25年3月来自斯坦福大学的论文“Unified Video Action Model”。
统一的视频和动作模型对机器人技术具有重大意义,其中视频为动作预测提供丰富的场景信息,而动作为视频预测提供动态信息。然而,有效地结合视频生成和动作预测仍然具有挑战性,当前基于视频生成的方法在动作准确性和推理速度方面难以与直接策略学习的性能相匹配。为了弥补这一差距,引入统一的视频动作模型(UVA),它联合优化视频和动作预测以实现高精度和高效的动作推理。关键在于学习联合视频动作潜表示和解耦视频动作解码。联合潜表示,连接视觉和动作领域,有效地建模视频和动作序列之间的关系。同时,由两个轻量级扩散头驱动的解耦解码,在推理过程中绕过视频生成,实现高速动作推理。这种统一的框架通过掩码输入训练进一步实现多功能性。通过选择性地屏蔽动作或视频,单个模型可以处理策略学习以外的各种功能,例如正向和逆向动力学建模和视频生成。通过大量实验证明 UVA 可以作为各种机器人任务的通用解决方案,而不会与针对特定应用定制的方法相比影响性能。
UVA如图所示:
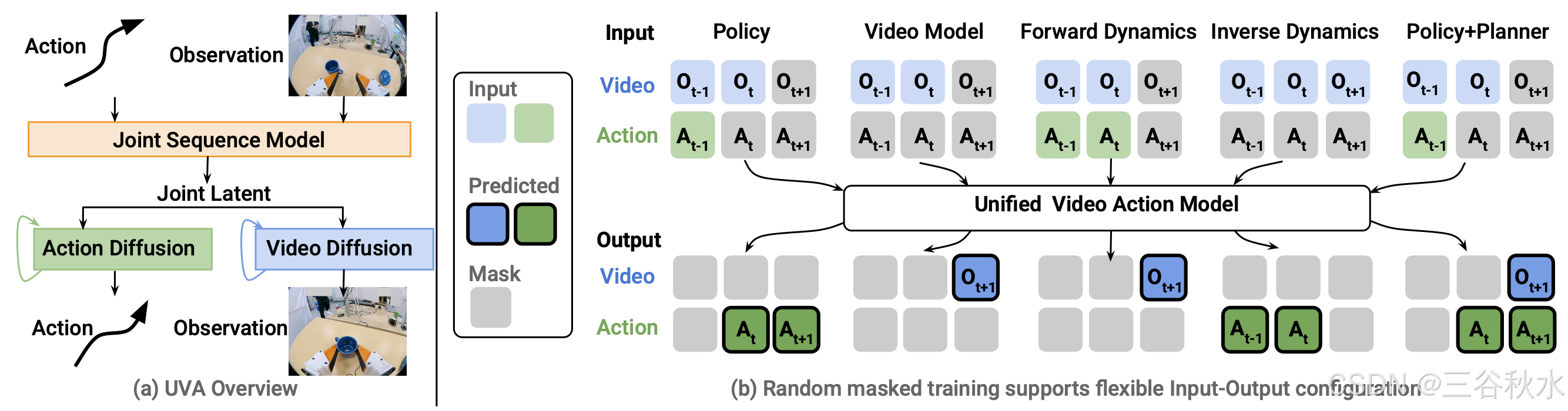
统一的视频和动作模型,可以共同学习智体的动作及其对视觉观察的影响,这对机器人技术来说大有裨益——视频为预测动作提供丰富的环境背景,而动作则揭示交互如何推动视觉变化,从而能够更准确地建模现实世界的动态。然而,尽管前景光明,以前的方法往往未能充分发挥这种潜力。一个关键的挑战在于动作和视频生成要求之间固有的不匹配。动作建模需要高时域速度来捕捉密集、细粒度的运动,而视频生成需要高空域分辨率来产生高保真视觉输出,这通常会导致处理速度变慢。
用于策略学习的视频生成:视频模型通过模拟任务动态和预测未来状态来帮助策略学习。[12、25] 等模型利用视频生成技术来制作高质量视频,然后将其用于动作预测。[46] 的工作利用视频模型生成目标流作为中间表示,该表示捕获物理交互并用于预测动作,以便在不同的机器人实现和环境中进行技能迁移。在 [21] 中,视频扩散模型针对机器人任务进行微调,预测视频的潜表示作为动作预测策略网络的输入。现有的利用视频生成进行策略学习的方法,通常存在推理速度慢的问题,因此不适用于实际应用。此外,这些方法通常需要辅助组件,例如低级策略 [12] 或图像跟踪技术 [46],从生成的视频中提取动作。因此,最终的动作准确性会受到视频生成和动作预测中的复合误差的影响。
