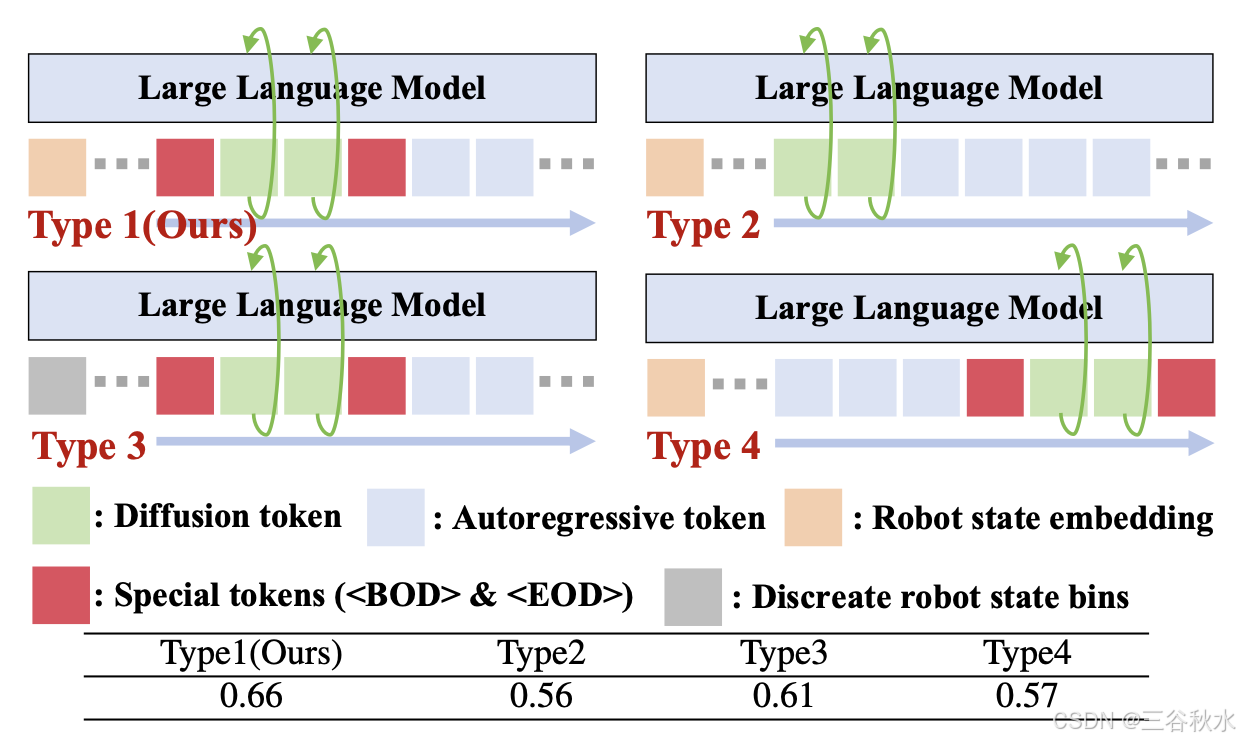
Token 序列公式设计。如上图上半部所示,训练期间的输入 token 序列不仅包含视觉和语言 token,还包括机器人状态、扩散噪声和自回归动作 token。对于机器人状态,将其集成到 LLM 中以增强动作生成的时间一致性。没有将机器人状态离散化并将其与语言查询 [56](下表中的类型 3)合并,而是使用可学习的 MLP 将机器人状态直接映射到词嵌入空间 f_r。动机是在后续的下一个 token 预测过程中生成扩散动作 token,使用所有前面的 token 作为条件。引入离散的机器人状态可能会对连续动作的扩散预测产生负面影响。对于扩散动作,通过扩散去噪过程来预测它们,并以先前的 token 为条件。去噪步骤 i 和噪声动作 a^i_t 通过 MLP 投影到 LLM 的词嵌入中,表示为连续向量。为了在单个序列中无缝连接先前的多模态 token、扩散 token 和后续离散 token,引入特殊的扩散开始 () 和扩散结束 () token 来封装扩散 token。这种设计不仅明确扩散和自回归生成之间的界限,而且还防止下一个 token 预测过程中的混淆,例如扩散 token 直接预测被屏蔽的离散 token(下表中的类型 2)。对于自回归动作,将末端执行器姿势量化为离散 bin,并替换 LLM [47] 中的部分词汇,然后将其 token 化为离散 token 序列。由于下一个 token 预测的固有性质,问题和答案(离散动作 GT)在训练期间都会输入到 LLM 中,而在推理期间只提供问题。如果将自回归预测放在扩散 token 之前,则会导致动作 GT 泄漏,从而成为扩散训练的条件(下表中的类型 4)。因此,将扩散 token 放在最前面,明确为后续的自回归生成提供连续知识。
混合目标。为了同时训练扩散和自回归动作生成,需要两个不同的损失函数。对于扩散部分,遵循之前的扩散策略 [14],最小化 VLA 模型的预测噪声(ε_π)和 GT 噪声(ε)之间的均方误差。
此外,为了确保机械臂行为稳定 [61],不使用无分类器指导 [30]。对于自回归部分,采用交叉熵损失 (L_ce) 来监督离散输出。通过设计的 token 序列公式,可以将这两个损失无缝结合起来,以实现协同惩罚。
结构化训练阶段。加载预训练的 VLM 参数后,HybridVLA 经历两个具有混合目标的训练阶段:对开源机器人数据进行大规模预训练,对自收集的模拟和真实世界数据进行微调。在预训练期间,在来自 Open X-Embedding [69]、DROID [46]、ROBOMIND [101] 等的 35 个数据集上对 HybridVLA 进行 5 个 epochs 的训练。预训练数据集包含 760k 条机器人轨迹,包括 33m 帧。由于数据集的差异,预训练仅依赖于单个 2D 观测,而微调依赖于单视图或多视图观测,具体取决于下游任务。
协作动作集成
在推理过程中,给定视觉、语言和机器人状态输入,HybridVLA 同时使用扩散和自回归方法生成动作,然后集成这些动作以产生更稳定的执行。
自回归动作。自回归生成,从特殊 token 之后开始。与 [47, 56] 类似,7-DoF 或 14-DoF 动作的生成与 LLM 中的文本生成过程非常相似。与之前的自回归 VLA 方法不同,HybridVLA 的自回归生成还以扩散 token 动作的固有连续性为条件,优于独立自回归方法。
扩散动作。生成扩散动作时,在前一个条件 token 后附加特殊 token ,以指示模型应执行去噪过程。采用 DDIM [89] 采样,采样步骤为 n。在 HybridVLA 中,将扩散集成到下一个 token 预测过程中,不仅可以通过充分利用 VLM 的推理能力和预训练知识来提高动作精度,而且还可以在减少推理去噪步数(例如 n = 4)时减轻性能下降。为了加速采样过程,在扩散 token 之前引入 KV 缓存,仅在初始采样步骤期间转发条件信息、去噪时间步长和纯噪声。在后续步骤中,将重用第一遍的缓存 K-V,而仅迭代转发时间步长和噪声。此策略消除冗余计算并提高推理速度。
