0. 简介
一个实用的导航代理必须能够处理广泛的交互需求,例如遵循指令、搜索物体、回答问题、跟踪人员等。现有的具身导航模型在现实世界中未能作为实用的通用模型,因为它们通常受到特定任务配置或预定义地图(带有离散的路径点)的限制。在本研究中,《Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks》提出了Uni-NaVid,这是第一个基于视频的视觉-语言-行动(VLA)模型,旨在统一多样的具身导航任务,并实现对未见过的真实环境中混合长时间任务的无缝导航。Uni-NaVid通过协调所有常用具身导航任务的输入和输出数据配置,从而将所有任务整合到一个模型中。为了训练Uni-NaVid,我们从四个基本导航子任务中总共收集了360万条导航数据样本,并促进了它们之间的协同学习。相关的代码工作可以在Github上找到。
1. 主要贡献
在本研究中,我们构建了Uni-NaVid,一个用于统一多样化常见导航任务的视觉-语言-行动(VLA)模型(见表1)。
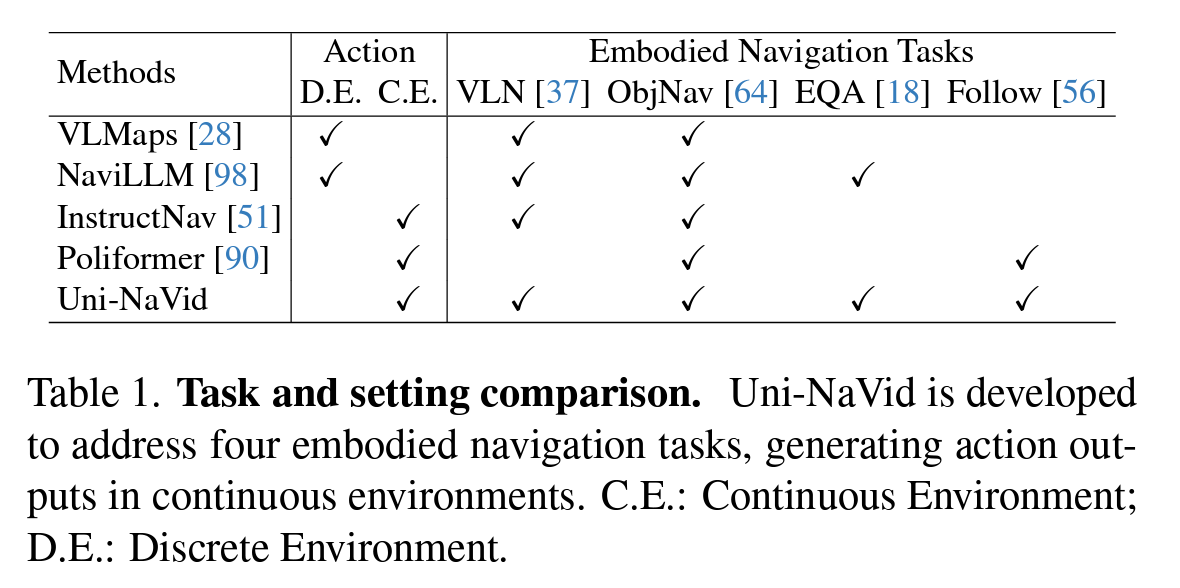
表1. 任务与设置比较。Uni-NaVid旨在解决四种具身导航任务,在连续环境中生成动作输出。C.E.:连续环境;D.E.:离散环境。
它以视频流和自然语言作为输入,能够自适应地生成遵循指令的动作,并在需要时以端到端的方式自动回答问题。我们首次努力解决三个关键问题,具体如下:
追求最终的现实应用:如何在最小化问题简化和最大化数据利用的情况下统一不同的导航任务?我们针对Uni-NaVid中的最新统一建模,采用单视角自我中心视频流和自然语言作为输入,自适应地端到端生成指令或问题的动作或语言响应。我们遵循大型语言模型(LLMs)的自然特性,将不同导航任务的输入和输出在标记空间中交错成一个单一序列,以便在Uni-NaVid中实现基于下一个标记预测范式的联合学习。该模型整合了四个广泛需求的导航任务,包括视觉与语言导航(VLN)、目标物体导航、具身问答和人类跟随。相应的训练数据均来自模拟环境。此外,我们进一步将互联网真实世界数据用于视频问答(VQA)和视频字幕生成作为辅助任务,融入这个统一模型中,以增强导航性能并促进从模拟到真实的泛化。这是该领域在统一跨模态、跨任务和跨模拟到真实建模方面的一项开创性尝试。它在广泛范围内实现了显著的协同效应,形成了一个全栈导航代理。
如何提高这种统一设计的效率,以便实现便于部署的模型?除了统一建模外,我们还优先考虑高效的模型设计以便于实际部署。具体而言,我们采用在线标记合并机制,以相对较低的比例压缩近历史帧,同时以相对较高的比例压缩远历史帧。通过这种方式,Uni-NaVid学习到的紧凑表示不仅保持了细粒度的空间信息,还保留了结构化的时间信息,从而通过减少标记数量加快模型推理。
此外,Uni-NaVid采用前瞻性预测一次性生成未来时间段的动作,而不是逐步生成。这使我们能够对动作推理和执行采用异步策略。如何验证不同任务之间的协同效应?我们进行全面的消融研究,以验证不同导航任务之间的协同效应,以及在模拟和真实世界环境中模拟任务与真实任务之间的协同效应。我们发现,在如此广泛的统一建模中,它们相互促进,并帮助Uni-NaVid在所有子任务中相较于近期工作取得明显优势。此外,我们还在包含多个子任务的长时间真实世界任务上评估了Uni-NaVid,并观察到它能够以零样本的方式完成这些任务,如图1所示。通过探索这三个关键问题,我们展示了统一建模和跨不同任务及从模拟到真实转移的联合数据利用的优势。

图1. Uni-NaVid通过使用360万条导航样本,学习了四种具身导航任务的通用导航技能。Uni-NaVid仅以在线RGB视频帧和语言指令作为输入,并输出相应的动作,从而在现实世界的部署中实现了通用导航能力。