视频生成作为动力学模型:视频模型可以作为动力学模型,根据当前的观察和动作预测未来状态,使机器人能够模拟和规划任务。GameGen-X [8] 引入一种扩散 transformer 模型,用于生成和控制开放世界游戏视频,从而实现交互式模拟。Genie [4] 利用基础世界模型将静态图像转换为交互式 3D 环境,为具身智体提供丰富的模拟。此外,[40] 展示扩散模型如何充当实时游戏引擎,生成动态和交互式场景以促进决策。这些进步凸显视频生成模型在机器人应用中的多功能性。
掩码训练:机器人领域的最新研究探索掩码训练技术 [28、31、45]。例如,Liu [28] 和 Wu [45] 随机掩码观察和动作并重建缺失部分。他们的结果表明,掩码训练提高对下游任务的泛化能力,并使模型能够用于各种应用。然而,这些方法主要依赖于低维状态观测,而不是视频,视频更自然,但更难预测。Radosavovic [31] 首先使用掩码训练预训练模型来预测动作或观察,然后对模型进行微调或使用线性探测进行下游任务。他们的工作只关注动作预测结果。
以前的策略学习方法一直在努力平衡这些相互冲突的要求,往往只关注一个方面而忽略了另一个方面。例如,仅关注动作的方法(如 [9, 22, 48])完全绕过视频生成。虽然这种方法降低计算复杂性,但它们忽略视频生成的好处——增加观察监督有助于模型学习场景动态,从而减少对动作历史的过拟合并增强对视觉干扰的鲁棒性。另一方面,诸如 [12, 25] 之类的视频生成方法通常首先生成高分辨率视频,然后根据生成的视频预测动作。虽然这种分层方法可以利用现有的视频模型,但它也带来重大缺陷,包括处理速度较慢以及错误从生成的视频传播到动作预测中。
为了解决这些限制,UVA 是一个统一的视频和动作模型,旨在同时对视频和动作进行建模 - 捕捉视觉和动作之间的底层交互以增强任务理解,同时在推理过程中保持高速动作预测。
在机器人技术中,学习将观察结果映射到动作的可推广策略。然而,这个目标往往倾向于过拟合训练数据,从而限制学习策略适应新场景的能力。相比之下,视频生成 [3, 33] 表现出对新场景的强大泛化能力,并支持在没有动作的数据集上进行训练。然而,有效地利用视频数据进行策略学习带来挑战,例如能否匹配输出密集、细粒度运动所需的高时间速度。