集成动作。在协作训练配方下获得两种类型的动作后,经验观察到两种现象。1) 不同的动作类型在不同任务中表现出不同的性能。基于扩散的预测在精确的操作任务中表现出色,例如将手机放在底座上和关闭笔记本电脑盖,而自回归预测在需要场景语义推理的任务中表现更好,例如浇灌植物和将框架从衣架上取下。2)自回归动作 token 的置信度是动作质量的可靠指标。在超过 80% 的成功完成的测试样本中,自回归动作 token 的平均置信度超过 0.96。用自回归 token(car_t+1)的平均置信度来指导动作集合。如果置信度超过 θ(θ = 0.96),自回归动作(aar_t+1)足够准确,并与扩散动作(a^d_t+1)执行平均运算。否则,仅依靠扩散动作来控制机器人。此外,为了加速推理,HybridVLA-dif 完全依赖基于扩散的动作生成,同时在训练期间仍然协作学习两种动作生成类型以增强相互强化。
模拟基准。为了系统地进行评估,选择 CoppeliaSim 模拟器中的 RLBench [36] 基准,其中包含 10 个不同的桌面任务。这些任务使用 Franka Panda 机器人和前视摄像头执行,包括关闭盒子、关闭笔记本电脑、放下马桶座圈、扫到簸箕、关闭冰箱、将手机放在底座上、取出雨伞、从衣架上取下框架、将葡萄酒放在架子上和给植物浇水。数据是使用预定义的航点和开放式运动规划库 [90] 收集的。按照以前研究中使用的帧采样方法 [24, 40, 87],构建训练数据集,每个任务由 100 条轨迹组成。
模拟实验。将方法与之前的四种 SOTA VLA 模型进行比较,包括基于自回归的方法,例如 ManipLLM [56] 和 OpenVLA [47],以及基于扩散的方法,例如带有 DiT-基动作头的 π 0[8] 和 CogAct[52]。同时,将方法分为三种模式:Hybrid-VLA (7B)、HybridVLA (2.7B) 和 HybridVLA-dif (7B)。所有模式均使用协作训练方案进行联合训练;然而,HybridVLA-dif 在推理过程中仅依赖基于扩散的动作生成。为了确保公平比较,加载每种方法提供的官方预训练参数,并遵守它们各自的训练设置。对于 HybridVLA,单视图 RGB 输入的大小被调整为 224×224,机器人状态与预测的动作(7-DOF 末端执行器姿势)一致。在训练过程中,用 AdamW 优化器,学习率恒定为 2e-5。仅更新 LLM 和注入的 MLP 参数。模型在 8 个 NVIDIA A800 GPU 上进行 300 个 epoch 的混合精度训练。为了进行评估,遵循 [47, 52],所有方法都使用最新 epoch 20 个 rollout 进行测试。
真实世界数据。对于单臂任务,用带有静态前视和腕视摄像头的 Franka Research 3 机器人。执行 5 项任务:1)拾取和放置,2)拔下充电器,3)打开抽屉并放入其中,4)倒水,5)擦黑板。对于每个任务,使用 SpaceMouse 从桌子上的各个位置通过远程操作收集 100 个演示。对于双臂任务,使用配备静态外部视图、右腕视图和左腕视图摄像头的 AgileX 双臂机器人。执行 5 项协调的双臂任务:1)拾取和放置,2)举起球并放置,3)将两个瓶子放在架子上,4)擦黑板,5)折叠短裤。同样,使用主木偶远程操作为每个任务收集 100 个演示。
真实训练和评估实验。为了公平比较,仅评估方法 (HybridVLA-dif) 与基于扩散的 VLA 方法 π 0[8] 和 CogAct[52] 的扩散生成动作。除了在单臂任务中加入双视图输入,在双臂任务中加入三视图输入外,实现细节与模拟实验保持一致。为了进行评估,使用最近 epoch 检查点在不同的桌面位置执行 20 次展开。