我们希望这将促进未来在开发适用于一般目的的最新全栈导航代理方面的进展。为此主要的亮点为:
-
具身导航任务统一:Uni-NaVid是一个导航通用模型,将多种具身导航任务整合为一个模型,包括视觉与语言导航(VLN)、目标导航(ObjectNav)、具身问答(EQA)和人类跟随任务。
-
任务协同应对数据需求:Uni-NaVid整合了360万条涵盖不同任务的导航样本,通过有效的任务协同,在多样化的导航基准测试中实现了显著的性能提升。
-
高效且非阻塞的部署:Uni-NaVid采用在线标记合并策略,实现约5 Hz的模型推理,并预测多个未来步骤的动作,以便在现实世界中实现非阻塞部署。
-
令人印象深刻的从模拟到真实的结果:Uni-NaVid通过结合模拟动作数据和互联网语义进行统一的共同训练,能够生成动作和语言。这在真实环境中展现了令人瞩目的从模拟到真实的泛化能力。
2. 方法
2.1 一般导航
我们将Uni-NaVid的一般导航定义如下:在时间 T T T时,给定一个由 l l l个单词组成的自然语言指令 I I I和一个包含序列帧 { x 1 , … , x T } \{x_1, \ldots, x_T\} { x1,…,xT}的以自我为中心的RGB视频 O T O_T OT,代理需要规划接下来的 k k k个动作 { A T , … , A T + k − 1 } \{A_T, \ldots, A_{T+k-1}\} { AT,…,AT+k−1}以在新环境中完成指令(在我们的实验中, k = 4 k=4 k=4)。遵循最常见的设置[64],我们采用四个低级动作 a ∈ A a \in A a∈A,包括 { F O R W A R D , T U R N − L E F T , T U R N − R I G H T , S T O P } \{FORWARD, TURN-LEFT, TURN-RIGHT, STOP\} { FORWARD,TURN−LEFT,TURN−RIGHT,STOP}。
2.2 概述
如图2所示,Uni-NaVid的架构旨在用于通用导航,由两个主要组件组成:视觉编码器和大型语言模型(LLM)。首先,视频通过视觉编码器被编码为一系列视觉标记。视觉标记在空间和时间上被合并,形成一个紧凑的视觉标记序列。然后,它们被投影到与语言标记对齐的空间中,这些标记被称为观察标记。与此类似,指令也被标记化为一组标记,称为指令标记。观察标记和指令标记被连接在一起,并传递给LLM,后者推断出代表接下来四个动作的四个动作标记。
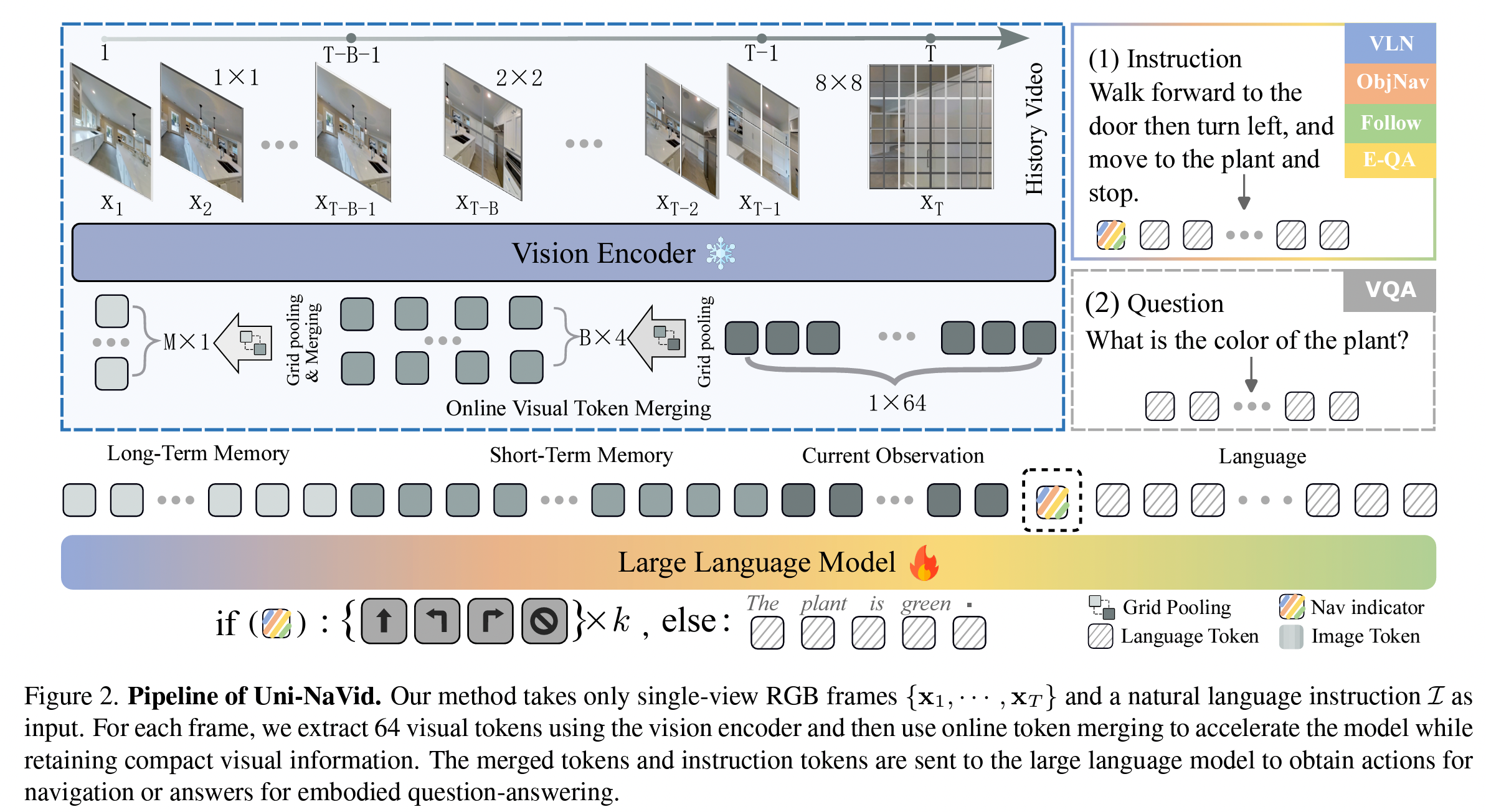
图2. Uni-NaVid的流程图。我们的方法仅将单视角RGB帧 { x 1 , … , x T } \{x_1, \ldots, x_T\} { x1,…,xT}和自然语言指令 I I I作为输入。对于每一帧,我们使用视觉编码器提取64个视觉标记,然后采用在线标记合并技术来加速模型,同时保留紧凑的视觉信息。合并后的标记和指令标记被发送到大型语言模型,以获取用于导航的动作或用于具身问答的答案。
3. Uni-NaVid模型
3.1 观察编码
给定时间 T T T内的自我中心视频,记作 O T = { x 1 , … , x T } O_T = \{x_1, \ldots, x_T\} OT={ x1,…,xT},我们将视频编码为一系列观察标记。对于每一帧 x t x_t xt,我们首先通过视觉编码器(实现中使用EVA-CLIP [70])获取其视觉标记 X t ∈ R N x × C X_t \in \mathbb{R}^{N_x \times C} Xt∈RNx×C,其中 N x N_x Nx为补丁数量( N x N_x Nx设定为256), C C C为嵌入维度。受到视觉-语言模型[44, 46]的启发,我们还通过将视觉特征嵌入投影到语言空间来执行视觉-语言对齐,记作观察标记 E t V ∈ R N x × C E^V_t \in \mathbb{R}^{N_x \times C} EtV∈RNx×C。其关系为:
E V t = P V ( X t ) , ( 1 ) E_V^t = P_V(X_t), \quad (1) EVt=PV(Xt),(1)
其中 P V P_V PV表示跨模态投影器。尽管观察标记为代理提供了规划下一步行动所需的关键视觉信息,但这些标记数量线性增加( T × N x T \times N_x T×Nx)导致处理时间逐渐延长,使得直接用于导航变得不切实际。
3.2 在线视觉标记合并
为了平衡视觉标记的效率和有效性,我们设计了一种标记合并策略,以保留与导航相关的视觉信息。这一策略基于关键导航洞察,即最近的观察更为重要,并且连续帧之间及相邻像素的视觉信息可能是冗余的。受到阿特金森-希弗林记忆模型[6, 69]的启发,我们将视觉标记分为当前视觉标记 X curr X_{\text{curr}} Xcurr、短期视觉标记 X short X_{\text{short}} Xshort和长期视觉标记 X long X_{\text{long}} Xlong。这些标记根据其相对于最近帧的时间戳进行分组。当前视觉标记捕捉了足够的视觉信息,使代理能够感知其周围环境并规划后续路径。短期视觉标记保持时间连续性,暂时保留相关信息以支持正在进行的规划。长期视觉标记促进了整个导航历史知识的整合和检索。对于每一类视觉标记,我们在不同的池化分辨率下应用网格池化操作:
X 1 : T = { X curr = GridPool ( X t , α curr ) , if t = T X short = GridPool ( X t , α short ) , if t ∈ [ T − B , T ) X long = GridPool ( X t , α long ) , if t ∈ [ 1 , T − B ) ( 2 ) X_{1:T} = \begin{cases}X_{\text{curr}} = \text{GridPool}(X_t, \alpha_{\text{curr}}), & \text{if } t = T \\X_{\text{short}} = \text{GridPool}(X_t, \alpha_{\text{short}}), & \text{if } t \in [T-B, T) \\X_{\text{long}} = \text{GridPool}(X_t, \alpha_{\text{long}}), & \text{if } t \in [1, T-B) \end{cases} \quad (2) X1:T=⎩ ⎨ ⎧Xcurr=GridPool(Xt,αcurr),Xshort=GridPool(Xt,αshort),Xlong=GridPool(Xt,αlong),if t=Tif t∈[T−B,T)if t∈[1,T−B)(2)