问题陈述:给定一系列图像观察结果 {O_t−h+1,…,O_t} 和动作块 {A_t−h,…,A_t−1},其中 h 是历史范围,目标是预测未来的动作 {A_t,…,A_t+h′−1} 和观察结果 {O_t+1 , … . . , O_t+h′ },其中 h′ 是未来范围。每个动作块(例如 A_t)由 L 个动作组成,每个动作有 m 个维度。在实验中设置 h = h′。
如图所示,本文方法对观察和动作的历史记录以及掩码的未来观察进行编码,并将它们传递给 Transformer [41]。对于掩码的观察,在训练期间随机掩码未来观察帧内的 token,并训练模型重建它们。在推理过程中,模型从空序列开始生成完整的 token 集。本文选择解耦视频动作扩散来进行快速推理,以满足机器人策略的高时域速度要求。
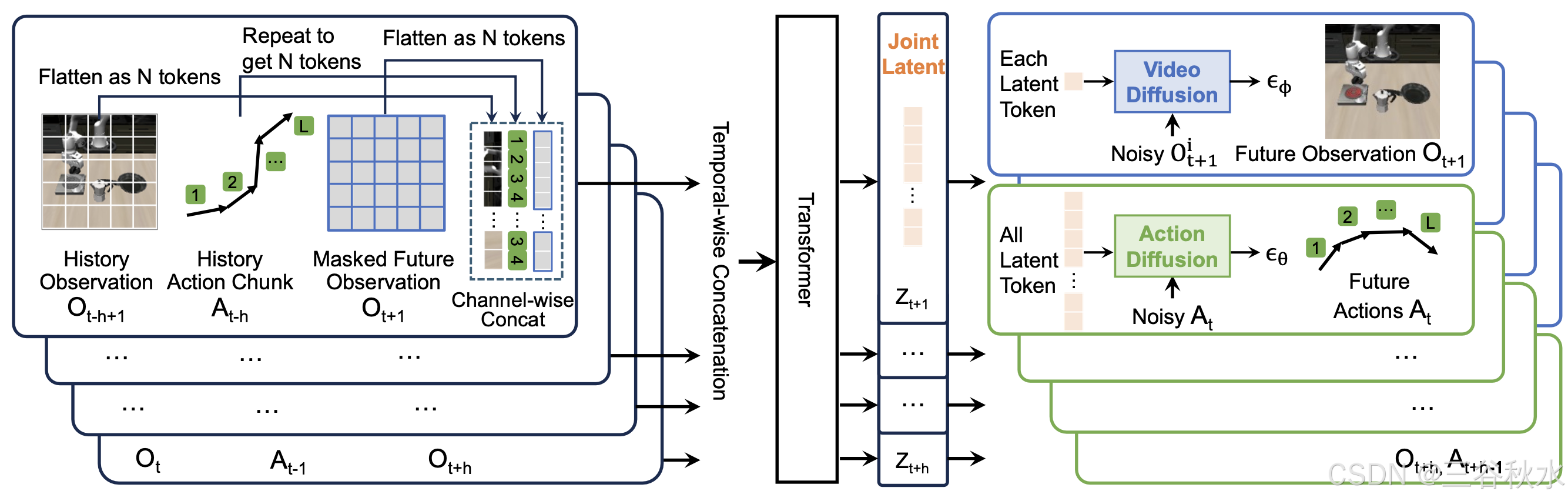
编码历史
首先通过预先训练的 VAE 编码器 (kl-f16) [32] 处理历史图像观测,以获得其潜表示。每幅图像都被编码成一个尺寸为 w×h×c 的潜图,其中 w 和 h 代表宽度和高度,c 是潜维度。然后,该图被展平并通过全连接 (FC) 层进行处理,将每个元素投影到 d 维潜向量中。因此,每幅图像都表示为 N 个视觉 tokens 的序列,每个 token 都有 d 维特征。
对于历史动作,用比观测更高的采样频率,因为观测通常在短时间间隔内表现出冗余和最小变化。每个图像观测(例如,O_t−h+1)对应于动作块(例如,A_t−h)内的 L 个动作。重复动作块 M 次以匹配视觉 token 的数量,如上图所示。然后,重复的序列通过 FC 层,并转换为 N 个动作 tokens 的序列,每个动作 token 都有一个 d 维潜表示。这些历史视觉和动作 tokens 可作为预测未来观察和动作的条件。
用于观察预测的掩码自动编码器(MAE)
与 [7, 24] 密切相关,他们的方法侧重于以类标签为条件的图像生成。它首先为图像生成视觉 token 的子集,然后根据先前生成的 token 顺序预测其他 token,然后遵循自回归过程以完成图像。这种逐步自回归方法已被证明优于同时单步生成所有视觉 tokens。为了促进逐步预测,采用掩码自动编码器 [17] 框架。在训练过程中,一些视觉 tokens 被随机掩盖,并训练模型重建这些被掩盖的 tokens。