其中 GridPool ( ⋅ ) \text{GridPool}(\cdot) GridPool(⋅)是网格池化操作[44, 95],将标记从 N x N_x Nx压缩到 N x α 2 \frac{N_x}{\alpha^2} α2Nx, B B B(设定为64)是短期记忆缓冲区的长度。在这里,我们采用 α curr = 2 , α short = 8 , α long = 16 \alpha_{\text{curr}} = 2, \alpha_{\text{short}} = 8, \alpha_{\text{long}} = 16 αcurr=2,αshort=8,αlong=16,最终得到的视觉标记为 X curr ∈ R 64 × C X_{\text{curr}} \in \mathbb{R}^{64 \times C} Xcurr∈R64×C、 X short ∈ R 4 × C X_{\text{short}} \in \mathbb{R}^{4 \times C} Xshort∈R4×C、 X long ∈ R 1 × C X_{\text{long}} \in \mathbb{R}^{1 \times C} Xlong∈R1×C。这些超参数通过经验实验确定,如果内存和计算资源不是主要限制,可以进行调整。
在导航过程中,代理持续观察新的帧。当时间 T + 1 T + 1 T+1的新帧到达时,我们对时间 T T T的最新视觉标记和时间 T − B T - B T−B的最旧短期视觉标记应用网格池化,然后分别将它们插入短期和长期视觉标记中:
X curr → short = GridPool ( X curr , α short α curr ) , ( 3 ) X_{\text{curr} \to \text{short}} = \text{GridPool}(X_{\text{curr}}, \frac{\alpha_{\text{short}}}{\alpha_{\text{curr}}}), \quad (3) Xcurr→short=GridPool(Xcurr,αcurrαshort),(3)
X short → long = GridPool ( X short , α long α short ) . ( 4 ) X_{\text{short} \to \text{long}} = \text{GridPool}(X_{\text{short}}, \frac{\alpha_{\text{long}}}{\alpha_{\text{short}}}). \quad (4) Xshort→long=GridPool(Xshort,αshortαlong).(4)
通过这种方式,我们可以在线更新短期视觉标记和长期视觉标记,使用之前生成的标记。此外,我们比较 X short → long X_{\text{short} \to \text{long}} Xshort→long与时间 T − B − 1 T - B - 1 T−B−1的最新长期视觉标记 X long X_{\text{long}} Xlong的余弦相似度。如果相似度高于给定阈值 τ \tau τ,我们根据最新长期视觉标记中先前合并的帧数 K K K进行合并:
X long = 1 K + 1 ( K X long + X short → long ) , ( 5 ) X_{\text{long}} = \frac{1}{K + 1}(K X_{\text{long}} + X_{\text{short} \to \text{long}}), \quad (5) Xlong=K+11(KXlong+Xshort→long),(5)
subject to cos ( X long , X short → long ) > τ . ( 6 ) \text{subject to } \cos(X_{\text{long}}, X_{\text{short} \to \text{long}}) > \tau. \quad (6) subject to cos(Xlong,Xshort→long)>τ.(6)