遵循此设置进行视频预测。未来观察帧 {O_t+1 , … , O_t+h } 的处理方式与历史观察类似:它们通过 VAE 编码器提取潜表示,然后通过 FC 层,产生每帧 N 个 tokens 的序列,每个 token 都有一个 d 维潜向量。一些 tokens 在训练期间被随机掩码。这些视觉 tokens 与历史视觉 tokens 和动作 tokens 按通道连接,如上图所示,以形成新的潜特征序列。然后将来自 h 个不同时间步骤的潜特征与来自其他时间步骤的潜表示在时间上连接以产生 N × h 潜序列。得到的序列通过 Transformer 融合视频和动作信息,产生一组联合视频动作潜表示,{Z_t+1 , … . , Z_t+h},其中每个潜表示(例如,Z_t+1)包含 N 个潜 tokens。然后使用这些联合视频动作潜 tokens 来重建未来的观察和相应的动作块。
为了最大限度地减少不同帧之间的信息泄漏,始终掩码所有视频帧中的相同位置。在推理时,模型从空序列开始预测所有 tokens 来生成完整的视频。在每个自回归生成步骤中,所有视频帧中相同位置的视觉 tokens 都会同时生成。与以类标签或文本为条件的图像生成不同,历史观察提供有关环境的丰富上下文信息。单步生成足以生成高质量的观测值,而使用额外的步骤可以进一步提高质量。
解耦视频和动作扩散
以前基于视频生成的策略学习方法,依赖于先分层生成视频,然后预测动作,导致速度慢和累积错误。为了解决这个问题,在联合训练视频和动作预测时将它们解耦。在训练过程中,视频生成有助于潜表示 Z 捕获更详细的场景信息,这有利于动作预测。在速度至关重要的策略推理过程中,解耦设计允许跳过视频生成并仅解码动作。同样,对于质量优先的视频生成,可以执行多步自回归视频生成,同时绕过动作解码。
引入两个轻量级扩散解码器用于动作和视频预测(如上图所示)。该方法不是对整个模型进行去噪 [9],而是将去噪过程限制在轻量级解码器上,从而提供更高效的性能。这种设计保留扩散模型的生成优势,同时显着缩短推理时间。
联合潜表征 Z 用作扩散解码器的条件输入。视频扩散解码器处理每个潜 token z_i ∈ Z_t+1 = {z_1,…,z_N} 以预测视频帧中的各个块,然后重塑这些块并发送到 VAE 解码器以重建完整帧 O_t+1。对于动作扩散解码器,Z_t+1 中的所有潜 token 都使用卷积层进行聚合,然后是 MLP 层,以生成动作潜 token。该潜 token 对当前步骤的视觉和动作相关信息进行编码,并作为动作扩散模型生成动作块 A_t 的条件。用 [24] 中的扩散头(基大小)进行动作和视频预测。在训练期间,解码器学习预测添加到有噪声的动作块或视频块中的噪声。在策略推理或视频生成过程中,解码器使用学习的去噪过程迭代地将纯噪声细化为动作或视频。