如果它们的相似度低于 τ \tau τ(经验上设定为 τ = 0.95 \tau = 0.95 τ=0.95 [69]),则我们插入新的长期视觉标记 X short → long X_{\text{short} \to \text{long}} Xshort→long,这表明它们包含相对独特的视觉信息。这种时间上的融合以高度紧凑的形式(长度为 M ≪ T − B − 1 M \ll T - B - 1 M≪T−B−1)保留了观察历史,并且合并这些标记的计算成本最小。只有视觉标记类型边界的帧需要通过并行池化操作进行计算,使得该过程在计算上高效,并自然适合于现实世界导航应用的在线部署。与现有的视频基础大型语言模型[44, 69, 95]相比,这种合并策略显著减少了处理时间,平均每次推理仅需0.2秒。当处理较长的视频序列时,这一改进变得愈加显著。关于时间效率的详细分析见补充材料。
3.3 行动规划
对于行动规划,我们遵循现有工作[95],使用特殊标记<NAV>来通知大型语言模型(LLM)预测导航动作。因此,我们将观察标记序列 E 1 : T V E^V_{1:T} E1:TV(通过公式(1)获得,结合公式(2)的视觉标记)与特殊标记<NAV>和指令标记连接,并将其输入LLM以推断4个行动标记 { E T A , … , E T + 3 A } \{E^A_T, \ldots, E^A_{T+3}\} { ETA,…,ET+3A}:
输入: { 长期帧 } { 短期帧 } { 当前帧 } < N A V > { 指令 } \{长期帧\} \{短期帧\} \{当前帧\} <NAV> \{指令\} { 长期帧}{ 短期帧}{ 当前帧}<NAV>{ 指令}
输出: < A c t i o n 0 > < A c t i o n 1 > < A c t i o n 2 > < A c t i o n 3 > <Action 0><Action 1><Action 2><Action 3> <Action0><Action1><Action2><Action3>
这些行动标记属于离散行动集 { F O R W A R D , T U R N − L E F T , T U R N − R I G H T , S T O P } \{FORWARD, TURN-LEFT, TURN-RIGHT, STOP\} { FORWARD,TURN−LEFT,TURN−RIGHT,STOP}。根据现有导航设置中的标准配置[64, 90],前进动作对应于25厘米的移动,而转向动作表示30°的旋转。该配置与所有训练导航数据一致(见第3.2节)。经验上,我们发现预测接下来的四个步骤能够获得最佳性能,这鼓励Uni-NaVid预测长时间跨度的行动序列,同时仍考虑足够的观察以实现准确预测。这种多步预测也支持异步部署,使得在现实世界中实现非阻塞的导航性能成为可能。有关详细阐述,请参见补充材料。
4. Uni-NaVid的训练
为了训练一个适用于通用导航的大规模模型,收集广泛且多样的导航数据至关重要,这些数据应涵盖各种任务和环境。然而,直接收集大量的真实世界导航数据可能会导致高昂的成本。为此,我们提出了两种关键方法来训练Uni-NaVid:首先,我们在广泛的合成环境中收集多任务导航数据(共861个场景),使Uni-NaVid能够获得通用的导航技能;其次,我们与真实世界的视频问答数据共同微调Uni-NaVid,增强其对真实世界图像的理解,并支持其开放词汇知识。
4.1 多任务导航数据
我们在Habitat模拟器环境中收集了迄今为止最大的多任务导航数据集[64],包括在四种不同导航任务中收集的360万样本。所有数据均以统一格式整理,详细信息见补充材料。