具有灵活目标的掩码训练
提出一种使用统一框架具有多个训练目标的掩码训练方法,而不是仅仅根据历史数据来训练模型以预测未来的观察和行动。该模型通过改变输入和输出组合在五个不同的任务上进行训练。未使用的组件被掩码并替换为学习的掩码 token。根据具体任务,有选择地应用动作损失和视频损失来监督模型。
这种训练方法,能够充分利用各种组合中的数据,并支持使用不完整的数据,例如没有相应动作的视频数据。这种掩码训练策略使模型能够执行多种功能,包括充当机器人策略、视频模型、正向和逆向动力学模型以及组合策略和规划器。例如,当仅给出图像观察时,该模型可以用作逆动力学模型,从视频中生成动作标签。此外,这种策略有助于防止过拟合特定任务,从而增强模型的整体多功能性和稳健性。
附录:
自回归视频生成,基于 [7] 和 [24] 中的方法,这些方法最初是为图像生成而设计的,已将其扩展到视频生成。在 [7] 中,首先使用 VQGAN [13] 将图像转换为离散的视觉代码。在训练期间,这些视觉代码的子集被随机掩码,并训练模型重建它们。在推理期间,整个图像由空掩码生成。这种掩码训练方法使模型能够自回归地生成图像。自回归步骤的数量可以在推理过程中调整,步骤越多,性能越好,正如论文中所证明的那样。然而,VQGAN 中的视觉离散化和使用离散视觉代码进行训练通常会导致信息丢失,从而导致图像质量下降。Li [24] 通过使用连续潜表示而不是图像 token的离散代码来解决这一限制。他们的方法使用扩散模型对每个视觉 token 概率进行建模,从而无需矢量量化。与以前的方法相比,这种方法表现出更好的性能。
本文方法与 [24] 相似,因为它预测连续的潜表示。然后,这些表示被用作扩散头的条件,以解码动作和视频观察。自回归生成过程如图所示。如果自回归步骤设置为 1,则整个视频在一次传递中生成。否则,使用预定义的步骤数,该方法将自回归生成视频,并在指定的步骤数内完成该过程。
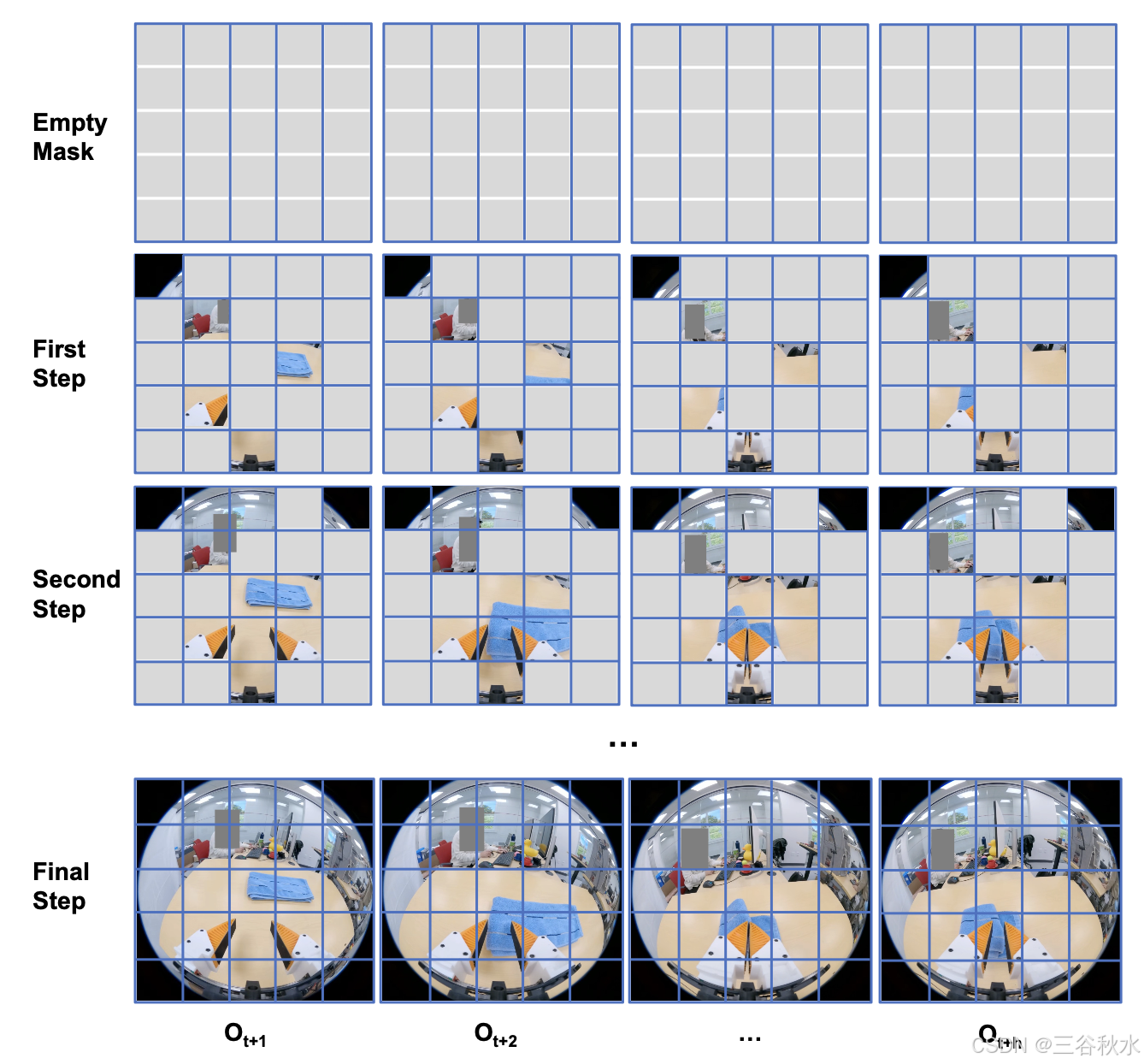
本文模型建立在 [24] 发布的预训练模型 (MAR-B) 的基础上,但已针对联合视频和动作建模进行重大修改。