(A) 视觉与语言导航 [37]要求代理理解语言指令,以便沿着描述的路径行进。我们收集了两种类型的指令:一种使用地标并描述它们之间所需的动作,另一种则指定低级动作,例如向前移动5步。我们基于VLN-CE R2R [37]和RxR [40]收集了240万样本。
(B) 目标物体导航 [64]涉及代理在环境中导航,以根据提供的视觉或语言线索定位特定物体。该任务评估代理感知物体、理解空间关系和执行高效搜索策略的能力。我们从Habitat Matterport 3D数据集[57]收集了48.3万样本。
© 具身问答 [18]要求代理导航到相关区域以进行问答。这涉及空间推理、物体描述和理解上下文信息,要求代理能够整合感知、语言理解和决策能力。根据EQA [18]中的设置,代理首先导航到与问题相关的目标,发出停止动作,然后提供答案。我们在Matterport 3D环境[10]的EQA数据集[18]上收集了24万视频动作样本和1万视频回答样本。
(D) 人类跟随 [31]要求代理在动态和拥挤的环境中跟踪并跟随具有特定描述的人类目标,例如:“跟随穿蓝色T恤的男人。”代理必须识别该人类的外观,跟随指令中描述的正确人物,预测其运动轨迹,并在避免障碍物的同时保持适当的距离[20]。基于Habitat 3.0社交导航环境[56],我们收集了54.4万个人类跟随导航样本。数据统计见图3。请注意,所有数据均来自合成环境,包括Habitat-Matterport和Matterport 3D,总计861个场景。我们使用每个环境的默认设置,高度范围为0.88米至1.25米,机器人半径为0.1米至0.6米。这有助于避免对特定机器人形态的过拟合。
4.2 合成数据与真实世界数据的联合训练
尽管我们从各种环境中收集了导航数据,但观察和指令的多样性仍然局限于某一特定的合成环境集。为了融入开放世界知识,我们遵循先前的视觉语言导航(VLA)方法[8, 95],使用开放世界视频问答数据集对Uni-NaVid进行微调。我们从公开可用的数据集中收集了230万视频问答数据[7, 16, 44],使总训练样本达到590万。我们采用两阶段训练过程:首先训练视觉投影器,然后联合训练投影器和大型语言模型。进一步的训练细节见补充材料。
5. 实施细节
5.1 训练配置
Uni-NaVid在一个配备40个NVIDIA H800 GPU的集群服务器上训练,持续约35小时,总计1400 GPU小时。对于视频数据,我们以每秒1帧的频率采样,以去除连续帧之间的冗余信息。在训练过程中,EVA-CLIP [70]和Vicuna-7B [17]预加载了默认的预训练权重。遵循VLM [46]的训练策略,我们仅优化可训练参数1个周期。
5.2 基准评估与真实世界部署
对于每个导航任务,我们遵循其默认设置[18, 31, 37, 64]。具体而言,对于具身问答(EQA)[18],代理根据策略执行动作,直到输出停止命令。然后,我们移除导航特殊标记

图4. Uni-NaVid在真实世界中的视觉结果.我们在多样化的环境中部署Uni-NaVid,以在零样本设置下执行指令。我们提供了第三人称视角和机器人的轨迹,展示了其有效的多任务导航性能。
6. 结论
我们提出了一种视觉-语言-动作模型Uni-NaVid,旨在通过多任务导航数据获取通用的具身导航技能。为了高效编码在导航过程中遇到的扩展视频序列,我们开发了一种在线视觉标记合并策略,该策略分别处理当前观察、短期观察和长期观察。这一设计使我们的模型能够以平均5 Hz的速度运行。针对公开可用基准的广泛实验显示了我们模型的卓越性能。消融研究证明了通过学习多个导航任务所实现的协同效应,并验证了我们关键设计的有效性。未来,我们将探索更基础的具身技能之间的协同,整合操作和导航两方面的能力。